

1.概述
假设你是一个科比布莱恩特的粉丝突然想回顾科比退役前最后一场比赛的所有精彩防守片段,你肯定不会想再花 2 个小时连同中场休息的广告一起把比赛视频再看一遍。再或者假设你是一个 24 小时营业的便利店店长想通过监控视频了解过去的一个月里哪些新品的广告更能吸引店里的顾客驻足关注,即使是以 32 倍速快进你都要花一整天才可以全看完。
随着大数据技术的发展,结构化数据得到了越来越广泛的应用,而对视频、音频等非结构化数据的信息挖掘现在还很不充分。随着人工智能技术的发展,对这些非结构化数据的分析手段的不断成熟,视频内容结构化的任务逐渐成为这几年研究的热点。视频结构化技术是指提取视频内容中的重要信息并进行结构化处理,采用时空分割、特征提取、对象识别等处理手段, 将视频数据重新组织成可供计算机和人理解的结构化信息。用一句话来概括视频结构化的作用就是让机器分析视频数据从而提取出画面中的具象含义。
2.视频内容理解中的关键技术
视频结构化技术涉及到从一串视频帧序列中分析,包含场景识别、人的检测识别、物体检测识别、动作事件识别、时序动作定位、异常检测、视频剪辑等多种任务。主流的方法有两种:一种逐帧融合的方法,是图像任务的一种自然扩展,即在多帧序列中进行图像识别,然后基于每一帧的结果聚合成分析结果;另外一种是 end-to-end 的模型,直接提取视频序列中的特征信息,并加以分析。
2.1 密集跟踪轨迹(Dense Trajectory)
密集跟踪轨迹算法[1],是利用每一帧的光流信息得到视频中物体的运动轨迹,再沿着轨迹提取特征(图 1)。

图 1
首先系统对整个视频序列进行光流场计算。通过对连续帧里每一个像素点计算场景中所有物体的三维运动向量在画面所在平面上的二维投影,这些二维投影所形成的向量包含了物体运动的速度和方向。接着从初始帧开始,每隔一定数量个像素进行像素点阵采样。最后对采样点进行跟踪,由光流判断跟踪点在下一帧的位置。
DT 算法由于其特征维度较高,对运算资源消耗过大,随着深度学习方法的崛起,DT 逐渐淡出了视野。
2.2 逐帧处理融合
逐帧处理然后融合特征的方法是把视频看作连续帧图像的集合,单独提取每帧的图像特征,最后再将所有特征融合。
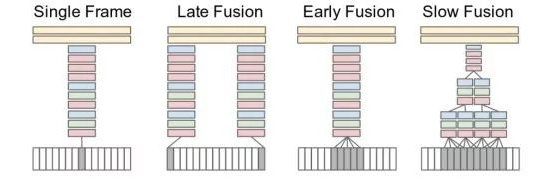
图 2
早期的研究分别有:逐帧提取图像特征(Single Frame),相距固定数量帧的图像分别提取图像特征然后融合它们的深度卷积特征(Late Fusion),直接提取连续多帧的图像特征(Early Fusion),和连续多帧图像在早期时候单独提取特征后期逐层合并(Slow Fusion)。实验发现,Slow Fusion 能够较好地保留时序信息,相比于其他三种方法是更为理想的模型(图 2)[2]。
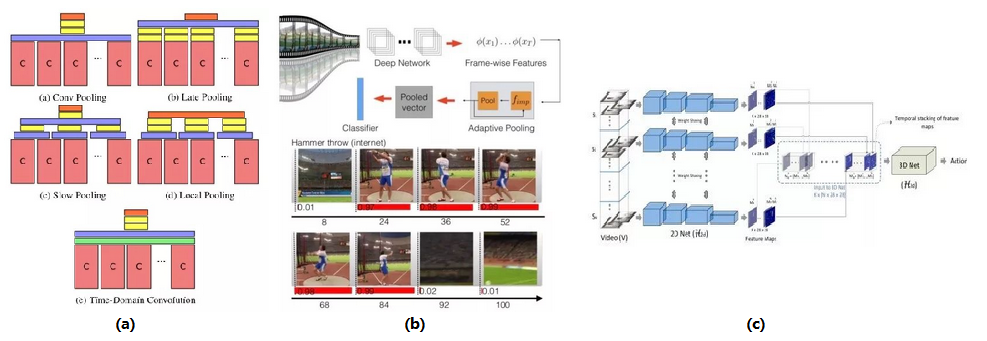
图 3
之后的研究还有基于 Slow Fusion 继续研究卷积层池化层结构的(图 3-a)[3],根据每帧图像的卷积特征的重要程度进行特征汇合(图 3-b)[4],和高效卷积网络(Efficient Convolutional network),从视频中采样若干帧单独用 2D 卷积提取特征后沿时间方向拼接,再用 3D 卷积捕获它们的时序关系,从而削减相邻帧的信息冗余(图 3-c)[5]。
2.3 3D 卷积
2013 年提出的 3D 卷积[6]是 single-stream 方法中比较成功的一种基础网络,其通过构建 3D 卷积神经网络提取空间信息和特征,用于动作识别、场景识别和视频相似度分析等领域。
C3D 特征是由 3D 卷积核而不是跨帧使用 2D 卷积的方式,从一组连续画面上按照时序获取的特征。区别于 2D 卷积核获取的图像特征,C3D 特征不但有每一帧高度抽象的图像特征,还包含了时间序列中的运动特征。
由于其可以一次处理多帧,在做 inference 时候的效率是相当高的,因此在工业界中得到了很广泛的应用。该网络想法虽然很简单,但主要问题则是参数量更大,计算资源的开销相对较高,需要更多的训练数据和训练时间。
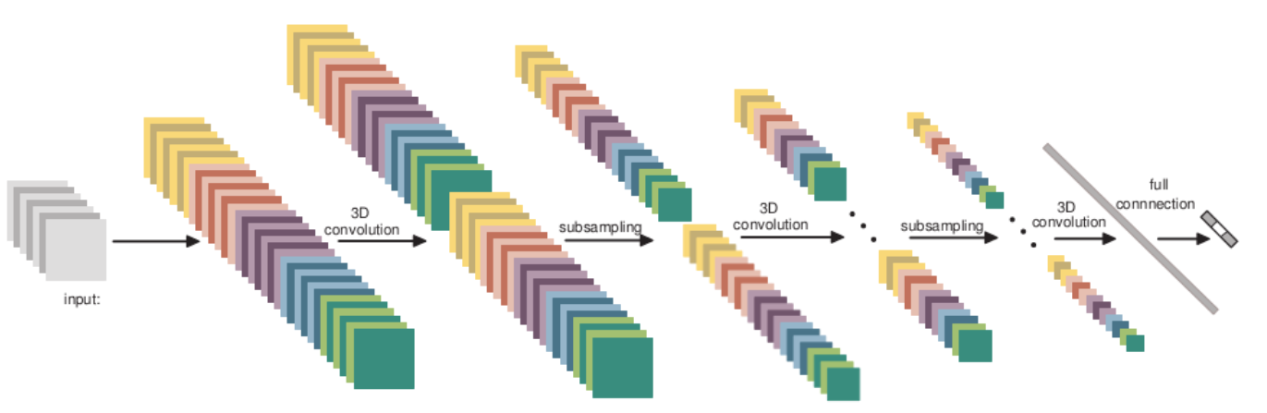
图 4
3D 卷积使用 VGG 骨干网络结构,运算复杂度较高,有大量的研究团队正在寻求更简洁的方法。最直接的想法就是把 3D 卷积分解为空间方向 2D 卷积和时间方向 1D 卷积来减少直接在三个维度上进行卷积计算的复杂度(图 5-a)[7],也有方法借鉴 inception 和残差网络的结构对 3D 卷积结构进行优化。有团队提出基于 2D ConvNet 的 Inflated 3D ConvNet 模型(I3D)。为了利用到现已成熟的图像分类网络结构,直接加入时序信息,将原本的 2D 卷积核和池化核扩展为 3D(图 5-b)[8]。还有团队提出伪 3D 网络 Pseudo-3D ResNet(P3D)。通过空间方向卷积和时间方向卷积组合成不同的模块结构。在模拟原本 C3D 的卷积核功能的同时,减少参数数量并提高运算速度(图 5-c)[9]。
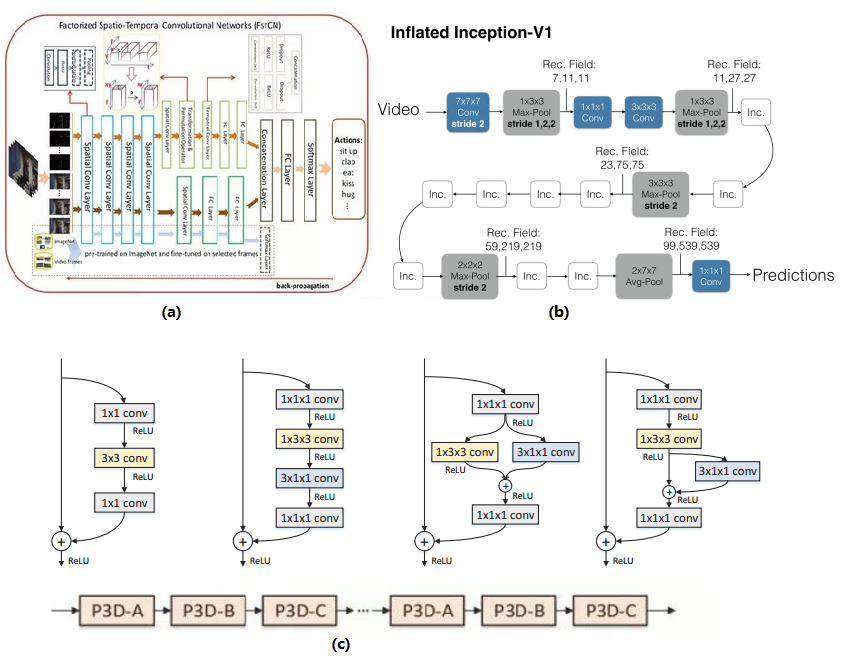
图 5
Non-local Neural Networks 方法通过改进卷积结构提升算法的效率[10]。由于传统的 3D 卷积只能在卷积核可以覆盖到的邻域时间空间内进行特征捕捉,感受野局限很大。Non-local 网络根据图像的自相似性,以图像块为单位在整个时序图像集中寻找相似的区域来计算邻域像素的权重。该方法获取像素点之间的依赖关系的同时也大幅降低了计算开销。Multi-Fiber Networks for Video Recognition[11]提出 MF-Net 结构在参数和计算量较低的情况下也取得了不错的效果(图 6)。

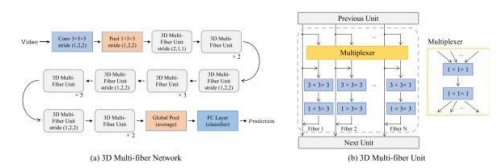
图 6
2.4 双流处理模型(Two-stream)
双流模型的特点是图像和光流双线同时处理:一边输入图像信息进行图像特征提取(空间流 Spatial Stream)另一边输入光流分析进行运动信息提取(时间流 Temporal Stream),然后将结果融合(图 7-a)[12]。之后还有研究团队针对融合方式有过研究,发现空间流和时间流在较浅的网络层融合和比在较深的网络层融合要效果好很多并且减少了计算复杂度(图 7-b)[13]。由于空间流和时间流的网络结构一致,处理的图像信息和运动信息可以完全对应上,有研究团队将双流模型和跟踪轨迹算法结合(图 7-c)[14],检测出图像中运动密集的区域,跟随光流场轨迹提取双流特征。
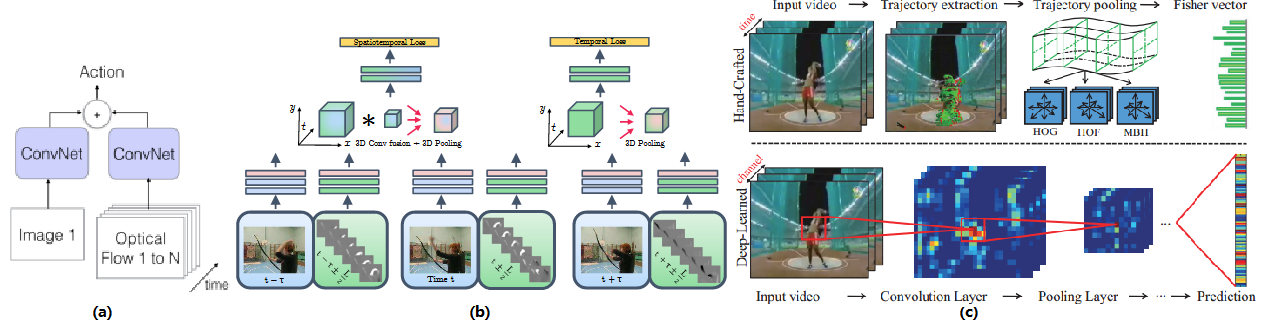
图 7
由于一个连续动作在相邻帧中的变化不是很大,这就导致了连续采样导致的信息冗余。Temporal segment networks(TSN)[15]结构对视频采样方式做了一定的优化,通过分割输入视频,从每个片段中随机选择帧,之后用双流结构提取空间和时间特征再融合。
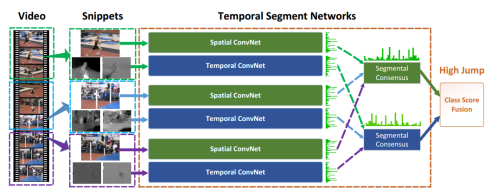
图 8
2.5 时序动作定位
随着应用场景的多样化,对视频结构化能力的要求也更加复杂。仅仅能检测出一个视频中正在发生哪一种行为事件已经不能满足 AI 研究者对神经网络能力极限的期望了,类似图像识别到图像检测任务的发展,对于视频数据,学术界也从分类任务关注到检测任务。一些研发团队正在试图将研究重点推进到精确定位事件的开始和结束时间。类似于目标检测的技术,对于时序动作定位的方法,其实也可以分为 two-stage 和 one-stage 的两种思路:一种为用不同大小的滑动窗生成若干 proposal slice,然后再用 3D 分类网络判断是前景还是背景(图 9-a)[16],另外一种是边界回归的方法(图 9-b)[17]。
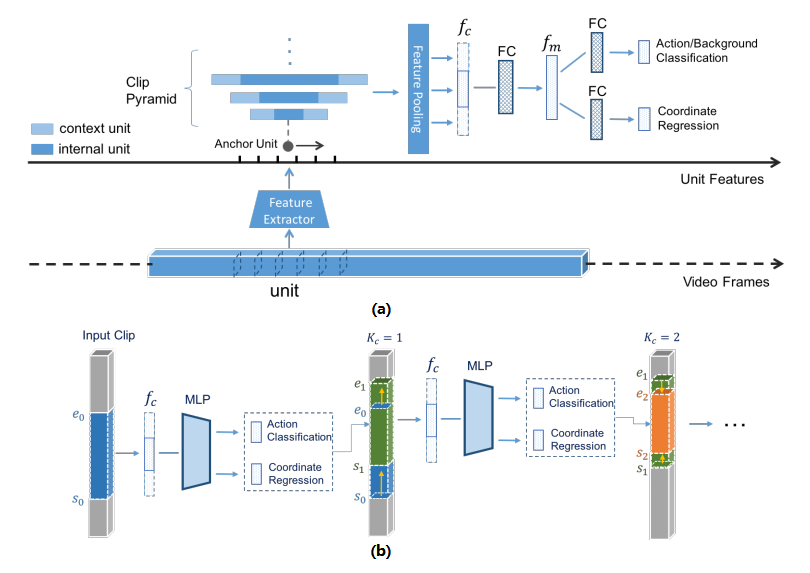
图 9
3.苏宁在视频内容理解中的技术应用
视频结构化技术在苏宁也有丰富的应用场景:苏宁线下有近万家门店,数十万摄像头,这些设备每天采集了海量的视频数据,挖掘这些视频数据的价值已成为“新零售”最重要的基石和战场,除此之外,苏宁的置业和物流每天也累计了大量监控视频数据。在线上,苏宁易购的直播和短视频频道以及 PPTV、PP 体育的版权视频每天也会产生大量视频资源。通过视频结构化以及智能分析技术我们可以实现门店的客流分析、商品热度分析,安防的视频结构化以及视频分类以及剪辑,提高了数据处理的效率的同时降低了人力成本。
苏宁的线下门店的规模以及人流量对我们的算法落地都提出了很高的要求。在门店场景,我们遇到的一个挑战是检测算法检测框精准度的问题,行人检测框的准确度对接下来做 reID 提取行人特征有较大影响,商品也需要进行主体检测进一步提高商品识别的准确性。Two-stage 的模型由于引进了 proposal 对 ROI 进行回归,所以对目标区域的检测框更加准确。同时,我们引入 soft NMS 的改进算法,将候选框的置信度与 IoU(Intersection over Union)相关联,进一步提高检测的准确率
我们面临的另外一个挑战是目标检测问题中的遮挡。对于遮挡,其实可以分为 occlusion 和 crowded。对于 occlusion,更多需要从数据的角度增加训练样本来提高模型的泛化能力对于 crowded 情况,从模型角度是有优化空间的。首先我们借鉴 DPM 经典算法的思想,对人体不同部位组件分开建模。其次,从损失函数对于候选框的惩罚的改进以及 ROI proposal pooling 设计,也可以使回归框更加接近 ground truth。

图 10
第三个挑战就是算法的复杂度与边缘计算节点的计算能力开销之间的矛盾。在线下场景我们大部分的采集设备都是摄像头,我们的算法需要对视频流进行分析,考虑网络带宽以及算法实时性的要求,我们大部分的算法计算尽量放在前端进行,云端则更多进行数据的整合以及统计工作。但前端计算节点处于功耗以及成本考虑,计算能力有限,这就需要对我们的算法进行进一步的优化。
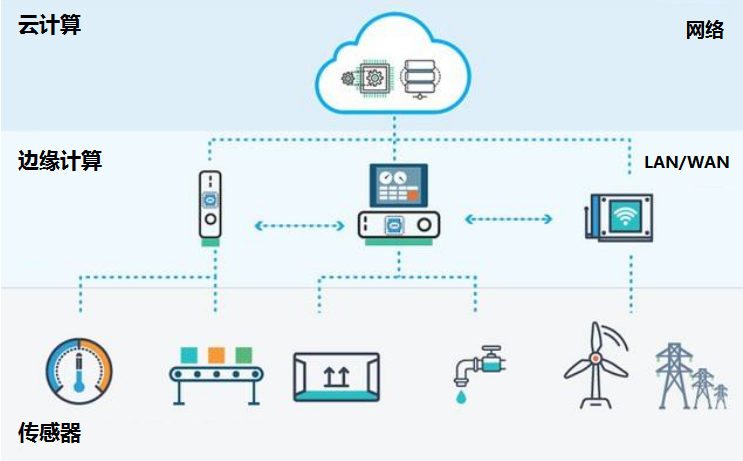
图 11
从模型考虑,我们除了常规的模型压缩手段,包括神经元剪枝、量化、网络编码以外,我们也进行了模型的网络结构的变换,比如对用于目标检测的网络,出于对检测框精度的要求,我们有些场景使用了精度更高的 two-stage 的方案,但我们实际发现,对于 ROI 区域获取后第二阶段的分类网络,做成级联结构可以有效降低网络复杂度的同时提高模型的效率。同时,我们也从代码层面进行优化,利用多线程、定点化、指令集加速等手段提高推理阶段的运行速度。
对于更高级的人与物的交互行为的识别,苏宁也在做一定的尝试。在门店购物流程和物流打包流程都有相关应用场景。在门店中需要识别出顾客对哪一种商品感兴趣,正在进行的动作是取出还是放回,物流仓储环境相对恶劣,要检测识别出形状各异的商品以及包装,还要对包装过程中的各种规范操作进行识别,这些都对算法提出了很大的挑战。我们采用了目标检测,物体识别算法得到基础的结构化数据,并结合业务逻辑进行过滤,对于动作的识别,我们通过深度神经网络单独训练了商品拿取动作以及异常行为动作的识别模型。除此以为,我们也在探索结合人体关键点检测和时序动作分析的神经网络来提高动作检测的准确性。

图 12
苏宁不但在线下场景有视频分析的需求,在线上苏宁同样拥有丰富的视频资源。苏宁易购的直播频道以及短视频入口,PPTV 以及 PP 体育丰富的视频资源都为视频分析提供了丰富的素材。拿足球赛事分析举例(图 13),我们首先利用目标检测以及跟踪算法识别球员身份、球门、捕捉足球运动轨迹等基础信息,并结合动作识别、动作检测、事件分析等语义分析算法,捕捉视频中的行为和关联关系信息,形成序列化的结构信息,辅以逻辑规则的先验信息进一步增加结构化数据识别的准确率,最终生成精彩动作集锦和内容解说。
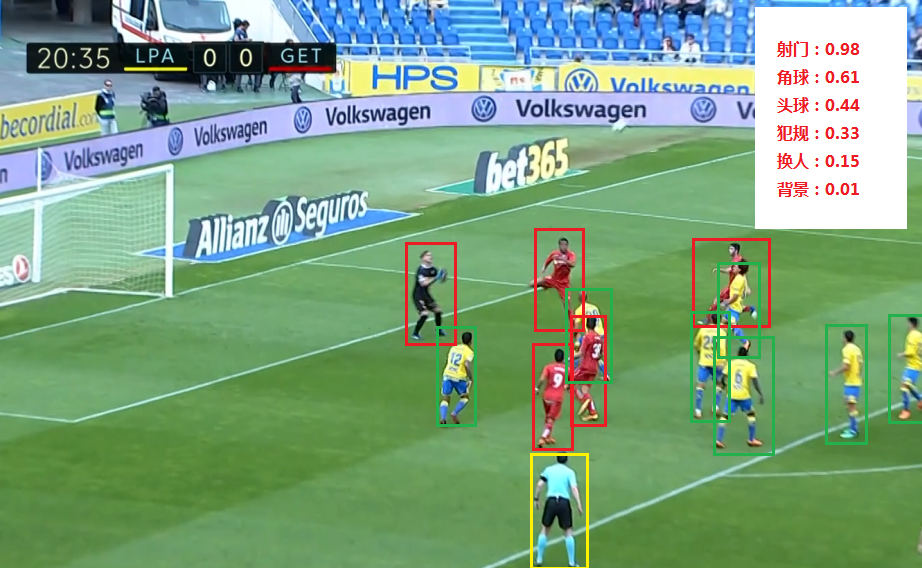
图 13
动作识别检测是整个链路中的技术难点,考虑算法的效率,我们采用基于 C3D 改进网络作为基础模型,通过添加时域分水岭算法优化事件分类和时序动作边界(图 14),纠正 C3D 误识别导致的识别结果抖动,保证了事件的完整性。
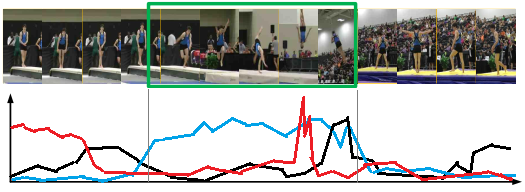
图 14
4.展望
尽管深度学习在图像处理领域取得了很大的突破,但在视频分析还有很大的提升空间。
4.1 骨干网络结构
不同于图像识别领域中性能卓越的 CNN 网络,在视频分析的任务中,深度学习算法还缺乏一种通用有效的骨干网络。无论是 LSTM 这样的时序模型,还是 3DCNN 这样的卷积网络,或者通过 two-stream 利用光流信息来增强运动捕捉能力,这些模型在对视频上下文信息的理解中还没有取得一个令人满意的效果,对于摄像机的姿态变化也不够鲁棒。视频分析网络结构的发展目前很重要的一个热点是对视频冗余信息的处理,通过借鉴视频编码中到技术思路,或者通过增加注意力机制捕捉时序中的关键帧和画面中的局部重要信息,过滤视频中的冗余信息,苏宁在这方面也在积极的尝试。
4.2 视频数据集
ImageNet 促进了图像识别技术的快速发展,MS-Celeb 又大大加速了人脸识别算法的指标提升。一个优秀的公开数据集可以很大程度推动算法模型的演进升级,视频分析领域缺乏优秀的基础模型,很大原因也是受限于该领域数据集的规模和质量。学术界目前较常用的动作视频库有体育运动类 Sports-1M、日常生活场景类 ActivityNet 等,这些数据集在规模上还是视频内容的覆盖度都远没有达到 ImageNet 的质量。视频数据的收集以及标注难度更大,要求更高。苏宁通过线下门店、物流仓储、pptv、pp 体育等场景,收集海量的视频资源,这些真实场景的视频数据资源,不但是智慧零售的数据金矿,也是做算法分析的重要保障。新搭建的苏宁数据标注平台也实现了业内领先的视频标注工具,使得标注流程更加智能更加规范,最大限度降低人工介入引起的误差。
4.3 实际应用的工程问题
视频的分析除了关注图像细节信息还要关注视频上下文,这导致计算复杂度成指数倍增加。主流的工程方案是将视频进行离线处理,受算力限制,目前对在线视频的实时处理还比较难实现。另外在真实场景中存在很多长度不一致的视频应用,对于一部电影或者一场球赛的视频处理需要消耗大量的计算资源。对于不定长的视频以及长视频的分析,目前也缺乏行之有效的算法工程框架。
4.4 动作预测
现有视频处理分析更多扮演“事后诸葛亮”的角色,更难到动作预测视频分析目前研究的还很少。动作预测的算法对时序信息的挖掘能力要求非常高,一个算法只有在有限的数据中有效提取出足够的时序特征,总结出运动模式的特点,才能够准确预测出下一个动作发生的位置、轨迹和时间。现在已有研究团队采用 LSTM 等网络并利用深度强化学习研发动作预判,但是为了达到理想的效果还需要更多新的尝试。如果动作预测算法趋于成熟,可以大幅提高智慧营销到即时性和客户的体验,在安防预警、门店营销、人机交互等领域都对该项技术有很广泛的需求。
4.5 图像和音频结合
近几年计算机视觉的顶会上也出现了有关声音图像文本结合的研究。医学和心理学研究也曾表明过在人类通过视觉认知的同时,听觉也起到了一定的辅助作用。视频作为一种包括了图像声音的多模态数据,在多物体识别中也可以借鉴人类认知的原理,使用音频信息辅助视频分析,最大化利用输入数据包含的信息。图像和音频等多媒体技术的结合发展潜力巨大,可以弥补现有纯视频处理算法的缺陷,还能够覆盖大量全新的应用场景。
5.参考文献
[1] H. Wang, et al. Dense trajectories and motion boundary descriptors for action recognition. IJCV’13.
[2] Le, et al. Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis. CVPR’11.
[3] J. Y.-H. Ng, et al. Beyond short snippets: Deep networks for video classification. CVPR’15.
[4] A. Kar, et al. AdaScan: Adaptive scan pooling in deep convolutional neural networks for human action recognition in videos. CVPR’17.
[5] M. Zolfaghari, et al. ECO: Efficient Convolutional network for Online video understanding. arXiv:1804.09066.
[6] S. Ji, et al. 3D convolutional neural networks for human action recognition. TPAMI’13.
[7] L. Sun, et al. Human action recognition using factorized spatio-temporal convolutional networks. ICCV’15.
[8] J. Carreira and A. Zisserman. Quo vadis, action recognition? A new model and the Kinetics dataset. CVPR’17.
[9] Z. Qiu, et al. Learning spatio-temporal representation with pseudo-3D residual networks. ICCV’17.
[10] X. Wang, et al. Non-local neural networks. CVPR’18.
[11] Y. Chen,Y. Kalantidis,J. Li ,S. Yan,J. Feng, Multi-Fiber Networks for Video Recognition. ECCV’18.
[12] K. Simonyan and A. Zisserman. Two-stream convolutional networks for action recognition in videos. NIPS’14.
[13] C. Feichtenhofer, et al. Convolutional two-stream network fusion for video action recognition. CVPR’16.
[14] L. Wang, et al. Action recognition with trajectory-pooled deep-convolutional descriptors. CVPR’15.
[15] L. Wang, et al. Temporal segment networks: Towards good practices for deep action recognition. ECCV’16.
[16] J. Gao, et al. TURN TAP: Temporal unit regression network for temporal action proposals. ICCV’17.
[17] J. Gao, et al. Cascaded Boundary Regression for Temporal Action Detection. CVPR’17.
作者简介:
董昱青,美国宾夕法尼亚州立大学电子工程信号和图像处理硕士、南加利福尼亚大学计算机科学硕士。苏宁人工智能研发中心视觉算法工程师。研究方向包括生物特征和信号处理,图像特征识别。曾在 ISCAS 2015 IEEE 和 Asilomar 2016 会议上发表学术论文。
杨现,中科院半导体所博士毕业,苏宁人工智能研发中心计算机视觉算法专家,负责计算机视觉在苏宁线上线下的应用落地,在图像识别、目标检测跟踪、人脸识别等研究方向上有丰富的实战经验。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 2 条评论