
Julia 运行速度很快,但从性能表现上看,也没快的那么离谱。
几周前,当我在 YouTube 上刷编程趣闻时,无意中看到一个视频,它展示了 C++ 和 Python 从 0 加到 10 亿时的性能差异。不出所料,Python 在执行此操作过程中不是非常快,耗时 1m52s,C++ 耗时 2.4s,但我很想看看 Julia 执行效果是什么样子。
接着,我开始写一些简单的 Julia 代码,来运行这个基准测试,以此看看 Julia 是否比 C++ 还快,是否能碾压 Python 很多(虽然这不是一个专业性的对比实验,但仍然可以作为一个有趣的参考指标)。
我使用的 Python 代码跟 YouTube 视频中的几乎一样,把它运行起来也比较简单:
>>> import time>>> def count():... start = time.perf_counter()... n = 0... while n < 1000000000:... n += 1... print(f"Completed Execution in {time.perf_counter() - start} seconds")... >>> count()Completed Execution in 44.67635616599998 seconds如您所见,我使用 Python 代码,整个计算过程花了惊人的 44.67 秒,这个结果比视频中的运行时间快了很多,但这可能是由于很多其它原因导致的,比如我电脑 CPU 等硬件差异。
实现相同功能的 Julia 代码,与 Python 的代码比较相似,只需做一些小的改动。
julia> function count() n = 0 while n < 1000000000 n +=1 end endjulia> using BenchmarkToolsjulia> @benchmark count()BenchmarkTools.Trial: 10000 samples with 1000 evaluations. Range (min … max): 1.167 ns … 10.584 ns ┊ GC (min … max): 0.00% … 0.00% Time (median): 1.250 ns ┊ GC (median): 0.00% Time (mean ± σ): 1.261 ns ± 0.222 ns ┊ GC (mean ± σ): 0.00% ± 0.00%我相信,你肯定也跟我一样,刚开始也为这个结果大吃了一惊。这段 Julia 代码只花了 1.25 纳秒。这样的结果好的令人难以置信,它比 Python 代码快了近 34,000,000,000 倍。
一个小小的区别是,这个函数目前还没有返回 n 的值。但是即便我们加上返回值,整体运行时间也基本维持在 2.0 纳秒左右。
另外,如果在 print 语句中打印出结果,这个时间花费接近~ 33.084 微秒,这明显影响很小。
1 evaluation. Range (min … max): 25.333 μs … 79.291 μs ┊ GC (min … max): 0.00% … 0.00% Time (median): 33.084 μs ┊ GC (median): 0.00% Time (mean ± σ): 37.645 μs ± 9.828 μs ┊ GC (mean ± σ): 0.00% ± 0.00%我知道这样难以置信的效果应该不是真实的,之后我没有去 Julia slack 而是直接到 Julia 社区寻求帮助,很快我便得到了一些有效反馈,Mosè Giordano 建议使用 @code_llvm 来分析下 LLVM,看看在底层创建了什么(LLVM 是 Julia 的编译器)。
确实,之后 Julia 编译器在这个例子中发挥了关键性的作用:
julia> @code_llvm count(); @ REPL[7]:1 within `count`define i64 @julia_count_868() #0 {top:; @ REPL[7]:6 within `count` ret i64 1000000000}如您所见,编译器完全移除了循环,并选择立即返回 10 亿的值。作为一个对编译器基本一无所知的人(我也期望我能有更多的了解),这种操作着实让我大吃一惊。我写这篇文章的目的也是为了防止其他人在自己的代码中发现类似的误导性基准。
在这种情况下,该函数没有足够的计算复杂度,无法与 Python 版本进行充分比较。
如果想了解 Julia 的真实速度性能,Mosè有一个不错的帖子,它对 Julia 的速度神话提出了挑战,我强烈建议你去看看:
Julia 如何做基准测试
在 Julia 社区,基准测试是个热门话题,因此有相当多的文档资源。我强烈建议您通读 BenchmarkTools.j1 文档,有很多实践案例可以查看:
https://juliaci.github.io/BenchmarkTools.jl/stable/manual/
最简单的,你可以使用 @benchmark 宏对任何函数进行基准测试(提示——基准测试会“打印”代码,如下所示,可能会导致很多东西打印在你的屏幕上):
julia> @benchmark print("Hello world") Range (min … max): 25.125 μs … 87.625 μs ┊ GC (min … max): 0.00% … 0.00% Time (median): 32.792 μs ┊ GC (median): 0.00% Time (mean ± σ): 37.638 μs ± 10.026 μs ┊ GC (mean ± σ): 0.00% ± 0.00% ▁▃▆██▆▄▂ ▁ ▂▅▇█████████▇▆▅▅▅▄▄▃▃▂▂▂▂▂▂▃▃▃▅▆▄▄▅▄▃▂▂▂▃▃▄▆█▇▆▅▃▃▃▄▃▂▂▂▁▁▁ ▃ 25.1 μs Histogram: frequency by time 59.6 μs < Memory estimate: 48 bytes, allocs estimate: 2.你也许会对 Valentin Churavy 写的关于 Julia 性能的 notebook 程序感兴趣,可以通过它更好的理解 Julia 性能。Valentin 是 Julia 的长期贡献者,在这个领域有很大的权威性。
Valentin 是一个有智慧的人,这里分享下他在 Julia slack 说过的一段话:
基准测试是困难的,你首先需要确保度量的是真实的东西™
使用 Julia 可以带来哪些方面的性能改善呢?
虽然关于 Julia 的性能有很多夸大和错误引导的文章,但使用 Julia,比起 Python 和 Matlab 等语言,在多数情况下我们还是能获得比较大的性能提升。
2022 年 4 月,SciML 团队在 Julia 博客上发表了一篇关于在 Julia 中使用小型网络进行科学机器学习的文章。他们将其性能与 PyTorch 的等效性能进行了比较,并在此基础上获得了 5 倍的速度提高。虽然 PyTorch 通常是同类中最好的工具,但该文章强调,当您想将科学计算结合到您的深度学习(DL)工作流程中时,Julia 在深度学习(DL)领域确实具有较好的效果。你可以在这里阅读全文:

我们来看几个其他的例子:
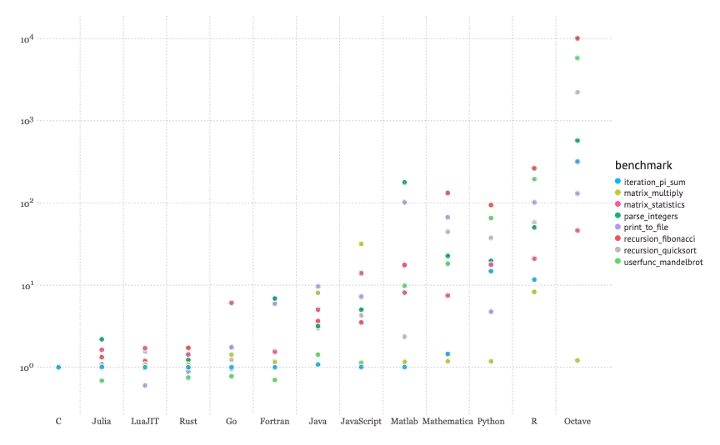
图片来自 julialang.org
上图标识了几种基本操作及其在每种语言中的速度。该基准测试位于于:
https://julialang.org/benchmarks/,你可以去了解更多的细节。
Julia 提高速度性能的另一个地方是读取 CSV(大多数数据科学家应该都不愿意承认他们要频繁做这个操作)。下面这篇文章写的非常好,它描述了 Julia 和 CSV.jl 是如何做到比 Python 和 R 快 10-20 倍的。

另一个案例来源于 Pfizer(辉瑞) 公司的团队,他们使用 Julia 将他们的一些模拟速度提高了 175 倍:

为了避免重复造轮子,我想向大家推荐最后一篇关于 Julia 速度性能的文章。在下面这篇文章中,作者介绍了用 Julia 编写的一些基本算法,并将它们的性能与其他语言进行了比较:

如果您有 Julia 代码方面的疑问想要获得帮助,可以到 https://discourse.julialang.org的“General Usage”主题、“Performance”子类别下发帖:https://discourse.julialang.org/c/usage/perf。
英文原文地址:https://juliazoid.com/no-julia-is-not-34-000-000-000-times-faster-than-python-f63e956313d7




