

引言
过去 6 年,达达集团秉承“万千好物 即时可得”的初心和愿景,不断迭代和升级技术能力,持续提升履约效率和服务体验。为保障系统持续稳定和业务不间断地高效运行, 我们在数据库高可用架构升级、数据库垂直/水平拆分、 微服务治理及可观测性、容量弹性和多活容灾等方面进行了不断实践并取得一定成果。
本文主要分享达达在双云双活容灾能力建议方面的实践和经验。
为什么做双活?
首先,介绍一下高可用(High Availability)和容灾(Disaster Recovery),两者相互联系、相互补充,但也有明显区别:
从故障角度看,高可用主要处理单组件故障导致的负载在集群内服务器之间做切换,容灾则是应对大规模故障导致的负载在数据中心之间做切换。
从网络角度看,局域网是高可用的范畴,广域网是容灾的范畴。
从云的角度看,高可用是一个云环境内保持业务连续性的机制,容灾是多个云环境间保持业务连续性的机制。
从目标角度看,高可用主要是保证业务高可用,而容灾则是在保证数据可靠的基础上,业务对外连续可用,以尽可能降低 RPO(灾难发生时丢失的数据量)和 RTO(灾难发生时系统恢复时长)。
由此,我们可以看出,高可用往往是指本地的高可用系统或架构,表示在任一服务器出现故障时,应用程序或系统能迅速切换到其他服务器上运行的能力;而容灾是指异地(同城或者异地)的冷备/热备/双活系统,表示在大规模集群或云级别灾难发生时,数据、应用和业务在灾备数据中心的恢复能力。容灾通常可以从网络接入、应用治理、主机、数据存储等层面去实施,业界如大型银行的“两地三中心”同城双活+异地灾备、蚂蚁金服的“三地五中心”异地多活、饿了么的北京上海双机房“异地双活”都是典型的容灾架构方案。
从支付宝 527 大规模宕机事故、携程 528 数据库全线崩溃、AWS 北京光缆被挖断、腾讯云硬盘故障、谷歌云 K8s 服务(GKE)宕机 19 小时不可用、微盟删库事件,再到近期的华为云香港机房因制冷设备故障导致整个机房崩溃,无论是天灾,还是人祸,居安思危并建立容灾能力对一个企业的重要性是不言而喻的。
达达在 2017-2018 年饱受网络故障之苦,如云网关组件故障、NAT 网关故障、单运营商线路网络连接故障等,这些问题往往让我们束手无策。为规避单云灾难级风险,我们在调研并比较业界容灾方案后,最终选择双云架构做同城双活的探索。
双云双活一期
双活一期主要是围绕服务双云部署、业务分流和接口功能/性能等方面的探索验证。
双云双活一期架构图
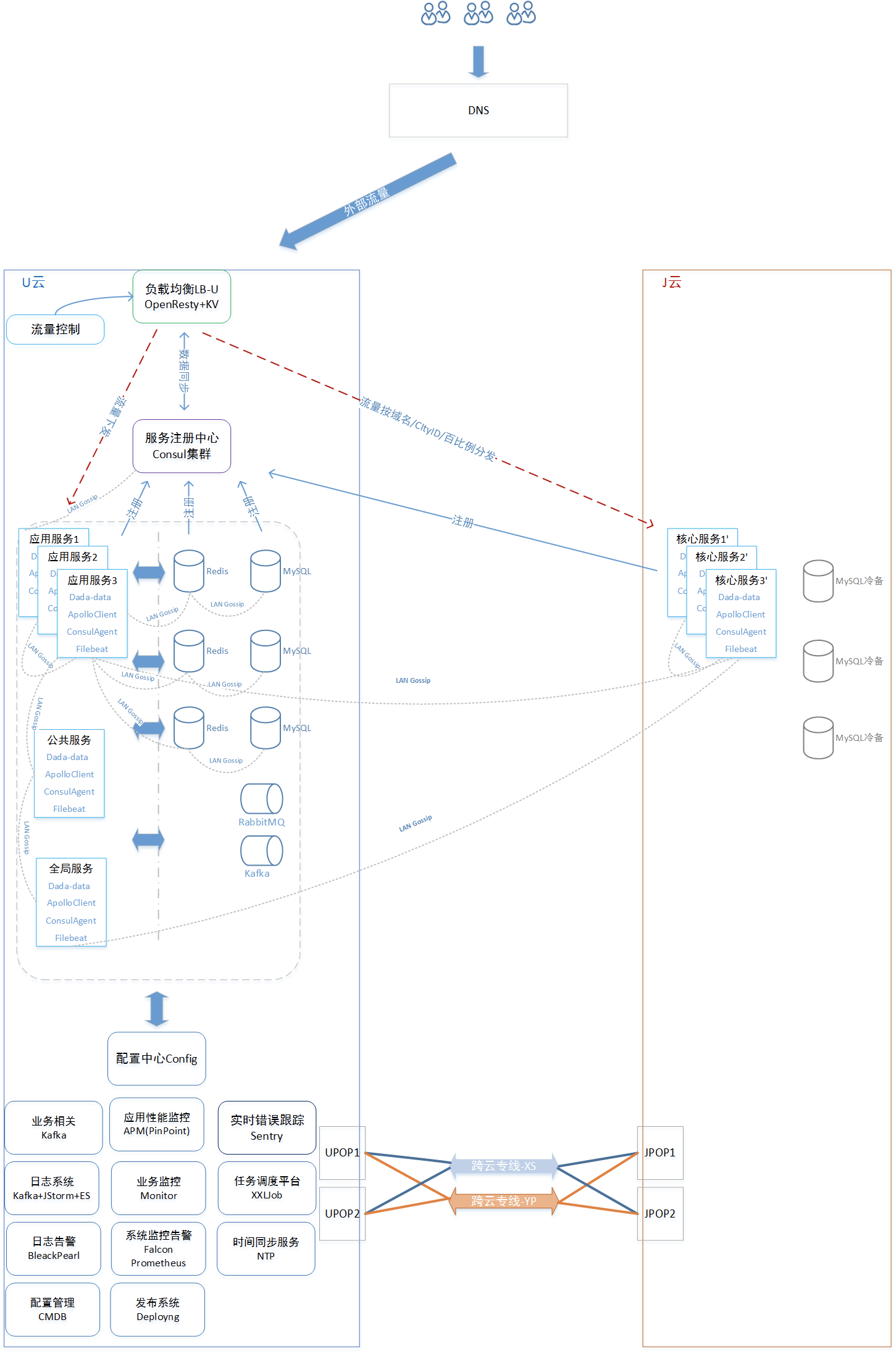
双云双活一期方案细节
双云双活一期方案主要有以下几个方面:
跨云专线:双云间通过 2 家供应商建立了 4 根高可用的跨云专线,带宽 4Gb,时延 3-4ms
服务注册:达达重度使用 Consul,并基于 Consul 1.1.0 版本二次开发,实现了服务注册发现、链路隔离、数据源发现和高可用切换等高级功能。Consul 采用一致性算法 Raft 来保证服务列表数据在数据中心中各 Server 下的强一致性,这样能保证同一个数据中心,不论哪一台 Server 宕机,请求从其他 Server 中同样也能获取最新的服务列表数据。数据强一致性带来的副作用是当数据在同步或 Server 在选举 Leader 过程中,会出现集群不可用(在接下来遇到问题中会分享我们遇到的问题)。
在双云双活一期中,双云共用原有生产 Consul 集群,J 云的服务节点处于单独拉取的链路而非 base 基础链路,确保部署在 J 云的核心服务间调用在 J 云内部闭环。
配置中心:双云共用原有生产配置中心 Config,通过 Config 获取服务相关参数、缓存和数据库的连接地址。
服务部署:J 云只部署了核心服务,并注册到原有 Consul 集群,而配置中心、缓存、队列、数据库等均跨云访问 U 云侧原有集群。
流量分发:达达的负载均衡 LB 是基于 OpenResty+Consul 建设的,并结合自身业务特点自研了一套流量控制逻辑,具备生产流量、灰度流量、压测流量的转发控制。在双活一期针对 J 云类似灰度链路的流量控制,根据 J 云机器的 tag 标签,可以做到指定域名根据 CityId 实现可调百分比的外网流量经由跨云专线打到 J 云的服务节点之上。
监控告警、日志系统、应用性能、发布系统等均共用原有 U 云生产环境。
双云双活一期遇到的问题
在双云双活一期架构中,J 云侧核心服务的订运单主流程功能验证通过,但也遇到棘手问题。
1.接口响应时间过长
由于只有部分核心服务部署在 J 云,其依赖的 Redis、DB、队列和其他服务等仍需要跨云读写访问,跨云专线的 3-4ms 时延在多次跨机房请求下将延迟问题彻底放大,例如 U 云侧一个发单接口响应时间约在 200ms,而在 J 云侧需要 500ms+,这个响应时间对业务而言是无法接受的。
2.跨云共用同一 Consul 集群有偶发风险
跨云专线的网络波动和 3-4ms 时延,这会造成跨云使用 LAN Gossip 协议通信的同一个 Consul 集群发生紊乱情况。我们曾遇到过 J 云侧 Consul 节点将 U 云侧正常节点投票下线 继而影响 U 云生产集群的问题,也遇到过这种紊乱情况下,J 云的节点会疯狂地消息广播投票确认并导致专线带宽急剧上升。基础架构团队针对这些问题专门优化了 Consul Gossip 协议以降低对网络延迟的敏感度。
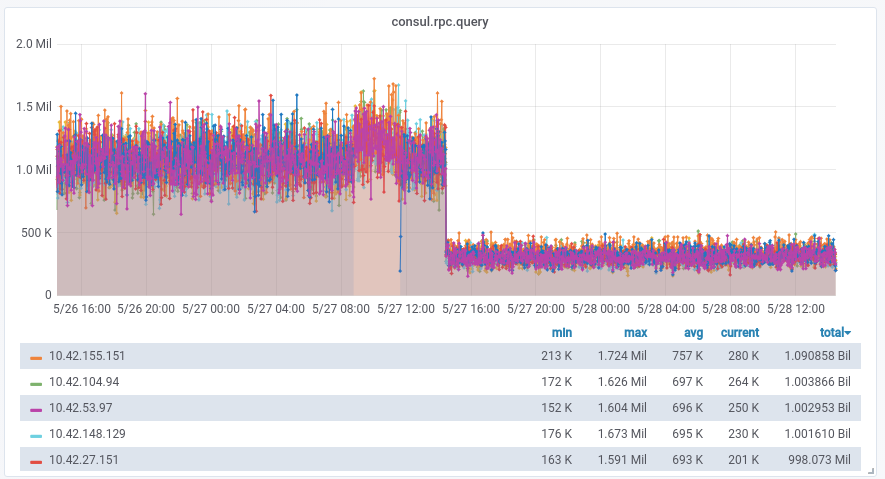
3.灰度用户前后请求体验有明显差异
双云双活一期的流量分发方案可指定到域名+按百分比分发流量+默认负载均衡轮训后端,这样虽然可以灰度验证业务功能,但开启双活流量城市的骑士前后两次请求如果流向不同云,接口响应时延差别较大,相应体验上会有较大差异。
双云双活一期总结
实际结果证明,按以上所描述的一期方案来实施的双云双活,没有办法达到预期结果,特别是比较大地影响了用户体验,更无法支持诸如抢单这类实时性较高的场景。达达的双活一期最终也以失败告终。
双云双活二期
针对同城双活一期遇到的跨机房调用时延问题、跨云网络波动可能引发 Consul 集群紊乱,以及业务流量精准分发一致性体验等问题,我们进行了深度思考,形成了服务间交互单云内内敛、数据库双云双向复制、流量总控精细化配置三大核心点,并且结合业务场景依据数据访问频次、时延要求和数据一致性要求等维度,我们对数据和关联服务进行了梳理和 RCG 模型分级。
此外,我们还在双云统一配置中心、服务一致性部署和发布、系统可观测性、工具系统主备、容量规划和成本控制方面做了相应功能迭代和能力建设。
双云双活二期架构图
双云双活二期的架构图如下所示
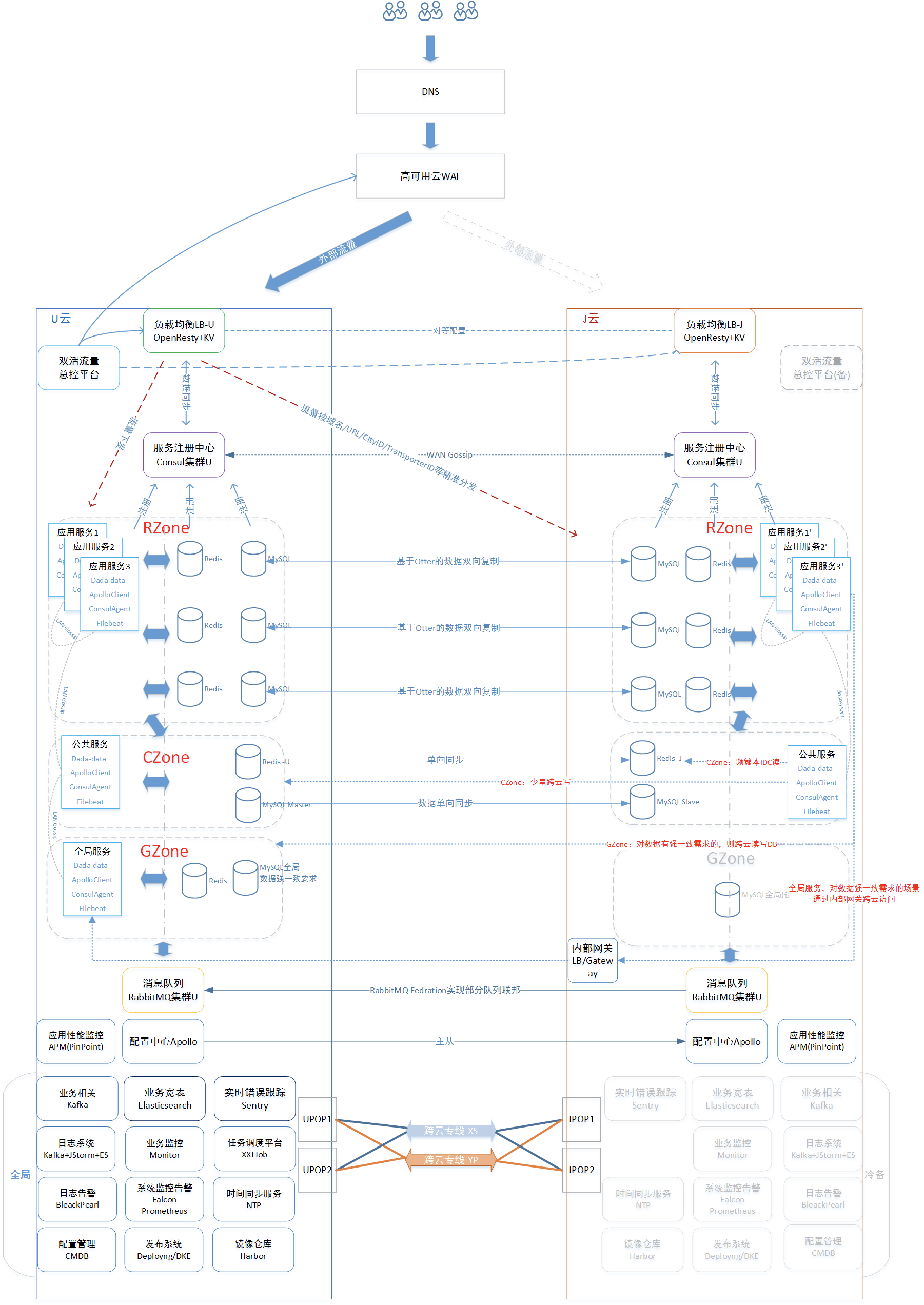
双云双活二期方案的三大核心点

1.Consul 多 DC 方案
双活一期遇到的跨机房调用时延问题及跨云网络波动可能引发 Consul 集群紊乱,这让我们更清楚地认识到服务间请求单云内内敛的重要性,对 Consul LAN Gossip 与 WAN Gossip 协议适用不同场景的理解。
因此,双活二期,我们采用了 Consul 多数据中心方案,官方示意图如下:
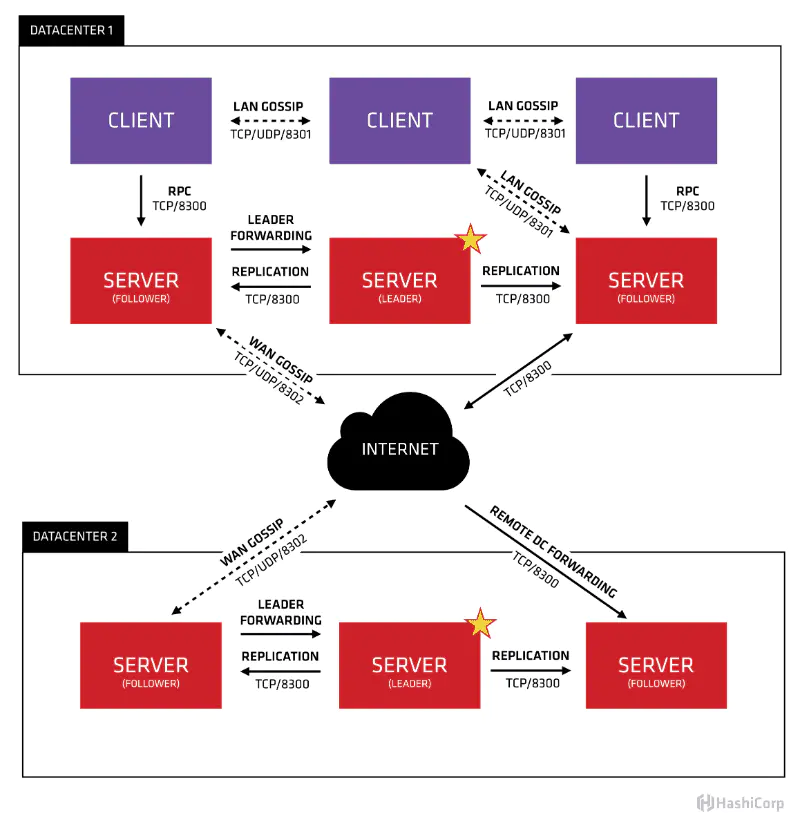
每个云有各自的 Consul Server 集群,consul client 默认以 LAN Gossip 协议 join 到所在云的 Consul Server,不同云之间 Consul Server 通过 WAN Gossip 协议 join 到一起。在达达内部,每个服务会默认携带一个 Sidecar 并 join 到所在云的 Consul 集群, Mysql 和 Redis 也同样以 consul client 方式 join 到所在云的 Consul 集群,这样通过 Consul 多 DC 架构和 Consul 服务发现,我们实现了服务间交互、服务与绝大多数数据源间交互在单云内内敛,也尽可能规避了一期遇到的问题。
2.数据库双云双向复制
为实现 RZone 模型的 DB 本地读写,且在数据库水平项目没有大规模开展的情况下,我们调整了双云两侧数据库的自增步长为 2,即 auto_increment_increment=2,主键也做奇偶数区分,即 U 云侧主键是奇数,J 云侧主键是偶数。
为实现双 A 数据库双云双向稳定同步,我们采用了阿里开源的分布式数据库同步系统 Otter,其架构图如下:
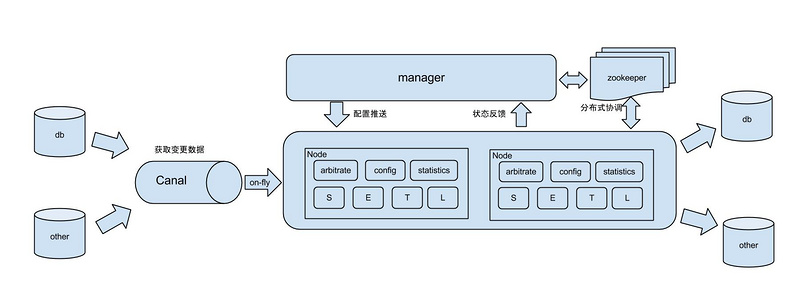
生产环境中,我们通过 Otter 不同的 Channel 管理不同双 A 数据库的双向同步
如下是生产环境 Otter 同步列表的 TOPN
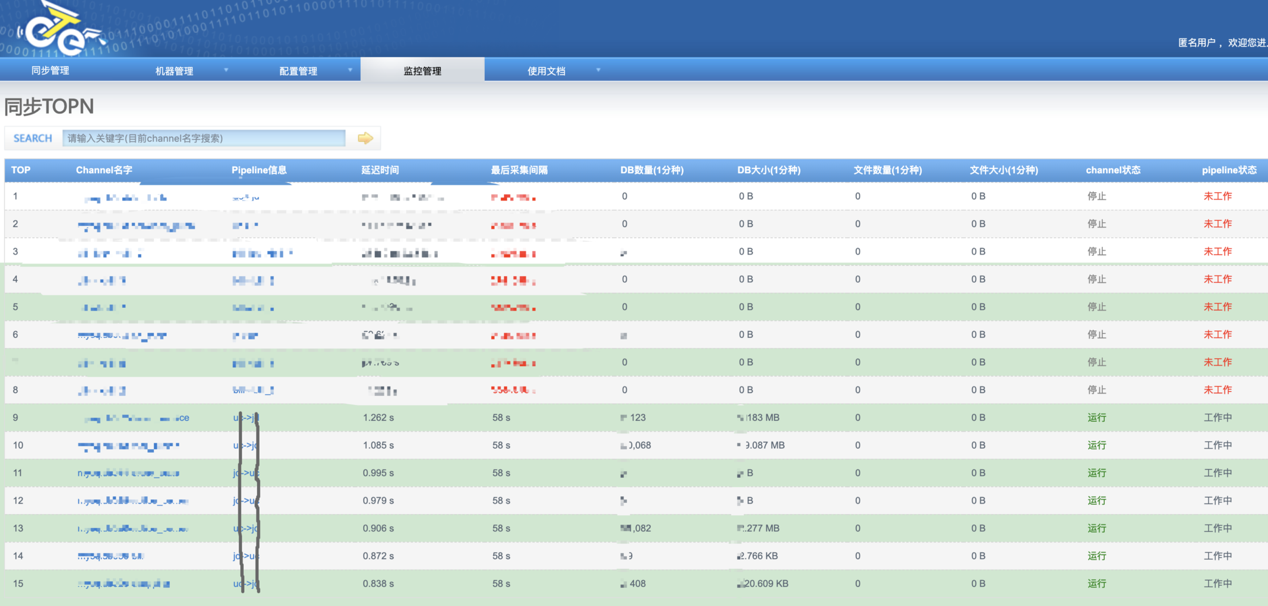
目前,数据库双向复制时延平均 0.9s,最大时延为 2.2s(瞬间)
3.流量精准分发
我们利用 OpenResty 根据请求头/体中/CityId/TransporterID/ShopID 及域名+URI 以精准分流。
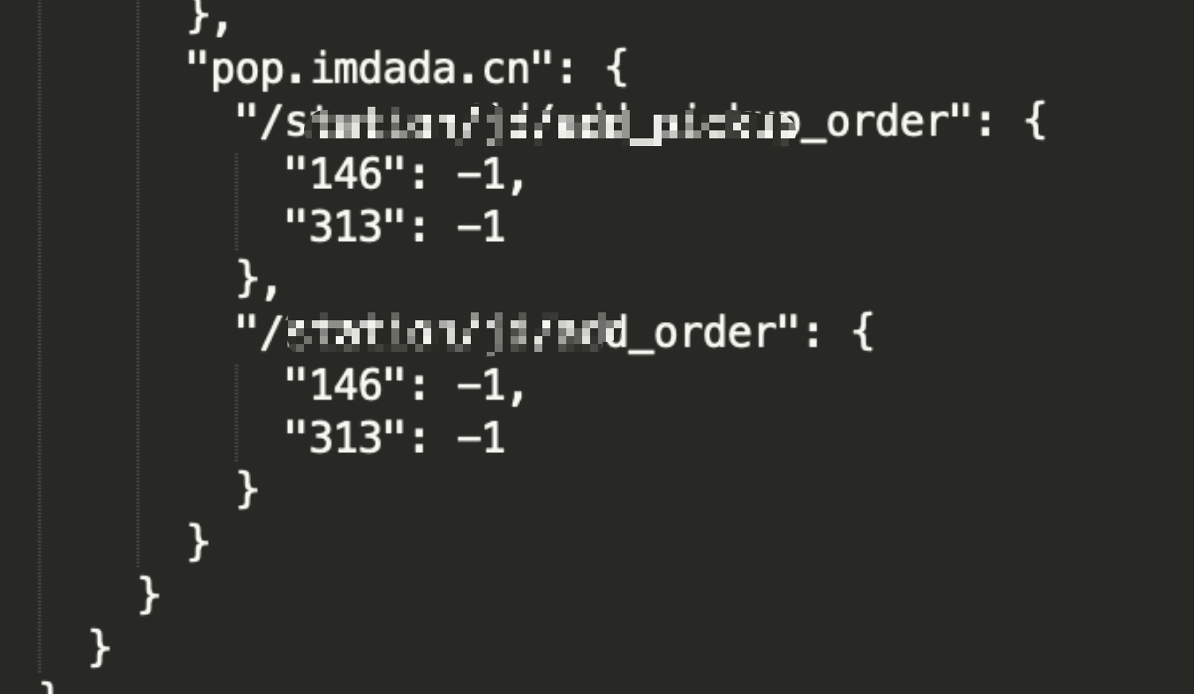
如下图,相比一期我们可以做到,针对 pop.imdada.cn 的某两个具体的和订单相关的 URI,对城市 ID 313 和 146 流量分发到 J 云,其余城市或 pop 其他接口默认分发到 U 云(默认主 IDC)。
同时,我们也做到骑士 ID 对齐城市 ID,即如果某个骑士属于这个城市,而且这个城市针对该骑士对应的业务也开启了双活流量,那么该骑士的每次请求都会走到 J 云。
双云双活二期方案之 RCG 模型分级
参考业务双活解决方案,并结合业务场景依据数据访问频次、时延要求和数据一致性要求等纬度,我们对数据和关联服务进行了梳理和 RCG 模型分级,如下

双云双活二期之工具/系统适配双活
主要有以下几个方面的工具系统改造支持并适配双活
配置中心:配置中心从 Config 迁移至 Apollo,涉及达达数百个服务,生产环境的 Namespace 下,通过不同集群 Cluster 区分 U 云和 J 云的个性化配置, 并通过服务本地配置文件 server.porperties 对齐 apollo 的 cluster 名字和 consul 的 datacenter 名字以取得正确的配置信息。同时,Apollo 本身依赖的几个 DB 也在双云间做了数据库主从同步,以备灾难时切换。
发布系统:得益于配置中心和中间件包版本的统一,我们实现了服务一次打包双云一致发布,这里包含发布系统对双云两侧同一服务版本的一致、发布/回滚/重启等变更批次的一致、变更逻辑步骤及消息通知的一致性。
业务监控:业务监控系统为了更好的支持双云服务监控,对齐 Consul 集群 datacenter 名,业务只需选择对应 dc 的 tag 即可切换到具体某个云上查看服务的监控情况。
应用性能监控:为了更好的监控服务间在单云内敛的交互情况,我们在双云各自部署了一套 Pinpoint 系统。
NTP 时间同步服务:双云间时间步调不统一会直接影响业务问题的排除,而且在流量切回瞬间同一个未完成状态的订单可能会发生意想不到的情况。我们在双云间建立了 NTP 服务主备,双云所有服务器默认与 U 云的 NTP Server 每分钟同步时间。
镜像仓库:目前 Harbor 在双云各部署一套,默认是从 U 云增量同步到 J 云,灾难时会切换 J 云的 Harbor 为主镜像仓库。
双云双活二期之容量弹性和成本控制
通常建立双活会使云资源成本接近等量的增加,我们也面临同样的困难,如何做好成本控制,我们的答案是从容器规划和弹性扩缩容方面下功夫。
数据库:几乎等量,但在调研从一主多+冷备集群往 MGR 方案迁移
无状态服务:引入原生容器,即时即用,在效率和成本上得到有效控制
在业务流量总量一定的情况下,流量在双云间调配,意味了双云无状态服务的负载也在随之变化。鉴于此,我们基于 K8s HPA 算法自研了 Auto Scaling 自动扩缩容系统支持双活架构下的容量弹性,通过实时收集业务系统的多种 metrics 指标,实现了双云依据各自业务负载实时调节所需资源。
这样,我们在保障业务系统双云稳定性的同时,又做到了成本有效节约。
双云双活二期方案与业界双活方案对比
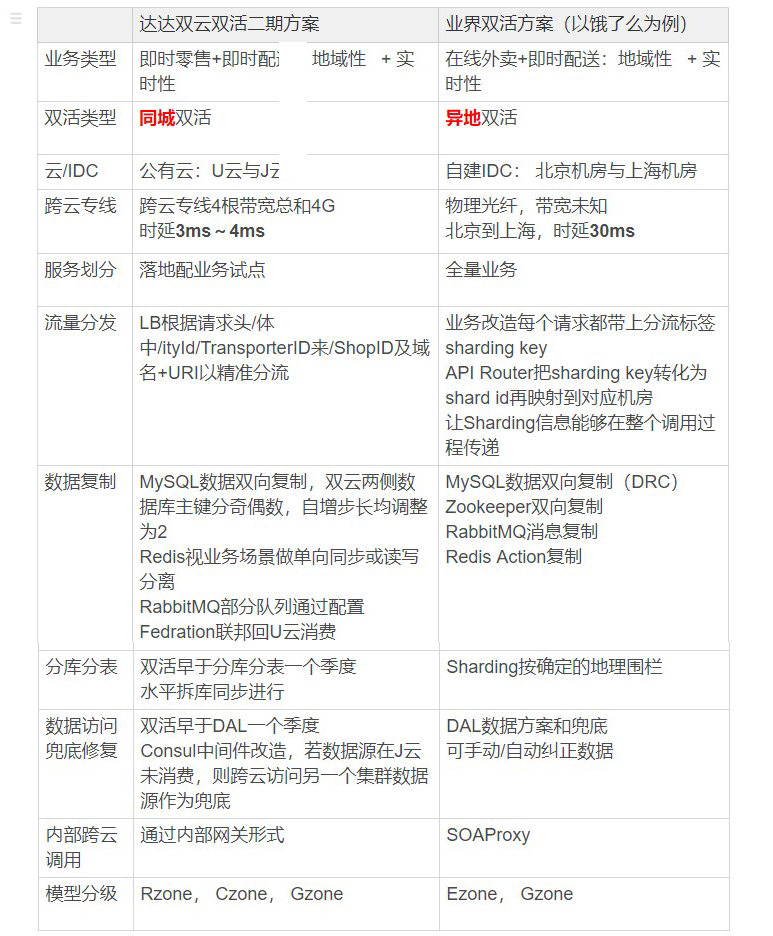
双云双活现状
目前落地配业务已稳定运行在双云之上,并且达达也具备了以城市为粒度任意在指定云间切换业务处理量的能力。不仅具有了抗 IDC 级别故障的能力,也达到了按业务和地域灵活灰度切换的预期。
未来规划
未来需要在业务入层增加更多的 Sharding Key(城市 ID/骑士 ID/商家 ID/订运单 ID 等),引入 API Router 以便于其他业务更好地在双活架构下流量分发到准确的云或机房;兜底 Job 改造为 Pulsar 延迟消息并在各个云内执行,以避免因数据库双向同步时延且 Job 单边运行造成业务上数据的错乱;业务监控特别是单量的监控水位,需要能及时对齐流量切换比例;账户服务目前是默认在 U 云的全局服务,拟采用 TiDB 方案以适配双活架构;最后,双活需要对齐数据库水平拆分,流量切换从 CityID 维度变化为 ShardingID 维度便于流量调配和管理。
总结
回顾双云双活两期,我们希望尽可能借助架构和运维的方式来解决同城双活中遇到的问题,尽量对业务透明,减少业务改造成本,同时以落地配业务作为同城双云双活架构的业务试点,以减少全局风险。同时,我们希望积累相关经验,为后续开展单元化和多云多活打好基础。双云双活的建设是一项复杂的系统工程,需要有点、线、面、体的维度思考和前瞻规划。在这里特别感谢云平台各团队、落地配研发团队、物流平台团队)、落地配运营团队对双活项目的大力支持。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论