
整理 | 华卫
“当所有人都在关注 OpenAI 的各种风波时,通义千问正在低调发力。中国的 AI 实验室确实有着不一样的发展节奏。”
刚刚,阿里发布了最新推理模型 Qwen3-Max-Thinking 的早期预览版,一位国外的网友对其发出这样的感叹。
Qwen3-Max-Thinking 是 Qwen3-Max-Preview 的推理增强版本,目前还是一个仍在训练中的中间检查点模型。但据称,即便在当前阶段,当该模型结合工具使用功能并提升测试时的计算规模后,它在 AIME 2025、HMMT 等具有挑战性的国际知名的高水平数学推理竞赛中,已能实现 100% 的正确率。

现在,用户可在 Qwen Chat 及阿里云 API 中试用当前版本,随着训练的持续推进,后续还将推出更多更新。
Qwen Chat: https://chat.qwen.ai/?thinking=true
阿里云 API(enable_thinking=True): https://modelstudio.console.alibabacloud.com/?tab=doc#/doc/?type=model&url=2840914_2&modelId=qwen3-max-preview
虽然刚推出不久,但上新推理功能的 Qwen3-Max-Preview 在 AI 社区迅速引起了关注。不少国外网友纷纷评价道,“对于一个中间检查点模型来说,能在 AIME 上实现 100% 正确率堪称疯狂。”而这似乎意味着:现在我们正逐渐进入一个新阶段:这些模型不再只是机械输出答案,而是真的开始通过思考来解决问题了。
值得注意的是,此前该模型还没有推理能力时,社区内就有许多用户基于个人体验广泛反馈,其在某些推理类任务上的表现比官方宣传的更出色。
排名比 Deepseek-V3.1 高,速度也比 ChatGPT 更快?
Qwen3-Max-Preview 最早在今年 9 月下旬推出,是阿里迄今为止规模最大、能力最强的语言模型,参数量在 1 万亿以上,预训练数据达到 36T tokens。该模型支持 262144 个 token 的上下文窗口,最大输入 token 数为 258048,最大输出 token 数为 32768。模型还支持上下文缓存功能,可在长时间会话中优化性能表现。
根据通义千问(Qwen)公布的对比基准测试数据显示,该 1 万亿参数模型在多项测试中均处于领先地位。在 SuperGPQA、AIME25、LiveCodeBench v6、Arena-Hard v2 以及 LiveBench(2024 年 11 月 25 日版本)等测试中,Qwen3-Max-Preview 的排名始终高于 Claude Opus 4、Kimi K2 和 Deepseek-V3.1。
在放出思考模式之前,就有外媒对其进行简短、纯经验性测试后称,Qwen3-Max-Preview 不仅规避了大语言模型(LLM)常见的缺陷, 比如错误统计 “Strawberry” 一词中字母 “R” 的出现次数、错误判断 9.11 与 9.11 哪个更大,而且响应速度极快。在 Qwen Chat 上的初步测试中,它的速度也确实比 ChatGPT 更快。
同时,有用户反馈,尽管当时 Qwen3-Max-Preview 并未被定位为推理模型,但在其测试中,该模型的表现优于多款 SOTA 模型,不仅能解决基础算术题、24 点类谜题,甚至还攻克了一道“GPT-5 Thinking 和 Gemini 2.5 Pro 无工具辅助时均无法解答” 的题目。根据其观察,面对更难的挑战时,该模型似乎会切换到类推理模式,输出结构清晰、步骤分明的答案。
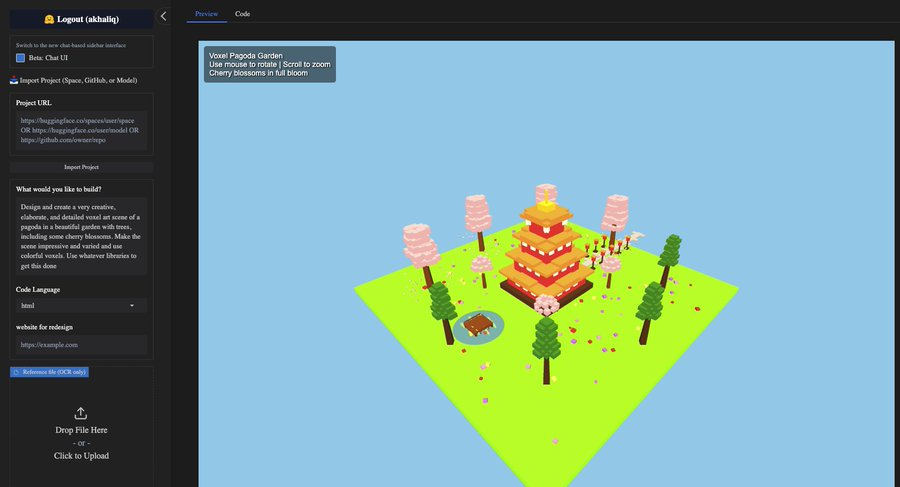
并且,Qwen3-Max-Preview 已成为 Hugging Face 机器学习增长负责人 Ahsen Khaliq 开发的开源编程工具 AnyCoder 中的默认选项。Khaliq 还在 X 上发布了一张屏幕截图,展示了它如何在 AnyCoder 上的单个提示中创建一个完整的体素像素花园。
不过,与通义千问以往发布的开源版本不同,Qwen3-Max-Preview 未基于开源许可证发布。这意味着现阶段开发者需通过该公司的付费 API,或上述提及的分销合作伙伴获取其使用权。阿里云为 Qwen3-Max-Preview 推出了分级定价方案,费率根据输入 token 的规模不同而变化:
0–32K token:每百万输入 token 0.861 美元,每百万输出 token 3.441 美元
32K–128K token:每百万输入 token 1.434 美元,每百万输出 token 5.735 美元
128K–252K token:每百万输入 token 2.151 美元,每百万输出 token 8.602 美元
通义千问强调,该模型专为复杂推理、代码编写、处理 JSON 等结构化数据格式,以及创意类任务设计。其能力还延伸至通用对话与智能体行为,使其成为适用于企业与科研场景的多用途工具。
推理版的实测表现如何?
如今的 Qwen3-Max-Preview 实现了思考与非思考模式的有效融合。在思维模式下,其智能体编程、常识推理以及跨数学、科学和通用领域的推理等能力有了显著增强。不过,当前的早期预览版仅支持文本到文本这一模态,输出是“限时免费”的。
目前,已有不少开发者和 AI 爱好者对该模型进行了实测体验并放出了使用感受。
一名开发者称,“在处理简单提示词时,Qwen3-Max-Thinking 的表现优于复杂提示词场景。从前端开发的角度来看,Qwen3-Max-Thinking 的表现比较一般。在部分推理题上,Qwen3-Max-Thinking 的表现超过了 GPT-5 Thinking。”

知名 YouTube 博主、AI 云工程师 Fahd Mirza 也第一时间测试了 Qwen3-Max-Thinking,案例是要求它创建一个使用 p5.js 的独立 HTML 文件,结果是:第一次尝试它就做得非常出色,几乎完成了代码的创建,描述了功能以及如何使用,最终呈现的效果也相当不错。
视频源 @Fahd Mirza(Qwen3-Max Thinking Released: Best Qwen Yet https://www.youtube.com/watch?v=DF5NMgMUmbw)
然而,也有开发者在实测该模型后先是表示,“考虑到它目前还只是预览版,团队确实需要抓紧时间继续训练优化。短期内不建议用它来处理编程类任务。”后又补充道,“根据测试结论,Max 系列可能不再适用于编程了。”
视频源 @karminski3(https://x.com/karminski3/status/1985233932405891348)
这名开发者在社交平台上分享了他对 Qwen3-Max-Thinking 的详细测试结果:
“大象牙膏” 实验测试中,画面看起来整体偏暗且模糊,但这其实是光线问题 —— 我已经放大画面让大家看清效果了。模型生成的场景建模和粒子效果只能说一般。提示词的完成度则非常差。过山车测试表现还不错,各部件衔接虽不算完全平滑,但没有出现断裂情况,不过支撑柱存在部分穿模问题。鞭炮连锁爆炸测试完全不合格:无法完成连锁反应演示,物理效果也不太对。而且成功率极低,6 次生成中只有 1 次没有代码错误。Python 倒水程序测试表现尚可,在顶级模型里算是达到及格水平。
另外,生成过程中的网页界面过于花哨。提示词里并没有要求这么复杂的设计,但最终呈现的效果却夸张得离谱。那它擅长写前端页面吗?答案是否定的。我让它写了一个瀑布流图片网站 —— 这个需求很考验前端布局能力,大家可以看看结果。它做的布局一团乱,所有卡片都叠在一起了。相比之下,GLM-4.6 就做得很好,在不同缩放比例下都能实现完美的 CSS 布局。
与此同时,还有用户在 Qwen3-Max-Thinking 的帮助下写了一篇黑色侦探小说,并评价其“展现出强大的推理能力,是正在发展中的前沿 AI 该有的样子”。
参考链接:
https://venturebeat.com/ai/qwen3-max-arrives-in-preview-with-1-trillion-parameters-blazing-fast
声明:本文为 AI 前线翻译整理,不代表平台观点,未经许可禁止转载。




