
作为近十几年人工智能最热门的研究领域之一,深度学习取得的突破进展有目共睹,甚至影响到人工智能行业整体的发展基础。4 月 26 日,2021 年 ArchSummit 全球架构师峰会在上海召开,百度举办“深度学习技术解读与实践”专场,多位飞桨技术专家分享了核心框架 2.0、开源模型库、分布式训练技术、以及 AI 开发平台的技术实践经验。

据了解,ArchSummit 全球架构师峰会是重点面向高端技术管理者、架构师的技术会议,54%参会者拥有 8 年以上工作经验。会议聚焦业界强大的技术成果,展示先进技术在行业中的典型实践,以及技术在企业转型、发展中的推动作用。
深度学习技术的广泛应用得益于深度学习框架的建设。深度学习框架在智能时代起到了承上启下的作用,下接芯片,上承各种应用,是“智能时代的操作系统”。而我国首个自主研发的产业级深度学习平台飞桨,已涵盖深度学习核心框架、基础模型库、端到端开发套件、工具组件以及飞桨企业版 AI 开发平台,能够助力开发者快速实现 AI 业务创新,上线 AI 应用。
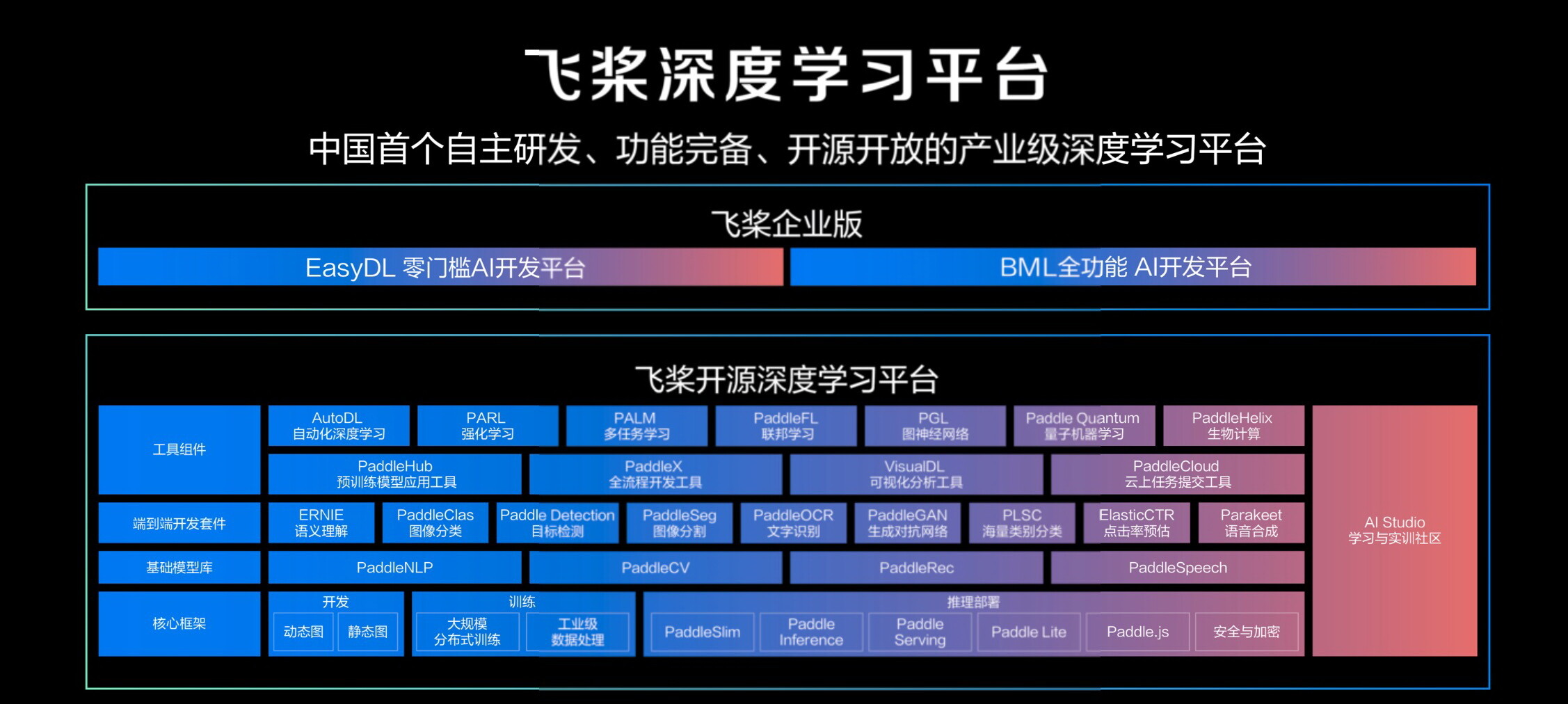
(飞桨产业级深度学习平台全景图)
飞桨核心框架 2.0 与开源模型库解读
活动当天,百度杰出研发架构师从飞桨的核心技术,飞桨核心框架 2.0 版本的升级特色,以及飞桨的产业级官方模型库的能力和产业应用案例进行介绍。整体而言,飞桨训练时以 Python 为主,拥有非常简单易用的编程界面,提供了多语言部署接口,可以顺畅部署到各种各样的研发环境。相对于其他框架,飞桨具备以下四大优势:
开发便捷的深度学习框架:提供了易用的 API,在飞桨框架 2.0 API 中表现明显;
超大规模深度学习模型训练技术:天然提供超大规模深度学习的模型训练技术,包括异构参数服务器、多维混合并行等等方面;
多端多平台部署的高性能推理引擎:飞桨模型在经过开发之后,会经过模型压缩、量化、蒸馏等优化的策略,能够在服务器端、移动端、网页端等不同架构的平台设备轻松部署。
产业级的开源模型库
开源丰富算法和预训练模型,包括国际竞赛冠军模型,快速助力产业应用。
今年初,飞桨框架 2.0 正式版发布。飞桨框架 2.0 的性能和效率明显提升,主要表现在以下方面:
动静统一的开发体验
飞桨框架 2.0 支持动态图和静态图两种开发模式,在 API 设计的时候,保持静态图和动态图组网类 API 的统一,通过添加一行代码,即可使得相同的网络在动态图和静态图两种模式下执行。动静统一的接口设计,使得飞桨在保持动态图的灵活性的同时,兼具静态图的高效。飞桨提供了全面完备的动转静支持,在 Python 语法支持覆盖度上达到领先水平。开发者在动态图编程调试的过程中,仅需添加一个装饰器,即可实现静态图训练或模型保存。同时飞桨框架 2.0 还做到了模型存储和加载的接口统一,保证动转静之后保存的模型文件能够在动、静态图模式中加载和使用。
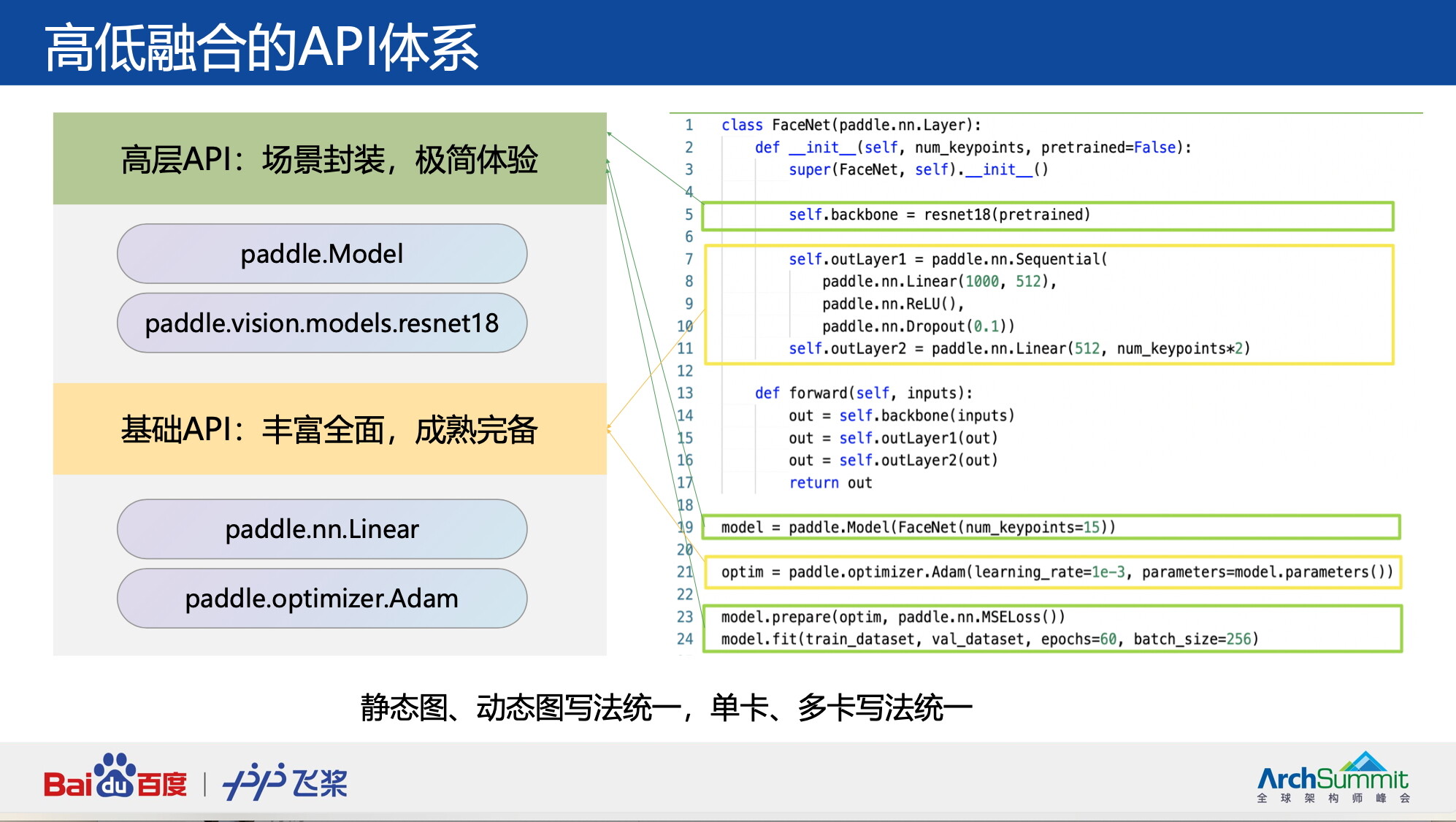
高低融合的 API 体系
飞桨框架 2.0 不仅完全兼容历史版本,配套完善文档和教程。高层 API 与基础 API 还采用一体化设计,即在编程过程中可以同时使用高层 API 与基础 API,让用户在简捷开发与精细化调优之间自由定制。
此外,飞桨官方支持超过 270 个经过产业实践长期打磨的主流算法模型,涵盖计算机视觉、自然语言处理、语音、推荐等多个领域,其中包含在图神经网络国际权威榜单 OGB(Open Graph Benchmark)和文本图推理比赛 TextGraphs2020 取得 4 项第一的飞桨图学习框架(PGL)、顶会 ECCV 2020 比赛中斩获两个赛道冠军的 PaddleDetection 等多个比赛夺冠模型。
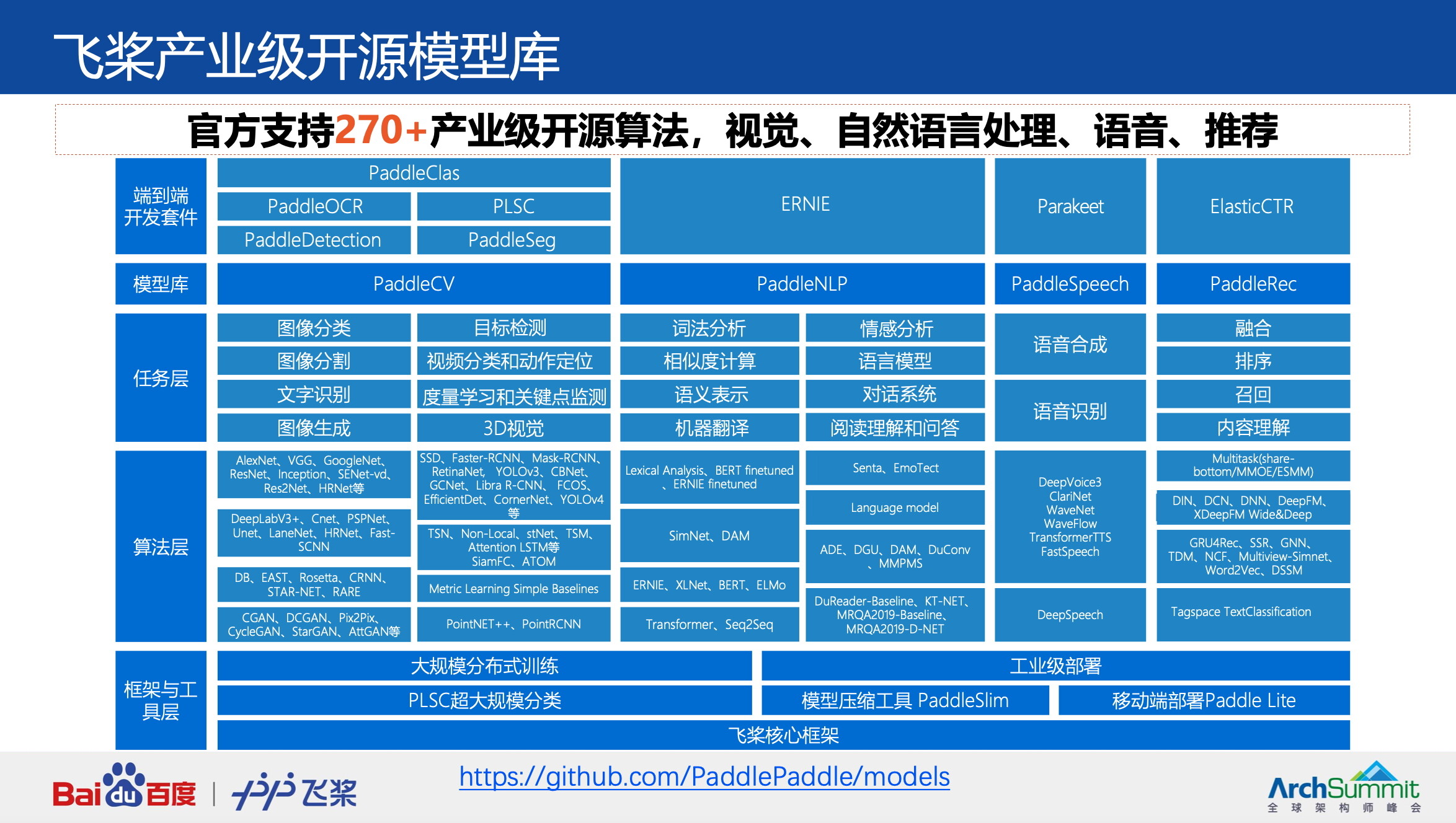
飞桨模型库具备很好的敏捷性,针对不同任务还提供了丰富的开发套件,除了图像分类套件 PaddleClas,还有包括目标检测开发套件 PaddleDetection、PaddleOCR 开发套件、图像分割开发套件 PaddleSeg 等等,覆盖全面、应用效果显著。
飞桨分布式训练技术架构剖析
当需要大规模的数据或使用大规模参数量进行模型训练时,百度资深研发工程师还向大家介绍了飞桨深度学习平台的分布式训练技术。其支持面对海量数据、大规模稀疏模型以及常规数据、大规模稠密模型的训练,并提出了参数服务器模型和集合通信模式,两个模式分别具备相应的优势:
参数服务器模式 (ParameterServer)
特点:中心化参数存储 + 同步当前节点的梯度
常见应用场景:IO 密集型任务(数据大、参数稀疏),如点击率预估
集合通信模式 (Collective)
特点:去中心化参数存储 + 同步所有节点的梯度
常见应用场景:训练密集型任务,如图像分类
在实际操作中,飞桨分布式训练框架包括三层:
硬件部署层:支持 CPU、GPU,还有如百度的昆仑、华为的昇腾等国产 AI 芯片。针对原生的 K8S,或者是各种云都具备调度功能。
核心框架层:从硬件逐渐到基础框架,再到二次开发的开发者层面、API 层面,逐渐自下往上的过程。
应用产业层:支持各种不同的业务、提供不同飞桨开发套件支持。

而在飞桨框架 2.0 升级之后,飞桨分布式训练又具备了更多的新特性:
分布式 API Fleet 全面升级
飞桨将一些主流的训练模式,包括集合通信训练和参数服务器训练,做成统一的 Fleet API(paddle.distributed.fleet),并在集合通信训练功能下实现了动态图和静态图训练 API 的统一。
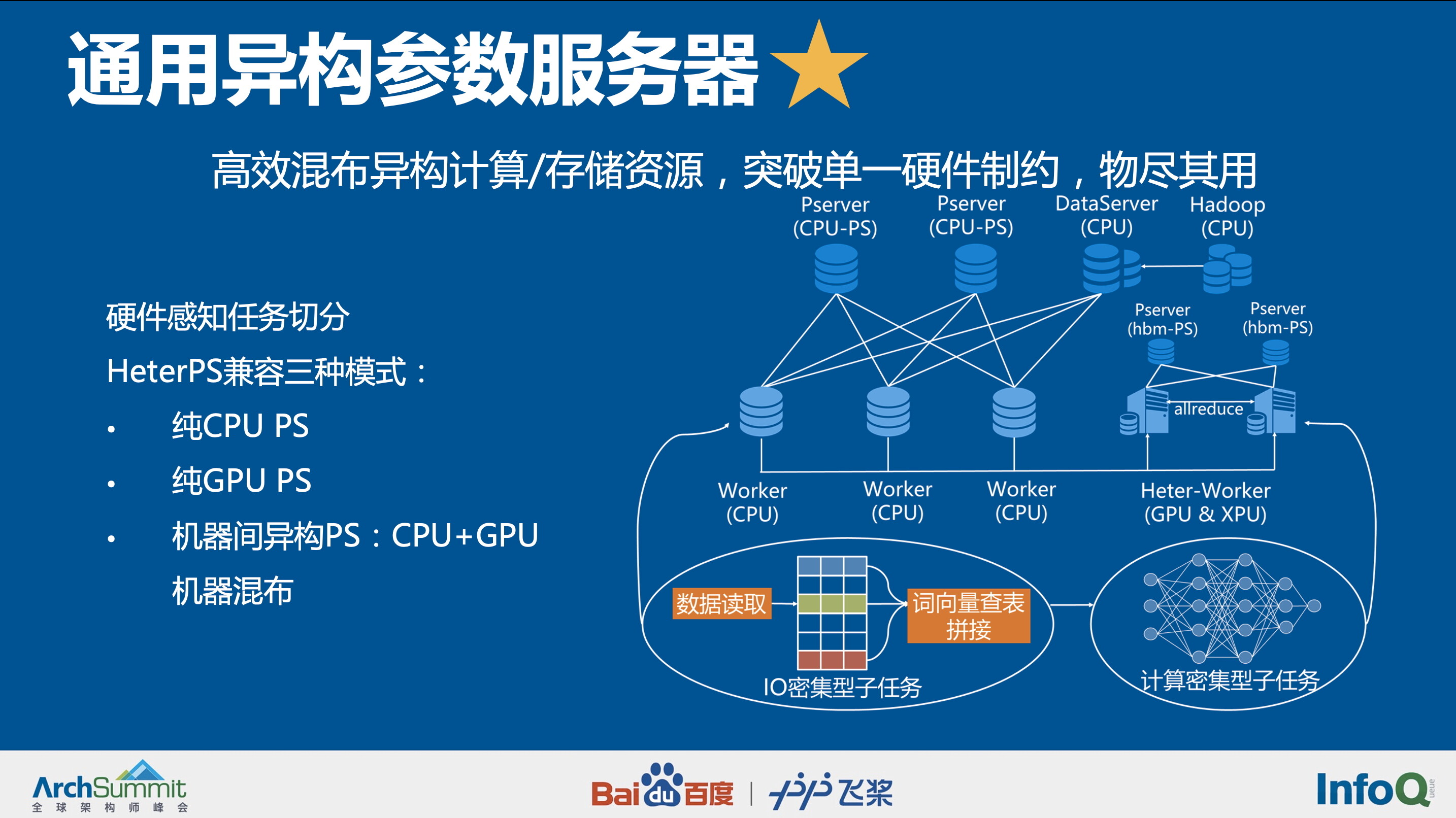
通用异构参数服务器
通用异构参数服务器可以对任务进行切分,让用户可以在硬件异构集群中部署分布式训练任务,实现对不同算力的芯片高效利用,为用户提供更高吞吐,更低资源消耗的训练能力。
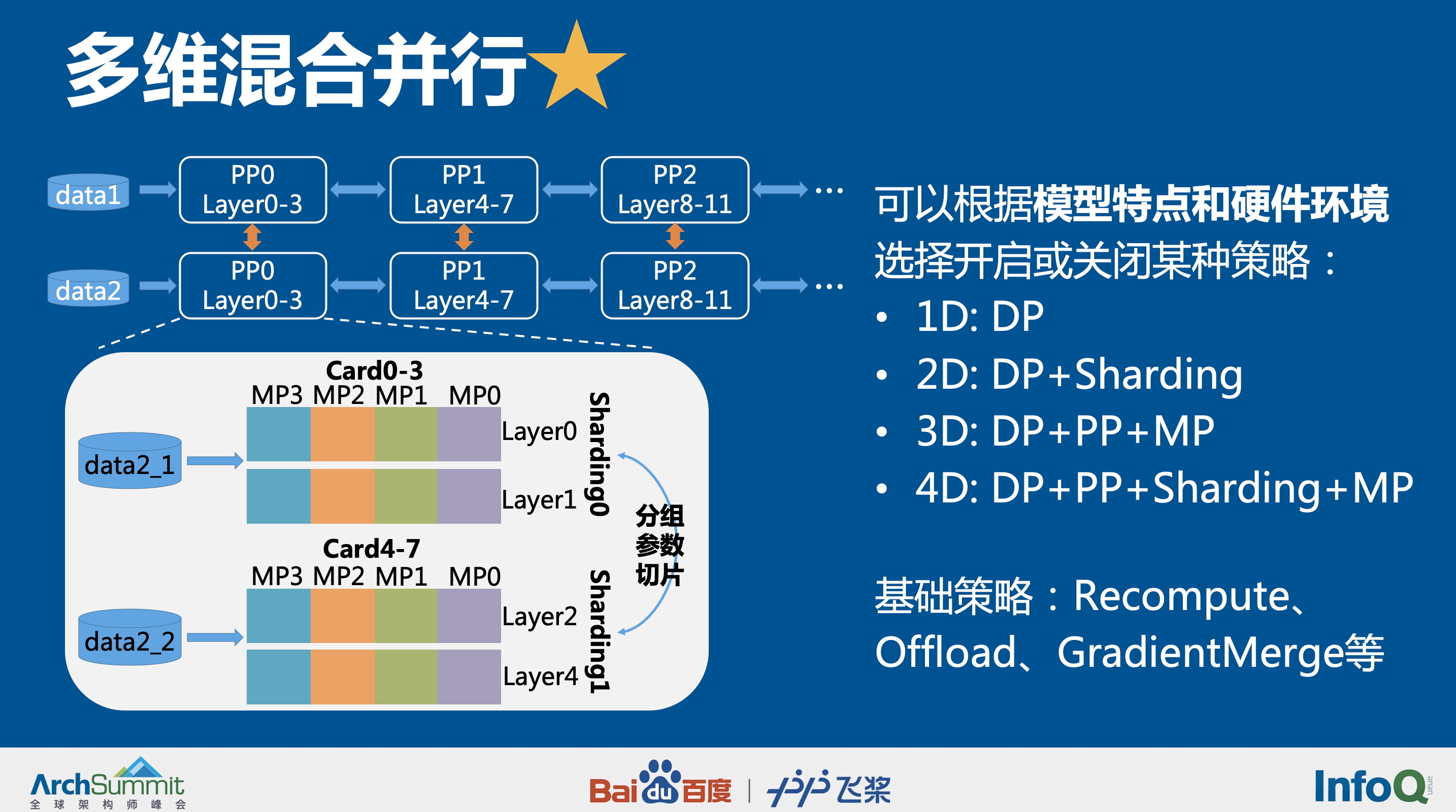
千亿语言模型多维混合并行训练
飞桨可以支持对四种不同并行策略的任意选择组合,充分考虑显存、带宽,并结合每一种硬件的特性和策略通讯量组合策略,降低超大规模的计算耗时,同时保证模型效果。
百度 AI 开发平台的探索与实践
除了架构与技术上的优势与创新经验外,根据百度与波士顿咨询公司的联合调研中,发现市场上约 86%的企业需求都是定制化的 AI 需求,从平台在 2017 年到 2020 年四年的数据也可以看出,定制化模型翻了六倍,整个产业的智能化正在跟 AI 技术做深度结合,这个需求也在不断地增长。
为了解决 AI 开发上的困难和挑战,并且满足企业针对场景的定制化应用需求,百度推出飞桨企业版,包括面向 AI 应用开发者打造的零门槛 AI 开发平台 EasyDL 和面向 AI 算法开发者的全功能 AI 开发平台 BML。
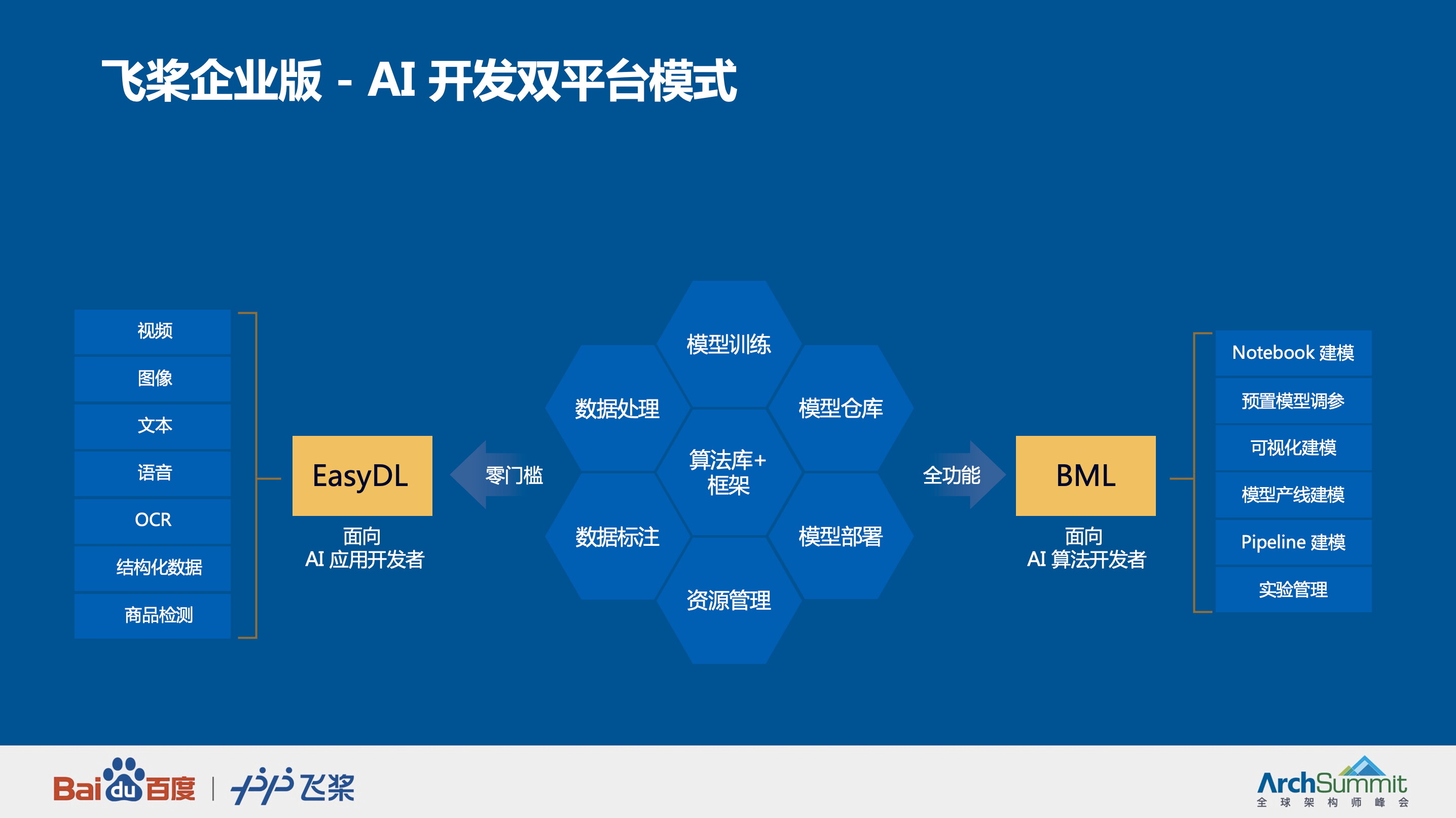
面向 AI 应用开发者的平台——EasyDL
截止目前 EasyDL 已有超过 80 万企业用户,落地智能硬件、零售快消、安全生产等行业。EasyDL 最快 15 分钟即可获取定制 AI 服务,满足 AI 应用开发者的核心诉求:
丰富任务场景:支持图像、文本、视频、语音、OCR、结构化数据、零售行业版 7 大技术方向,图像分类、视频分类、情感倾向分析、OCR 模版定制、语音识别、时序预测、商品检测等 16 种任务类型。
便捷的数据服务:提供了 EasyData 智能数据服务,实现数据采集、评估、清洗、标注的一站式服务。极大降低用户获取与处理数据的成本。
超高精度训练效果:EasyDL 内置了百度自研的超大规模视觉预训练模型和自然语言处理的预训练模型文心(ERNIE)2.0,对比开源数据集训练的预训练模型可以有效全面提升模型效果。
灵活部署方案:提供了公有云 API、本地服务器部署、设备端 SDK、软硬一体产品四大部署方式。在设备端 SDK 上,适配了超过 15 种主流芯片与四大操作系统,实现了业界适配最广。软硬一体产品上,提供 6 款方案,模型识别速度最高达 10 倍提升。
面向 AI 算法开发者的平台——BML
BML 具有以下四个核心优势,建模方式全面、自动搜索调优、灵活交付部署、提供多种国产化的解决方案,为企业提供自主可控广泛适配的 AI 开发平台。
建模方式全面:BML 提供预置模型调参、Notebook、多种框架的代码开发、可视化建模等多种建模方式。
自动搜索调优:BML 提供的自动超参搜索功能是创新基于随机微分方程的无梯度优化的调参算法,收敛速度快,不依赖平滑性假设,并且可以支持大规模的并行搜索调参。在开启自动超参搜索之后,BML 线上多场景的模型精度平均可提升 10%以上。
灵活交付部署:BML 有四种满足不同需求的交付方式,包括公有云、私有云、混合云、一体机。
国产化的解决方案:BML 全面支持从国产深度学习框架飞桨,到麒麟等国产操作系统,再到国产 CPU 和 GPU 以及长城、曙光、联想、浪潮推出的各类硬件形态,构成了自主可控、适配广泛的 BML 一体机,高性价比的算力资源满足各类算力需求。

从全球架构师峰会上百度技术专家的分享可以看出,作为拥有强大互联网基础的领先 AI 公司,百度正不断突破关键技术,开源开放,生态共建,推动企业赢得产业智能化大势商机。随着 AI 业务的需求量、应用场景增多,未来在飞桨这类深度学习平台的作用下智能经济时代也将加速而来。




