

最近人工智能得到了爆发式的发展,这个背后的主要的原因,就是因为互联网的发展速度之快,使得我们能够快速的堆积数据,同时加上硬件的快速发展,以及神经网络训练方式的革新,使得我们有能力能够训练比较深的神经网络,产出了能够具有突破人类“智能”的模型,并且广泛落地到了实际应用中。
在这个趋势下,算法以及背后的工程体系更加的收拢,促成了 TensorFlow,PyTorch 等深度学习框架的诞生和流行,从而使得进行深度学习应用开发的门槛进一步的下降,原有人工智能的算法结构创新,变得并不是那么高不可攀,如何能够将 AI 的工程化做到更大普惠化,成为人工智能研发的关键。
同时随着 Transformer 以及 Bert 等训练方式的创新,大规模预训练模型以及从大模型进行场景化蒸馏进,而产生垂直场景的 AI 应用,已经渐渐成为人工智能研究标准流程,那么 AI 的工程如何能够有效支撑超大规模预训练,成为另外一个关键。
因为大规模预训练模型需要耗费大量算力资源,AI 工程需要通过云化方式来提高算力的共享,利用云良好的弹性,共享性和互通性来降低研发成本,阿里巴巴机器学习平台 PAI 就是在这样的需求理解上,构建自己 AI 系统的建设,提高 AI 工程化的能力和效率。
我觉得做深度学习框架其实有两个派别的人,一派是做分布式系统的人来做的,另外一派是做算法的人来做的。不同的人的背景不同,所以做这个事情的角度也会不同,从而产生不同门派。TensorFlow 属于系统派,而 PyTorch 属于算法派。像我们这种做系统,特别是做过超大规模分布式系统的人,往往最担心的就是,当你要对一个已部署在成千上万台的计算集群上的平台软件,需要做重大重构的时候,如何保证重构和迁移能够更灵活顺畅的进行。
这个中间的困难没有做过这个事情的人可能不会太有体感,这么大一个平台,公司财力不可能让你去通过镜像一个个集群的方式来完成任务的迁移,并且越大公司的平台上用户数众多,业务都会耦合在一起去完成公司的使命,基本上你不可能有时间点可以让全公司的业务团队都放下他们自己手头的优先级,来配合你做这种迁移,哪怕你工程能力非常强,也不敢百分百的确保这种迁移中间不会出现任何意外,而对于很复杂的系统来说,要做到这一点基本上就更难了。
所以我们做系统的,往往会在系统设计阶段就有所考虑,把系统设计得更加具有可扩展性,从而尽最大可能去避免出现这种大的重构和推倒重来。当我们在面对需要构建一个深度学习框架的时候,我们第一时间就在设想这个框架需要能够(从规模上)很好支持分布式,能够很好的扩展到任意大的深度模型的框架,我们希望构建一个系统,(从模态上)能够像人脑一样能够把视觉,语音,语言等多种模型能够一同训练。其实这个就是 TensorFlow 这样系统构造的时候的原始想法,把整个计算构成一个 Tensor 的 Flow 图。
因为分布式本身就很复杂,需要处理各种节点相互的数据和执行中的各种依赖关系。这些事情由人来写代码,太繁琐且容易出错,所以自然地,我们就会设想由系统来负责这种依赖关系。这也就是为什么我们希望整个分布式执行的计划是一个静态图,然后系统再根据用户指定的或者系统智能的决定的 placement 进行分图,并在这些分图中添加合适的 Send-Recv 的 OP,从而构成一个分布式的执行计划。
但是这样的设计理念也会带来一些困扰,我们在模型训练时候,有时候有些类似控制图的部分,在这种设计理念下,我们必须要把这些控制流图的代码也 OP 化,然后把这些 OP 也整体串联在 Tensor 的 Flow 执行图中。大家有兴趣了解细节的话也可以看看论文《Dynamic Control Flow in Large-Scale Machine Learning, Eurosys2018》,不过这种方式会使得一些习惯单机开发的研究人员觉得比较晦涩。
同时也是因为分布式的原因,我们做系统的很自然会把模型的开发过程分成构图和执行两个阶段。构图的时候只是生成一个逻辑执行计划,然后通过显式方式的提交(或者 execute)过程进行执行。
这种方式让研究人员觉得不能一边写代码一边就能够马上看到代码片段的结果,所以这也造成很多人诟病 TensorFlow 的模式不太容易调试自己模型程序的原因,其实这也对分布式带来负担。
但是 TensorFlow 也有很多优势,因为 TensorFlow 是静态图的方式,(带来好处之一就是)其可以做到训推一体,正在训练出来的模型能够导出模型图,并且在这个图上进行系统化的推理优化,从而能够非常方便部署到线上。这个系统性的方法,对于工程化也是另外一个优势。
框架的另外一派是算法派,特别是感知类模型(图像,语音,语言类)训练,因为这类训练一般都是同步训练,然后“分布式训练”也不像系统派那样设想是任意异构的分布式执行图(即每个分布式节点的执行逻辑可以不同),而只是需要数据并行,这样我们就可以利用 MPI 的 AllReduce 的通讯源语来进行梯度的汇集计算。
算法同学需要一种丰富的可扩展的在 GPU 上能够很好运行的,并且能够很好进行自动梯度的算子库,并且因为面向是数据并行的场景,这样的话在神经网络部分其实都是单机程序,从而可以利用任何 python 的语法糖去构建任何的动态的训练控制逻辑(大家也把这种称作动态图),对于算法研究人员来讲,这种方式写代码比较随性也方便调试,所以在研究界 PyTorch 得到大量的关注和使用。
刚才说过 TensorFlow 从设计之初就在考虑可以超大的模型分布式训练的场景,但是没有预想到硬件的发展也非常迅速,显存越来越大以及训练技术的发展,还有非常精细化优化显存的工作,比如 DeepSpeed 等,把 optimizer 所需要的显存 sharding 化掉,使得除了超大规模稀疏模型训练外,感知类的 SOTA 模型一直可以利用数据并行的方式来进行训练。从而使得 TensorFlow 这种设计理念看上去有 overdesign 的嫌疑。
并且就算超大规模稀疏模型训练,因为 TensorFlow 整体化的设计理念,不把 Parameter Server 作为游离在 Flow 图之外,使得他在超大规模场景下的(限制了它)scalability 上出现了问题,从而催生一堆自建 PS+深度学习框架的(稀疏)模型训练框架。
好在随着 Transformer 的出现,我们终于有方法能够回归到最初那个梦想,使得我们可以把多种数据(图像的,文字的)合在一起训练多模态的模型,因为问题规模的增大,必然需要更多参数的模型来支持,所以我们迅速将模型大小从几十亿增加到万亿规模,这个时候就必然需要能够支持很好模型的并行框架,这也是为什么最近这个领域重新变得火热,比如类似 OneFlow,MindSpore,PaddlePaddle,Mesh Tensorflow,GShard,以及我们阿里的 Whale 框架。
其实从设计理念来看,模型并行正是回归到原来 TensorFlow 一开始设计时候的设想,只是那个时候因为模型并行的需求不够,没有必要提供比较好高层自动分布式的抽象,写模型的人还是可以自己精细化去构造每个计算节点的子图,整体上 TensorFlow 的框架只是负责把这些子图能够自动通过 Send-Recv 进行连接,并且在 Runtime 能够合法的进行计算。
而现在,因为需求增多,算法迭代需求的增多,迫切需要一种高层次的自动分布式框架,从而使得算法同学能够去快速简单构造一个逻辑图的方式,去构造自己神经网络,而由系统层来进行复杂模型并行的构成。
所以其实可以看到 TensorFlow 的设计理念正好就是为这个考虑的,利用静态图,我们可以逻辑性去描述一个网络训练,然后在执行时候在进行系统化的分图和分布式训练。所以说自动分布式的需求并没有超越原来设计的基本范畴,也是因为这样,我们采取和谷歌 GShard 类似技术路线去提供自动分布式的能力。正是站在原有框架基础上去做增量。
不同于 GShard 更加关注于谷歌 TPU 集群,我们关注于异构的 GPU 集群,这里所说异构是因为我们不如谷歌这么有钱,构建非常大的同构化 TPU 集群,我们集群中有不同年代的 GPU 和 CPU,这些 GPU 各自算力和显存都大小不一。
也正是因为这样,其实给我们系统提出更大挑战,我们在进行自动分布式时候需要在 cost model 上考虑好这些差异点。这样才能做到比较优化的分布式训练。这也是我们自动分布式框架 Whale 一种差异性和核心能力之一。
其实系统派的框架和算法派的框架也在进行一定的融合,TensorFlow 提出了 Eager 模式,通过 TF.Func 在 Eager 模式下可能单步执行计算,得到 Tensor 来提高可调式性;而 Pytorch 通过 Trace 或者 Parse 的方式转化为 TorchScript 的图描述,从而能够更好支持训练到推理的工程化。
但是这种动静结合其实只是在一定层次的,比如如果考虑分布式,Trace 的方式去得到 TorchScript 就不足够。需要进一步去限制构图能够使用的 API,这也是像 NVIDIA 的 Megatron 以及微软 DeepSpeed,在 PyTorch 上去支持分布式所带来的一些约束,感兴趣的可以读读 OneFlow 的 Blog,《Dynamic Control Flow in Large-Scale Machine Learning》
所以我们认为现在深度学习框架中两个主要流行的框架 TensorFlow 和 Pytorch,是有其设计理念原因的。我们做 Whale 正是在这种理解的基础上进行路线选择,并且认为应该站在已有的 TensorFlow 工作基础上去做增量的东西。而不是再去造一个别人做过的轮子。
我们认为当前深度学习已经进入到超大规模预训练模型时代,在这个时代下,如何加速预训练模型的迭代,从而掌握人工智能上游的预训练模型的研发就成为关键。因为这些模型训练都需要比较复杂的模型并行方式来进行训练,所以如何能够降低甚至是对于算法同学能够隐含分布式训练的复杂,使得算法同学仅仅需要关注建模代码构建,而由框架来自动进行分布式从而加速模型结构迭代。
不同于 Megatron 优化一个定制的模型分布式训练,Whale 可能在特定模型上,d 训练的自动分布式做不到最优,但是我们可以支持模型的快速的迭代,从而推动算法和系统协同优化,而在这个层面上就能够和算法同学一起快速找到一个更加合适分布式的模型结构,而这个层面得到的训练加速比可能是一个量级的提升,这也是 Whale 能够快速几个月时间,把阿里巴巴的多模态预训练模型从几亿快速提升到千亿参数规模,并且利用算法和系统的协同优化,利用 480 张卡就能训练出比肩 NV3072 卡训练出来的模型的核心原因。
以下是阿里自研分布式训练框架 Whale 整体的架构图:
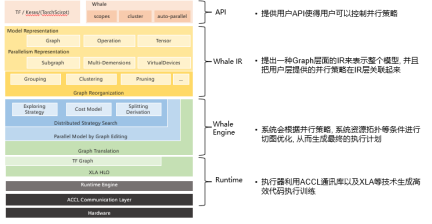
Whale 会将已有的静态图结构转化成 IR 描述的逻辑执行计划,然后系统会根据自动规划出来的并行策略,对于执行计划进行切图,并且把系统资源进行相应的划分,然后把切图的结果和资源进行相应的绑定,从而生成最终的执行计划。
就如同我们说的 Whale 设计的一大目标就是希望是个 scaleup 的解决方案,可以让用户写的单机单卡模型程序,能够自动扩展到分布式训练上,从而完成比较自然的程序的 scaleup 的过程。这样就能极大加快模型开发迭代速度,从而研究者可以先在单机上去聚焦模型本身的特性,比如收敛性,模型效果,模型研究方向是不是对头等等。
到了需要把模型规模扩大的时候,算法工程师只是需要扩大 Tensor 的 Shape,或者扩大模型结构的堆叠,系统就会根据模型结构的特点,结合数据并行,流失线并行,算子切分,混合并行,显存优化等方法,通过 Cost Model 选择一个合理的分布式训练的方案来自动分布式化,取得一个不错的训练加速比。
当然我们系统工程师都知道这个自动化其实是非常难的,因为要考虑不同切图情况,显存消耗,数据 IO 的范式,计算的瓶颈都是各自不同的,有时候分布式专家相比系统,在一些关键点,能够进行更好的指导,所以 Whale 把进行分布式策略探索中,如何描述切图的 subgroup,如何描述资源组成的 virtual device 以及进行各种并行策略,进行了用户层的暴露,然后用户可以在原有构建模型的过程中,可以通过 python 的 with 字句进行这些 annotation 和静态图的节点进行绑定,从而来指导系统,达到更好的更可控的分布式优化结果。随着系统自动优化的成熟,我们可以期待这种 annotation 将会越来越少。
同时因为大规模分布式训练对于资源消耗非常大,所以我们自然会在一个共享的大集群上运行训练,这样集群时时刻刻都会在不同的任务在上面去跑,用户得到的资源其实是一个动态的,并且考虑到硬件发展很快,比如 NVIDIA 的硬件基本上是半年一代,我们购买的硬件在数据中心平均使用时长是 3 年,这样就必然造成我们集群是多种 GPU 卡型共存的集群,加上有多种任务在集群中跑,必然造成资源有时候会有碎片的出现(即便调度器会极力去避免),这个时候我们是没有办法事先知道集群资源的情况,而系统自动优化能够更好适应资源实际情况,生成一个更加优化的分布式训练方案。
更进一步,如果我们希望调度器能够提供更大可能性,我们可以把不同任务装箱在一起,去共享 GPU 等计算资源,我们其实会把自动分布式和调度以及编译结合在一起。调度器可以给出不同的资源调度的计划,资源的上限限制,然后自动分布式通过这些约束结合编译器来生成不同执行计划,最后在全局上选择一个优的执行计划。从而能够达成全局最优而不是局部最优。当然现在离这个最终目标还有不少的工作需要去做。
总结下,我们认为未来 AI 的模型发展方向会从单机训练向大规模分布式训练发展,通过大规模预训练模型+小样本的蒸馏的模型开发流程将会成为主流。
在这个潮流下,我们需要有个更好的(自动)分布式框架能够让算法开发人员继续能够聚焦在模型结构的设计上,而由系统上进行有效自动分布式,这个易用性比并行化一个固定模型结构将会更加重要,从而推动算法的快速迭代。并且因为大规模分布式训练对于资源渴求,我们需要依托云的弹性构建一个共享的大的集群来激发算法的研究。
正是根据这些思考,阿里巴巴机器学习平台 PAI 会持续进行 AI 工程化建设,通过调度和分布式编程范式的规模化建设,数据和算力的云原生化建设,以及上层算法开发和服务标准化和普适化建设,从而使得算法能够关注他们要做什么,由系统来优化如何高效、低成本来执行模型训练和推理。
注:本文源自林伟的知乎:https://zhuanlan.zhihu.com/p/375634204 , InfoQ 经作者授权转载
作者介绍:
林伟,阿里云智能研究员,阿里云机器学习 PAI 平台技术负责人,主攻大规模分布式训练加速、编译优化等 AI 工程的建设和性能优化。具有大规模并发系统有 15 年的系统架构设计及研发经验,并在国际一流 ODSI、NSDI、SIGMOD 会议上多次发表论文。原微软大数据平台组的核心成员,曾在微软亚洲研究院和微软美国工作 10 年,一直从事分布式系统开发和大数据平台的相关工作。如果大家对于我们 PAI 团队的工作有兴趣,非常欢迎和我们联系,我的邮箱是 weilin.lw@alibaba-inc.com

InfoQ高级技术编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论