
社交、直播、论坛、电商等各类平台每天都会产生海量 UGC(User Generated Content),其中不可避免地混杂有大量垃圾文本。这些内容不但严重影响用户体验,而且还可能发生违规的运营风险。面对这些迫切需要,达观数据提供了垃圾信息过滤的服务,精准定位并剔除不良信息。通常垃圾信息过滤的问题可以看作分类问题,即判断一个评论是属于正常评论这个分类,还是属于垃圾信息这个分类。文本分类的研究已经经历了很长时间的发展,传统的垃圾信息过滤方法一般是监督的,但是为了确保分类器有良好的泛化能力,这些方法的使用都必须以存在大量标注语料作为前提条件。而在垃圾信息过滤的场景下,标注工作是一件极为困难的事情,达观的审核系统在开发阶段初期就面临标注样本不足的挑战。一方面,用户活跃的平台每天都能产生大量新的评论,而且垃圾信息所占的比重会很高,标注成本非常高;另一方面,垃圾信息发布用户会想方设法把自己“隐藏”在其他正常评论中,只凭语义信息可能难以确定是否垃圾信息。
为了克服标注样本不足的难题,垃圾信息过滤可以引入半监督学习方法来增强信息处理的能力。半监督学习方法的优势是能够在只有少量标注数据的条件下,综合利用已标注数据和未标注数据的信息,达到较好的过滤效果。达观的文本挖掘系统在多个模块里面都使用到了半监督学习的方法,主要方式是通过外部知识来对训练样本进行语义扩展,然后结合数量较多的未标注样本选取预测置信度高的子集作为新样本加入训练集进行模型训练。
下面我介绍一下最近阅读过的采用半监督学习来进行垃圾信息过滤的两篇论文:NetSpam 和 SPEAGLE。
1. NetSpam: a Network-based Spam Detection Framework for Reviews in Online Social Media
NetSpam 论文的基本思想是使用了异构信息网络方法来对用户评论进行建模,比较新颖的是在文本分类过程,利用到了异构网络中不同的边类型的信息来提升分类效果。另外,使用了无监督的方法能够在没有标注样本的情况下,根据评论数据的统计信息,获得各种特征对应的重要性。
a) 特征类型
这篇文章提到了问题解决使用到的几方面特征,主要是从基于用户 / 评论和行为 / 语言特征两个维度去刻画,具体特征示例参考表格 1:
表格 1 NetSpam 特征类型

b) 异构信息网络

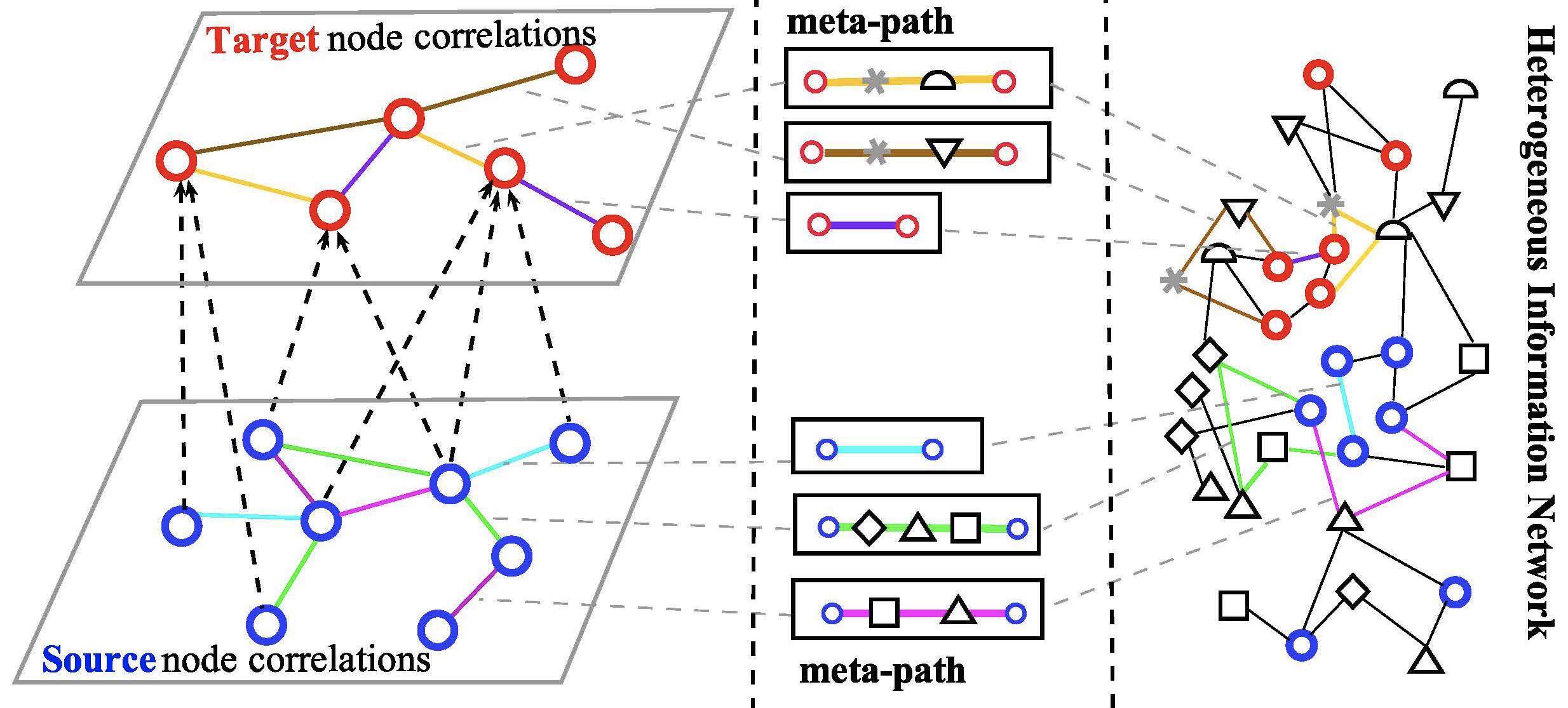
图 1 异构信息网络

c) 算法模型

图 2 网络架构
基于该网络架构形成的评论到评论的元路径可表示为表格 2。
表格 2 元路径列表
标记
类型
元路径
关联语义信息
R-DEV-R
RB
评论 - 带阈值偏差率 - 评论
具有同等偏差率的评论
R-U-NR-U-R
UB
评论 - 用户 - 负面比率 - 用户 - 评论
被具有相似的负面比率的不同用户发表的评论
R-ETF-R
RB
评论 - 早期时帧 - 评论
同一时间间隔发布的评论
R-U-BST-U-R
UB
评论 - 用户 - 突发性 - 用户 - 评论
同样突发性的用户发布的评论
R-RES-R
RL
评论 - 感叹号比例 - 评论
具有相同感叹号比例的评论
R-PP1-R
RL
评论 - 第一人称数目 - 评论
具有相同第一人称数目的评论
R-U-ACS-U-R
UL
评论 - 用户 - 平均内容相似度 - 用户 - 评论
具有相同平均内容相似度的不同用户发布的评论
R-U-MCS-U-R
UL
评论 - 用户 - 最大内容相似度 - 用户 - 评论
具有相同最大内容相似度的不同用户发布的评论
给定了元路径的设定后,论文扩展了异构网络的定义,在元路径上具有相同的值的两个评论是相互连通的。给定评论 u,u 在元路径 pl 上的值的计算方式为
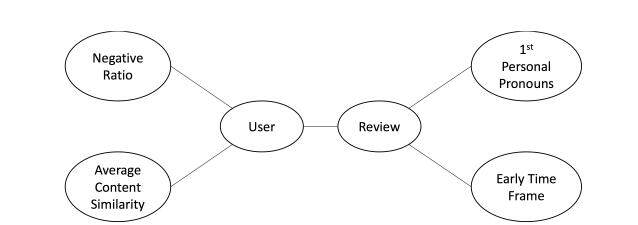
其中 s 表示指定的元路径对垃圾评论相关的确定性的级别。如果对于两个评论 u 和 v,如果满足
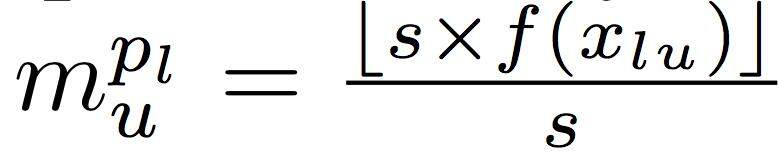
那么在评论网络中就把这两个评论连通起来。
d) 分类过程
NetSpam 的分类过程包括两个步骤:计算每个特征的影响权重;计算每条评论的最终概率并且进行标记垃圾 / 非垃圾信息。(达观数据 张健)NetSpam 认为节点的分类是基于评论网络中该节点与其他节点的关系完成的,关联的两个节点会有较高的概率带有同样的标签。在此过程中,元路径的权重会帮助我们去理解评论网络中各种影响因子的重要性,合理设计权重的计算方式对分类效果有直接影响。该论文提出元路径权重的计算方式为:
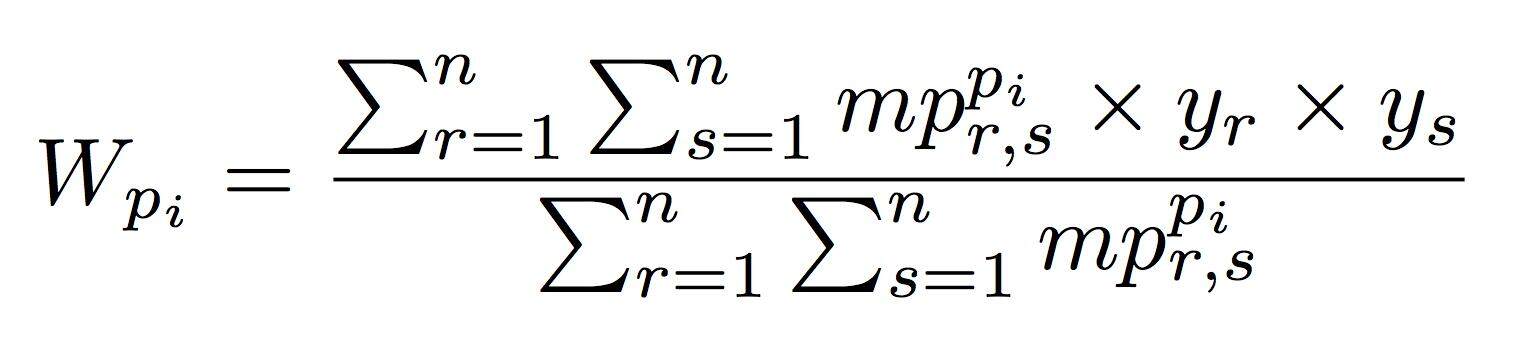
标记过程就比较简单,假设 Pru,v 是和垃圾评论 v 有连通关系的未标注评论 u 可能是垃圾评论的概率,它的计算方式为:
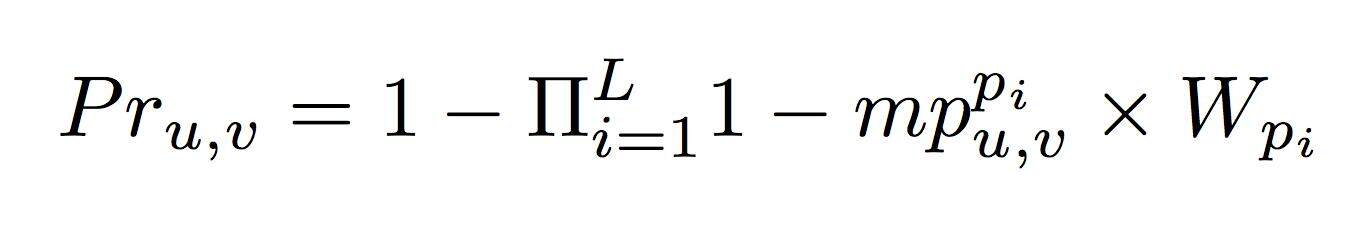
而评论 u 最终为垃圾评论的概率 Pru 计算方式为:
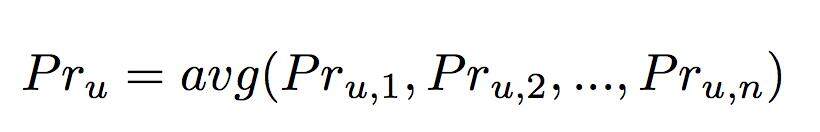
图 3 展示了对构建的异构信息网络进行分类处理的计算过程:
(点击放大图像)

图 3 NetSpam 分类处理流程
e) 小结:
基于异构信息网络对用户评论进行建模,从全局上充分地收集了评论和用户,评论和评论,用户和用户之间的多元关系信息,在行为和语言特征两个维度上进行评估,能在不依赖于专家知识的基础上,自动地学习到用户和评论的分类属性,具有较强的鲁棒性。
2. Collective Opinion Spam Detection: Bridging Review Networks and Metadata
SpEagle 论文认为垃圾信息过滤需要充分用到包括文本、时间戳和评分在内的元数据和评论网络,并且需要将这它们融合到一个体系内。如图 4 所示,SpEagle 利用了元数据、评论网络以及评论标签的信息,完成了识别出垃圾内容发布者、虚假评论和虚假内容目标商品三者的任务,分类过程是通过评论 - 产品和评论 - 用户的关系构建马尔科夫随机场模型实现。
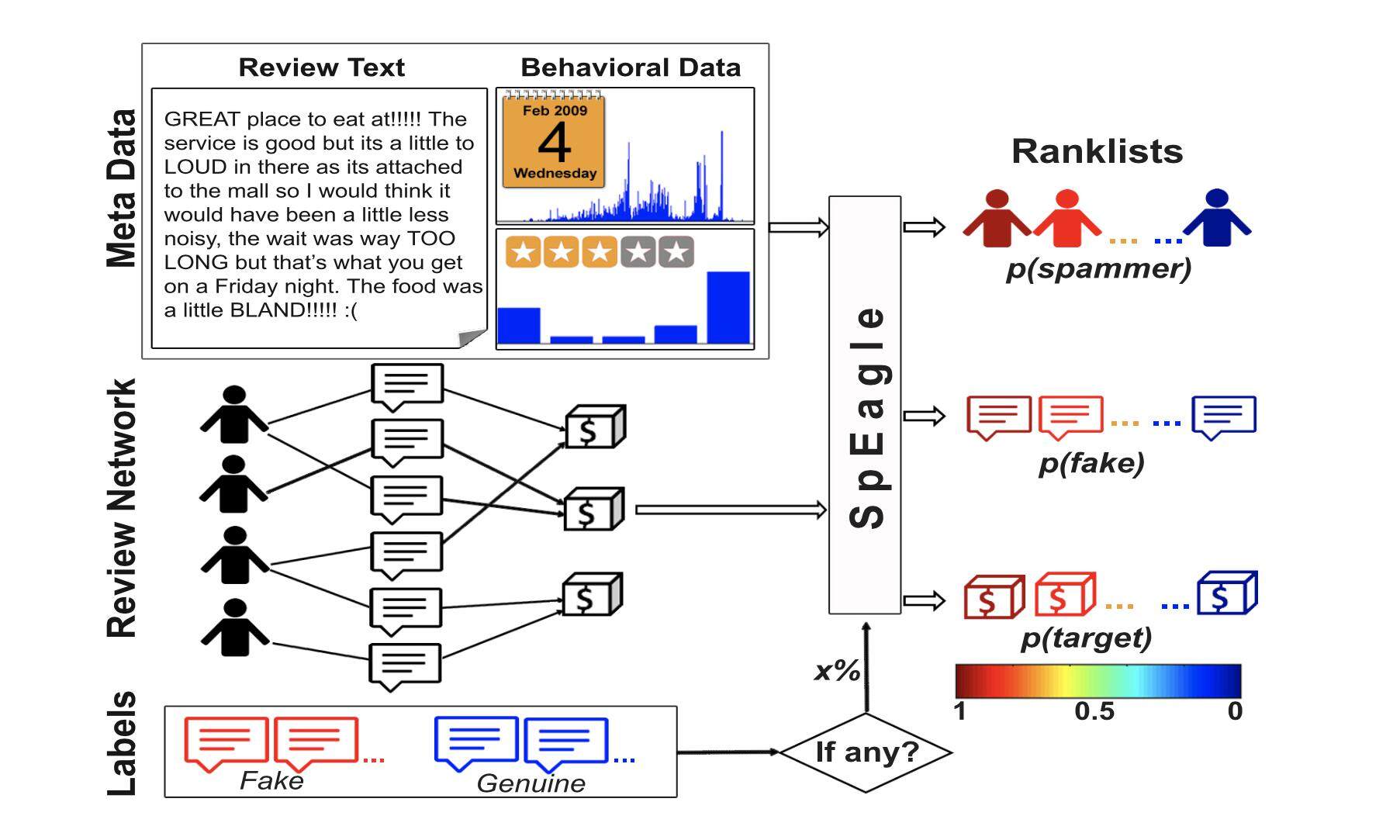
图 4 SPEAGLE 系统框架
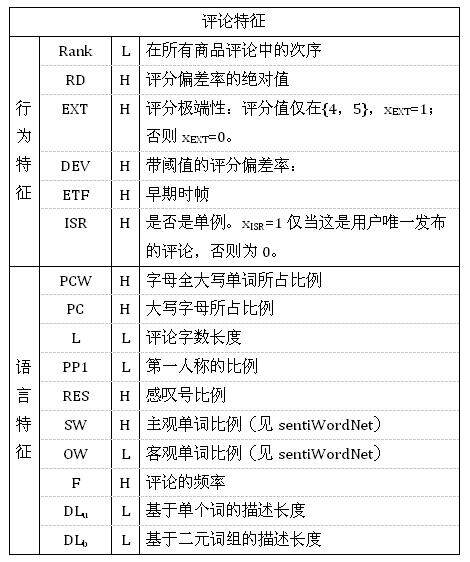
a) 特征类型:
SPEAGLE 用到的特征和 NetSpam 论文相似,如表格 3 和表格 4(其中第三列的 H/L 表示和垃圾内容的关联度是高 / 低):
表格 3 SPEAGLE 用户 & 商品特征类型
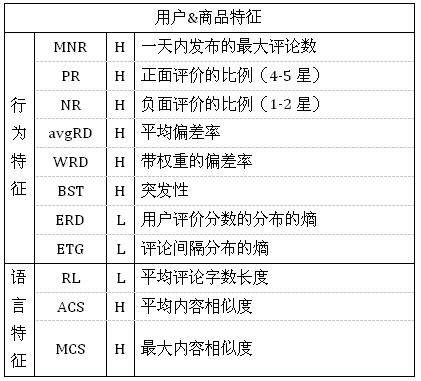
表格 4 SPEAGLE 评论特征
b) 模型定义

e) 算法过程


d) 小结
SPEAGLE 采用了基于评论网络来完成分类任务,将评论、用户和产品三者置于统一一致的框架内,而且对于不同的对象类型都使用了统一化的分类方法,这个点比较新鲜。
3. 达观数据垃圾信息过滤工程实践
达观的文本挖掘系统在多个模块里面都使用到了半监督学习的方法,主要方式是通过外部知识来对训练样本进行语义扩展,然后结合数量较多的未标注样本选取预测置信度高的子集作为新样本加入训练集进行模型训练。从上面两篇论文中的特征类型选择中可以看到,里面的语义特征抽取过程在英文文本上进行的。到了中文环境下,语义特征抽取的过程会变得复杂很多,主要是由于汉语的语言特性造成。具体到垃圾信息过滤这个场景中,变形识别问题是有效进行语义特征抽取亟需解决的重要问题。
a) 变形识别问题
我们在浏览像贴吧、论坛、新闻媒体等各种平台中,会时常看到变形的敏感词。人脑的思维方式让我们能够非常自然地发现这些变形词,因为这些变形词在句子中是“异常”的部分,这种“异常”的感觉会将我们的注意力聚集到这一区域,进而逐渐发现完整的变形词。而机器在直接面对这些变形词(包括间杂特殊符号,同音变换,形近变换,简繁转换,偏旁拆分等)时就显得稍微力不从心,变形词识别是解决中文垃圾内容过滤的一个重要问题。
0017
图 6 变形识别问题
b) 变形词自动化生成
如果关键词词库通过人工配置的话,不仅成本大,而且扩展比较困难,面对新类型的垃圾内容出现反应时间也相对较慢。为了解决变形词是被的问题,达观数据变形词采用了自动化生成的方法,具体步骤包括:
- 获取关键词词库的字作为种子集合。
- 构建变形词关联网络(结合拼音相似度、字形相似度、字频、共同出度、共同入度构建关联边的权重)。
- 生成关键字的相似度大于阈值的变形词。
- 已针对已有关键词词库构建变形词词库。

图 7 自动化生成变形词词库
c) 变形词检测
而在正文预测进行变形识别时,如果单纯依靠词库不结合语境的话,很有可能将正常词语错误识别为变形词。譬如根据同音转换的原则进行变形识别是, “Esports 海涛解说视频专题”识别出变形关键词“海淘”,实际上普通读者一眼可以看出来这其实是一段正常文本,“海涛”并非“海淘”的变形词。达观审核系统在解决变形词识别时,使用了下面的方法来进行变形词检测:
- 贝叶斯分析方法:统计变形词在正常文本上下文中出现概率,计算当前文本上下文中变形词的后验概率。像“徽ィ訁”这样的词语,在正常文本中出现的概率几乎为 0,所以可以判别为变形词;而对于出现在“Esports 海涛解说视频专题”的关键词“海涛”,在计算出了当前文本上下文的后验概率之后,可判别为正常词语。
- 词嵌入方法:将单词转化为词向量,计算上下文语义重心,计算单词的词向量与上下文文本语义重心向量的相似度。正常文本里面的词语跟上下文文本语义接近,所以对应的词向量在空间上也是比较接近的。通过计算它与上下文语义重心的相似度,可以判别出来该词语是否处于正常语境中,从而识别出来是否是变形词。
作者简介
张健,达观数据联合创始人,复旦大学计算机软件与应用专业硕士,达观数据专注于企业大数据技术服务,将拥有的人工智能、机器学习等技术,服务于广大的企业,独创的用户行为挖掘和预测系统,让计算机代替人脑自动分析文本数据挖掘数据隐藏的规律,提供智能搜索和推荐等专业技术服务后,极大的提升了企业运营的效率,帮助企业增加了运营利润。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论