

随着机器学习和深度神经网络两个领域的迅速发展以及智能设备的普及,人脸识别技术正在经历前所未有的发展,关于人脸识别技术讨论从未停歇。目前,人脸识别精度已经超过人眼,同时大规模普及的软硬件基础条件也已具备,应用市场和领域需求很大,基于这项技术的市场发展和具体应用正呈现蓬勃发展态势。
人脸表情识别(facial expression recognition, FER)作为人脸识别技术中的一个重要组成部分,近年来在人机交互、安全、机器人制造、自动化、医疗、通信和驾驶领域得到了广泛的关注,成为学术界和工业界的研究热点。本文将对人脸识别中的表情识别的相关内容做一个较为详细的综述。
1 表情相关概述
1.1 表情定义与分类
“表情”是我们日常生活中提到很多的一个词语,在人际沟通中,人们通过控制自己的面部表情,可以加强沟通效果。人脸表情是传播人类情感信息与协调人际关系的重要方式,据心理学家 A.Mehrabia 的研究表明,在人类的日常交流中,通过语言传递的信息仅占信息总量的 7%,而通过人脸表情传递的信息却达到信息总量的 55%,可以这么说,我们每天都在对外展示自己的表情也在接收别人的表情,那么表情是什么呢?
面部表情是面部肌肉的一个或多个动作或状态的结果。这些运动表达了个体对观察者的情绪状态。面部表情是非语言交际的一种形式。它是表达人类之间的社会信息的主要手段,不过也发生在大多数其他哺乳动物和其他一些动物物种中。
人类的面部表情至少有 21 种,除了常见的高兴、吃惊、悲伤、愤怒、厌恶和恐惧 6 种,还有惊喜(高兴+吃惊)、悲愤(悲伤+愤怒)等 15 种可被区分的复合表情。
表情是人类及其他动物从身体外观投射出的情绪指标,多数指面部肌肉及五官形成的状态,如笑容、怒目等。也包括身体整体表达出的身体语言。一些表情可以准确解释,甚至在不同物种成员之间,愤怒和极端满足是主要的例子。然而,一些表情则难以解释,甚至在熟悉的个体之间,厌恶和恐惧是主要的例子。一般来说,面部各个器官是一个有机整体,协调一致地表达出同一种情感。面部表情是人体(形体)语言的一部分,是一种生理及心理的反应,通常用于传递情感。
1.2 表情的研究
面部表情的研究始于 19 世纪,1872 年,达尔文在他著名的论著《人类和动物的表情(The Expression of the Emotions in Animals and Man,1872)》中就阐述了人的面部表情和动物的面部表情之间的联系和区别。
1971 年,Ekman 和 Friesen 对现代人脸表情识别做了开创性的工作,他们研究了人类的 6 种基本表情(即高兴、悲伤、惊讶、恐惧、愤怒、厌恶),确定识别对象的类别,并系统地建立了有上千幅不同表情的人脸表情图像数据库,细致的描述了每一种表情所对应的面部变化,包括眉毛、眼睛、眼睑、嘴唇等等是如何变化的。
1978 年,Suwa 等人对一段人脸视频动画进行了人脸表情识别的最初尝试,提出了在图像序列中进行面部表情自动分析。
20 世纪 90 年代开始,由 K.Mase 和 A.Pentland 使用光流来判断肌肉运动的主要方向,使用提出的光流法进行面部表情识别之后,自动面部表情识别进入了新的时期。
1.3 微表情
随着对表情研究的深入,学者们将目光聚焦到一种更加细微的表情的研究,即微表情的研究,那么什么是微表情呢?
微表情是心理学名词,是一种人类在试图隐藏某种情感时无意识做出的、短暂的面部表情。他们对应着七种世界通用的情感:厌恶、愤怒、恐惧、悲伤、快乐、惊讶和轻蔑。微表情的持续时间仅为 1/25 秒至 1/5 秒,表达的是一个人试图压抑与隐藏的真正情感。虽然一个下意识的表情可能只持续一瞬间,但有时表达相反的情绪。
微表情具有巨大的商业价值和社会意义。
在美国,针对微表情的研究已经应用到国家安全、司法系统、医学临床和政治选举等领域。在国家安全领域,有些训练有素的恐怖分子等危险人物可能轻易就通过测谎仪的检测,但是通过微表情,一般就可以发现他们虚假表面下的真实表情,并且因为微表情的这种特点,它在司法系统和医学临床上也有着较好的应用。电影制片人导演或者广告制作人等也可以通过人群抽样采集的方法对他们观看宣传片或者广告时候的微表情来预测宣传片或者广告的收益如何。
总之,随着科技的进步和心理学的不断发展,对面部表情的研究将会越来越深入,内容也会越来越丰富,应用也将越来越广泛。
2 表情识别的应用
2.1 在线 API
(1) Microsoft Azure
该 API 包括人脸验证、面部检测、以及表情识别等几部分。对于人脸 API 已集成的表情识别功能,可针对图像上所有面部的一系列表情(如气愤、蔑视、厌恶、恐惧、高兴、没有情绪、悲伤和惊讶)返回置信度,通过 JSON 返回识别结果。可以认为这些情感跨越了文化界限,通常由特定的面部表情传达。
链接:
https://azure.microsoft.com/zh-cn/services/cognitive-services/face/
图 2.1 为人脸 API 识别结果:
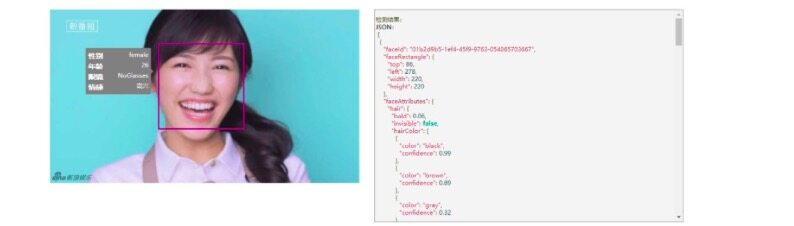
图 2.1 Microsoft Azure 人脸 API 表情识别实际操作示意图
(2) Baidu AI 开放平台(配备微信小程序)
该 API 可以检测图中的人脸,并为人脸标记出边框。检测出人脸后,可对人脸进行分析,获得眼、口、鼻轮廓等 72 个关键点定位准确识别多种人脸属性,如性别,年龄,表情等信息。该技术可适应大角度侧脸,遮挡,模糊,表情变化等各种实际环境。
链接:https://ai.baidu.com/tech/face/detect
图 2.2 为该 API 的功能演示。
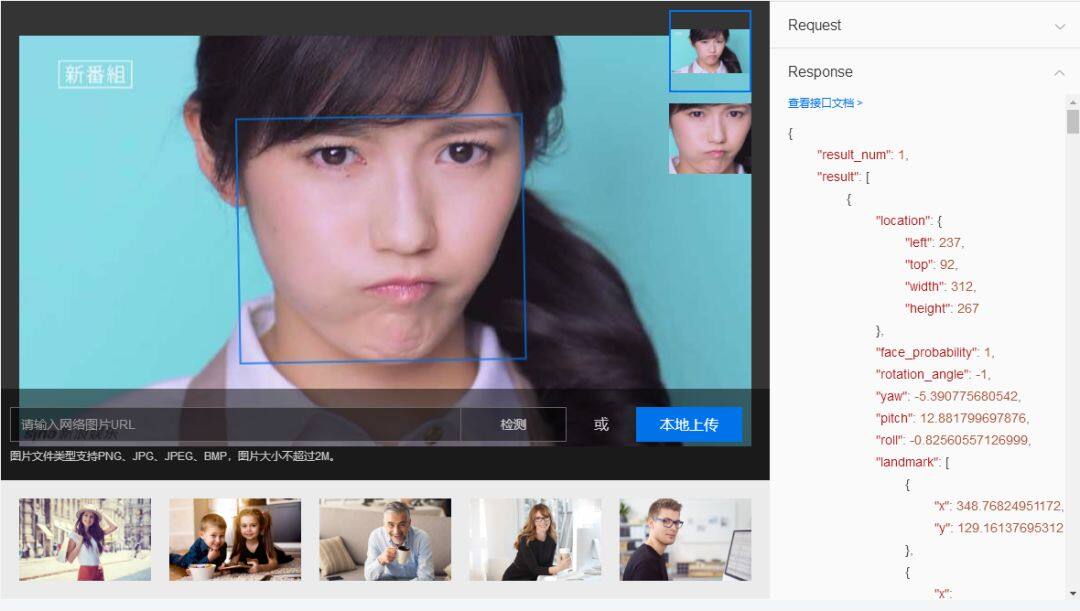
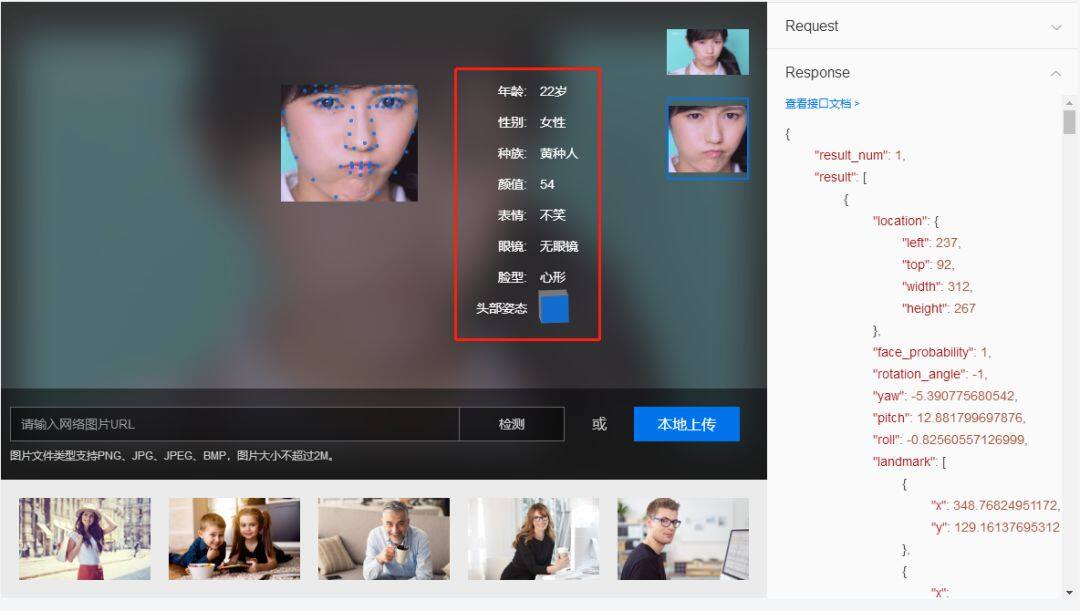
图 2.2 Baidu AI 开放平台人脸 API 的功能演示
(3) 腾讯优图 AI 开放平台(配备微信小程序)
该 API 对于任意一幅给定的图像,采用智能策略对其进行搜索以确定其中是否含有人脸,如果是则返回人脸的位置、大小和属性分析结果。当前支持的人脸属性有:性别、表情(中性、微笑、大笑)、年龄(误差估计小于 5 岁)、是否佩戴眼镜(普通眼镜、墨镜)、是否佩戴帽子、是否佩戴口罩。目前优图人脸检测和分析不仅成熟应用于图片内的人脸颜值分析,检测到人脸时启动相机等娱乐场景,还可通过对图像或视频中的人脸进行检测和计数,能够轻松了解区域内的人流量,并且可以通过对广告受众群体的人脸检测和分析,了解人群的性别、年龄等属性和分布,据此进行更精准匹配的广告投放。
链接:http://youtu.qq.com/#/face-detect
图 2.3 为该 API 的功能演示。


图 2.3 腾讯优图 AI 开放平台人脸 API 的功能演示
2.2 APP
(1) Polygram
微信已经成为了我们生活中必不可少的一部分,社交、转账、支付、购物均可以其为载体,刷微信、刷朋友圈、发段子、斗图成为了我们空闲时间的日常,各种微信表情包成为一大主流。Polygram 与以往的社交软件的方式不同,是一款基于人脸识别的表情包为主要特色的社交软件,加持人脸识别与神经网络技术,它可以使用用户的脸部表情来生成一个 emoji。在这里,用户可以通过人脸识别技术,搜索发送相应表情。Polygram 是一个人工智能动力社会网络,可以理解人脸表情。它以基于人脸识别的表情包为主要特色,即能够利用人脸识别技术,对面部的真实表情进行检测,从而搜索到相应的表情,并发送该表情。当用户在 Polygram 上发布图片或视频时,它非常聪明的是可以使用面部识别技术和手机摄像头,自动捕获用户在社交平台上浏览朋友分享的照片、文字、视频等信息时,脸部出现的真实表情,您将了解您的好友对他们的感受。这是通过模仿面部表情的现场表情符号来完成的,并允许用户对自己的脸部做出反应。

图 2.4 用户在使用 Polygram
(2) 落网 emo
emo,是一款可以识别情绪的音乐 APP,我们总是在掏出手机打开音乐播放器之后,不停的在播放列表中找歌,却难以在存了几百首歌的播放列表中找到此刻想听的,这并非出于执念,只是因为心情。快乐的时候,想听跳跃的歌;悲伤的时候,要放低沉的曲儿;激动的时候,需要激昂的调……每个人都有心情不同的时候,每个人都需要不同的音乐解药。emo 因此而生,解决听歌烦恼,在最适合的时候播放最适合的歌。
在 emo 面前的你,会是最诚实的你,不必掩藏你的心情,愉快便是愉快,悲伤即是悲伤。emo 会通过前置摄像头扫描你的脸,推算出你当下的心情状态,你会惊讶于它的准确度之高,而且,不仅是愉快悲伤,它还能“看”出来其它心情如:平静、困惑、惊讶、愤怒等等。
推算心情不是唯一让人惊叹的地方,在推算出你的心情状态之后,emo 还会贴心地为你推送音乐。emo 拥有庞大优质的音乐后台曲库,推送的每一首歌都由人工打上心情标签,每一首歌都是我们为你精心挑选的,符合你现时心情的。简单来说 emo 是一个音乐播放器,而脸部识别技术的嵌入让这个播放器又没那么简单——emo 可以通过扫描用户的脸部表情,判断用户的情绪,推荐给用户相应的音乐。产品的立意是希望用户在每一刻都能听到想听的符合心情的歌曲。总体而言,该 App 也跳出了一般意义上的播放器,是一款十分有意思的产品,期待优化的更好一些。其他三大主流音乐播放器或许未来也可以借鉴一下。
2.3 分析总结
目前,各家大厂的 API 都已经非常成熟,同时由于微信小程序的兴起,很多 APP 的功能都可以迁移至小程序完成,通过广泛的调研,可以发现目前做人脸识别的产品较多,而聚焦于表情识别的并不多,或者仅仅是简单的给出是否微笑等简单的表情提示,大部分并没有将其与产品进行一个有机的结合。在调研过程中,个人觉得 emo 是一个很好的点子,不过很可惜并没有得到很好的推广。
目前,仅针对人脸识别的技术相对成熟,表情识别还有很大的市场,接下来需要做的是将表情识别运用到实际场景中,将其与现实需求进行良好结合。例如在游戏的制作上面,可以根据人类情感做出实时反映,增强玩家沉浸感;在远程教育方面,可以根据学生表情调整授课进度、授课方法等;在安全驾驶方面,可以根据司机表情,判断司机驾驶状态,避免事故发生。在公共安全监控方面,可以根据表情判断是否有异常情绪,预防犯罪;在制作广告片的时候,制作者往往都会头疼一个问题:该在什么时候插入商标 logo、该在什么时候跳出产品图片才能让观众对这个品牌、这个产品有更深的印象?表情识别就可以帮助广告制作者解决这一令人头疼的问题。制作者只需要在广告片完成后,邀请一部分人来试看这个广告片,并在试看过程中使用表情识别系统测试观看者的情绪变化,找到他们情绪波动最大的段落,这就是最佳的 logo 插入段落。与其类似的,可以帮助广告制作者找出最佳的 logo 植入点,还可以帮助电影制作方寻找出一部电影中最吸引人的部分来制作电影的预告片,以确保预告片足够吸引人,保证有更多的人在看完预告片后愿意走进电影院观看“正片”。表情识别是一个很有发展前景的方向,将其与日常所需紧密联系是这类产品需要考量的重要因素,而不单单只是给一个检测结果而已,或许这个未来的发展方向之一。
3 表情常用开源数据库
(1) KDEF 与 AKDEF(karolinska directed emotional faces)数据集
链接:http://www.emotionlab.se/kdef/
这个数据集最初是被开发用于心理和医学研究目的。它主要用于知觉,注意,情绪,记忆等实验。在创建数据集的过程中,特意使用比较均匀,柔和的光照,被采集者身穿统一的 T 恤颜色。这个数据集,包含 70 个人,35 个男性,35 个女性,年龄在 20 至 30 岁之间。没有胡须,耳环或眼镜,且没有明显的化妆。7 种不同的表情,每个表情有 5 个角度。总共 4900 张彩色图。尺寸为 562*762 像素。图 3.1 是该数据集中一个微笑的示例。
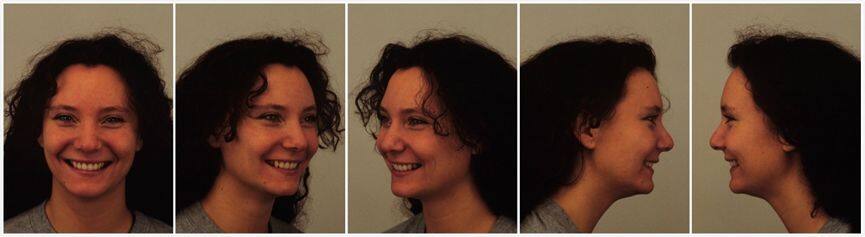
图 3.1 KDEF 与 AKDEF Dataset 中微笑示例
(2) RaFD 数据集
链接:http://www.socsci.ru.nl:8180/RaFD2/RaFD?p=main
该数据集是 Radboud 大学 Nijmegen 行为科学研究所整理的,这是一个高质量的脸部数据库,总共包含 67 个模特:20 名白人男性成年人,19 名白人女性成年人,4 个白人男孩,6 个白人女孩,18 名摩洛哥男性成年人。总共 8040 张图,包含 8 种表情,即愤怒,厌恶,恐惧,快乐,悲伤,惊奇,蔑视和中立。每一个表情,包含 3 个不同的注视方向,且使用 5 个相机从不同的角度同时拍摄的,图 3.2 是该数据集中 5 个方向的一个示例,图 3.3 是该数据集中一个表情的示例。

图 3.2 RaFD Dataset 中 5 个方向的一个示例

图 3.3 RaFD Dataset 中一个表情示例
(3) Fer2013 数据集
该数据集,包含共 26190 张 48*48 灰度图,图片的分辨率比较低,共 6 种表情。分别为 0 anger 生气、1 disgust 厌恶、2 fear 恐惧、3 happy 开心、4 sad 伤心、5 surprised 惊讶、6 normal 中性。图 3.4 为 Fer2013 数据集的部分数据。

图 3.4 Fer2013 Database 的部分数据
(4) CelebFaces Attributes Dataset (CelebA)数据集
链接:http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
CelebA 是商汤科技的一个用于研究人脸属性的数据集,一个包含超过 200K 名人图像的大型人脸属性数据集,每个数据集都有 40 个属性注释。该数据集中的图像涵盖了大型姿态变化和复杂背景。CelebA 的多样非常好,有约 10 万张带微笑属性的数据,图 3.5 是该数据集中一些微笑的示例。

图 3.5 CelebA Dataset 中一些微笑示例
(5) Surveillance Cameras Face Database
(SCface)
SCface 是人脸静态图像的数据库。图像是在不受控制的室内环境中使用五种不同品质的视频监控摄像机拍摄的。数据库包含 130 个主题的 4160 静态图像(在可见和红外光谱中)。图 3.6 是该数据集中不同姿势的一些示例。

图 3.6 SCface Database 中不同姿势的一些示例
(6) Japanese Female Facial Expression (JAFFE) Database
该数据库包含由 10 名日本女性模特组成的 7 幅面部表情(6 个基本面部表情+1 个中性)的 213 幅图像。每个图像被 60 个日语科目评为 6 个情感形容词。图 3.7 是该数据集中的部分数据。
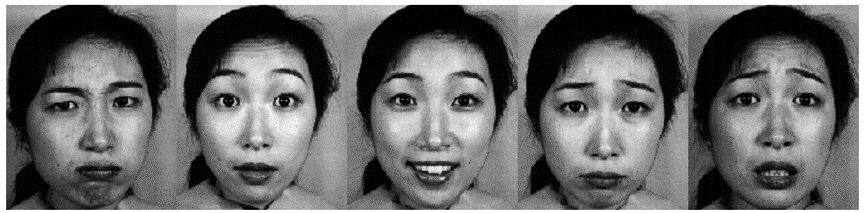
图 3.7 JAFFE 中的部分数据
除上述介绍到的开源数据集外还有许多关于表情的开源数据集,总之需要多去搜索总结,使用这些开源数据集,我们可以省去很多构造数据的时间,也便于我们训练出一个鲁棒性比较好的模型。
4 人脸表情识别研究方法
4.1 表情识别系统
人脸表情识别系统如图 4.1 所示,主要由人脸图像的获取、人脸检测、特征提取、特征分类四部分组成。

图 4.1 人脸表情识别系统
由于开源表情数据库目前已经比较多,图像获取难度不大,人脸检测算法也比较成熟,已经发展成为一个独立的研究方向,因此人脸表情识别的研究主要体现在系统的后面两个步骤:特征提取和特征分类上,下面将从传统研究方法和深度学习研究方法对以上两个步骤进行阐述。
4.2 传统研究方法
4.2.1 特征提取
表情特征提取主要采用数学方法,依靠计算机技术对人脸表情的数字图像进行数据的组织和处理,提取表情特征,去除非表情噪声的方法。在某些情况下,特征提取算法提取了图像的主要特征,客观上降低了图像的维数,因此这些特征提取算法也具有降维的作用。
人脸表情的产生是一个很复杂的过程,如果不考虑心理和环境因素,呈现在观察者面前的就是单纯的肌肉运动,以及由此带来的面部形体和纹理的变化。静态图像呈现的是表情发生时单幅图像的表情状态,动态图像呈现的是表情在多幅图像之间的运动过程。因此根据表情发生时的状态和处理对象来区分,表情特征提取算法大体分为基于静态图像的特征提取方法和基于动态图像的特征提取方法。其中基于静态图像的特征提取算法可分为整体法和局部法,基于动态图像的特征提取算法又分为光流法、模型法和几何法。
基于静态图像的特征提取方法:
(1)整体法
人脸表情依靠肌肉的运动来体现。人脸表情静态图像直观地显示了表情发生时人脸肌肉运动所产生的面部形体和纹理的变化。从整体上看,这种变化造成了面部器官的明显形变,会对人脸图像的全局信息带来影响,因此出现了从整体角度考虑表情特征的人脸表情识别算法。
整体法中的经典算法包括主元分析法(PCA)、独立分量分析法(ICA)和线性判别分析法(LDA)。研究者针对于此也做了大量的工作,文献【1-3】采用 FastICA 算法提取表情特征,该方法不但继承了 ICA 算法能够提取像素间隐藏信息的特点,而且可以通过迭代,快速地完成对表情特征的分离。文献【4】提出了支持向量鉴别分析(SVDA)算法,该算法以 Fisher 线性判别分析和支持向量机基础,能够在小样本数据情况下,使表情数据具有最大的类间分离性,而且不需要构建 SVM 算法所需要的决策函数。实验证明了该算法的识别率高于 PCA 和 LDA。文献【5】依靠二维离散余弦变换,通过频域空间对人脸图像进行映射,结合神经网络实现对表情特征的分类。
(2)局部法
静态图像上的人脸表情不仅有整体的变化,也存在局部的变化。面部肌肉的纹理、皱褶等局部形变所蕴含的信息,有助于精确地判断表情的属性。局部法的经典方法是 Gabor 小波法和 LBP 算子法。文献【6】以 Gabor 小波等多种特征提取算法为手段,结合新的分类器对静态图像展开实验。文献【7】首先人工标记了 34 个人脸特征点,然后将特征点的 Gabor 小波系数表示成标记图向量,最后计算标记图向量和表情语义向量之间的 KCCA 系数,以此实现对表情的分类。文献【8】提出了 CBP 算子法,通过比较环形邻域的近邻点对,降低了直方图的维数。针对符号函数的修改,又增强了算法的抗噪性,使 CBP 算子法取得了较高的识别率。
基于动态图像的特征提取方法:
动态图像与静态图像的不同之处在于:动态图像反映了人脸表情发生的过程。因此动态图像的表情特征主要表现在人脸的持续形变和面部不同区域的肌肉运动上。目前基于动态图像的特征提取方法主要分为光流法、模型法和几何法。
(1)光流法
光流法是反映动态图像中不同帧之间相应物体灰度变化的方法。早期的人脸表情识别算法多采用光流法提取动态图像的表情特征,这主要在于光流法具有突出人脸形变、反映人脸运动趋势的优点。因此该算法依旧是传统方法中来研究动态图像表情识别的重要方法。文献【9】首先采用连续帧之间的光流场和梯度场,分别表示图像的时空变化,实现每帧人脸图像的表情区域跟踪;然后通过特征区域运动方向的变化,表示人脸肌肉的运动,进而对应不同的表情。
(2)模型法
人脸表情识别中的模型法是指对动态图像的表情信息进行参数化描述的统计方法。常用算法主要包括主动形状模型法(ASM)和主动外观模型法(AAM),两种算法都可分为形状模型和主观模型两部分。就表观模型而言,ASM 反映的是图像的局部纹理信息,而 AAM 反映的是图像的全局纹理信息。文献【10】提出了基于 ASM 的三维人脸特征跟踪方法,该方法对人脸 81 个特征点进行跟踪建模,实现了对部分复合动作单元的识别。文献【11】借助图像的地形特征模型来识别人脸动作和表情;利用 AAM 和人工标记的方法跟踪人脸特征点,并按照特征点取得人脸表情区域;通过计算人脸表情区域的地形直方图来获得地形特征,从而实现表情识别。文献【12】提出了基于二维表观特征和三维形状特征的 AAM 算法,在人脸位置发生偏移的环境下,实现了对表情特征的提取。
(3)几何法
在表情特征提取方法中,研究者考虑到表情的产生与表达在很大程度上是依靠面部器官的变化来反映的。人脸的主要器官及其褶皱部分都会成为表情特征集中的区域。因此在面部器官区域标记特征点,计算特征点之间的距离和特征点所在曲线的曲率,就成为了采用几何形式提取人脸表情的方法。文献【13】使用形变网格对不同表情的人脸进行网格化表示,将第一帧与该序列表情最大帧之间的网格节点坐标变化作为几何特征,实现对表情的识别。
4.2.2 特征分类
特征分类的目的是判断特征所对应的表情类别。在人脸表情识别中,表情的类别分为两部分:基本表情和动作单元。前者一般适用于所有的处理对象,后者主要适用于动态图像,可以将主要的特征分类方法分为基于贝叶斯网络的分类方法和基于距离度量的分类方法。
(1)基于贝叶斯网络的分类方法
贝叶斯网络是以贝叶斯公式为基础、基于概率推理的图形化网络。从人脸表情识别的角度出发,概率推理的作用就是从已知表情信息中推断出未知表情的概率信息的过程。基于贝叶斯网络的方法包括各种贝叶斯网络分类算法和隐马尔科夫模型(HMM)算法。文献【14】研究者 分别采用了朴素贝叶斯(NB)分类器、树增强器(TAN)和 HMM 实现表情特征分类。
(2)基于距离度量的分类方法
基于距离度量的分类方法是通过计算样本之间的距离来实现表情分类的。代表算法有近邻法和 SVM 算法。近邻法是比较未知样本 x 与所有已知类别的样本之间的欧式距离,通过距离的远近来决策 x 与已知样本是否同类;SVM 算法则是通过优化目标函数,寻找到使不同类别样本之间距离最大的分类超平面。文献【8】采用了最近邻法对表情特征进行分类,并指出最近邻法的不足之处在于分类正确率的大小依赖于待分类样本的数量。【15,16】分别从各自角度提出了对 SVM 的改进,前者将 k 近邻法与 SVM 结合起来,把近邻信息集成到 SVM 的构建中,提出了局部 SVM 分类器;后者提出的 CSVMT 模型将 SVM 和树型模块结合起来,以较低的算法复杂度解决了分类子问题。
4.3 深度学习方法
上述均为传统研究方法的一些介绍,下文主要讲述如何将深度学习应用到表情识别里,并将以几篇文章为例来详细介绍一下现在深度学习方法的研究方法和思路。
与传统方法特征提取不同,之所以采用深度学习的方法,是因为深度学习中的网络(尤其是 CNN)对图像具有较好的提取特征的能力,从而避免了人工提取特征的繁琐,人脸的人工特征包括常用的 68 个 Facial landmarks 等其他的特征,而深度学习除了预测外,往往还扮演着特征工程的角色,从而省去了人工提取特征的步骤。下文首先介绍深度学习中常用的网络类型,然后介绍通过预训练的网络对图像进行特征提取,以及对预训练的网络采用自己的数据进行微调的 Fine-Tunning。
如果将深度学习中常用的网络层 CNN,RNN,Fully-Connect 等层组合成网络,将会产生多种选择,然而这些网络性能的好与坏需要更多地探讨,经过很多研究者的一系列实践,很多网络模型已经具备很多的性能,如 ImgeNet 比赛中提出模型:AlexNet,GoogleNet(Inception), VGG,ResNet 等。这些网络已经经过了 ImageNet 这个强大数据集的考验,因此在图像分类问题中也常被采用。
对于网络的结构,往往是先通过若干层 CNN 进行图像特征的提取,然后通过全连接层进行非线性分类,这时的全连接层就类似与 MLP,只是还加入了 dropout 等机制防止过拟合等,最后一层有几个分类就连接几个神经元,并且通过 softmax 变换得到样本属于各个分类的概率分布。
关于人脸表情识别的讨论一直在继续,很多学者团队都聚焦于此。文献【17】提出了用于注释自然情绪面部表情的一百万个图像的大型数据库(即,从因特网下载的面部图像)。首先,证明这个新提出的算法可以跨数据库可靠地识别 AU 及其强度。根据调研,这是第一个在多个数据库中识别 AU 及其强度的高精度结果的已发布算法。算法可以实时运行(> 30 张图像/秒),允许它处理大量图像和视频序列。其次,使用 WordNet 从互联网下载 1,000,000 张面部表情图像以及相关的情感关键词。然后通过我们的算法用 AU,AU 强度和情感类别自动注释这些图像。可以得到一个非常有用的数据库,可以使用语义描述轻松查询计算机视觉,情感计算,社会和认知心理学和神经科学中的应用程序。

文献【18】提出了一种深度神经体系结构,它通过在初始阶段结合学习的局部和全局特征来解决这两个问题,并在类之间复制消息传递算法,类似于后期阶段的图形模型推理方法。结果表明,通过增加对端到端训练模型的监督,在现有水平的基础上我们分别在 BP4D 和 DISFA 数据集上提高了 5.3%和 8.2%的技术水平。
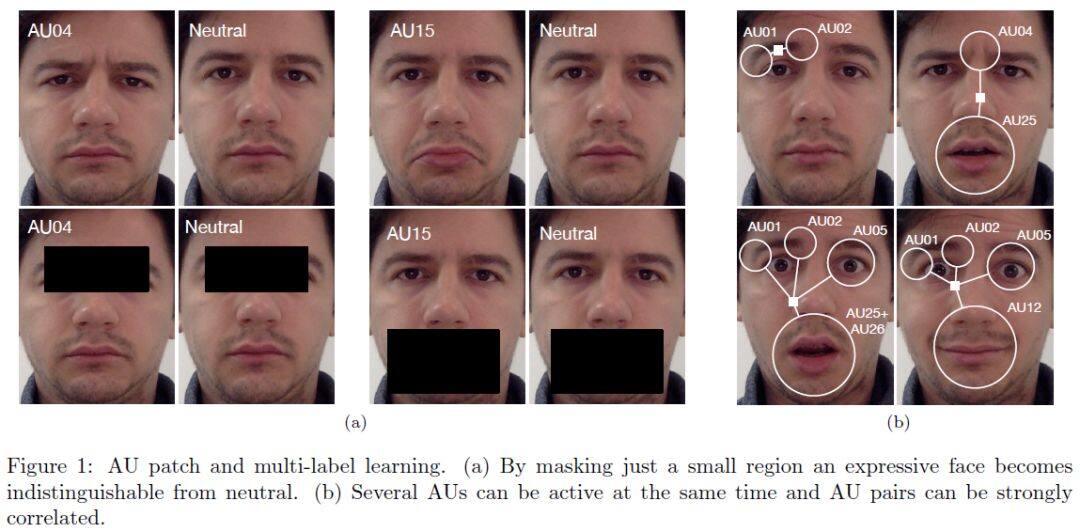
5 总结
FER 目前的关注点转移到具有挑战性的真实场景条件下,利用深度学习技术来解决如光照变化、遮挡、非正面头部姿势等问题。
需要考虑的另一个主要问题是,尽管目前表情识别技术已经被广泛研究,但是我们所定义的表情只涵盖了特定种类的一小部分,主要是面部表情,而实际上人类还有很多其他的表情。
表情的研究相对于颜值年龄等要难得多,应用也要广泛的多,相信这几年会不断出现有意思的应用。
参考文献:
[1] 何良华. 人脸表情识别中若干关键技术的研究[D]. 东南大学, 2005.
[2] 周书仁, 梁昔明, 朱灿,等. 基于 ICA 与 HMM 的表情识别[J]. 中国图象图形学报, 2008, 13(12):2321-2328.
[3] 周书仁. 人脸表情识别算法分析与研究[D]. 中南大学, 2009.
[4] 应自炉, 唐京海, 李景文,等. 支持向量鉴别分析及在人脸表情识别中的应用[J]. 电子学报, 2008, 36(4):725-730.
[5] Khorasani K. Facial expression recognition using constructive neural networks[C]// Signal Processing, Sensor Fusion, and Target Recognition X. Signal Processing, Sensor Fusion, and Target Recognition X, 2001:1588 - 1595.
[6] Kyperountas M, Tefas A, Pitas I. Salient feature and reliable classifier selection for facial expression classification[J]. Pattern Recognition, 2010, 43(3):972-986.
[7] Zheng W, Zhou X, Zou C, et al. Facial expression recognition using kernel canonical correlation analysis (KCCA).[J]. IEEE Transactions on Neural Networks, 2006, 17(1):233.
[8] 付晓峰. 基于二元模式的人脸识别与表情识别研究[D]. 浙江大学, 2008.
[9] Yacoob Y, Davis L S. Recognizing Human Facial Expressions From Long Image Sequences Using Optical Flow[J]. Pattern Analysis & Machine Intelligence IEEE Transactions on, 1996, 18(6):636-642.
[10] Tsalakanidou F, Malassiotis S. Real-time 2D+3D facial action and expression recognition[J]. Pattern Recognition, 2010, 43(5):1763-1775.
[11] Wang J, Yin L. Static topographic modeling for facial expression recognition and analysis[J]. Computer Vision & Image Understanding, 2007, 108(1):19-34.
[12] Sung J, Kim D. Pose-Robust Facial Expression Recognition Using View-Based 2D 3D AAM[J]. IEEE Transactions on Systems, Man, and Cybernetics - Part A: Systems and Humans, 2008, 38(4):852-866.
[13] Kotsia I, Pitas I. Facial Expression Recognition in Image Sequences Using Geometric Deformation Features and Support Vector Machines[J]. IEEE Transactions on Image Processing A Publication of the IEEE Signal Processing Society, 2007, 16(1):172.
[14] Cohen I, Sebe N, Garg A, et al. Facial expression recognition from video sequences: temporal and static modeling[J]. Computer Vision & Image Understanding, 2003, 91(1–2):160-187.
[15] 徐文晖, 孙正兴. 面向视频序列表情分类的 LSVM 算法[J]. 计算机辅助设计与图形学学报, 2009, 21(4):000542-553.
[16] 徐琴珍, 章品正, 裴文江,等. 基于混淆交叉支撑向量机树的自动面部表情分类方法[J]. 中国图象图形学报, 2008, 13(7):1329-1334.
[17] Benitez-Quiroz C F, Srinivasan R, Martinez A M. EmotioNet: An Accurate, Real-Time Algorithm for the Automatic Annotation of a Million Facial Expressions in the Wild[C]// Computer Vision and Pattern Recognition. IEEE, 2016:5562-5570.
[18] Benitezquiroz C F, Wang Y, Martinez A M. Recognition of Action Units in the Wild with Deep Nets and a New Global-Local Loss[C]// IEEE International Conference on Computer Vision. IEEE Computer Society, 2017:3990-3999.
作者介绍
李振东,北京邮电大学硕士在读,计算机视觉方向。
言有三,真名龙鹏,曾先后就职于奇虎 360AI 研究院、陌陌深度学习实验室,6 年多计算机视觉从业经验,拥有丰富的传统图像算法和深度学习图像项目经验,拥有技术公众号《有三 AI》,著有书籍《深度学习之图像识别:核心技术与案例实战》;
原文链接
https://mp.weixin.qq.com/s/Ht8kFTgIWASusfSUQqoaJA

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论