

北京时间 8 月 6 日,小米 AI 实验室 AutoML 团队对外展示最新研究成果:MoGA(作者:初祥祥,张勃,许瑞军)。据了解,该模型超过了由 Google Brain 联合 Google AI 团队的代表作 MobileNetV3(谷歌官方尚未公开模型源码)。同时,小米方面称:该模型为真实场景所使用设备深度定制,可直接服务于手机端视觉产品。


作为 Google Brain 首席科学家 Quoc Le 团队联合 Google AI 的一流团队顶级成果,MobileNet 三部曲最新番 MobileNetV3,5 月份一出江湖便备受瞩目,Github 上复现者层出不穷。
在谷歌还未放出 V3 之时,小米 AutoML 团队推出 MoGA(https://github.com/xiaomi-automl/MoGA)。在 ImageNet 1K 分类任务 200M 量级从移动端 GPU 维度超过 V3 和 FairNAS。方法基于 FairNAS 改进,且结果胜过 FairNAS。
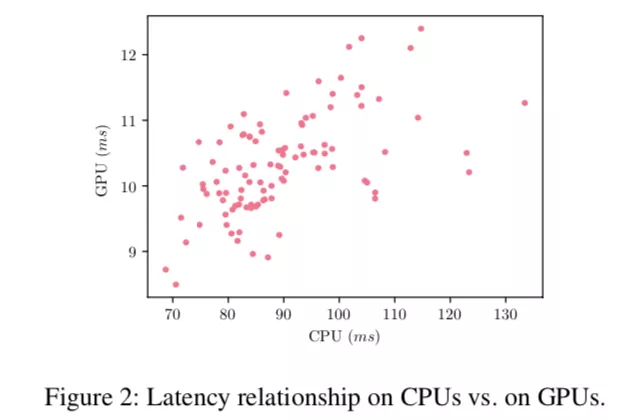
本文第一个新颖点是 Mobile GPU-Aware(MoGA),即从实际使用角度,设计移动端 GPU 敏感的模型。过去的研究普遍只考虑移动端 CPU 的延迟,但实际使用的时候往往都运行在 GPU 上,两者的延迟并非简单的线性,不仅和硬件相关,还是框架实现相关,参见 Fig2 根据采用的搜索空间中随机采样的 100 个模型对应的 CPU/GPU 运行时间绘制的散点图。
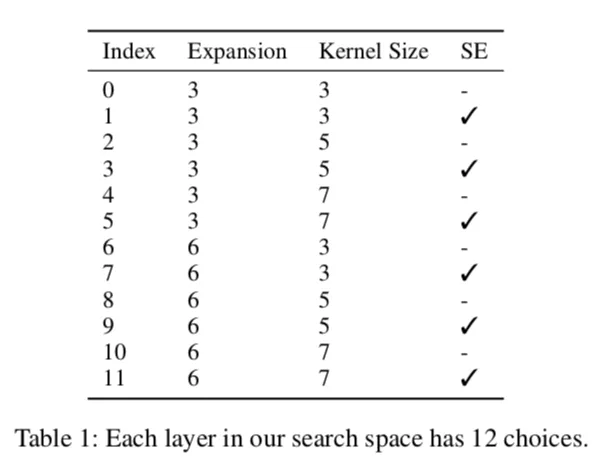
本文的搜索空间(Search Space,SS)是基于最新版的 MnasNet,融入了 squeeze-and-excitation 模块,MobileNetV3 也采用这个 SS,而且加入 Hswish 非线性激活,MoGA 因此保持了 V3 的各层输入输出和激活单元。另外,在 FairNAS 基础上,MoGA 每层的可选择运算模块(choice block)从 6 个增加到了 12 个,超网的训练依然很快收敛。
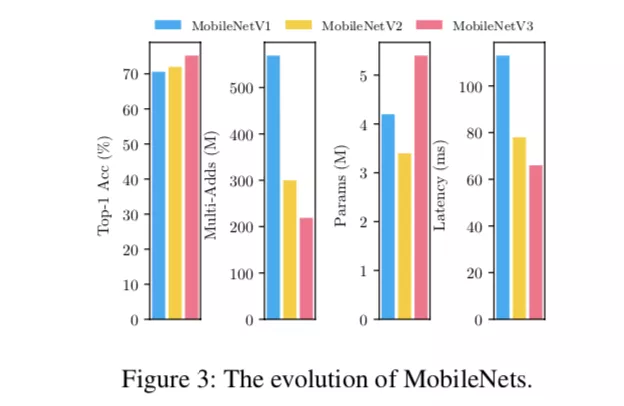
文章的第二个新颖点来自于对 Mobilenet 三部曲的分析,从 V1 到 V3,各项指标均在提升,但模型参数量反而增多。这对设计多目标的优化条件给出了方向。文章认为,除了业务指标 Top-1 Acc,模型在设备端的运行时间是作为衡量模型的关键指标,而非乘加数,所以在目标中剔除乘加数。另外,之前的方法都是在尽量压缩参数量,这对多目标优化极为不利。在非损人不能利己的帕累托边界上,必须有舍才有得。文章认为,参数量是模型能力的表征,所以选择鼓励增加参数量反而能增大搜索范围,从而获得高参数但低时延的模型。
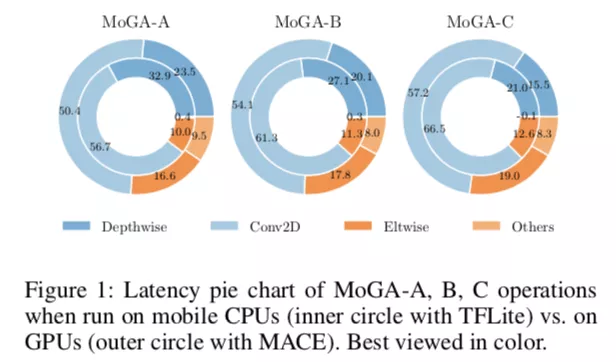
文章比较了 MoGA 三款模型在移动端 CPU 和 GPU 的各算子占比统计,证实了相同模型对不同的硬件上表现并不相同,Depthwise 和普通卷积在 CPU 上要花更多的比重,而 Elementwise 操作在 GPU 上要花更多时间。
文章的第三个不同之处是用加权的 NSGA-2 处理多目标优化。从实际使用角度出发,第一业务指标和运行速度是最重要的,所以对于多个目标也需要区别对待。本文采用了 2:2:1 的比重(acc, latency, params)。
NAS 方法基于先前的 FairNAS,引入了查表方式的 GPU latency,加权 NSGA-II,对 FairNAS 进行了迭代更新。
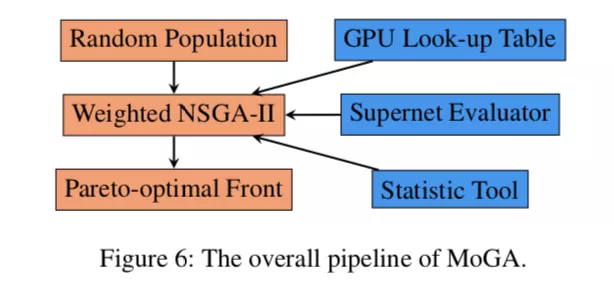
表 2 给出了 MoGA-A 的结构,可以看出在各层输入输出,还有下采样点及激活单元的使用上是对齐了 MobileNetV3。

图 9 给出了三款模型 MoGA-A,B,C 的可视化展示。
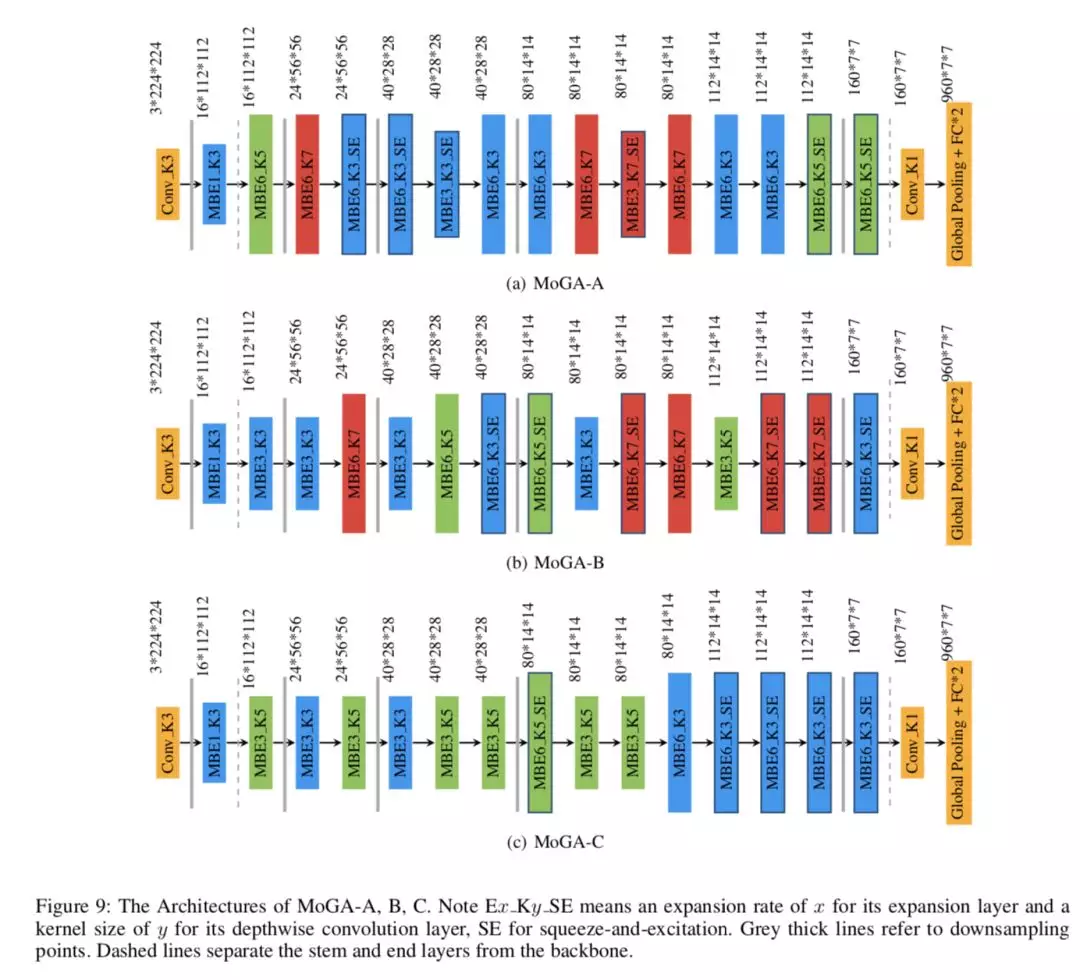
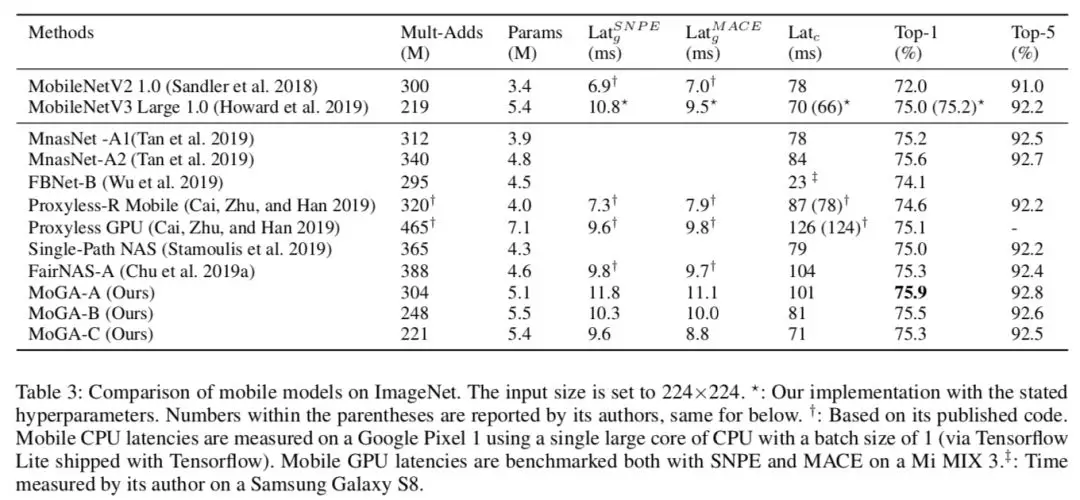
表 3 是对当前同量级 SOTA 模型的对比。MoGA-C 比 MobileNetV3 Large 有更高的精度,更短的移动端 GPU 时延(SNPE、MACE 结果一致),从 SNPE 结果看, MoGA-B 也超过了 V3,所以本文揭示了不仅要 GPU-Aware,还需要 Framework-aware,不同的框架对模型也有不同的要求。另外 300M 模型 MoGA-A 也是再次刷新记录,达到了 75.9%。
消去实验
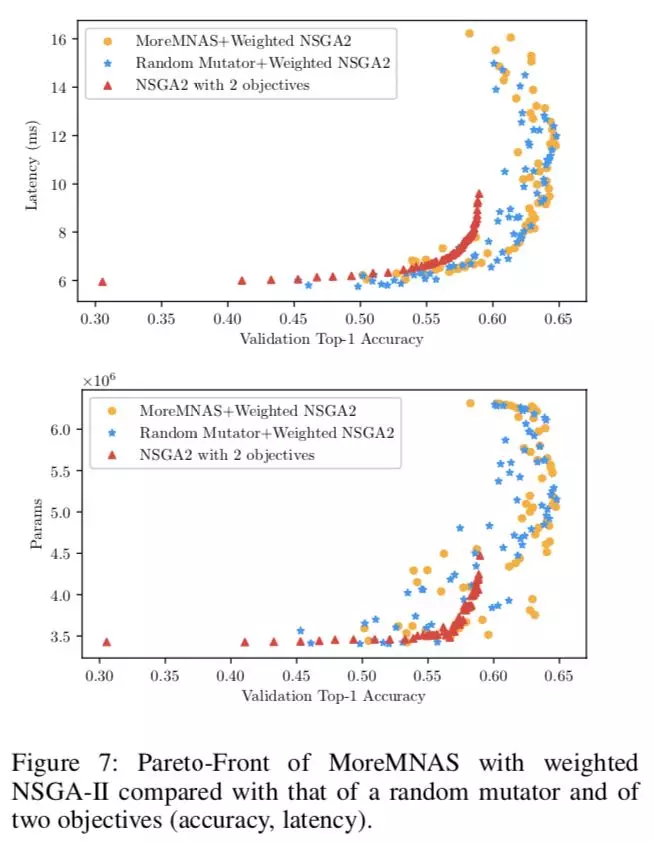
由于三个目标难以调和,所以可以观察到帕累托边界开始上扬,在加了目标权重之后,此现象有所缓解,但仍不能避免。
作者对比了 MoreMNAS、随机变异和只有两目标的情形。佐证强化+演化的加权 NSGA2 优于随机变异的加权 NSGA2,也说明只采用两个目标(acc,latency)会极大削弱搜索能力,鼓励增大 params 的三目标优化是所有方案中最优的。
总结
综上所述,MoGA 提出了移动端 GPU 敏感的 NAS,对多目标进行加权处理,鼓励增大参数量,使用了更新版 MnasNet 的搜索空间,融合了 V3 的激活单元和结构,方法是对 FairNAS 的改进和提升,在 ImageNet 1k 任务上刷新了 SOTA,最重要的是直接面向落地,而且模型代码和预训练权重都已开源。
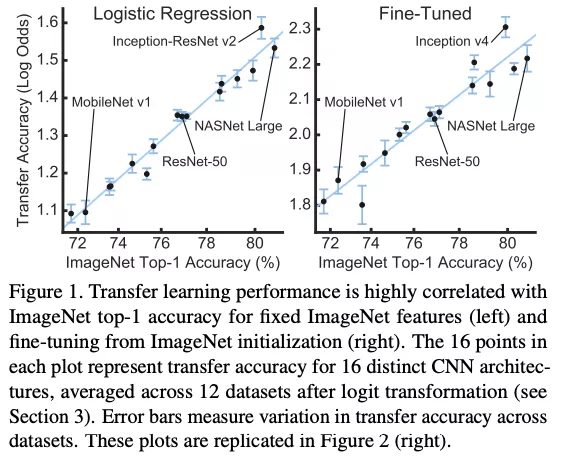
有同学担心通用任务上的模型能否直接应用于业务呢?Google Brain 最新的系统性研究给出的答案是肯定的:在 ImageNet 上表现好的 16 个经典结构在 12 个常用数据集上均表现出稳定的排名。
参考
1.Chu et al. MoGA: Searching Beyond MobileNetV3,http://arxiv.org/abs/1908.01314
2.MoGA 模型开源地址:https://github.com/xiaomi-automl/MoGA
3.Chu et al., FairNAS: Rethinking Evaluation Fairness of Weight Sharing Neural Architecture Search,https://arxiv.org/abs/1907.01845
4.FairNAS 模型开源地址:https://github.com/xiaomi-automl/FairNAS
5.Chu et al., Multi-Objective Reinforced Evolution in Mobile Neural Architecture Search,https://arxiv.org/abs/1901.01074
6.Andrew Howard et al., Searching for MobileNetV3,https://arxiv.org/abs/1905.02244
7.Kornblith et al., Do Better ImageNet Models Transfer Better,
https://arxiv.org/pdf/1805.08974.pdf

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论