

微服务架构是互联网很热门的话题,是互联网技术发展的必然结果。它提倡将单一应用程序划分成一组小的服务,服务之间互相协调、互相配合,形成分布式调用,为用户提供最终价值。然而微服务概念提出者 Martin Fowler 却做了这样的强调“分布式调用的第一原则就是不要分布式”。这二者之间看似确实是矛盾体,那么在业务和用户高速发展的时候,到底要不要做微服务呢?其实答案很简单:“不痛就不要微服务”,所谓的“痛”表示着在项目开发过程中已经有东西已经阻碍了项目的正常推进。
在传统的软件开发中会经常会遇到这样的“痛”:
1、代码冲突加剧
多个人或者一个团队一起维护一个模块,共同开发。当提交代码的时候发现大量冲突,每次提测或者发版的时候需要花大量的时间来解决冲突。随着团队规模的增大以及项目复杂程度增加,代码冲突的现象越严重;
2、模块耦合严重
模块之间通过接口或者 DB 相互依赖,耦合越来越严重。而且不同的人,写代码的风格不一样,代码质量也不一样,上线前需要协调多个团队,任何小模块的异常都会导致整个项目发布失败;
3、项目质量下降
由于所有的代码都是在一个服务里面,做一次改动,可能会牵一发而动全身,代码冲突以及耦合严重,导致测试覆盖范围不充分,经常会出现没有更改的模块在线上突然出现问题,查询后发现是由于工程师不小心做了某种改动,但是测试用例并没有覆盖;
4、团队效率下降
由于大量时间在处理代码冲突,消耗了研发人员大量的时间;而测试人员为了提高项目质量,不得不在每次发版之前做全方位的回归测试,本身一次小的迭代结果项目时间却很长。
如果上述的“痛”深深刺痛到了你,那么是时候开始做服务化改造了。将原来耦合在一起的复杂业务拆分为单个服务,规避了原本复杂度无止境的积累,每一个微服务专注于单一功能,并通过定义良好的接口清晰表述服务边界。每个微服务独立部署,当业务迭代时只需要发布相关服务的迭代即可,降低了测试的工作量同时也降低了服务发布的风险。
关于微服务的调用框架先前曾经写过文章做过比较,详见《微服务架构技术路线对比:Dubbo VS Spring Cloud | 争议》,本文将介绍在金融行业如何从 0 开始到 4500W 用户将单体应用迁移到微服务过程。
在金融行业中数据安全性,数据一致性、响应时间短、数据量大,业务逻辑复杂,在内部经过多轮讨论,最后技术选型微服务 RPC 框架选择了 Dubbo 2.6.3 版本,从 2015 年到 2019 年,整体服务的系统架构的演变过程如下:
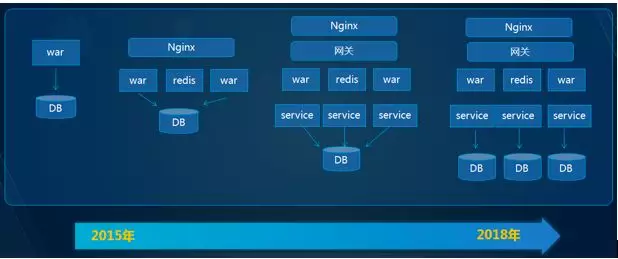
从上图可见,由单体应用演变为微服务的结构,不是一蹴而就而是循序渐进的演变。根据 4 年多服务化改造的经验,微服务改造的步骤如下:
一、单体应用时期
公司处于创业期,讲究需求能快速上线,快速试错,所有的所谓设计模式,高并发、可扩展、容错机制等都不需要考虑。唯一的述求就是快速上线。所以 2015 年的项目架构非常简单,虽然速度快了,但是也暴露出一些问题。

二、负载均衡期
为了解决发版期间不影响投放,支持横向扩展机器,提升系统整体的 TPS。所以引入了 Nginx 做反向代理,session 共享,工程支持横向扩充。这个方案维持了线上一段时间,但是随着功能的逐步迭代,线上质量越来越低,整个团队效率很差。整个工程越来越臃肿,改动任何接口都是小心翼翼 ,因为不知道会不会影响其他模块。

经历了上述阶段后,团队发现必须要拆分功能,需要按业务领域来划分功能,支持分模块来开发、提测、部署上线。于是团队在 2016 年开始启动微服务重构。在做微服务改造的时候,也经历了一些非常痛苦的事情。下面分享下在金融行业微服务改造的流程:
一、统一思想充分培训
微服务实施之前必须先得到高层的支持,给团队传递一个信号,公司全力支持微服务改造,如果不做业务就受阻,公司可能就会死。而不是小范围的试验或者是 demo。再做团队培训,让团队中所有人员了解微服务开发的工作原理,并能熟悉使用。
二、工程结构标准化
当团队开始实时微服务重构的时候,大家按照之前各自负责的模块,从现有代码中剥离开,定义各种接口,相互依赖。看似高效的协作,但是当进入代码 review 阶段的时候发现了问题,每个人的工程结构不一样,代码风格不一样。研发人员在面对之前未接触的功能时候,发现自己是个新人,很难理解代码的业务逻辑。
我们做了一次复盘,最终得出如下的一致意见:需要同一个的工程结构,统一的代码风格,统一的变量命名规范,同时需要定义一些相关术语,以避免小组间沟通产生歧义。
代码未动,工具先行,一个好的工具能够提升团队的开发效率。代码自动生成工具能生成标准项目结构,DTO 对象,PO 和 DTO 之间互转以及生成相关的增删改查。
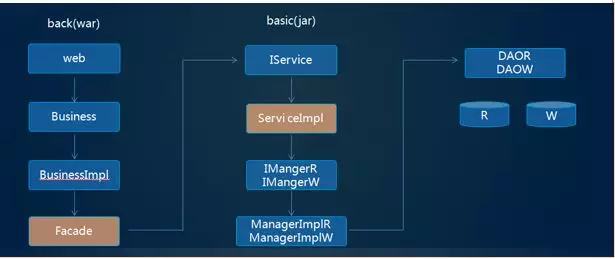
术语约定:统一的术语约定,能降低团队在沟通过程中的歧义。在微服务中聚合层使用 back-工程名称命名,基础服务以 basic-工程名称命名;
1.back-工程名称:业务聚合层,以 war 的方式在容器中运行,提供聚合服务;
2.basic-工程名:基础服务层,以 jar 的方式直接运行,提供原子服务;
任何工程代码结构需要标准化,都具备相同的 module 结构,这样团队中任何人看到相关 module 都知道该 module 所负责的功能;例如以产品 product 为例,涉及的工程结构如下:
back-product(产品服务聚合层)
back-product-business:业务处理层,如果需要调用过多个服务在这里做聚合
back-product-façade:外部服务调用统一出口
back-product-model:定义 VO 相关的字段
back-product-web:接收网关转过来的请求
basic-product(产品基础服务层)
basic-product-api:接口层,外部服务依赖该接口提供的服务;
basic-product-service:接口实现层,实现 api 接口
basic-product- business:数据相关的处理;以及 PO
basic-product- model:定义 DTO 对象
basic-product-façade:如果基础服务调用需要调用外部服务,则统一在此调用。
定义好了 back 和 basic 之后,完整的业务调用逻辑就比较清晰了,如下图:
三、系统拆分
很多团队面临这样的问题,服务到底如何拆分,怎么样的拆分是合理的,拆分后新的微服务框架和老的系统如何做兼容运行,老系统如何逐步平滑过渡到微服务架构中,而且不影响线上业务运行,也不能影响正常的项目迭代。其实,业绩没有标准的方式来指导如何做拆分,我们主要围绕“拆“ 与 ”合“来做服务的拆分,所谓拆就是按业务功能拆分,所谓”合“,就是拆分后的模块经过多次迭代后可以做合并处理。
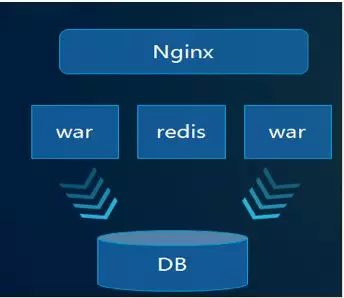
1、服务拆分:好的平台都是逐步演变出来的而不是设计出来的,所以微服务初期最简单的是按业务模块来拆分,比如用户、产品、订单、积分、活动等粗力度来拆分。比如订单服务改动非常的平凡,那么订单服务可以继续拆分,比如历史订单,待支付订单等等;经过多次迭服务拆分后,整体的服务框架如下:

2、session 共享:一般系统都通过判断 session 是否有效来判断用户是否能访问平台,所以新老系统首先要做的就是 session 共享,session 放入分布式缓存中。访问模式如下:
3、功能迁移:增加 Nginx 做反向代理,并在 Nginx 层(或者网关层)做模块的流量切分,例如产品列表接口,切分了 20%的流量到微服务,80%的流量到老的平台。微服务上线后,大部分业务逻辑还是访问老系统,迁移过来的业务逻辑以及新增的业务逻辑访问微服务系统
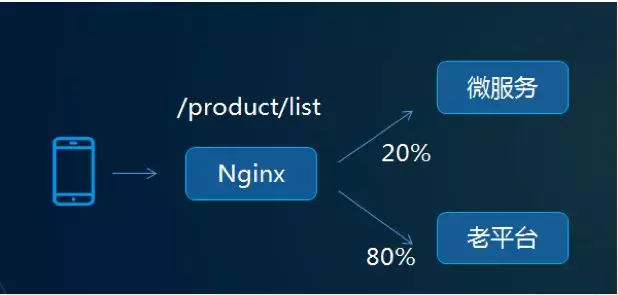
在 Nginx 层做流量拆分
切分比例 2/8 ,5/5,100%
服务化的部分初始阶段和老平台使用相同 DB
新业务迭代优化在微服务上开发,DB 隔离
微服务上线后做好流量切换后的监控
整个微服务的访问流程如下:

四、化串行为并行
我们在打开 APP 产品详情页的时候,大概需要调用后端二十几个服务,且每个服务之间通过 RPC 的方式来调用,初期的时候,由于产品结构简单,详情页调用后端服务比较少,程序员程序员根据以往的经验,串行方式逐个调用服务。但是随着迭代过程的持续,详情页调用后端服务越来越多,响应越来越慢。因为聚合层需要调用多个基础服务,会增加系统的响应时间。最后对于微服务后的产品详情页又做了多次重构,整个重构过程如下:
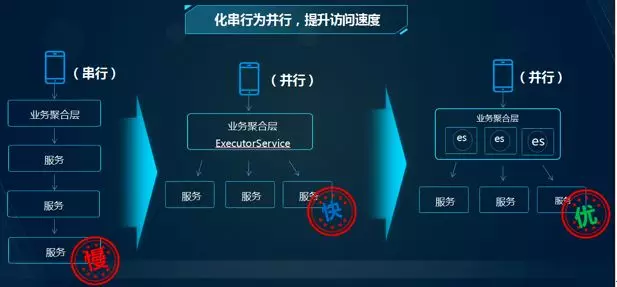
1、线程池并行调用:为了提高接口响应时间,把之前串行调用方式修改为把请求封装为各种 Future 放入线程池并行调用,最后通过 Future 的 get 方法拿到结果。这种方式暂时解决了详情页访问速度的问题,但是运行一段时间后发现在并发量大的时候整个 back-product 服务的 tomcat 线程池全部消耗完,出现假死的现象。
2、服务隔离并行调用:由于所有调用外部服务请求都在同一个线程池里面,所以任何一个服务响应慢就会导致 tomcat 线程池不能及时释放,高并发情况下出现假死现象。为解决这个问题,需要把调用外部每个服务独立成每个线程池,线程池满之后直接抛出异常,程序中增加各种异常判断,来解决因为个别服务慢导致的服务假死。
3、线程隔离服务降级:方式 2 似乎解决了问题,但是并没有解决根本问题。响应慢的服务仍然接收到大量请求,最终把基础服务压垮。程序中存在大量判断异常的代码,判断分支太多,考虑不完善接口就会出差。
五、服务熔断降级
在进行服务化拆分之后,应用中原有的本地调用就会变成远程调用,这样就引入了更多的复杂性。比如说服务 A 依赖于服务 B,这个过程中可能会出现网络抖动、网络异常,或者说服务 B 变得不可用或者响应慢时,也会影响到 A 的服务性能,甚至可能会使得服务 A 占满整个线程池,导致这个应用上其它的服务也受影响,从而引发更严重的雪崩效应。所以引入了 Hystrix 做服务熔断和降级;
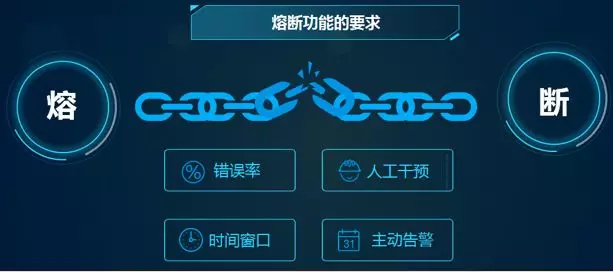
我们针对如下几项做了个性化配置:
错误率:可以设置每个服务错误率到达制定范围后开始熔断或降级;
人工干预:可以人工手动干预,主动触发降级服务;
时间窗口:可配置化来设置熔断或者降级触发的统计时间窗口;
主动告警:当接口熔断之后,需要主动触发短信告知当前熔断的接口信息;
六、服务解耦
虽然服务拆分已经解决了模块之间的耦合,大量的 RPC 调用依然存在高度的耦合,不管是串行调用还是并行调用,都需要把所依赖的服务全部调用一次。但是有些场景不需要同步给出结果的,可以引入 MQ 来降低服务调用之间的耦合。
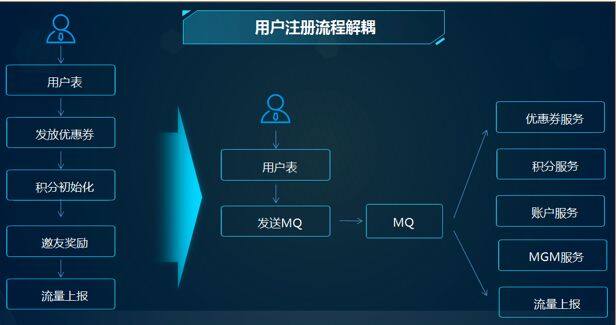
用户完成注册动作后,只需要往 MQ 发送一个注册的通知消息,下游业务如需要依赖注册相关的数据,只需要订阅注册消息的 topic 即可,从而实现了业务的解耦。使用 MQ 的好处包括以下几点:
解耦:用户注册服务只需要关注注册相关的逻辑,简化了用户注册的流程;
可靠投递:消息投递由 MQ 来保障,无需程序来保障必须调用成功;
流量削峰:大流量的新用户注册,只需要新增用户服务,并发流量由 MQ 来做缓冲,消费方通过消费 MQ 来完成业务逻辑;
异步通信(支持同步):由于消息只需要进入 MQ 即可,完成同步转异步的操作;
提高系统吞吐、健壮性:调用链减少了,系统的健壮性和吞吐量提高了;
对于 MQ 做了如下约定:
应用层必须支持消息幂等
支持消息回溯
支持消息重放
消息的消费的机器 IP 以及消息时间
七、缓存
在高并发场景下,需要通过缓存来减少 RPC 的调用次数,减少数据库的压力,使得大量的访问进来能够命中缓存,只有少量的需要到数据库层。由于缓存基于内存,可支持的并发量远远大于基于硬盘的数据库。缓存分本地缓存(基于 JVM 的 CACHE)和远端缓存(如 Redis 或 MemCache),在产品详情页的场景,允许有短暂的数据一致情况,所以使用了本地缓存+远端缓存组合的模式,来降低 RPC 调用次数,网络开销和 DB 的压力。

如果业务聚合层直接访问远端缓存,虽然减少了 RPC 调用次数以及 DB 的压力,但却增加了网络开销,所以调整为先本地缓存,如果没有命中则自动调用后端基础服务,基础服务首先会先用远端缓存,如未命中再查询 DB;
对于缓存做了如下的改动:
使用自定义 @anntation:程序员只需要在需要使用缓存的地方增加一个 @Cache 即可;
本地缓存 TTL:本地缓存的 TTL 时间可以自动配置;
远程缓存 :如本地未命中可直接转发到远端缓存;
自动注册到配置中心 :所有的缓存节点和配置时间都再配置中心可见;
支持手动修改 TTL 时间 :可手动调整每个节点的 TTL 缓存时间;
防止缓存雪崩
八、分布式事务
用户在平台上支付他订购某种业务的时候,需要涉及到支付服务、账户服务、优惠券服务、积分服务,在单体模式下这种业务非常容易实现,通过事务即可完成,伪代码如下:

然而在微服务的情况下,原本通过简单事务处理的却变得非常负责,若引入两阶段提交(2PC)或者补偿事务(TCC)方案则系统的复杂程度会增加。我们的做法是通过本地事务+MQ 消息的方式来解决:
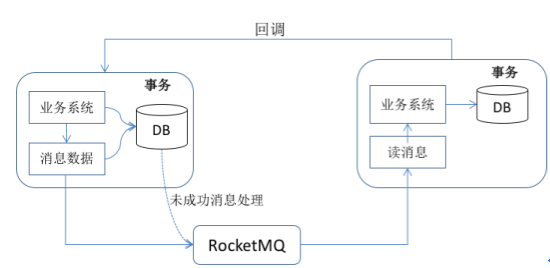
消息上游:需要额外建一个 tc_message 表,并记录消息发送状态。消息表和业务数据在同一个数据库里面,而且要在一个事务里提交。然后消息会经过 MQ 发送到消息的消费方。如果消息发送失败,会进行重试发送;
消息上游:开启定时任务扫描 tc_message 表,如果超过设置的时间没有变更状态,会再次发送消息到 MQ,如重试次数达到上限则发起告警操作;
消息下游:需要处理这个消息,并完成自己的业务逻辑。此时如果本地事务处理成功,表明已经处理成功了,需要发起业务回调通知业务方;
九、安全
暴露在外部的接口有身份认证、验签等步骤可以有效验证用户的合法性,但是服务内部之间的接口调用完全是透明的,无任何验证的。这个对于金融行业来说是不可容忍的,所以基于 Dubbo 的 Filter 机制做了一套认证授权系统。

Consumer:提供一个 ACLFilter,读取给定的用户名和密码,把数据放入 Attaches 中传给 Provier 端;
Provider:提供一个 ACLFilter,验证 Consumer 提交过来的用户名和密码,并验证 IP,访问时间,对于异常访问的 IP 会发出告警信息;
十、持续集成
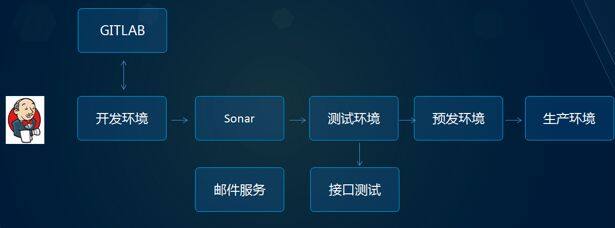
持续集成是微服务的必经过程,即团队开发成员经常集成他们的代码,通常每个成员每天至少集成一次,也就意味着每天可能会发生多次集成。每次集成都通过自动化的构建(包括编译,发布,自动化测试)来验证,从而尽快地发现集成错误。
代码管理用 git 管理,Jenkins 编译打包。每个模块独立一个工程,要求要求每天都提交代码,代码提交之后会进入静态代码扫描 CI 服务,通过 Sonar 服务器进行观察代码是否存在异常的代码;编译发布成功后,会自动触发接口测试功能,对于测试有异常的接口自动邮件通知相关人员。
十一、实战经验
1、线程池满
突然有反馈说服务非常慢,甚至出现异常,通过后台日志查询发现了如下的错误信息“Caused by: java.util.concurrent.RejectedExecutionException: Thread pool is EXHAUSTED! Thread Name: DubboServerHandler-XX.XX.XX.XX:XXXX, Pool Size: 200 (active: 200, core: 200, max: 200, largest: 200)“,因为所有服务设置的都是固定线程池大小,看到这样的错误日志,第一反应就是调整线程池大小,由 200 调整为 500。但是运行一段时间后发现 500 后很快满了,改到 1000 很快又满了,增加服务器后线程池很快又满了,但是服务器的 CPU 和内存使用率都比较低。通过接口压测,又出现不了任何问题,问题似乎陷入僵局。突然运维说线上有大量慢查询 SQL,通过分析这些 SQL 发现都是通过这个异常服务的 SQL 语句。优化掉这些 SQL 后,Dubbo 线程池再也没有出现线程池满的情况。总结:高频调用服务的 SQL 响应时间一定要快,必须增加缓存,同时需要做熔断处理。
2、数据库 CPU 飚高
客服反馈经常在一段时期内系统响应非常慢,阻碍了客户的正常操作。此时观察日志后发现,同时刻后端大量基础服务抛出线程池满的异常。观察 MYSQL 数据库,发现 CPU 飙风到 95%以上。但是当时的访问量并不大,是什么问题导致 CPU 占用如此之高?
运维分析后发现存在一次性将全部用户表的数据拉取出来的情况,当时注册用户量已经达到了 3000W,一旦出现这样的情况必然导致 CPU 高。我们持久层框架选择 MyBatis,SQL 文件类似

如果传入的条件是空或者没有传任何条件,那么必然导致拉取全部数据。所以在内部做了约定,禁止不带条件的查询,并在框架层面做了一层拦截,如果 PO 对象是空那么直接抛出异常。总结:SQL 查询语句禁止不带 where 条件的查询,禁止多表 join 查询,接口调用的 DTO 禁止为 null 或者禁止是一个没有任何数据的 DTO 对象;
3、无止境的循环依赖
由于服务之间通过接口调用,原则只要上发布出来的服务都可以,会形成 A 调用 B,B 也有可能调用 A。本以为只需要在配置端增加 check=“false”,例如
<dubbo:reference interface=“com.****.UserService” check=“false” />就可以解决了问题。但是上线后出现了 RPC 服务死循环般依赖调用,但是服务之间的依赖又是不可避免的,最终约定如下:基础服务(basic)层主要做数据库的操作和一些简单的业务逻辑,不允许调用其他任何服务;
聚合服务(back)层,允许调用基础服务层,完成复杂的业务逻辑聚合操作;不运行调用其他 back 层.
4、接口定义规则
我们的服务端代码 70%通过代码生成器完成,但是另外新增的接口是由业务端开发人员自己编写的,当初未定义规则,出现了 PO 层直接返回到业务聚合层,甚至使用 Json 或者 Map 方式来定义接口,给后续维护带来非常大的困难。约定:
接口数据透传规则:全部按照 PO、DTO、VO 来设计接口,禁止混用,因为数据定义的改变,影响面仅仅在调用方和被调用方,后续升级和扩展更方便;
接口参数类型:禁止 json 格式的参数、禁止 Map 类型的参数;
5、日志格式
微服务初期阶段,没有考虑到日志的打印策略和格式,大部分研发人员还是按照之前的方式来打印日志。当服务器数量增加时,查询线上日志变得非常困难。在启用 ELK 的时候缺发现日志格式无规则可循。约定:不管微服务在什么阶段,必须事先明确约定日志格式,例如:日志类别|所属于模块|业务操作|具体事件|操作人|自定义。有了统一的日志根式,方便后续日志的收集和报警处理。
总结
构建复杂的应用真的是非常困难,单体式的架构更适合轻量级的简单应用。如果你用它来开发复杂应用,那真的会很糟糕。微服务架构模式可以用来构建复杂应用,当然,这种架构模型也有自己的缺点和挑战。
微服务实施过程中会出现各种各样异常信息,对于开发人员和架构师来说都是一种挑战。最后如果能真正成功实施微服务,无非是合理的组织架构、对于项目的认可、工具的合理化、持续集成过程。特别是在金融行业,尤其会关注到性能、准确性、数据一致性等一系列指标。Dubbo RPC 框架的高效、稳定、可扩展这些特点,在整个服务化过程中起到了非常大的作用,线上运行中也一直稳定的提供服务。然而架构的演变是随着业务的演变而演变的,微服务入口层“网关“是整个微服务的最核心层,后续的文章中会介绍下本次架构演变过程中网关的演变历史,会介绍如何搭建一套支持亿级流量的网关。欢迎大家持续关注。
本文转载自技术琐话公众号。
原文链接:https://mp.weixin.qq.com/s/PlIk1OHS0RX9oL_zhxuUSw

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论