AIBrix 项目作为大模型推理的可扩展且高性价比的技术方案,项目于 2025 年 2 月 21 日正式开源,并通过 vLLM 官方博客官宣 ,为 vLLM 推理引擎提供可扩展且高性价比的控制面。开源 72 小时内,AIBrix 收获的 GitHub Star 数已超 1K, 96 小时突破 2K,开源一周左右,AIBrix 保持在 GitHub trending榜第一的位置。目前 GitHub Star 已超过 3.6K,贡献者接近 50 人。
2025 年 5 月 21 日,AIBrix 发布 0.3.0 版本,本文是官方博客文章“AIBrix v0.3.0 Release: KVCache Offloading, Prefix Cache, Fairness Routing, and Benchmarking Tools”的中文翻译。
0.3.0 博客原文: https://aibrix.github.io/posts/2025-05-21-v0.3.0-release/
AIBrix 技术详解博客:https://aibrix.github.io/
项目 GitHub 代码仓库:https://github.com/vllm-project/aibrix
AIBrix 是一款模块化、云原生的 AI 基础设施工具包,专为构建可扩展且经济高效的大语言模型(LLM)推理系统而设计。随着生产环境对内存高效、低延迟 LLM 服务的需求持续增长,我们正式发布 AIBrix v0.3.0 版本。本次升级包含三大架构革新——KV 缓存卸载系统、更智能的前缀缓存及负载感知路由策略、可复现的性能评估框架,以及全面的稳定性提升。
本次版本更新重点解决 LLM 推理系统的三大核心挑战:
高效多级 KV 缓存机制, 实现跨推理引擎的 token 级复用
智能流量调度体系, 确保公平、低延迟的流量分发
可复现的评估框架, 基于真实工作负载轨迹的测试框架
我们引入了完全集成的分布式 KV 缓存卸载系统、自适应路由逻辑和基准测试框架。控制平面和数据平面均已重构,以满足生产就绪性和可扩展性要求。
1. 最新功能
1.1 多层 KV 缓存卸载系统
在 AIBrix v0.2.0 版本中,我们首次通过集成 Vineyard 并对 vLLM 进行实验性修改,引入了分布式 KV 缓存功能。这一早期设计旨在解决 LLM 推理中的关键瓶颈:随着模型规模和上下文长度的增长,KV 缓存对 GPU 内存的占用日益增加,严重限制了系统可扩展性。然而 v0.2.0 存在显著局限——vLLM 的 KVConnector 接口刚被合并到上游代码库,我们尚未有机会充分利用该接口,也未能构建专为 LLM 工作负载优化的缓存服务器。与此同时,Dynamo、MoonCake 和 LMCache 等系统探索了将 KV 缓存卸载到 CPU、SSD 或远程内存的方案,但它们的分层设计仍不完善或存在限制:Dynamo 缺乏完整实现,其他解决方案采用低效的淘汰策略,内存分配效率无法满足需求等。
AIBrix v0.3.0 弥补了这些缺陷,推出了生产可用的 KV 缓存卸载框架,支持高效的内存分层和低开销的跨引擎复用。默认情况下,该框架采用基于 DRAM 的 L1 缓存,通过最小化延迟影响来减轻 GPU 内存压力,已能提供显著的性能提升。对于需要多节点共享或大规模复用的场景,用户可选择性启用 L2 远程缓存,解锁分布式 KV 缓存层的优势。本次发布还首次引入了 InfiniStore(https://github.com/bytedance/infinistore) —— 由字节跳动开发的高性能基于 RDMA 的 KV 缓存服务器, 专为 LLM 推理工作负载的大规模、低延迟、多层 KV 缓存需求而构建。
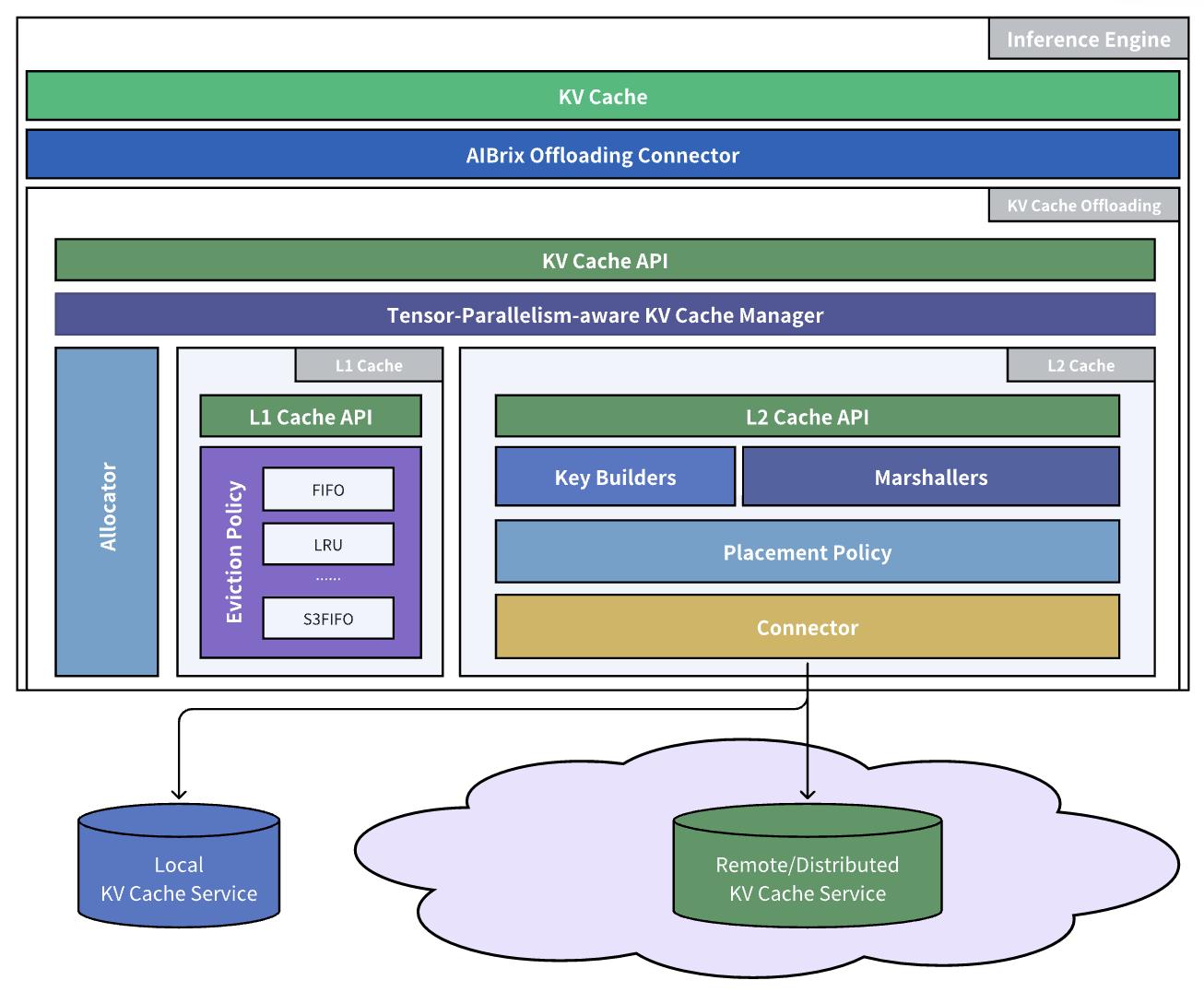
在数据平面,AIBrix 通过 AIBrixOffloadingConnector(AIBrix 卸载连接器) 直接与 vLLM 集成——这是一个专为 GPU 与 CPU 间高效数据传输设计的高性能桥梁。该连接器采用优化的 CUDA 内核来加速 KV 张量传输,最大限度减少关键推理路径上的开销。为了突破 GPU 内存限制,卸载框架配备了多层缓存管理器,能够动态地将 KV 数据分布在包括 DRAM 和 RDMA 互连后端在内的存储层级中。这使得系统能够在不牺牲批处理规模或延迟的情况下处理大型会话和长提示词。AIBrix KV 缓存连接器支持可插拔的淘汰策略(如 LRU、S3FIFO)和灵活的后端(如 InfiniStore, HPKV),以适应不同的工作负载模式和硬件环境。
此外,我们还重构了现有的 KVCache CRD 以支持 InfiniStore 等新后端,从而提供更广泛的兼容性和部署灵活性。AIBrix 现在利用通过一致性哈希环组织的多个缓存服务器,使推理引擎能够无缝与分布式 KV 节点通信。这一特性与内置的缓存放置模块及全局集群管理器的协调相结合,实现了跨引擎的 KV 重用——将原先孤立的缓存转变为统一共享的 KV 基础设施。
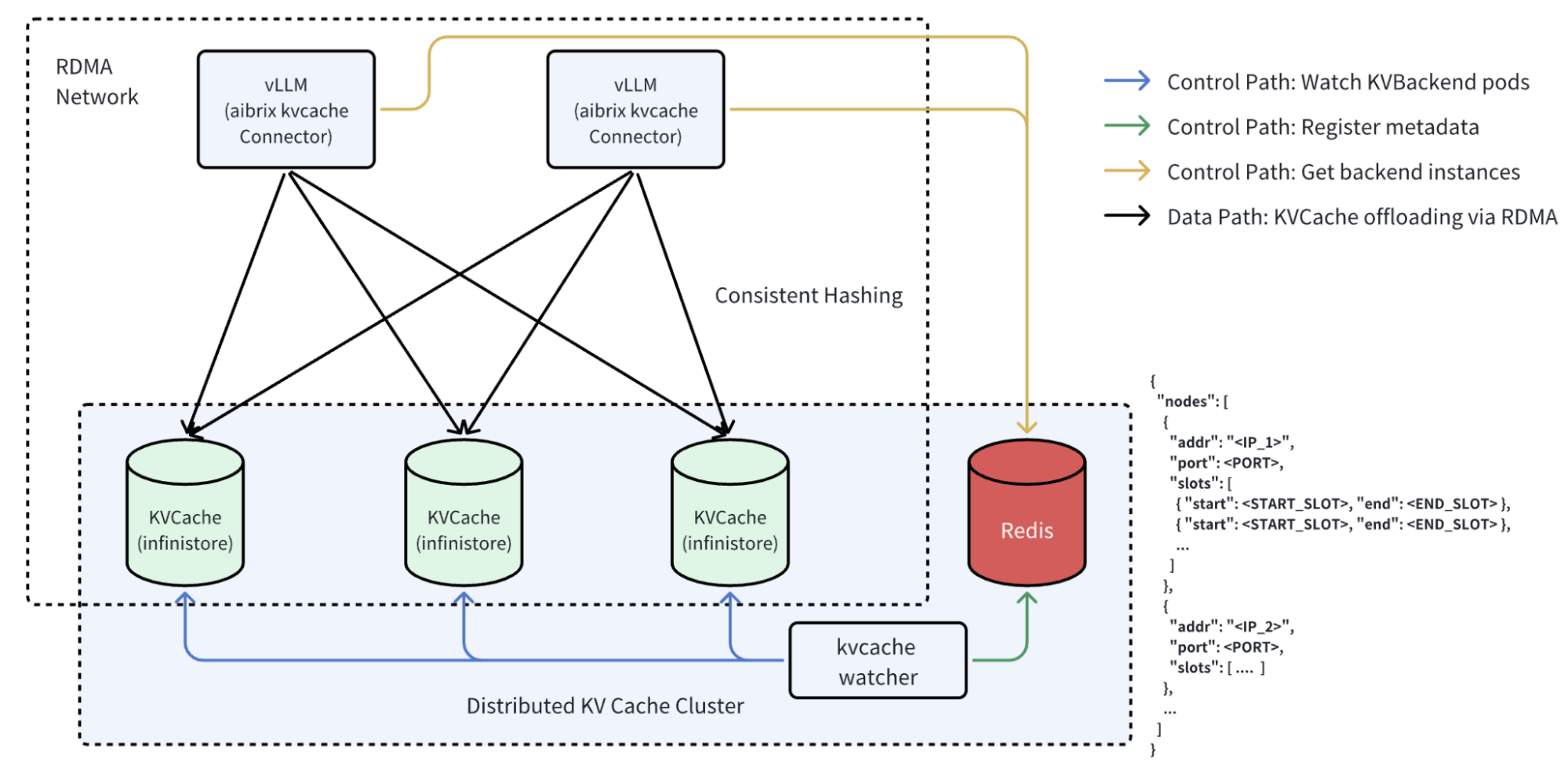
该架构不仅提高了 token 复用率和系统吞吐量,还降低了 GPU 内存压力,使得大规模可靠部署大型模型变得更加容易。以下是我们进行的基准测试结果。我们的基准测试涵盖两种场景:
场景 1 模拟了我们内部某个生产系统的工作负载模式;
场景 2 模拟了多轮对话应用的工作负载模式。
对于场景 1,我们基于从内部生产系统观察到的实际使用模式构建了两个工作负载(即 Workload-1 和 Workload-2)。这两个工作负载保持相同的共享特性但具有不同的规模。Workload-1 中的所有独特请求都可以放入 GPU KV 缓存,而 Workload-2 将独特请求的内存占用扩大到 8 倍,模拟缓存争用严重的容量受限用例。请注意,工作负载生成配置和复现这些基准测试的步骤将很快在AIBrix代码库中发布。
图 1 和表 1 展示了所有系统(Cache-X 是社区中另一个 KV 缓存卸载系统)在 Workload-1 下的性能结果。与其他系统相比,AIBrix 显示出更优的 TTFT(首 token 时间)性能,特别是在 QPS 增加的情况下。AIBrix L1 和 AIBrix + InfiniStore 在所有负载级别下都能实现亚秒级的 P99 TTFT。对于 Workload-2,如图 2 和表 2 所示,由于 InfiniStore 的低延迟访问和大容量特性,AIBrix + InfiniStore 在所有负载条件下都继续保持数量级优势的 TTFT 表现。
图 1: 不同 QPS 下的平均首 token 时延(秒)- Workload-1
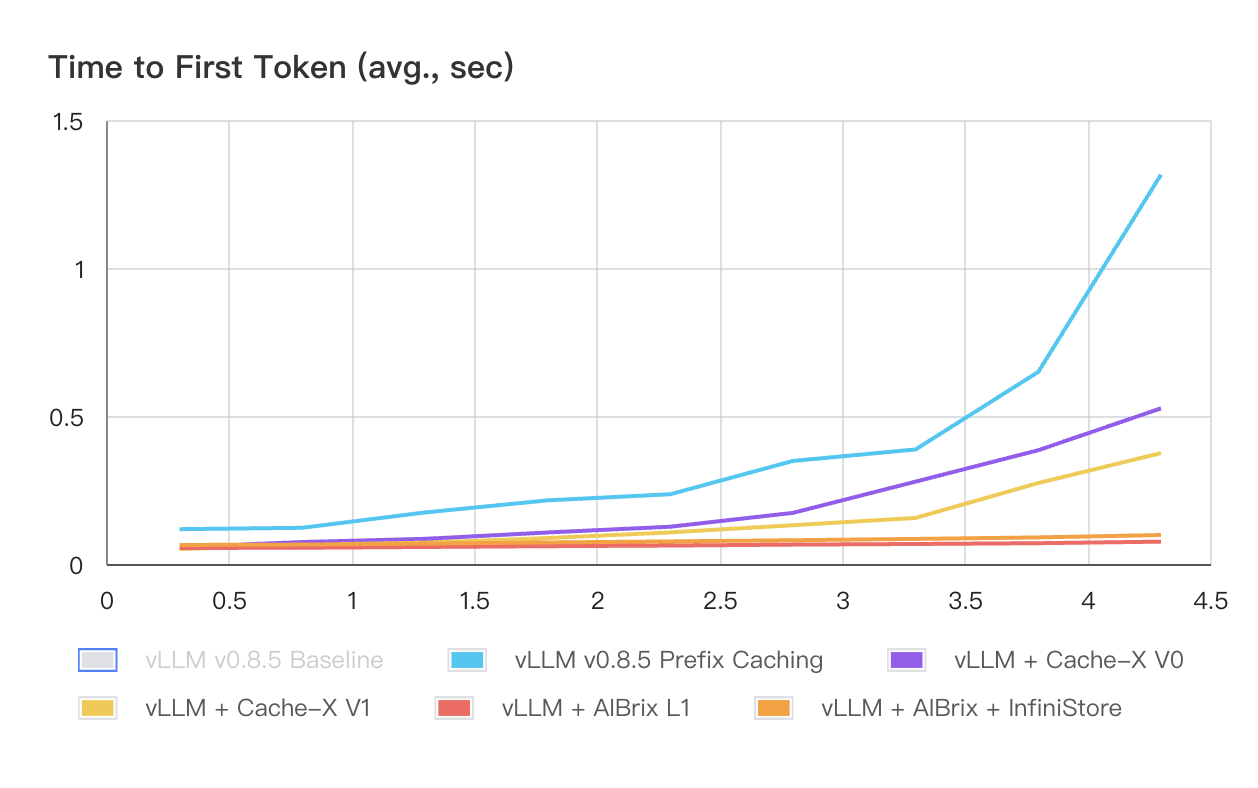
注意: vLLM 基线不包括在此图表中,因为其性能明显差于其他系统,导致在此规模下难以区分它们的曲线。
表 1:点击展开工作负载 1 的 TTFT 表
图 2: 不同 QPS 下的平均首 token 时延(秒)- Workload-2
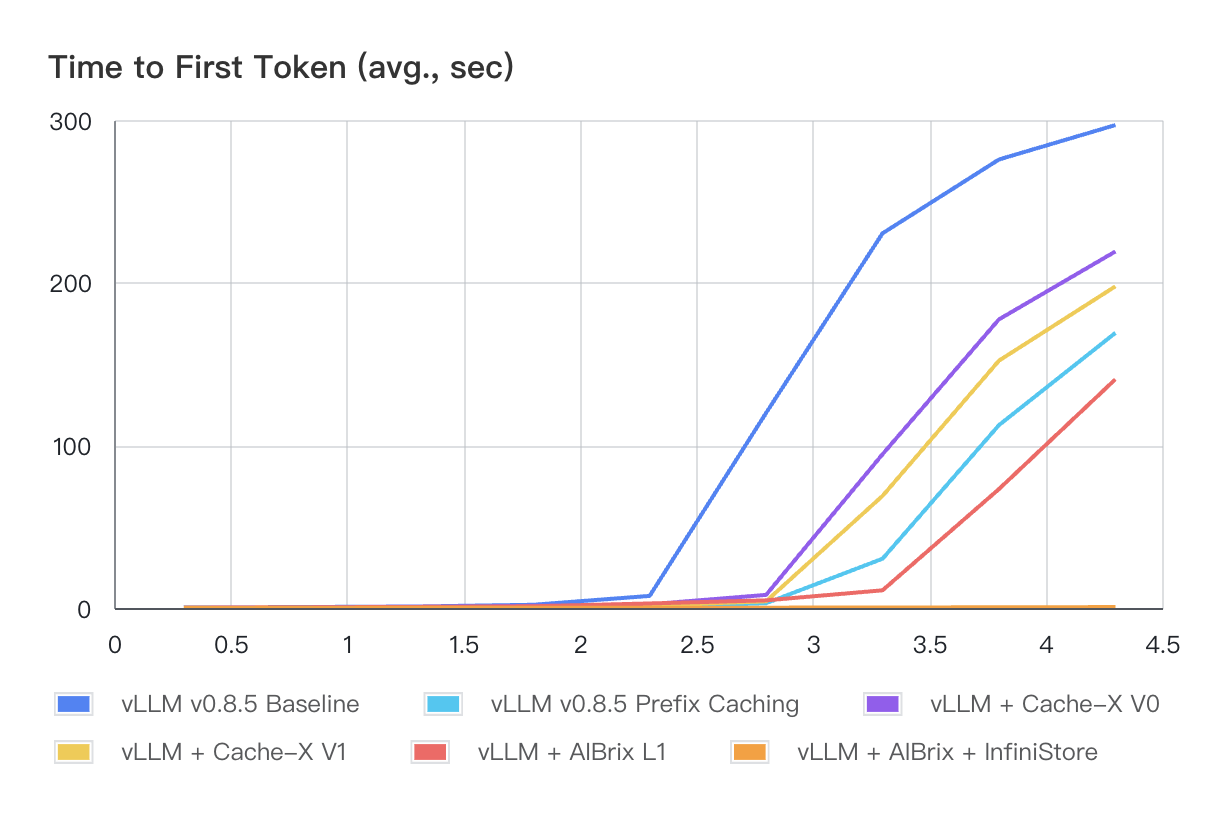
表 2:点击展开工作负载 2 的 TTFT 表
针对场景二,我们构建了一个理论消耗 8 倍 GPU KV 缓存容量的工作负载(即 Workload-3),用以展示 KV 缓存卸载技术在多轮对话应用中的优势。如表 3 所示,性能对比凸显了以下关键发现:
Cache-X V1 版本因实现 I/O 与计算的重叠执行,减少了流水线中的空闲时间("气泡"),其性能优于 V0 版本;
在 AIBrix 方案与 Cache-X 的对比中:
AIBrix L1 达到与 Cache-X V0 相当的基准性能
AIBrix + InfiniStore 凭借更大容量,在所有 QPS 级别均保持最低延迟
AIBrix KVCache 即将在 v0.4.0 版本中支持 vLLM V1 的 KV 连接器,通过进一步压缩 I/O 与计算间的"气泡"时间,实现更优的能效表现。
图 3: 不同 QPS 下的平均首 token 时延(秒)- Workload-3
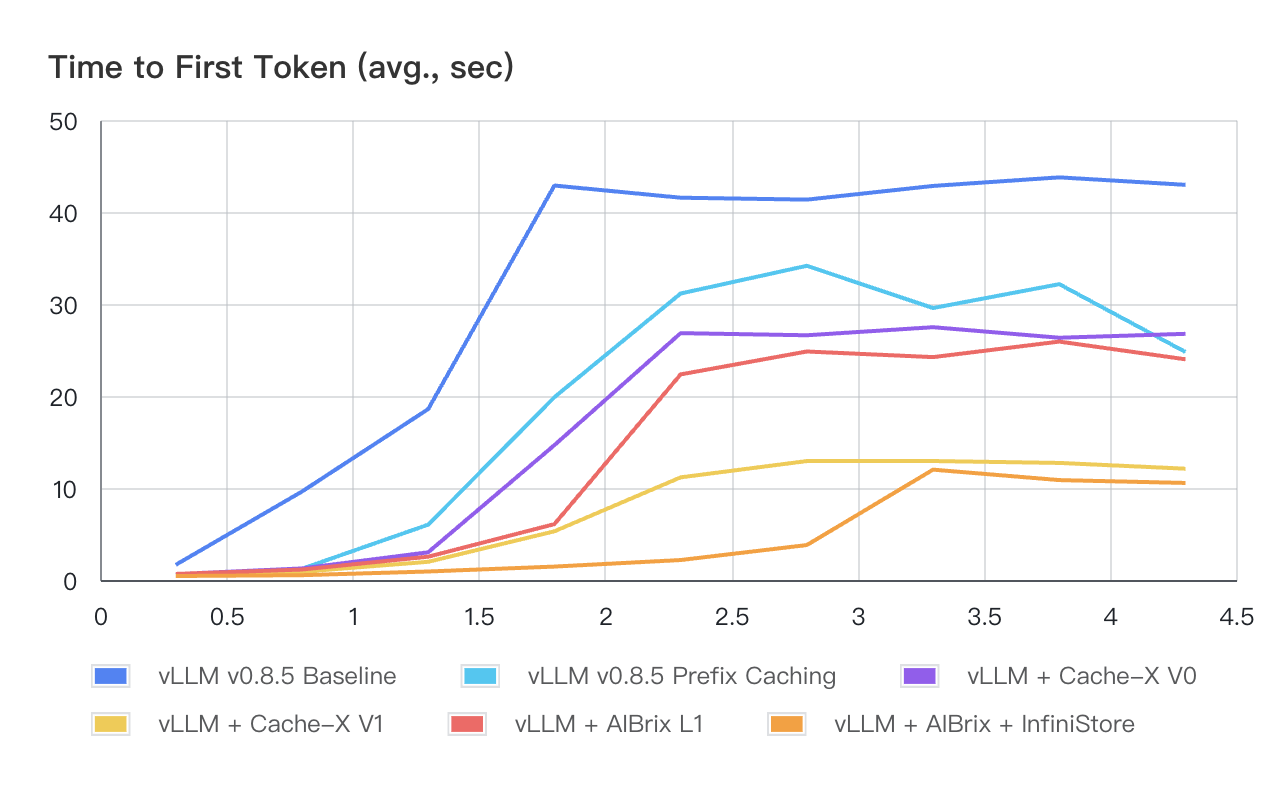
表 3:点击展开工作负载 3 的 TTFT 表
1.2 增强的路由功能
此版本通过智能、自适应的 LLM 服务策略升级了路由逻辑:
前缀感知路由(Prefix-aware Routing):采用基于哈希 token 的前缀匹配技术,结合负载感知机制以降低延迟
Preble 算法实现:基于ICLR'25 Preble论文实现,通过前缀长度分析和提示词感知成本模型,动态平衡 KV 缓存复用与 GPU 计算负载
公平性导向路由(Fairness-oriented Routing):实现OSDI’24 VTC论文方案,引入
vtc-basic路由器,采用窗口自适应公平路由算法,通过动态 token 追踪和自适应 Pod 分配来确保负载公平性
1.2.1 前缀缓存路由
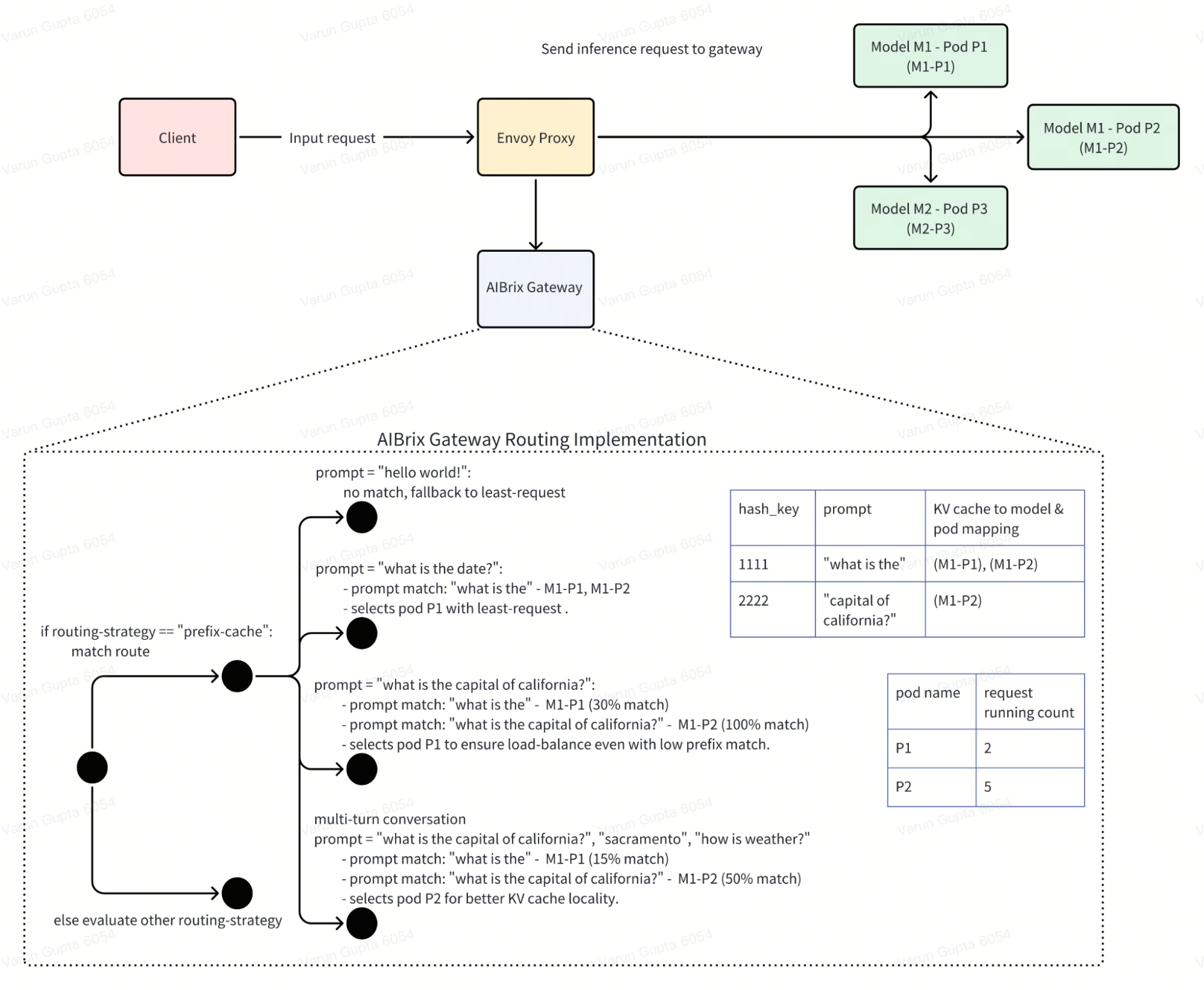
vLLM 等推理引擎提供的前缀缓存功能,可将现有查询的 KV 缓存保存,使新查询若与任一现有查询共享相同前缀时,可直接复用 KV 缓存,从而跳过共享部分的重复计算。为利用此特性,AIBrix 网关引入了前缀缓存感知的路由机制。主要设计如下:
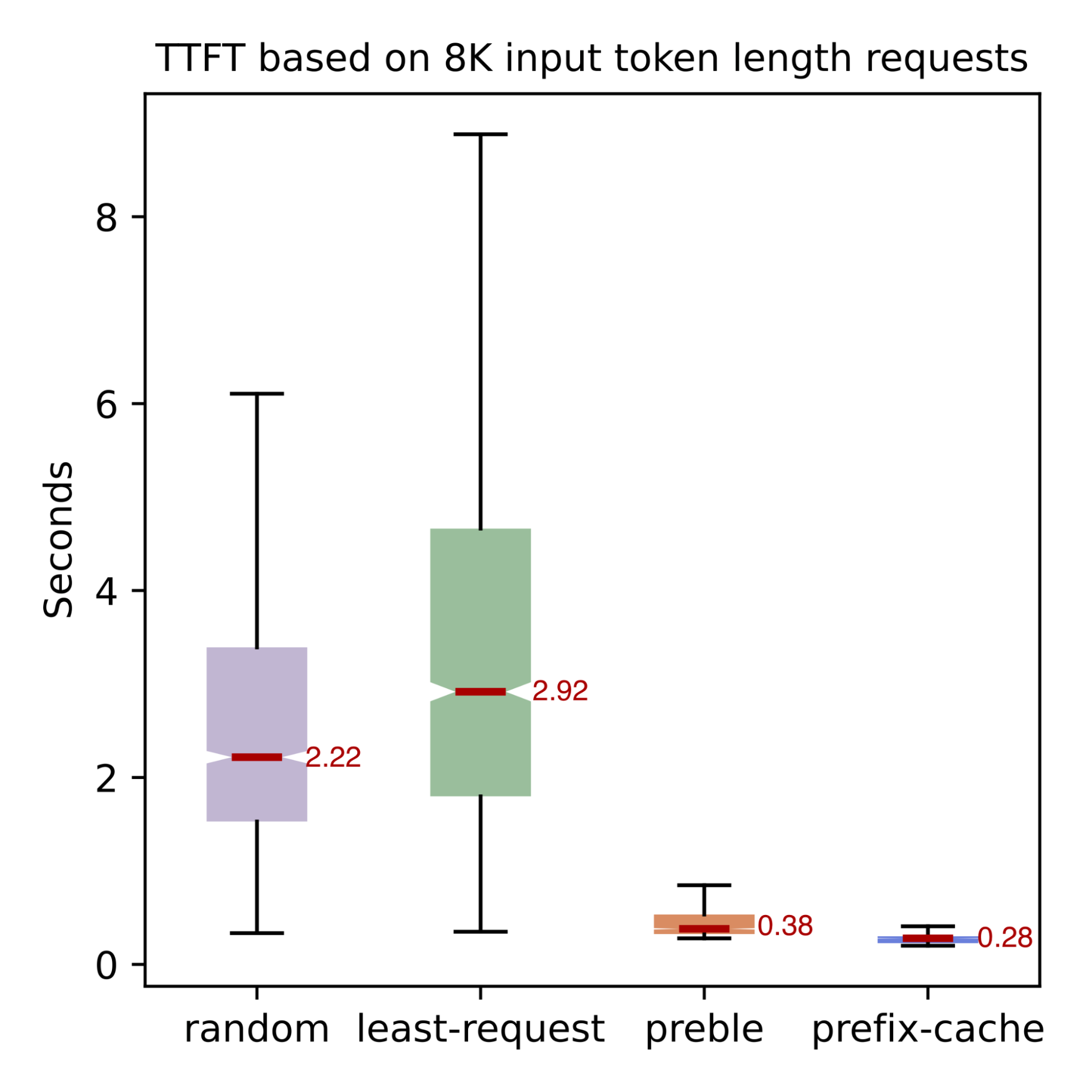
前缀缓存路由在负载均衡时确保不产生热点,即所有共享相同前缀的请求会被智能分配到不同 Pod 上,其目标是在提升前缀缓存共享率的同时避免热点形成(详细设计、具体实现)。实测表明,相比随机路由,采用前缀缓存路由后 TTFT(首 token 延迟)在不同请求模式下平均提升约 45%。
该路由支持多轮对话场景,网关路由器能识别多轮对话请求并高效路由,确保 KV 缓存共享。启用方式为在请求头中添加:"routing-strategy": "prefix-cache"。
1.2.2 基于 Preble 论文的前缀缓存路由实现
Preble 是一种前缀缓存路由策略,专为高效处理具有部分共享前缀的长提示词(long prompt)而设计,可协同优化 KV 缓存复用和计算负载均衡。其核心思想是:当提示词共享前缀时,跨请求缓存和复用已计算的 KV 状态能显著提升性能,但需与系统负载相平衡。具体运作逻辑为:若共享前缀长于提示词的独特后缀,则将请求路由至已缓存最长匹配前缀的 GPU;否则路由至其他 GPU 以平衡负载。
负载均衡方面,当共享前缀部分小于可配置阈值(如 50%)时,会为每个 GPU 计算"提示词感知负载成本",该成本包含三个维度(均以 GPU 计算时间为单位):
历史计算负载:通过时间窗口捕获各 GPU 近期处理活动,反映基准利用率
淘汰成本:评估需要内存时移除缓存 KV 状态的代价,按缓存命中率加权以保护高频使用前缀
处理成本:估算新请求在各 GPU 上的处理开销(重点关注非缓存 token 的预填充时间)
通过综合这三项成本(L+M+P),Preble 将请求分配给总成本最低的 GPU,在即时处理效率与集群长期性能间取得平衡。AIBrix 的 Preble 实现基于原始代码。启用方式为添加请求头:"routing-strategy": "prefix-cache-preble"(当前为实验性功能)。
1.2.3 公平导向路由
虚拟 Token 计数器(VTC)是基于论文《Fairness in Serving Large Language Models》(Sheng 等)的 LLM 服务公平调度算法,通过追踪各客户端已获得的加权 token 服务量,优先服务获得较少服务的客户端以实现公平性。虽然原论文实现针对批处理推理环境,但本次发布的简化版 vtc-basic 更适配 AIBrix 分布式云原生环境的非批处理请求。
vtc-basic 路由器实现窗口自适应公平路由算法,采用窗口化自适应钳位线性方法确保用户间负载公平,包含四个关键组件:
滑动窗口:在可配置时间段内追踪 token 使用量
自适应分桶:根据观测到的 token 模式动态调整分桶大小
钳位 token 值:防止过度敏感和抖动
token 与 Pod 分配的线性映射
通过这些组件,路由器创建混合评分系统,平衡基于标准化用户 token 计数的公平性和基于当前 Pod 负载的利用率,选择综合分数最低的 Pod,确保资源分配公平性和系统利用率。可通过环境变量配置路由器的默认值。启用方式为添加请求头:"routing-strategy": "vtc-basic"(当前为实验性功能)。
1.3 合成基准测试与负载生成框架
现代 LLM 部署面临着不可预测的工作负载、波动的用户会话以及各种各样的提示/生成模式。为了满足这些需求,AIBrix v0.3.0 引入了一个完全模块化、生产级的基准测试工具包,旨在以前所未有的真实性和灵活性评估 AI 推理系统。
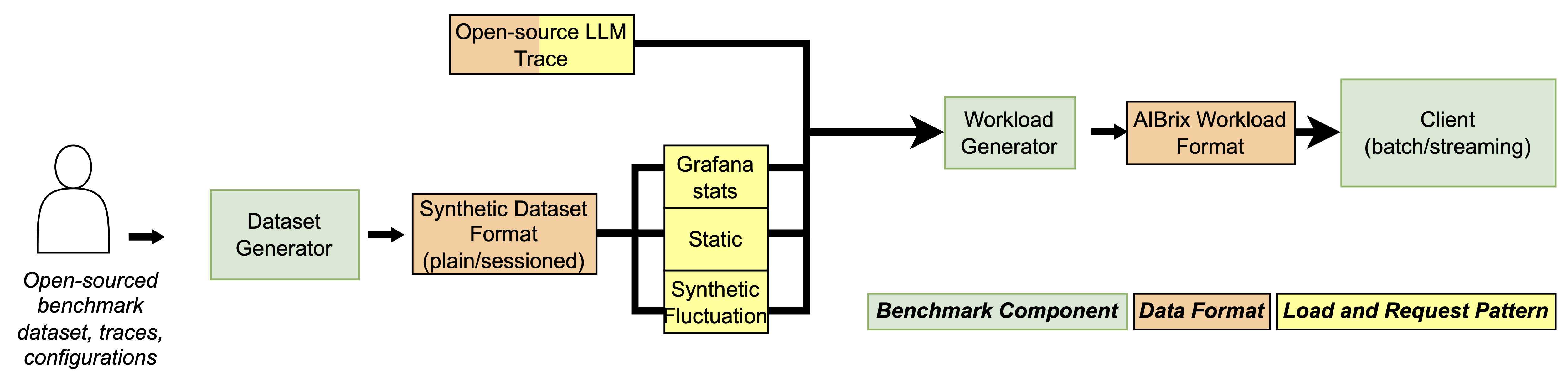
AIBrix 基准测试框架的核心是围绕一个清晰解耦的架构构建的:数据集生成、工作负载塑形和基准测试执行。每个组件均可独立定制,便于接入自定义的提示日志、流量轨迹或实验性工作负载——无论是用于新模型部署、扩缩容策略还是运行时优化。
灵活的数据集生成: AIBrix 支持各种数据集格式——从简单的提示列表到多轮、会话式对话。无论您是生成用于压力测试的综合数据还是转换真实的客户端日志,该工具包都提供四种灵活的模式:
用于研究前缀重用的受控合成共享。
用于对话式工作负载的多轮合成对话。
开放数据集转换(例如 ShareGPT)。
针对特定模型具有完全输入输出控制的客户端日志重放。
每种数据集类型都能无缝接入工作负载生成器,使您能快速迭代提示结构或会话行为。
模拟真实工作负载: 与许多综合或固定模式工具不同,AIBrix 在构建时考虑了真实的推理行为。您可以:
通过控制运行时特征, 例如每秒查询数 (QPS)、提示和生成 token 长度、会话并发量和基于时间的流量分配(如突发负载), 来尝试负载建模。
重放生产环境中的真实跟踪(例如 Azure LLM 轨迹、Grafana 导出的指标)。
使用统计模式模拟动态流量波动
评估基于会话的提示重用,包括具有受控共享前缀长度的场景。
从稳态基线到高突发或多会话模拟,AIBrix 让您能够复现生产流量的复杂现实。
执行、测量和调整: 基准测试客户端支持流式和非流式 API,收集细粒度的延迟指标,例如首 token 时延 (TTFT) 和单输出 token 时间(TPOT)。无论是研究路由行为、KV 缓存后端还是自动扩缩容指标,AIBrix 都能提供将洞察直接转化为生产改进所需的测量工具和灵活性。
2. 现有功能增强
除 KV 缓存卸载、智能路由和基准测试等核心新功能外,AIBrix v0.3.0 还包含多项生产级改进,全面提升全栈稳定性、可扩展性和运维可见性。
2.1 网关增强
支持 OpenAI 兼容 API,包括流式响应、用量报告、异步处理和标准化错误响应,实现端到端无缝集成(#703, #788, #799)
新增
/v1/models端点,兼容 OpenAI 风格 API 客户端(#802)基于可扩展的
ext-proc服务器架构重构 gateway-plugins,为可插拔策略奠定基础 (#810)
2.2 控制平面
为 CRD 添加了 Kubernetes webhook 验证,在资源创建期间提供早期错误反馈 (#748, #786)。
优化 RayClusterFleet 以完整支持 Deepseek-r1/v3 模型 (#789, #826, #835, #914, #954)。
2.3 安装体验
新增 GCP 和 Kubernetes 部署的 Terraform 模块(#823)
文档中新增 Lambda Cloud 和 AWS 上的 Minikube 设置指南 (#1020)
通过引入
kubectl apply支持简化升级流程。CRD 现拆分并通过--server-side方式应用,避免注解大小限制并支持平滑增量更新 (#793)支持发布容器镜像到 Github 容器注册表(GHCR) (#1041)
支持 ARM 容器镜像 (#1090)
2.4 可观察性和稳定性
提供预构建的 Grafana 仪表板,覆盖控制平面、网关和 KV 缓存组件,开箱即用的可观测性 (#1048)
调优 Envoy 代理内存和缓冲区配置,提升高并发下的性能 (#825)
优化 Envoy 代理在高并发下的内存和缓冲区管理配置 (#967)
添加优雅关闭、存活和就绪探针,提升服务弹性 (#962)
为所有主要系统组件提供生产级监控方案 (#1048)
3. 错误修复
本次版本包含 40 余项缺陷修复,重点提升系统健壮性、正确性和生产就绪度。关键修复包括:
OpenAI 和 vLLM 接口兼容性(网关插件):修复了请求/响应头处理、流式 token 使用情况报告和错误传播问题 (#703, #788, #794, #1006)
内部缓存存储和控制器可靠性:解决了陈旧缓存问题、不正确的 informer 设置和控制器清理处理问题 (#763, #925, #926, #937, #938, #981, #1015)
自动扩缩容稳定性:解决了指标获取失败、锁定问题和 HPA 同步正确性问题。(#860, #934, #1039, #1044)
4. 贡献者和社区
v0.3.0 是我们迄今为止协作最紧密的版本,共有 35 位贡献者在控制平面、数据平面、文档和开发者工具等方面做出了多样化改进。
特别感谢以下核心贡献者:
KV 缓存卸载与分布式 KV 编排:@DwyaneShi @Jeffwan
InfiniStore 实现:@thesues @hhzguo @XiaoningDing
路由与网关增强:@varungup90 @gangmuk @Venkat2811 @zhangjyr @Xunzhuo
基准测试工具链:@happyandslow @duli2012
稳定性优化:@googs1025 @Iceber @kerthcet
欢迎首次贡献的新成员:@gaocegege, @eltociear, @terrytangyuan, @jolfr, @Abirdcfly, @pierDipi, @Xunzhuo, @zjd0112, @SongGuyang, @vaaandark, @vie-serendipity, @nurali-techie, @legendtkl, @ronaldosaheki, @nadongjun, @cr7258, @thomasjpfan, @runzhen, @my-git9, @googs1025, @Iceber, @ModiIntel, @Venkat2811, @SuperMohit, @weapons97, @zhixian82
感谢所有贡献者的宝贵付出与反馈,期待更多参与!
5. 后续规划
我们正持续演进 AIBrix 以支持更先进、生产就绪的 LLM 服务能力。v0.4.0 及后续版本的路线图包括:
预填充与解码分离
支持跨设备/节点分离预填充和解码阶段
最大化吞吐量与资源利用率
KV 缓存卸载框架升级
适配 vLLM v1 架构
支持逐层流水线 KV 传输(相比 v0 设计降低延迟、提升并行度)
多租户与隔离
将租户作为一级概念引入
支持租户级模型隔离、请求隔离和细粒度 SLO 控制
批处理推理与请求共置
优化跨异构 GPU 类型的请求路由
提升混合负载场景下的成本效益
敬请期待v0.4.0路线图详情!若您有意贡献新功能或参与方向讨论,欢迎随时联系。
参与贡献:我们欢迎所有形式的协作!
功能建议:留言请到AIBrix Slack 频道, 或 AIBrix 社区技术微信交流群(进群请扫以下 QR 码)