编者按:「范式大学」由第四范式发起,致力于成为“数据科学家”的黄埔军校,校长为第四范式首席科学家,华人界首个国际人工智能协会AAAI Fellow、唯一的AAAI 华人执委杨强教授。
[范式大学]在探索AI 工业化的同时,也关注最新学术研究成果。近日,杨强教授在[范式大学]内部课程中,与大家分享了他在 “生成式对抗网络模型“ 和迁移学习等领域的独特见解和最新思考。在此特别感谢杨教授的博士生张颖华同学的帮助。
以下内容根据杨强教授演讲编写,略微有所删减。
有些人看过电视剧《西部世界》—在《西部世界》里,你可能问的一个关键问题是什么?就是当剧中的人们,其中任何一个人走到你面前,你能否区分出他/她是个真人? 你会问:咦,这不是图灵测试要解决的问题吗? 是的。 问题是,如果《西部世界》里的这些机器人已经通过了图灵测试,你又如何区分他/她们呢?
要解决这个问题,除了用“一枪把对方打死,然后看对方是否真的死了”这个极端的检测方法以外,还有什么更好的方法呢?这里有些剧透,答案是:拍苍蝇。当一个苍蝇飞到一个“人”的脸上,如果这个人没有感觉,不会去拨开或拍打苍蝇,他/她很可能就是机器人。结果因此还引发了一件趣事,去年美国大选的时候,希拉里在讲台上面,一个苍蝇飞到她脸上,她没有搭理,后来有人就说:糟了,我们要选一个机器人当总统了!那时《西部世界》恰好正在热播。
言归正传,从人工智能的角度,“拍苍蝇”这个例子,说明什么呢?它告诉我们有一些关键特征可供识别真人亦或机器人,但要找到这些关键特征并不容易。对《西部世界》而言,你得把整个剧看完才能知道。也就是说,你不但要有大量数据的训练,而且得知道剧里的机器人的制造原理,这样才能找到这个重要特征。那么问题来了:如果作为“游客”,我们对这个机器人的构造知道甚少怎么办?
要回答这一点,我首先要给大家讲一下概率模型的不同类型。概率模型是贯穿整个机器学习的主线。下面PPT 上的这两张图是对一个女孩的素描,我们在素描里面可以看到很多的特征,比方说比较飘逸的笔画、或者是适合女性颜色等。我们把上面的问题简化一下:如何能够通过辨别这些体征、从而认出来画上的是男是女?

这里我要介绍一个“生成”模型的概念。 在某个关于“人”的样本集里面找到某一个高概率的样本,我们认为这个样本很可能对应我们对“人” 这个概念的认识。然后我们根据这个样本来做完形填空或着彩。在小学中学我们经常做的一种题就是填空。其实,生成样本的过程和填空很相似:当我们看到这张画要给它着色时要选择颜色和图案,是因为这些选择符合“人”的概率分布。
再具体一些:如果数据是(X,Y),这里我们用X 这个变量来代表笔画和颜色,Y 这个变量来区分男女,那么这个概率数据是遵循一定分布规律的。但问题是,如何才能得到这个数据的分布?在现实中,做到这一点是非常难的,因为这需要我们获得概率的“联合分布”,就是所有显式和隐式的特征和它们所有可能取值的概率。知道了这个概率,生成某个样本就很容易了。 在机器学习的历史上, 关于要不要首先获得“联合分布”这个问题,有着很多的争论。比方说,有贝叶斯流派,就说:“是的,我们需要这样一个联合分布”。而深度学习流派,或者是SVM 等算法对应的这些流派,就说:既然我们的目的是分类,那用简单的算法就可以了,所以”不需要”。 得到一个联合概率分布是非常非常难的事情,因为需要因果关系的知识,还需要很多先验概率。
生成模型是很有用的。比如说,我们在一幅画上如何确定这样着色是有意义的,但那样做是没有意义的?除了在画作上,在音乐作曲的问题上也是如此:如何做一首动听的曲子?为什么有的曲子就很好听,有的就很难听?这些任务,其实都是在做“生成”的工作。我们为什么很尊敬某些作曲家、电影导演、作家? 作为观众,我们去看电影很容易,但是让自己去做导演,做编剧往往就觉得很难。 这是为什么呢? “联合概率模型”的学习过程就帮助我们回答了这样一个问题。问题是:学习如何产生一个联合概率模型,需要大量的高质量数据来训练。真正能了解真实概率生成机制的只有少数人,即那些机器人的设计者。这也和我们的常识是一致的: 只有少数人能够成为好的作家,只有少数人能够成为好的诗人,而要做到这一点需要遵循所谓的“一万个小时定律”。
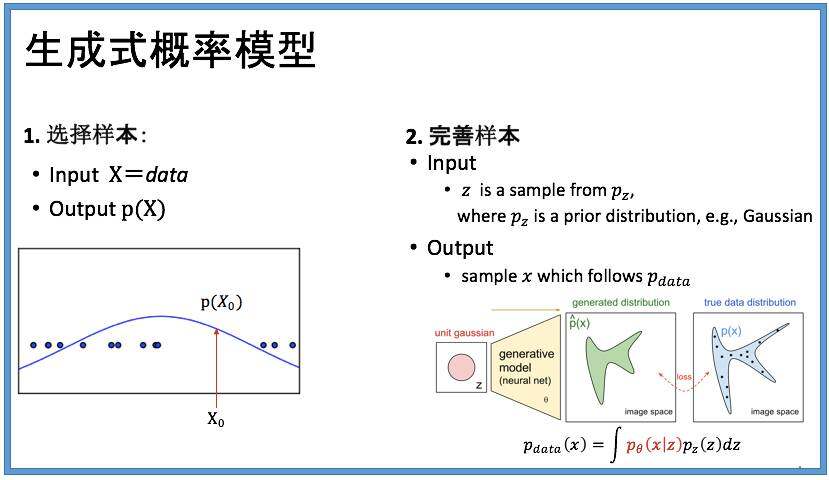
因为生成式模型很难估计,所以,我们在机器学习中更多的是使用“判别式机器学习模型”的。这种模型和“生成式概率模型”是有一个本质的区别的。 我们过去熟悉的模型如逻辑回归,SVM 和深度学习等,多是判别式模型。就是:给你一个样本,模型不关注样本是怎么“真正”生成的,也不关心样本构造的真实因果关系和概率值, 而是直接判别样本属于哪一类。 我们可以管这种判别的方式叫做“懒人主义”。 相反,生成式模型可以被认为是一个“完美主义。” 什么是完美主义呢?我们要去判别一个事,从它最原始的那个点开始分析,产生先验概率分布,然后根据因果关系一直推到可观察的样本分布,最后再得到样本。这样,一旦得到整个联合概率分布,就可以对缺失数据和未来的事件做出准确的预测。 所以,到了完成了这个联合分布的学习时,我们机器学习的工作就做的差不多了。
生成式模型和判别式模型的区别很像人和机器的区别:机器采取的是完美主义,因为它可以不断优化,追求极致。而人不会如此,人是够好了就满足了。从这一点上来说,人完全没有必要和阿尔法狗去比赛,因为这是不明智的。我们人类的构造不是干这个的,我们的构造是能把一件事给做完了。比方说,人应该去比的是你有多快能学会下围棋,并从中得到多少乐趣。而把围棋下的极致这件事是机器擅长的。
有没有办法,利用有限的数据,通过不断提高的方式,建立一个**** 生成式模型呢?Ian Goodfellow 提出了一种新的方法,很值得我们思考: 他的设想是用一个生成式模型(Generator)来生成模拟样本,再用一个判别式模型来区分这个生成的样本是否真实,这样的一对系统,可以互相对弈,共同提高。 以作画为例。 假设我们的目的是设计一台机器人来模拟大师们的画作。 最开始,机器人先通过生成式模型完成某个画作。 这幅画可能很差,离大师的水平差的很远。如果这个时候有一个评论员(判别式模型)来告诉机器人这幅画的缺点,那机器人就可以在下一幅画中加以提高。如果评论员自己犯了错误,没认对,那机器人就可以告诉评论员如何提高鉴赏能力。 评论员总是在问这样一个问题:这幅画是大师画的还是机器人画的?如果判别式模型可以准确地辨认出来是机器画的,那说明这个生成式模型还不够好,如果判别不出来,就说明画作已经能够以假乱真了,而判别式模型就有待提高。这里,生成式模型和判别式模型,利用不断反馈,实现相互提高。
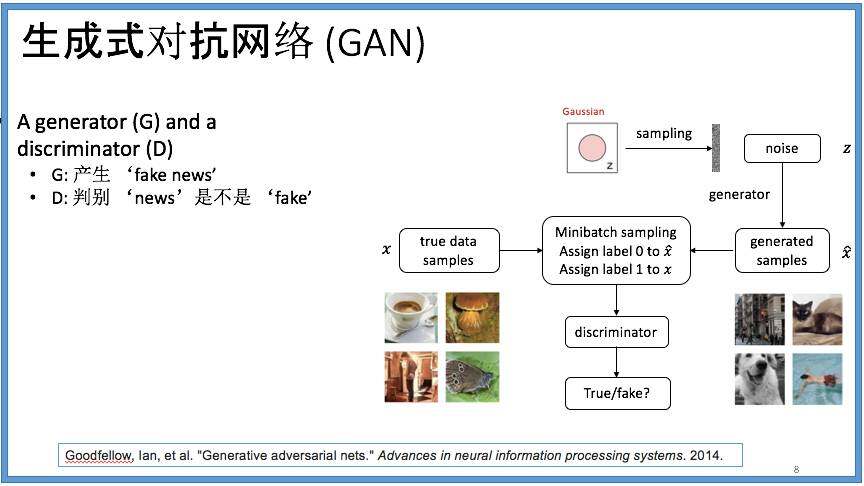
这让我们想起了图灵测试——计算机和裁判聊天,他们互相看不到彼此,如果在沟通的时候,裁判无法辨别哪个是计算机,“人工智能”在它身上就实现了。这个双机结构和图灵测试不同的地方就是,机器和判官都可以学习,不断提高,最后两者都可以达到最好。
这样,就把我们带到“生成式对抗网络” (GenerativeAdverserial Network, 或者GAN)这个概念。如下图所示, 我们有两个系统,在互相对抗, 两个系统都试图优化自己的目标函数。第一个系统对应判别式模型D: 判别式模型D 在试图识别到来的样本是否是自然真实的;它在尽量增大对真实样本的识别率,同时减少对模拟生成的样本的误判率。另一个系统则对应着生成式模型G:G 希望它生成的模拟样本可以在D 那里鱼目混珠。 所以G 试图最大可能地模拟真实的样本。 判别器D 从判别角度来说,判别的越好,D 的目标实现的就越优 。但对于生成器G 来说,它要最小化(minimize)对方的优化函数,这就相当于最大化(maximize)它自己的优化函数。这个过程就像G 和D 在下棋一样(如下图的博弈树)。在这个树里有两个棋手,一个在不断更新判别器,一个是在不断更新生成器。把这两个合并起来,叫做Minimax 算法,这是利用AI 下棋的一个基本算法。在这里,就是G 和D 两个系统在竞争中不断成长,最后两个都达到最优。
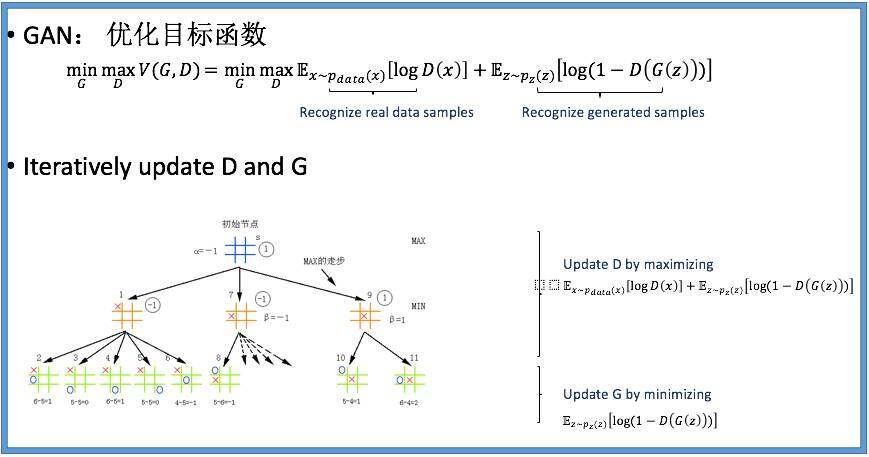
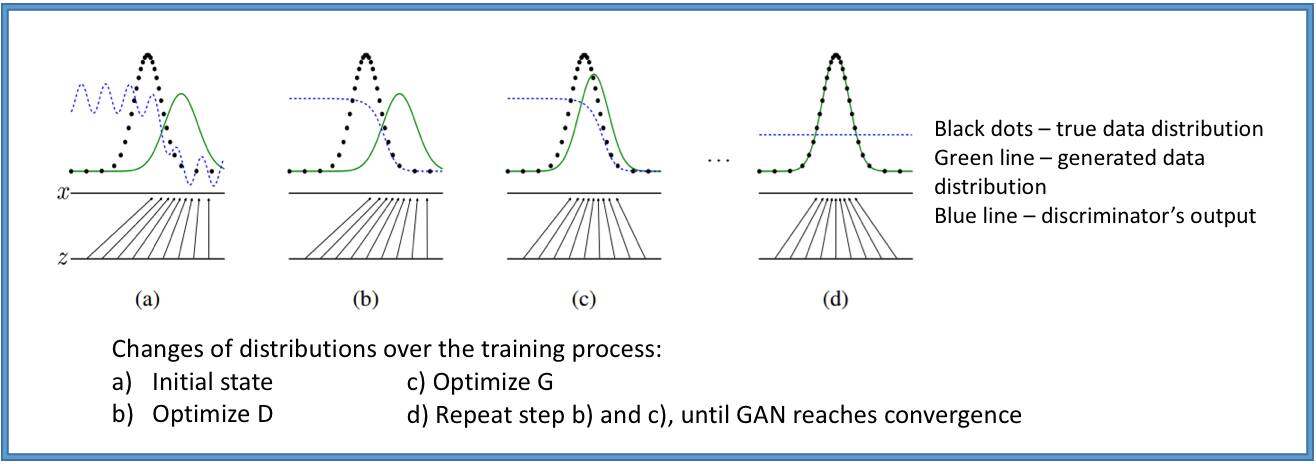
这个交互过程到底能不能同时优化两个目标?GAN 的发明人Goodfellow 有以下的解释。训练过程如下图所示,假设黑色的点是真实样本的分布,绿色的线是根据生成模型产生的生成的样本的分布,那么GAN 网络就是在把生成的样本的概率空间映射到真实样本空间里,再去加以对比。这样得到的结果与真实情况会存在偏差,而根据这样的反馈,生成的样本的数据分布不断得到调整,直到和真实分布重合为止。这时,判别式模型G 就分不出来真假数据,而学习任务就完成了。
那么,有没有理论来证明以上这个博弈学习交互过程会最终得到令人满意的结果呢?我们看看下面这个定理:
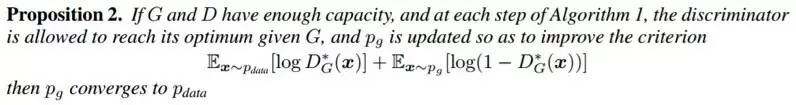
这里给大家翻译一下这个公式:
如果G 是丈夫,D 是妻子,妻子训练丈夫做家务。妻子不断指出丈夫的不足之处,以此希望丈夫提高自己。丈夫呢,有时他提高的办法是试图猜出妻子满意的家务到底是什么,就不断的试验。但一开始结果可能和妻子的需求不一样,然后得到一顿狠K。所以在提高如果夫妻两人同样好学,妻子能不断指出丈夫的错误,而丈夫也不放弃,一直很努力,那么这对夫妻就会一起进步,一直达到一个共同的最优值,这个家庭也就美满了。
那么这个定理到底是不是靠谱呢?因为它有很多的限制条件,这些条件在现实中都很难成立,所以我们只能通过实验来验证。比方说,我们可以使用手写识别的数据集MNIST 和图像识别的数据集TFD 来验证,最后发现GAN 在集种不同的算法里面的得分是最高的!

利用GAN 也可以让电脑学写字。在训练好的时候,这些GAN 写的文字几乎可以以假乱真。但它也有做不好的地方,比如说在一些复杂的图像中做出来的就是相当模糊的。我们后面会讨论,这是因为GAN 在数据集之间的“距离”的概念还没有学好。

我们接下来要问:样本到底是怎么产生的?一个简单的办法是“猜测”: 我们首先可以假设一个真实的概率分布是按照某种形式来分布的, 然后按照这种形式随机地产生一个样本。这样的结果如果不好,那就回来修改这个分布假设。但是,这种猜的办法质量低,速度慢,结果不靠谱。
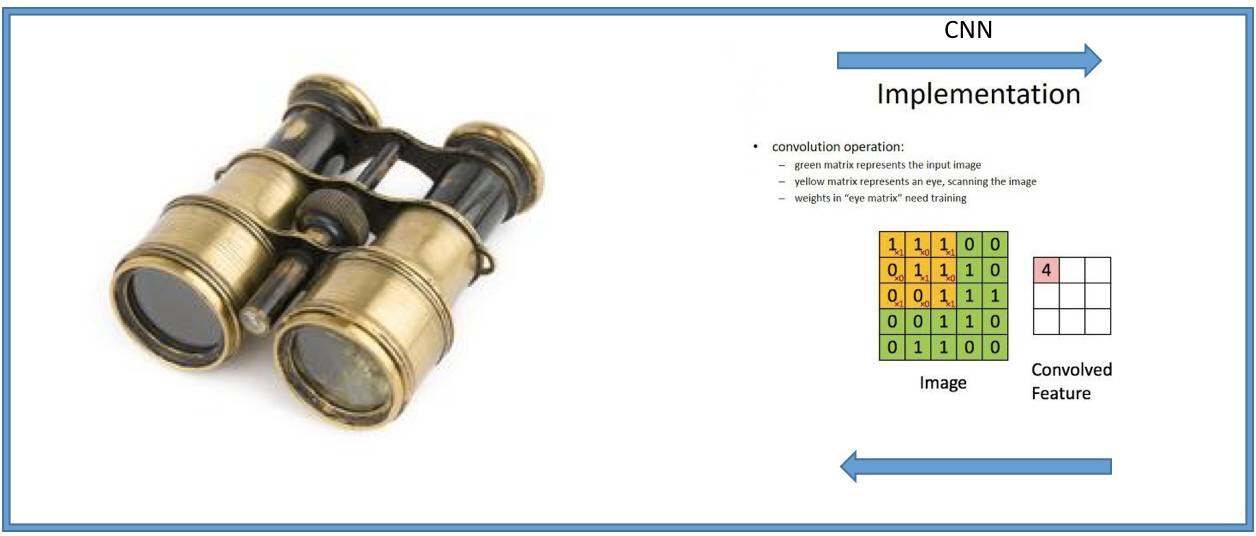
那要怎么办呢?假设我们有一张很大的画,我们要把它压缩一张小画,一般是怎么做的呢?我们大家可能用过双筒望远镜。这个望远镜可以反着看,就会看到小版的画面,这个就相当于把一大块数字压缩成一个数字,这个过程叫做convolution(卷积),卷积神经网络就是在做这件事情。那如果我们正着看望远镜,会把一张画放大,我们会看到画作当中的某一个部分,这个过程就相当于从一个或几个数字产生了整个矩阵,这也就是“生成”的过程,即生成式模型在做的事情。理解了这个原理后,基于深度学习和卷积,我们把整个网络反过来,相当于正着用望远镜,把压缩的图形一步一步放大,最后形成了一个复原的样本,它叫“转置卷积(Transposed-Convolution)”, 这个产生样本的方法叫做DCGAN。比方说,可以通过几个例子的训练之后,用来产生新的中文字。还有一些漫画的社区也开始用这个网络,来自动生成漫画的图像。
当然,还可以用DCGAN 网络来分类,用它的判别式模型部分来做分类这件事。这就好像用大炮打蚊子是没有必要的,但用大炮里某个部件(即判别式模型)打蚊子,确实要比用大炮拍打蚊子要打的好。所以,我们取出一块深度网络中的一部分来分析,发现它确实可以帮助找到非常关键的一些数据特征,而且用它来做分类的效果就比其他的办法要好很多。再回到西部世界的那个例子,看“苍蝇趴在脸上,人的反应”这个特征,就可以被找出来了。
有了GAN 这个方法,我们可以对任意样本做向量化,从而加以比较。比方说,我们可以比较“苹果”和“橘子”,看它们的距离到底是不是比“苹果”和“香蕉”近一些? 我们知道在自然语言界有一个技术叫Word2vec,从文字到向量表示(Embedding),是一个连续实数向量。它可以做什么呢?比方说它认为,v(“woman”)-v(“man”)+v(“king”) =v(“queen”),即女人减去男人,再加上一个国王,相当于把女人的特性赋予国王,这个国王对应的就应该是女王,这个过程做类比。类比是怎么产生的呢?在高维空间,大数据会表明,这两个字的用法差不多,它们的距离很近。而 GAN 网络也可以做这件事情,比方说这个男的戴墨镜,减去一个男的再加一个女的,就变成了一个女的戴墨镜,这个是可以用 GAN 可以做的,很神奇。

但是这样设计的系统还是有一些缺点。 比如,如果我们稍微换一换模型的参数,模型效果就会急剧变差。这说明,直接用 DCGAN 建立的模型不大可靠。
怎么解决这个问题呢?我们在开始讲过,GAN 的思想就是不断修改生成式模型使得模拟的概率模型尽量接近实际的概率模型。所以,可靠性问题的实质就在于:如何可靠准确地测量两个概率分布之间的距离。 这里有一个新的技术叫 Wasserstein GAN。 因为传统的生成式模型的目标函数通常都是优化 KLdivergence, GAN 的目标函数在优化 JS divergence. 但这两个距离都有缺点:就是不能准确表达所有分布之间的距离。所以有人提出一个更靠谱距离表达,叫做 Wasserstein 距离,外号叫“土地挖掘机” (Earth-mover),就是给你一个土山,那么如果你用挖掘机在这一座山,去复制另一座山,问你需要花多大的力气 — 这个移动土地的费用就是 Wasserstein 距离,简称W 距离。如果两座山的形状完全一样,那么就不需要任何费用。 如果两者完全不同,那么就需要很多的费用。

如果换成这个 W 距离来测量概率分布就好得多。比如说,给定两个数据集的分布,其中一个是真实的新闻分布,一个是假新闻的分布。如果用 KL 或 JS 距离来表达,结果都不够好,会得到一个是无穷大,一个是一个常数。用这样的距离就没有办法识别真、假新闻了。 但如果我们用了 W 距离,得到的会是一个连续可导的距离。所以,用 W 距离来设计 GAN (WGAN) 就靠谱多了。
生成式对抗模型(GAN)可以做哪些事呢?它可以做模型的解释,做图像分析和自然语言分析。还可以再加上一些新的边界条件,用来做迁移学习。

上面这个例子,是把一个模糊影像变到清晰影像的任务,模糊影像的模型是有很多的不确定的地方。把一幅画变为清晰的过程,就是在一个矩阵里面找到丢失的值,并且把它用真实值填满;这个事和我们第四范式做推荐系统的概念是一样的。
再者,就是可以用 GAN 来很自然地实现迁移学习。比如说, 如果我们又一个很好的生成式模型,在某个数据集上已经训练好了,如果有一些新的数据,和前一个数据集有明显的区别, 那么我们可以利用“GAN+边界条件”,把生成式模型“迁移到” 新的数据分布上。比方说,我们写字的时候,每个人签名都是不同的,我们不会用印刷体来签名,因为我们每个人都有自己的写字的特点。那么,如果用大量的印刷体字作为第一部分的训练样本,来训练一个不错的通用模型,而用某个人手写的斜体字做第二部分的训练样本,就可以利用 WGAN把印刷体的模型迁移到个人的签名。也就是说,这样的签名也就更具个性化特点。
所以说,即使源数据和目标数据在写法上、颜色上有一些区别,GAN 的模型可以实现迁移学习的目标。
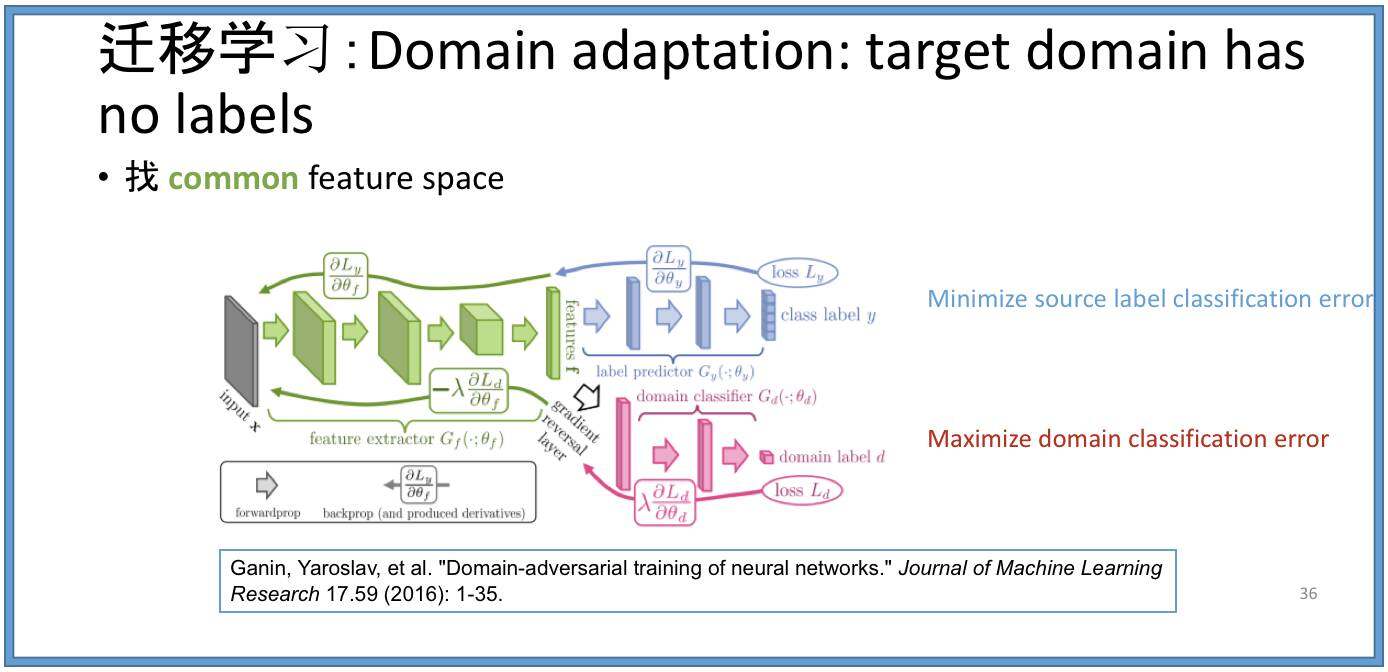
这里还有一个迁移学习的例子:在领域适应(Domain Adaptation)的问题中,在目标领域没有任何的标注,所有的标注都在源领域。 GANIN 等人设计了一个类似于 GAN 的模型,在源领域用标注数据来做标注数据的分类,同时连接到一个“领域判别器”来区分输入的数据,看数据是来源还是目标领域。 这个过程进行到最后,当领域判别器不 **** 可以很好地区分数据来自哪个领域,就说明神经网络的中间层学会两个不同领域的相同特征部分了。这个时候,迁移学习的目的就达到了。
总结起来我们看到,生成式对抗网络是一个新的机器学习的思想。它是由两个模型共同产生的——就像是两个学生同时成长,一个学生专注于生成样本,一个学生专注于判别真假,他们来互相促进。同时,生成式对抗网络也存在一定缺陷,首先它需要的数据量还是很大的;此外,理论的指导还是比较缺乏。
最后我们还回到《西部世界》的场景。这个电视剧的一条主线是对机器人(或人类)的智能成长的路径,电视剧的后面几集提出了一个重要的思想:**“二分心智”(Bicameral Mind)。** 这是个关于人类智能的发展的假说:提出大脑中的智能和意识的发展,是通过两个独立的智能体的不断对话和学习来实现的。也就是我们常说的 “脑袋里的两个小人在打架”。这个二份心智理论曾经在心理学界大行其道。
我们看到,生成式对抗网络 GAN 的模型,和这个“二分心智”的理论有些不谋而合:它们都是认为智能应该是能够不断学习提高的,都提出:智能成长的机制是由两个互动的系统来相互刺激。在 GAN 这个模型中,这两个机制分别是生成式模型和判别式模型。 在《西部世界》里,这个刺激来自很多的苦难和创痛,让机器人 Dolores 和她的同伴们经历了很多痛苦艰难的事情,最后刺激让她/他们产生了“二分心智”,也就产生了意识。 就像这幅图中的两个 Dolores 在对话所表现的那样, 最终导致机器人们产生了意识 。

当然,在生成式对抗网络 GAN 的学术方向上,并没有涉及到“意识的生成”这个问题, 实际上,整个人工智能的发展都还没有涉及到“意识”的概念。 但是,通过 GAN 来理解的“二分心智”, 以及“我们可以借两个对抗系统提高智能”这件事,还是非常有趣的!
扩展阅读
[1] Goodfellow, Ian, et al. “Generative adversarial nets.” Advances in neural information processing systems. 2014.
[2] Ganin, Yaroslav, et al. “Domain-adversarial training of neural networks.” Journal of Machine Learning Research 17.59 (2016): 1-35.




