在 LinkedIn 的数据基础设施中,Kafka 是核心支柱之一。来自 LinkedIn 的工程师曾经就 Kafka 写过一系列的专题文章,包括它的现状和未来、如何规模化运行、如何适应LinkedIn 的开源策略以及如何适应整体的技术栈等。近日,来自LinkedIn 的高级工程主管 Kartik Paramasivam 撰文分享了他们使用和优化Kafka 的经验。
LinkedIn 在 2011 年 7 月开始大规模使用 Kafka,当时 Kafka 每天大约处理 10 亿条消息,这一数据在 2012 年达到了每天 200 亿条,而到了 2013 年 7 月,每天处理的消息达到了 2000 亿条。在几个月前,他们的最新记录是每天利用 Kafka 处理的消息超过 1 万亿条,在峰值时每秒钟会发布超过 450 万条消息,每周处理的信息是 1.34 PB。每条消息平均会被 4 个应用处理。在过去的四年中,实现了 1200 倍的增长。
随着规模的不断扩大,LinkedIn 更加关注于 Kafka 的可靠性、成本、安全性、可用性以及其他的基础指标。在这个过程中,LinkedIn 的技术团队在多个特性和领域都进行了有意义的探索。
LinkedIn 在 Kafka 上的主要关注领域包括:
配额(Quotas)
在 LinkedIn,不同的应用使用同一个 Kafka 集群,所以如果某个应用滥用 Kafka 的话,将会对共享集群的其他应用带来性能和 SLA 上的负面影响。有些合理的使用场景有可能也会带来很坏的影响,比如如果要重新处理整个数据库的所有数据的话,那数据库中的所有记录会迅速推送到 Kafka 上,即便 Kafka 性能很高,也会很容易地造成网络饱和和磁盘冲击。
Kartik Paramasivam 绘图展现了不同的应用是如何共享 Kafka Broker 的:
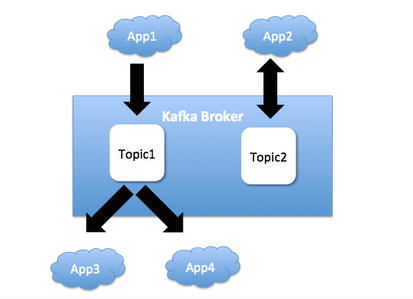
为了解决这个问题,LinkedIn 的团队研发了一项特性,如果每秒钟的字节数超过了一个阈值,就会降低这些 Producer 和 Consumer 的速度。对于大多数的应用来讲,这个默认的阈值都是可行的。但是有些用户会要求更高的带宽,于是他们引入了白名单机制,白名单中的用户能够使用更高数量的带宽。这种配置的变化不会对 Kafka Broker 的稳定性产生影响。这项特性运行良好,在下一版本的 Kafka 发布版中,所有的人就都能使用该特性了。
开发新的 Consumer
目前的 Kafka Consumer 客户端依赖于 ZooKeeper ,这种依赖会产生一些大家所熟知的问题,包括 ZooKeeper 的使用缺乏安全性以及 Consumer 实例之间可能会出现的脑裂现象(split brain)。因此,LinkedIn 与 Confluent 以及其他的开源社区合作开发了一个新的 Consumer。这个新的 Consumer 只依赖于 Kafka Broker,不再依赖于 ZooKeeper。这是一项很复杂的特性,因此需要很长的时间才能完全应用于生产环境中。
在 Kafka 中,目前有两个不同类型的 Consumer。如果 Consumer 希望完全控制使用哪个分区上的 Topic 的话,就要使用低级别的 Consumer。在高级别的 Consumer 中,Kafka 客户端会自动计算如何在 Consumer 实例之间分配 Topic 分区。这里的问题在于,如果使用低级别 Consumer 的话,会有许多的基本任务要去完成,比如错误处理、重试等等,并且无法使用高级别 Consumer 中的一些特性。在 LinkedIn 这个新的 Consumer 中,对低级别和高级别的 Consumer 进行了调和。
可靠性和可用性的提升
按照 LinkedIn 这样的规模,如果 Kafka 的新版本中有什么重要缺陷的话,就会对可靠性产生很大的影响。因此,LinkedIn 技术团队一项很重要的任务就是发现和修正缺陷。他们在可靠性方面所做的增强包括:
Mirror Maker**** 无损的数据传输:Mirror Maker 是 Kafka 的一个组件,用来实现 Kafka 集群和 Kafka Topic 之间的数据转移。LinkedIn 广泛使用了这项技术,但是它在设计的时候存在一个缺陷,在传输时可能会丢失数据,尤其是在集群升级或机器重启的时候。为了保证所有的消息都能正常传输,他们修改了设计,能够确保只有消息成功到达目标 Topic 时,才会认为已经完全消费掉了。
副本的延迟监控:所有发布到 Kafka 上的消息都会复制副本,以提高持久性。当副本无法“跟上”主版本(master)的话,就认为这个副本处于非健康的状态。在这里,“跟上”的标准指的是配置好的字节数延迟。这里的问题在于,如果发送内容很大的消息或消息数量不断增长的话,那么延迟可能会增加,那么系统就会认为副本是非健康的。为了解决这个问题,LinkedIn 将副本延迟的规则修改为基于时间进行判断。
实现新的 Producer:LinkedIn 为 Kafka 实现了新的 Producer,这个新的 Producer 允许将消息实现为管道(pipeline),以提升性能。目前该功能尚有部分缺陷,正在处于修复之中。
删除 Topic:作为如此成熟的产品,Kafka 在删除 Topic 的时候,会出现难以预料的后果或集群不稳定性,这一点颇令人惊讶。在几个月前,LinkedIn 对其进行了广泛地测试并修改了很多缺陷。到 Kafka 的下一个主版本时,就能安全地删除 Topic 了。
安全性
在 Kafka 中,这是参与者最多的特性之一,众多的公司互相协作来解决这一问题。其成果就是加密、认证和权限等功能将会添加到 Kafka 中,在 LinkedIn,预期在 2015 年能使用加密功能,在 2016 年能使用其他的安全特性。
Kafka 监控框架
LinkedIn 最近正在致力于以一种标准的方式监控 Kafka 集群,他们的想法是运行一组测试应用,这些应用会发布和消费 Kafka Topic 数据,从而验证基本的功能(顺序、保证送达和数据完整性等)以及端到端发布和消费消息的延时。除此之外,这个框架还可以验证 Kafka 新版本是否可以用于生产环境,能够确保新版本的 Kafka Broker 不会破坏已有的客户端。
故障测试
当拿到新的 Kafka 开源版本后,LinkedIn 会运行一些故障测试,从而验证发生失败时 Kafka 新版本的质量。针对这项任务,LinkedIn 研发了名为 Simoorg 的故障引导框架,它会产生一些低级别的机器故障,如磁盘写失败、关机、杀进程等等。
应用延迟监控
Consumer 开发了名为 Burrow 的工具,能够监控 Consumer 消费消息的延迟,从而监控应用的健康状况。
保持 Kafka 集群平衡
LinkedIn 在如下几个维度保证了集群的平衡:
感知机柜:在进行平衡时,很重要的一点是 Kafka 分区的主版本与副本不要放到同一个数据中心机柜上。如果不这样做的话,一旦出现机柜故障,将会导致所有的分区不可用。
** 确保 Topic的分区公平地分发到 Broker上:** 在为 Kafka 发布和消费消息确定了配额后,这项功能变得尤为重要。相对于将 Topic 的分区发布到同一个 Broker 节点上,如果 Topic 的分区能够均衡地分发到多个 Broker 上,那么相当的它有了更多的带宽。
确保集群节点的磁盘和网络容量不会被耗尽:如果几个 Topic 的大量分区集中到了集群上的少数几个节点上,那么很容易出现磁盘或网络容量耗尽的情况。
在 LinkedIn,目前维护站点可靠性的工程师(Site Reliability Enginee,SRE)通过定期转移分区确保集群的平衡。在分区放置和重平衡方面,他们已经做了一些原始设计和原型实现,希望能够让系统更加智能。
在其他的数据系统中,将 Kafka 作为核心的组成部分
在 LinkedIn,使用 Espresso 作为 NoSQL 数据库,目前他们正在将 Kafka 作为 Espresso 的备份机制。这将 Kafka 放到了站点延迟敏感数据路径的关键部分,同时还需要保证更高的消息传送可靠性。目前,他们做了很多的性能优化,保证消息传输的低延迟,并且不会影响消息传递的可靠性。
Kafka 还会用于异步上传数据到 Venice 之中。除此之外,Kafka 是 Apache Samza 实时流处理的一个重要事件源,同时Samza 还使用Kafka 作为持久化存储,保存应用的状态。在这个过程中,LinkedIn 修改了一些重要的缺陷,并增强了Kafka 的日志压缩特性。
LinkedIn 的 Kafka 生态系统
除了 Apache Kafka Broker、客户端以及 Mirror Maker 组件之外,LinkedIn 还有一些内部服务,实现通用的消息功能:
支持非 Java客户端:在 LinkedIn,会有一些非 Java 应用会用到 Kafka 的 REST 接口,去年他们重新设计了 Kafka 的 REST 服务,因为原始的设计中并不能保证消息的送达。
消息的模式:在 LinkedIn,有一个成熟的“模式(schema)注册服务”,当应用发送消息到 Kafka 中的时候,LinkedIn Kafka 客户端会根据消息注册一个模式(如果还没有注册过的话)。这个模式将会自动在 Consumer 端用于消息的反序列化。
成本计算:为了统计各个应用对 Kafka 的使用成本,LinkedIn 使用了一个 Kafka 审计 Topic。LinkedIn 客户端会自动将使用情况发送到这个 Topic 上,供 Kafka 审计服务读取并记录使用情况,便于后续的分析。
审计系统:LinkedIn 的离线报告 job 会反映每小时和每天的事件情况,而事件从源 Kafka Topic/ 集群 / 数据中心,到最后的 HDFS 存储是需要时间的。因此,Hadoop job 需要有一种机制,保证某个时间窗口能够获得所有的事件。LinkedIn Kafka 客户端会生成它们所发布和消费的消息数量。审计服务会记录这个信息,Hadoop 以及其他的服务可以通过 REST 接口获取这一信息。
支持内容较大的消息:在 LinkedIn,将消息的大小限定为 1MB,但是有些场景下,无法满足这一限制。如果消息的发布方和使用方是同一个应用的话,一般会将消息拆分为片段来处理。对于其他的应用,建议消息不要超过 1MB。如果实在无法满足该规则的话,消息的发送和消费方就需要使用一些通用的 API 来分割和组装消息片段,而在 LinkedIn 的客户端 SDK 中,他们实现了一种特性,能够自动将一条大的信息进行分割和重组。
目前,越来越多的国内外公司在使用Kafka ,如Yahoo!、Twitter、Netflix 和Uber 等,所涉及的功能从数据分析到流处理不一而足,希望LinkedIn 的经验也能够给其他公司一些借鉴。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 )。
)。




