
Pinterest最近将其基于Hadoop的数据平台替换为Moka,这是一个在 AWS EKS 上运行 Spark 的 Kubernetes 原生系统。Moka 实现了容器化作业隔离,支持基于 ARM 的实例,通过 YuniKorn 改进调度,并简化部署,同时降低基础设施成本,提高了数据处理工作负载的效率。
Pinterest 做出了一个战略性决定,从传统的基于Hadoop的架构转型到基于Kubernetes的Spark模型,更好地与现代基础设施实践保持一致。它选择 Kubernetes 是因为它对容器编排和安全性的原生支持,以及它在部署混合实例类型(如 ARM 和 x86)方面的灵活性:
凭借这些需求,我们在 2022 年对在各种平台上运行 Spark 进行了全面评估。我们倾向于 Kubernetes 为中心的框架,因为它们提供了以下优势:基于容器的隔离性和安全性,作为平台的一等公民,易于部署,内置了框架和性能调整选项。
此外,Moka 在传统平台上引入了关键的成本和效率改进。通过利用基于容器的隔离,Pinterest 将具有不同安全要求的工作负载整合到共享集群中,从而减少了对多个集群的需求。
Pinterest 的工程师也承认,“基于容器的系统提供了更强的隔离,允许移除专用但利用率低的 Hadoop 环境,转而在同一 Moka 集群上运行具有不同安全要求的作业。”该平台支持基于ARM的实例和机会式自动扩展,在非高峰时段扩展集群,进一步有助于基础设施成本的节省。
替换 Hadoop 需要重新设计与作业提交、调度、存储和可观测性相关的几个关键组件——“多年来,Hadoop 和 Monarch (Pinterest 的 Hadoop 平台)已经涵盖了大量的功能。构建一个替代方案意味着开发替代品...”。Pinterest 开发了新的服务,如用于作业提交的 Archer,采用Apache YuniKorn进行基于队列的调度,将存储从HDFS迁移到S3,并集成了Apache Celeborn远程混洗服务,以保持大规模的性能。
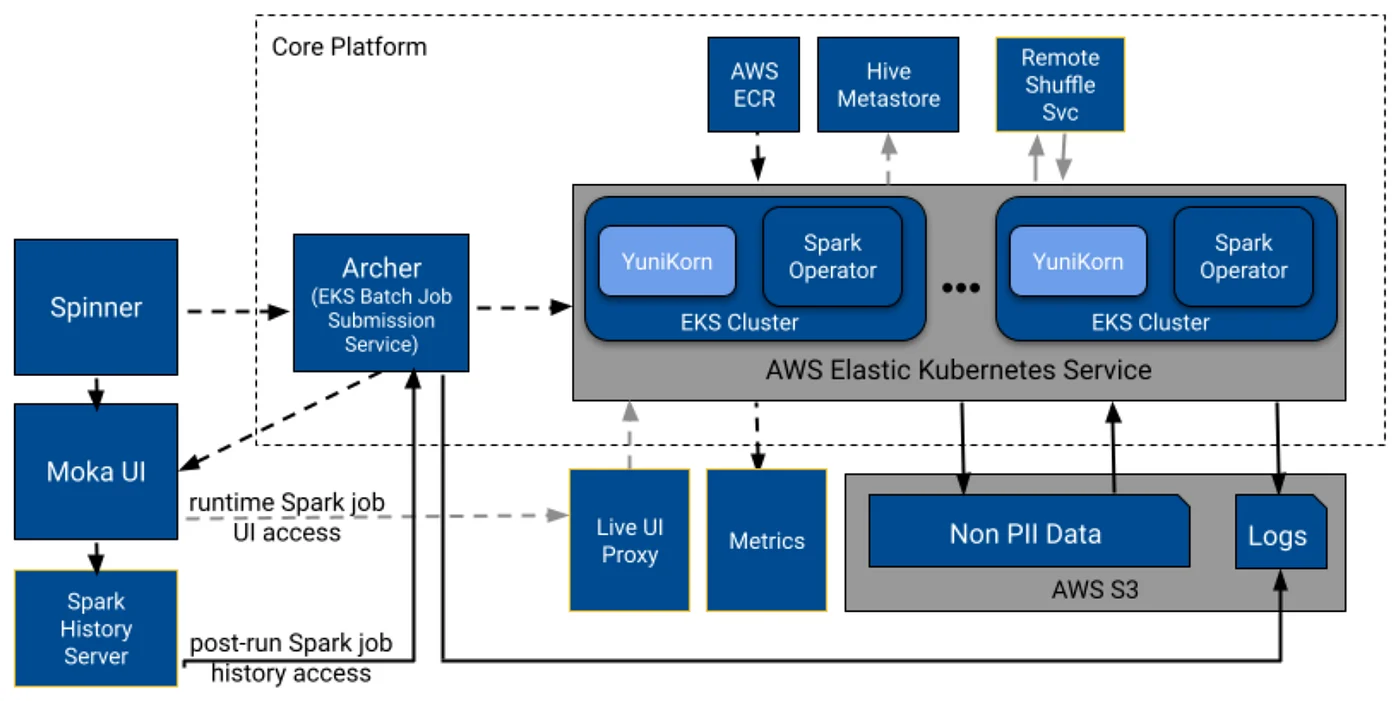
Moka 最初的高级设计(来源)
在 Moka 的初始设计中,Spinner,Pinterest 基于Airflow的编排系统,将计划的工作流程分解为单独的作业提交,并发送给 Archer,即 EKS 作业提交服务。Archer 将每个作业转换为 Kubernetes 自定义资源,并提交给支持 Spark 的 EKS 集群。Archer 处理作业排队、状态跟踪和与 Kubernetes API 的集成,实现跨集群的可靠部署和高效资源路由,同时保持与现有工作流程的兼容性。
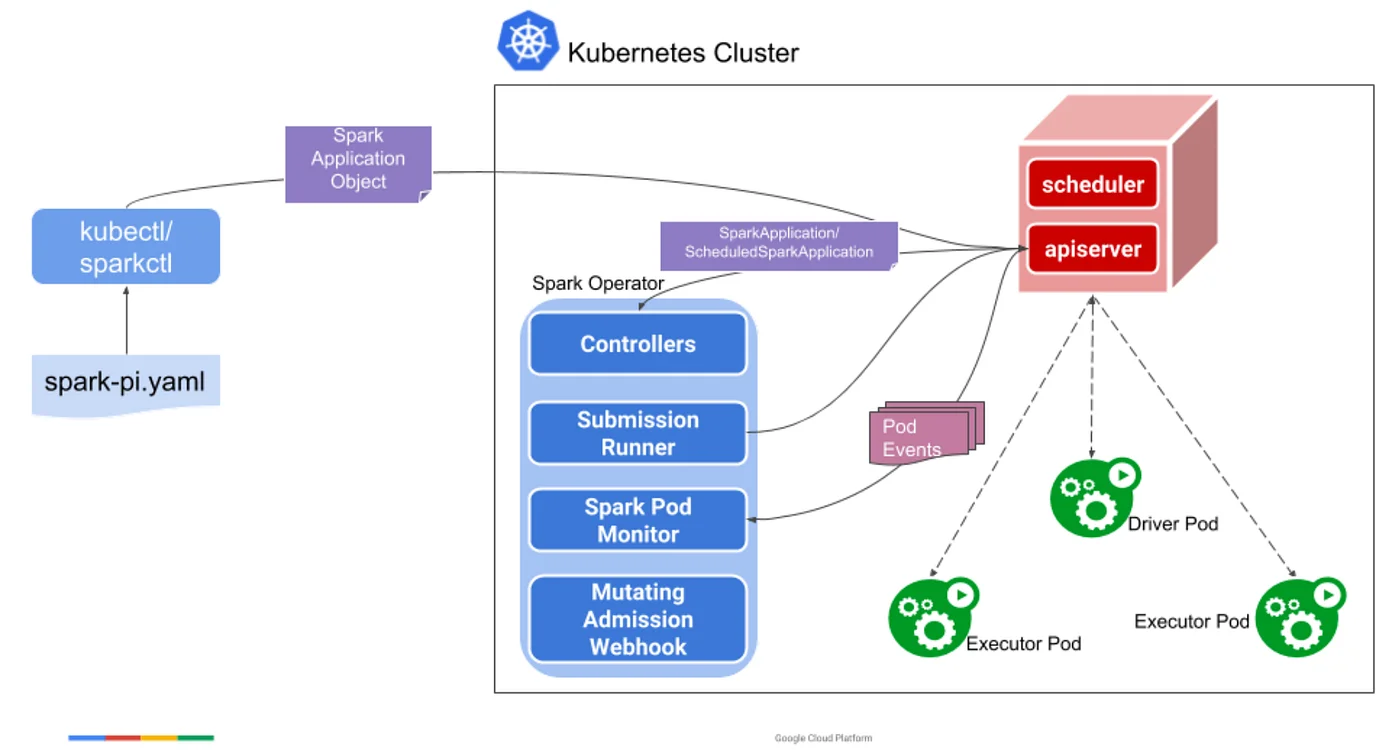
Spark Operator(来源)
Pinterest 的工程师选择使用Spark Operator在 Kubernetes 上原生执行 Spark,并使用 Apache YuniKorn 进行批量调度。Spark Operator 公开了 SparkApplication 自定义资源定义(Custom Resource Definition,CRD),允许以声明方式的定义 Spark 应用程序,并将所有底层提交细节留给 Spark Operator 处理。在内部,Spark Operator 仍然使用原生的 spark-submit 命令。
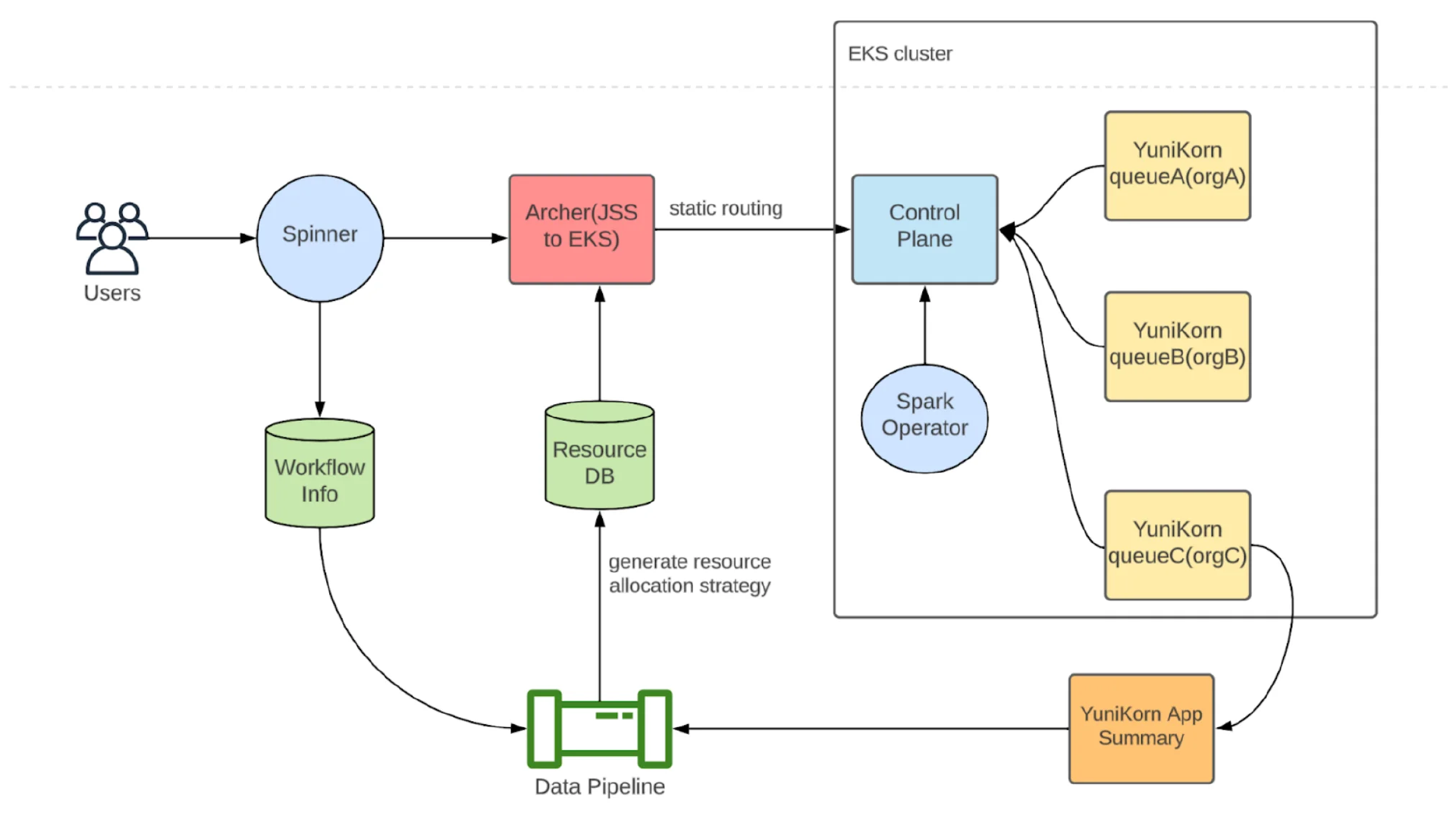
Moka 资源管理(来源)
YuniKorn 提供基于队列的调度、应用程序配额和抢占,并使 Pinterest 能够在团队之间强制执行资源隔离,并根据工作负载层和业务关键性动态调整作业的优先级。
一旦 YuniKorn 调度作业,SparkSQL作业就会连接到Hive Metastore,然后使用来自 AWS ECR 的容器镜像执行工作负载。在执行过程中,Archer 跟踪作业状态,系统将日志上传到 S3,将指标上传到内部仪表板。用户可以通过网络代理访问正在运行的作业 UI,也可以通过 Spark History Server 检索历史日志,所有这些都可以通过只读的 Moka UI 呈现出来。
原文链接:
https://www.infoq.com/news/2025/07/pinterest-spark-kubernetes/




