

人工智能正在改变人们创造、获取、分享及消费信息的模式,然而高效高质有用的内容创作仍然困难重重,保证大众能公正的获取到准确信息也充满挑战。本文,InfoQ 经授权整理了字节跳动 AI Lab 总监李磊近期在火山引擎智能增长技术专场的演讲(火山引擎是字节跳动旗下的数字服务与智能科技及品牌),其分享了文本生成技术进展、挑战及火山引擎的实践经验。
随着新媒体平台的兴起,人工智能技术已经大大提高了信息内容的创作,而个性化推荐算法的信息又为信息内容的分发提供了极大的便利,这其中,文本生成技术非常重要,因为它在很多的应用场景有广泛的应用,比如机器翻译、机器写作、对话机器人以及自动问答。2019 年在《管理科学》杂志上 MIT 研究人员发表的一项最新研究表明,机器翻译技术已经将国际化贸易量提高了 10%,这相当于将地球上的各个国家之间的距离缩短了 25% [1]。
近年来,字节跳动也研发了多项先进的机器翻译技术,目前字节跳动自研的火山翻译平台已经有公司内外的 50 多个客户使用,支持超过 50 多种语言的互相翻译。此外,在字节跳动我们研发了 Xiaomingbot 自动写稿平台,自 2016 年上线以来,已经累计写了 60 万篇文章,覆盖了 17 项的体育赛事,支持 6 种语言,在自媒体平台上面也有 15 万的粉丝。
下面给大家展示一下 Xiaomingbot 如何自动写新闻。

我们的系统将从数据源获取到比赛信息,例如球员比赛布阵、球员的进球等等信息。同时我们还会利用计算机视觉的算法,对比赛视频进行分析识别出其中的球员、球衣上面的号码,球员的运动轨迹、球员的动作、球员的位置以及关键的一些场景等等。再利用这些信息我们利用文本生成算法写出最后的文章 [2]。
在另外一项研究当中我们使用计算机视觉的算法去分析斯诺克比赛的运动、桌上球的运动轨迹、以及利用机器学习最后去预测球员的击球策略,预测下一杆球会落到哪个袋,并且利用这些预测去生成最终的比赛解说 [3]。这对于一些非职业的观众来说,非常有助于帮助理解球赛的进程。这是我们算法最终生成的一些解说情况。

本场讲座,会分为五部分内容。第一部分,我会给大家先简单介绍一下什么是序列生成问题,它有什么样的难度和挑战;第二部分,将介绍深度隐变量模型,Deep latent Variable Models for Text Generation;第三部分,我将介绍文本生成当中如果加上限制之后,如何做更好的算法,我们提出了一类蒙特卡洛采样算法来做文本生成;第四部分会介绍机器翻译当中如何使一个模型可以去获取四项双语语言能力。最后一部分介绍多语言的机器翻译,我们最新的一个工作 mRASP。

序列生成问题的难度和挑战
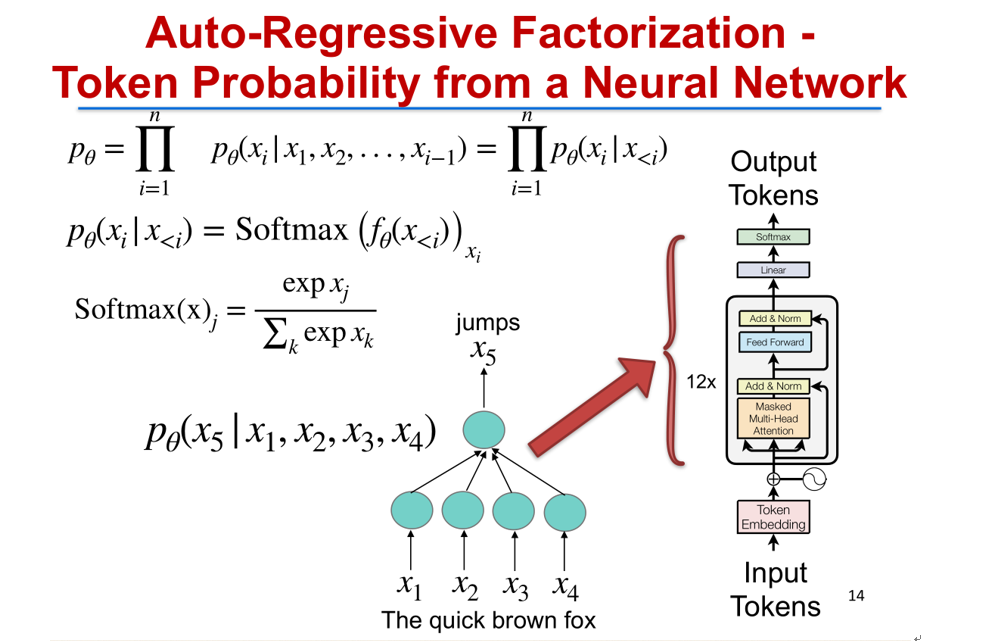
在自然语言中,所有自然语言声称的核心问题是对句子序列做建模,比如说这样一个句子的 The quick brown fox jumps over the lazy dog 句号,这里有 10 个字符,Modeling 的问题就是对这 10 个字符的联合概率去建模,也就任意一个句子长度为 L 的句子,我需要对整个 L 各字符对它算出它的联合概率分布。当然最基本的一种方法是叫 Auto-Regressive Language model,是把这个联合概率分解成下面这个形式,每一个部分它实际上是第 i 个字符的概率,是建立在前面 1 到 i-1 个字符的基础之上,这具体的每一个概率可以有很多建模的方法。比如说现在从 2017 年开始比较流行的叫 Transformer 网络里面对个条件概率的建模是使用多层的多头注意力机制(Muti-Head Attention)来建模的 [4]。当然这个 Transformer 有很多的参数,实际学习当中就需要找到最好的一组参数,使得语料里面的联合概率最大。

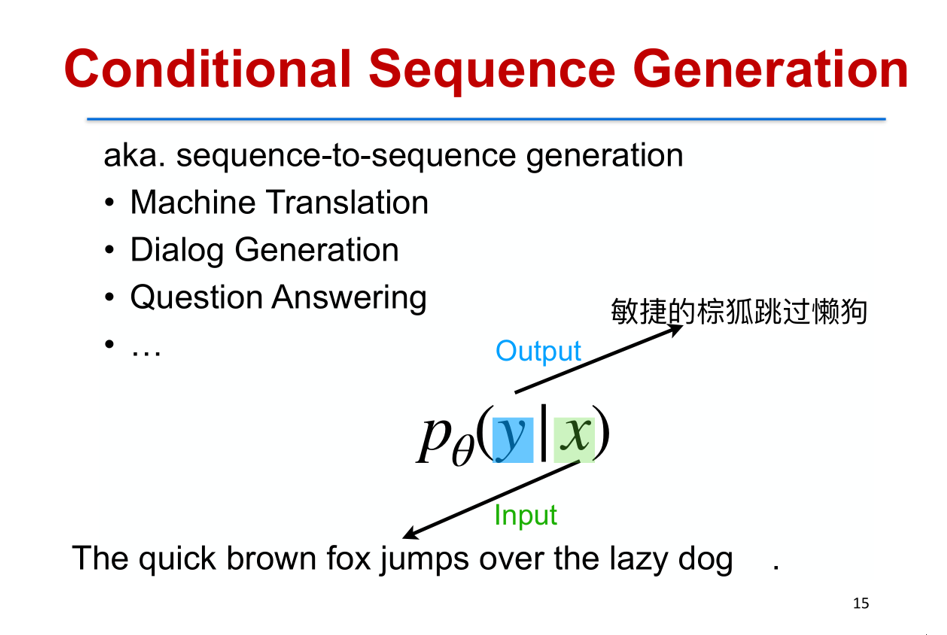
在另外一些问题当中,例如机器翻译、对话生成以及自动问答当中,我们通常会有一个输入,输入也是一个序列,我们要针对这个输入做一个输出,例如机器翻译,给定一个输入的英文句子(X),我们要输出一个目标语言中文的句子(Y),所以我们要对 Y|X 这样一个条件概率去建模,同样可以用之前提到的 Transformer 模型来对这个概率建模。

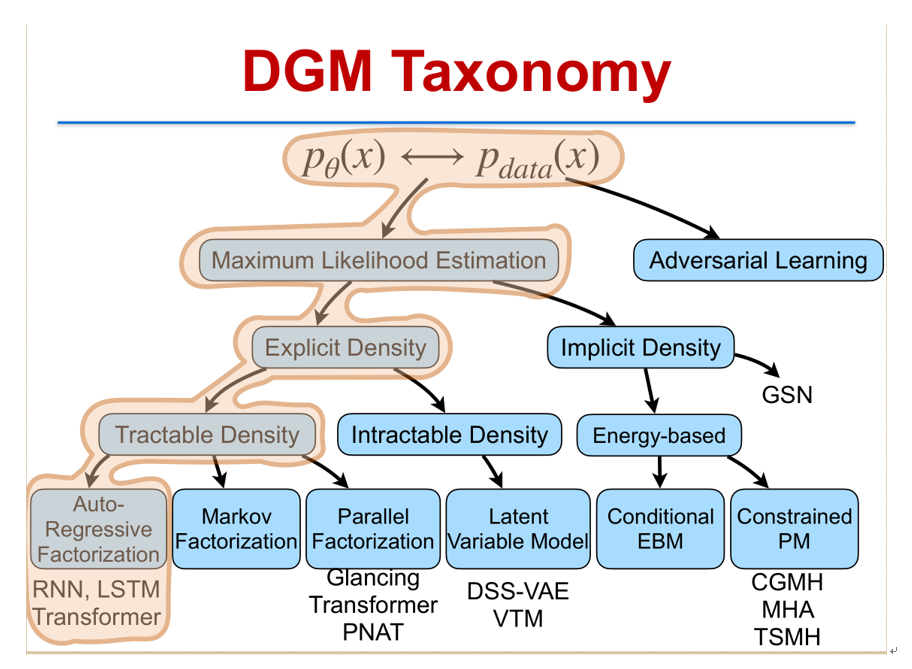
把深度生成模型按照方法类别去归一个类,大致可以分成这样几类:按照自然估计的方法可以分成概率密度有没有显式密度(explicit density),以及隐式密度(implicit density)。显式密度当中又分是否密度是可直接计算的,例如像自回归分解(Auto-Regressive Factorization)里面的 Transformer 模型 [4]。如果不是自回归分解,还有像马尔科夫分解(Markov Factorization)以及并行分解(Parallel Factorization)。像最新做的一些工作就 GLAT 等等这样一些工作就可以做并行分解。在显式密度中另外一块是不可高效计算的密度(Intractable Density),也是今天需要重点介绍的一类模型,叫隐变量模型(Latent Variable Model),典型的代表有 DSSVAE、VTM 等,本场讲座也将会介绍。
假如说这个密度没有显式公式的,是隐式的,也就是说你无法严格地写出它的概率分布,通常可以写出它的能量函数(Energy Function),可以是条件能量模型(Conditional Energy Based model)或者是受限概率模型(Constrained Probability Model)。这次,我们会特别介绍受限概率模型如何来快速生成句子。包含 CGMH、MHA、TSMH 等一系列算法。但有一部分内容这里不会介绍,就是对抗学习(Adversarial learning),它已经超出极大自然概率估计这个范围以外。
接下来的一部分我将会介绍文本生成的深度隐变量模型(Deep Latent Variable Models for Text Generation)。我具体会介绍两类工作,一类是我们如何从文本当中学到可解释的深度隐含表示。第二类是我们如何从文本当中学到解耦的一个表示,并且利用这个解耦的表示来做更好的文本生成。
文本生成的深度隐变量模型

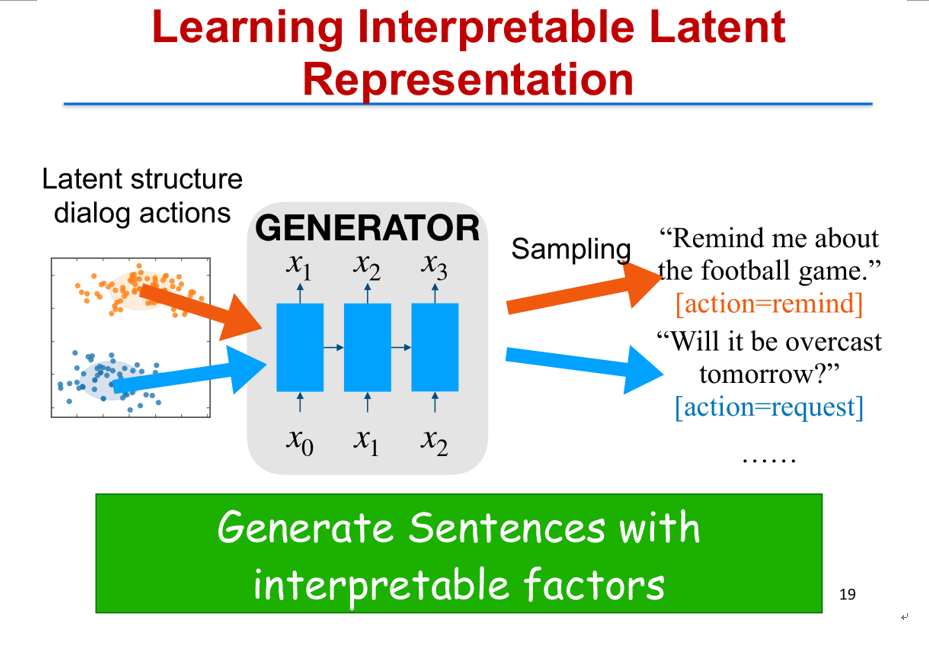
我们先看第一部分,我们要去学可解释的隐层表示,那么,什么是可解释?我们看这样一个具体的问题:我们从对话的句子当中希望去学到对话的一个隐表示,并且这个隐表示对应一定的语义关系,例如这里两个对话,”Remind me about the football game”,”Will it be overcast tomorrow”。这两个对话句子对应两个不同的意图,第一个意图是希望去给它一个提醒(Remind),第二个意图是问路(request for the information about where),这两个意图我们希望从句子本身通过学这样一个生成模型去学到,你在使用当中就可以根据对应的不同的意图去生成不同的回答。
传统的做法是用变分自编码(Variational Auto-encoder)的方法,去学一个隐表示,这个方法具体是假设有一个隐变量(Latent Variable) Z,它自己有一个高斯分布。从这个 Z 里面可以生成出文本句子 X 出来,利用这样的方法,Kingma & Welling 在 2013 年提出了 VAE 的算法,通过变分推断去学到隐层表示。这个方法当然可以去生成句子,也可以学到隐表示。但是当你把这个隐表示投影到低维空间去可视化出来的时候,你会发现不同的句子全部都混合到一起了,这整个混合在一起的一个大组并没有明显的聚类,所以很难去解释这个隐层表示。
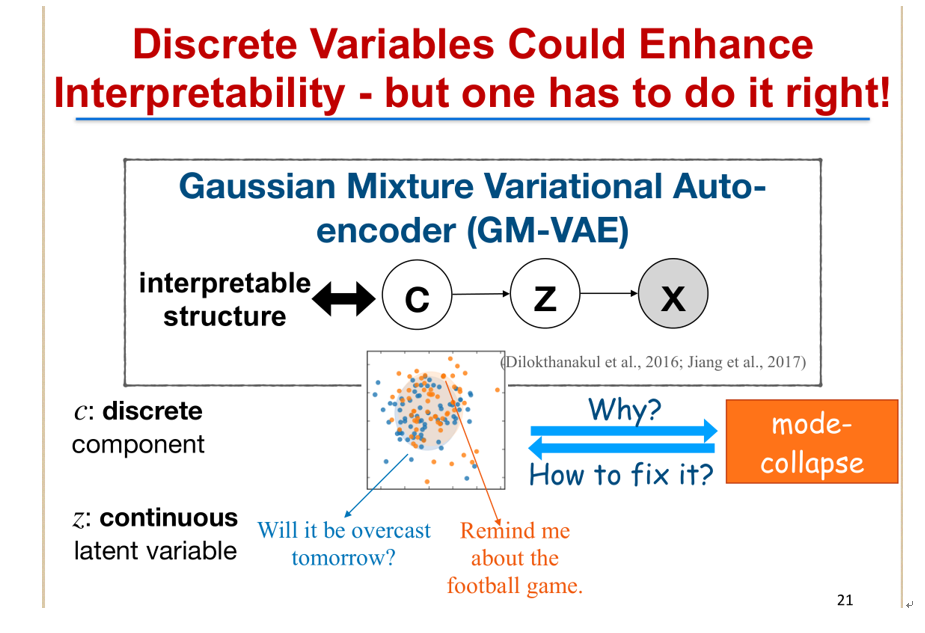
如何从这里的隐变量 Z 得到一个可解释的隐层表示?一个比较好的自然的方法是在隐变量 Z 上面再加一个先验变量 c,而这个先验和 Z 不同的在于 Z 是连续的,Z 的先验 C 是离散的。也就是说,Z 是一个高斯混合分布(Gaussian Mixture distribution),我们希望从原始文本里去学到比较有意义的 C 和 Z,这样不同语义、不同意图的句子可以落到不同的聚类里面,也就是对应不同 C 的值。
这里有一个很重要的动机是,在隐变量模型里面引入离散的变量,会显著提高模型的可解释性。这个愿望当然非常美好,可是大家在实际学习过程中会发现,往往学到的 Z 去投影到低聚维空间的时候,会发生一个 mode-collapse 问题,也就是实际上学到的这些不同的意图的句子,它在隐空间的表示是混合在一起的,无法看到一个很明显的区分。如何从混合在一起的区分里面,去理解为什么会产生这种现象?并且试图去修正它,使它得到我们希望的可解释的一个隐层表示?
我们最近在 ICML2020 上面的发表的 DEMVAE 的工作 [5],实际上解决了这个问题。
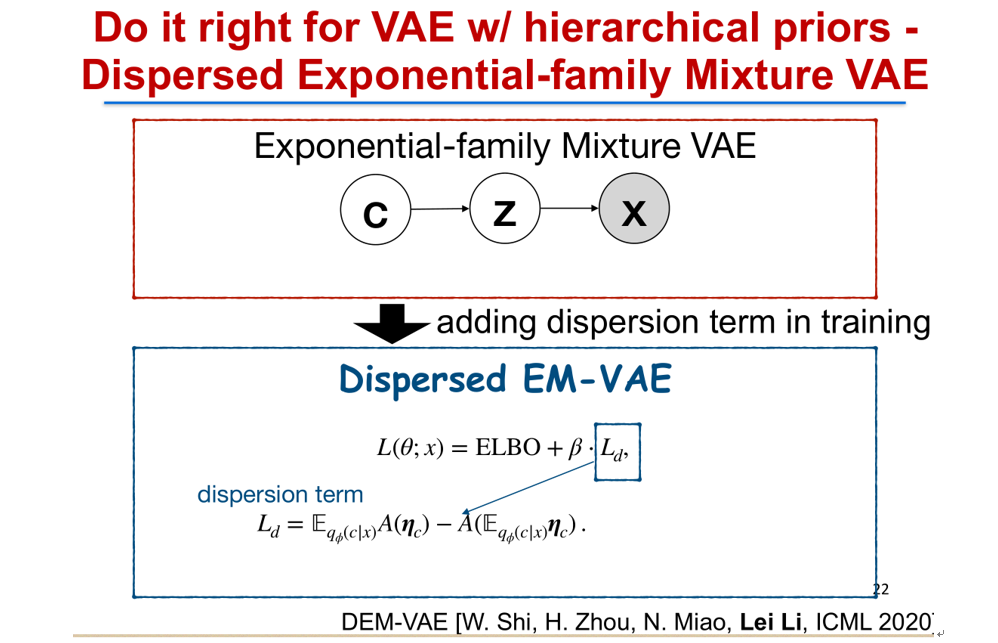
首先我们把要处理的模型推广到一个非常广泛的一族模型叫指数族混合变分自编码器(Exponential-family Mixture VAE)中。我们假设句子 X 是由一个隐变量 z 生成出来的。z 是指数族密度的一个混合分布。这里的 C 是离散的,代表不同混合概率。而 Z 是对应的不同组分,每个组分是一个指数族概率分布。我们前面提到的高斯混合自编码器(Gaussian Mixture VAE)是属于这一族分布里面的一个具体例子。

同样,这个模型我们要去直接估计的话,也仍然会遇到峰值塌缩(mode collapse)的问题。我们做的一个解决方案,是我们仔细分析了损失函数(Loss Function),我们发现只要在这个损失函数里面,也就是变分下界(Variational ELBO)里面加上一个额外的惩罚项叫离散项(dispersion term),加了这个之后,我们最终就可以让不同的峰值不会发生塌缩,从而会学到更有意义的隐层空间表示。

这是我们使用 DEMVAE 方法去学习到的一个效果。我们从对话句子里面去学到它的一个隐层表示 C 和 Z,注意 C 是离散的。我们用后验分布去分析这个 C 并且对它做一个简单的分类,发现这个 C 和真实的意图会非常非常接近,例如左边的这些句子,我们分析出来它们都属于同一个 C,实际上可以对应对话动作是问路(Request address),第二类都是对应问天气(Request-weather)这样一个意图。有了这个之后,我们就可以去生成更好的对话回复,例如,这样一个输入句子,“Taking you to Chevron“,我们可以预测假如说我们需要去做感谢这个意图的话,我们可以生成这样一个回复句子,“Thank you car ,let us go there“,假如说我们要去 Request address 的话,我们又可以生成另外一个句子,What is the address,所以根据不同的例子出来的意图,我们可以做可控的生成,这也是可解释性带来的一个好处。
介绍了可解释性,我们再介绍另外一个相关的问题,叫数据到文本的生成(Data-to-Text Generation),这个问题我们给定一个数据表格它是一个键值(Key- vaule)的表格的形式,比如这里显示了一个餐馆的一些的属性,希望去生成这个餐馆的描述。例如这右边是它一个可行的描述。这个问题可以把它建模成数据到文本的生成,Data-to-Text Generation。传统的做法是人工写出非常多的模板,这个模板里面留了很多空位,这些空位和数据结合之后,我们就可以去生成比较好的文本了。当然实际应用当中,我们不希望生成是一成不变的,我们希望同一个内容可以生成各式各样的文本。这就需要我们人工去写非常多的模板,而人工写这些模板是比较枯燥的。

我们希望提出一个新的方法,它能够自动地从语料里面学到这些模板,并且根据这些模板去做很好的生成。如何做呢?我们有两个动机:一是我们从概念上可以把隐空间的表示区分成两个随机变量,一个变量是用来刻画的数据内容(Content),另一个随机变量是用来刻画模板(Template),这样两个合起来之后,我们就能够从数据里面去生成句子。并且我们希望这个模板的隐层表示不是显示的离散的表示,而是连续的一个空间,这也就意味着你可以有几乎无限的模板。
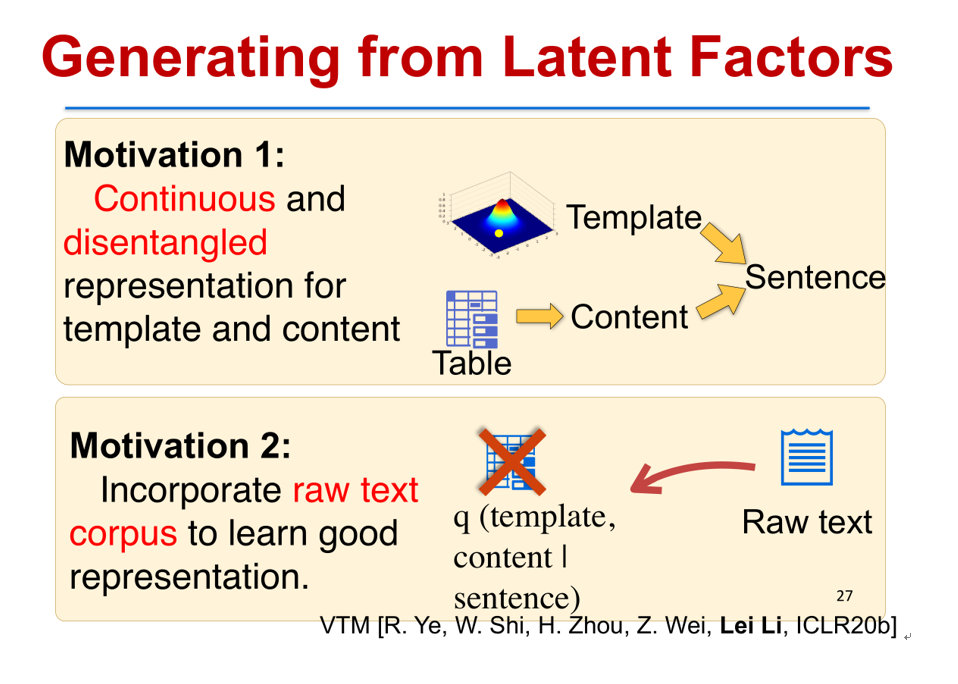
第二个动机是我们不仅仅需要利用成对的表格和文本句子,这样一个成对数据来训练,我们实际上这种成对的数据是非常少的。在实际应用中,我们还是希望去利用原始文本(Raw text)来训练,并且从原始文本当中学到模板(Template)和内容(Content)的表示。
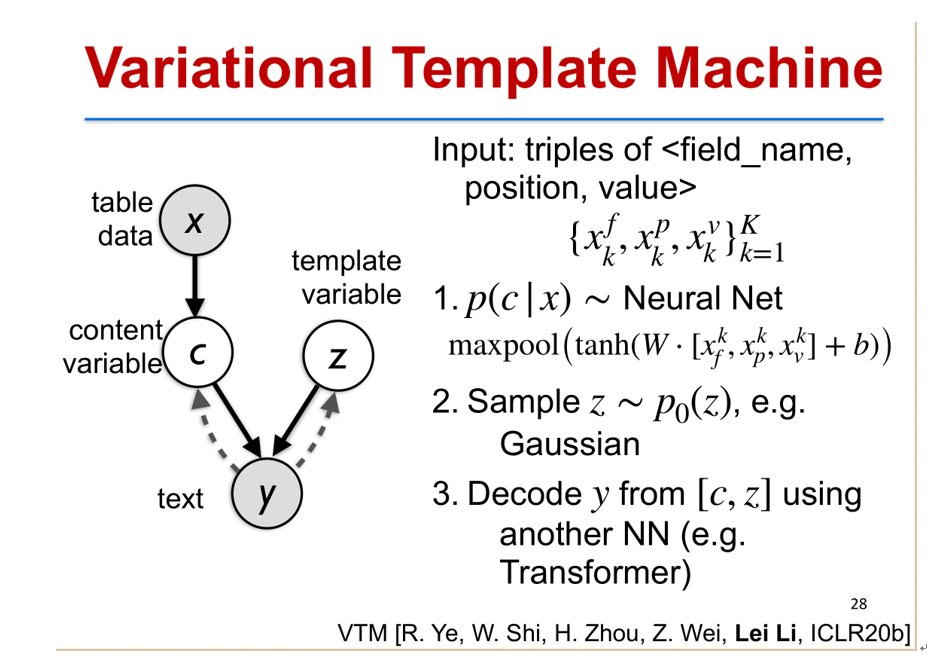
我们提出了一个新的模型叫变分模板机(Variational Template Machine),这个模型里面主要框架和前面介绍的变分自编码器(Variational Auto-encoder),本质上是非常类似的,但是与之不同的是我们有两个隐变量,一个是内容隐变量 C,它是从数据里面来得到的。另外一个是模板隐变量 Z,是有自己的先验分布。
生成的过程是怎么样的呢?一个输入数据 X,表示成 field,position 和 value 的一个三元组集合。我们先从输入的数据 X 里面去计算内容变量 C,这个可以通过一个神经网络来实现。第二步我们从 Z 的先验(例如高斯分布)里面去采样一个 Z,得到 Z 的值,这是相当于从一个无限大的模板库里面去采样选择一个模板。第三个是把 C 和 Z 合并之后,利用另外一个神经网络,例如 Transformer 可以去做生成。
利用这个变分模板机(Variational Template Machine)它最大的好处是不仅能够利用成对的表格数据和句子来训练,还可以利用额外的原始文本,这个并没有对应的表格数据也可以用来训练,并且提升这个模型的性能。这就相当于做了一个反向翻译,根据原始文本找到了对应的 C 和 Z,即模板和内容的后验分布,等同于制造了更多的一些伪平行语料,而这些伪平行语料可以用来提升学习的效果 [6]。

我们在 WIKI Data 和 SPNLG 的 Data 上面去做了实验,前者根据数据去生成个人简介,后者是根据餐馆的一些属性去生成餐馆的描述。
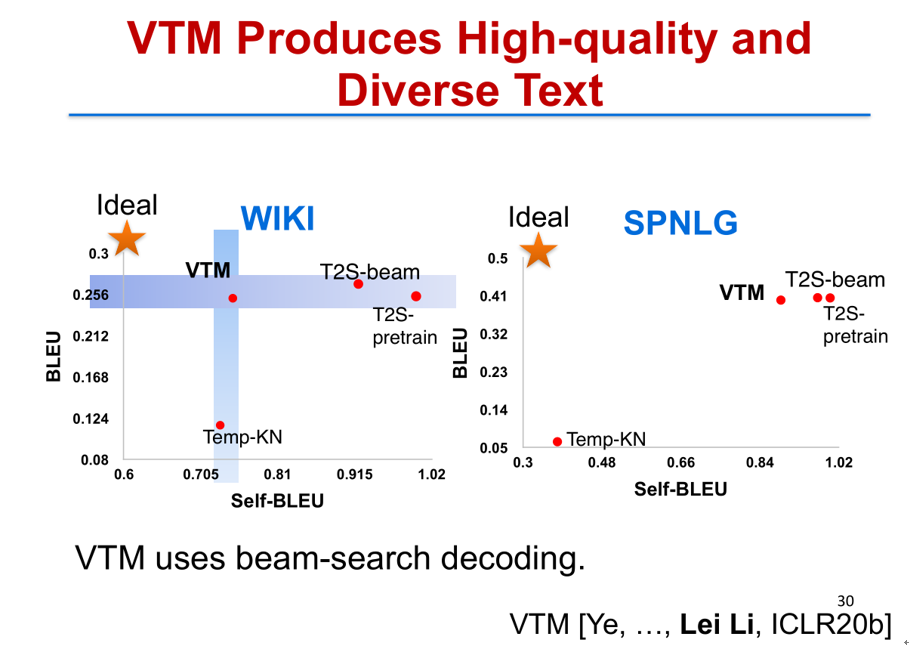
这里两幅图比较了我们变分模板机 VTM 方法和其他一些生成方法的性能优劣。纵轴是 BLEU SCORE,是用来衡量的生成结果和真实结果之间的相关性,所以越高越好。横轴是 self-BLEU,是用来衡量同一个方法生成的不同句子之间的相关性,我们希望同一个方法生成的句子,相互之间相关性越小越好。所以理想情况是:左上角的位置,质量最高,BLUE SCORE 最高,而 Self-BLEU 相关性越好,Self-BLEU 要越低越好。我们提出的这个变分模板机方法,它在质量上面和 Self-BLEU 两方面都取得了最好的分数。
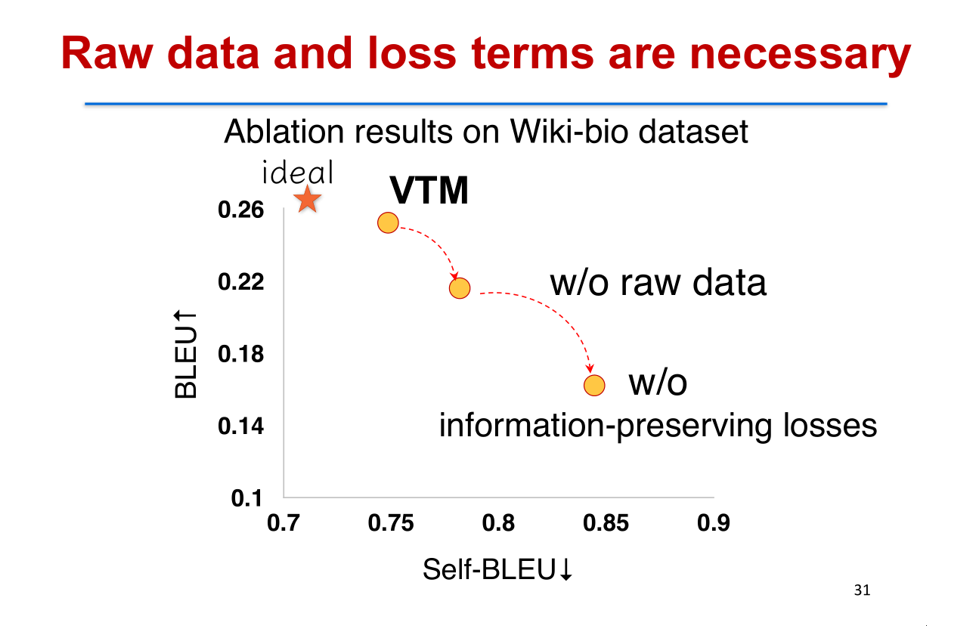
我们也比较了变分模板机的优势,如果完整的变分模板机它并不使用原始文本的话,只用成对数据对它来训练,它的性能就会下降,它的 Self-BLEU 质量会下降,同时它的多样性会降低。所以额外的原始数据还是非常重要的,我们也验证了在这个过程当中有一些重要的训练目标,也是起了非常关键的作用,去掉它也会使性能下降。
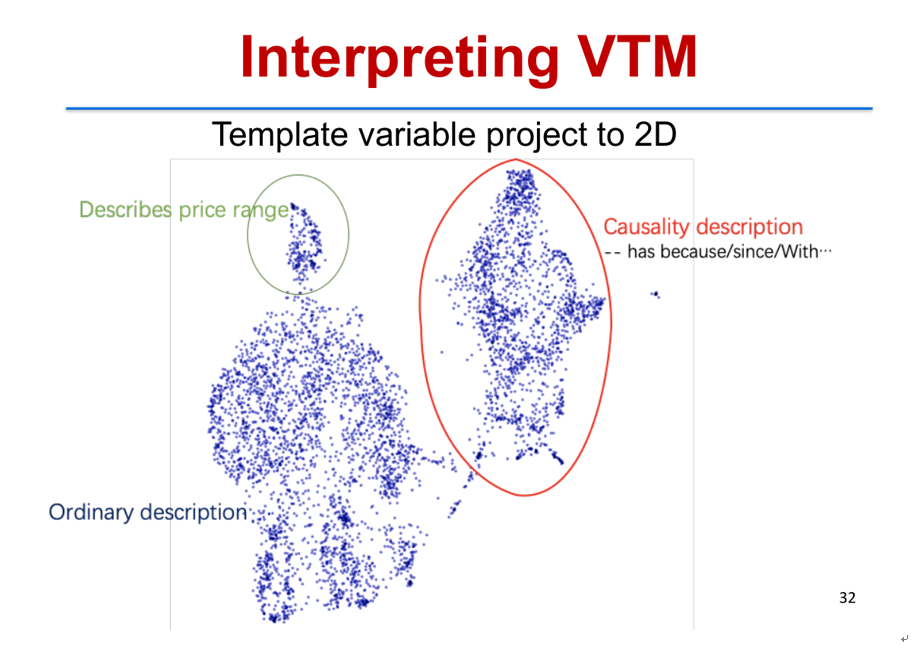
使用这个变分模板机 VTM 模型,我们得到的额外的一个好处是我们能够去分析原始数据里面它对应的隐变量,以及通过这个隐变量找到数据的一些合理的结构。例如,我们把模板变量 z 映射到二维空间去之后,我们会发现每一个句子实际上有一些独立的聚类,比如说右边这个聚类它对应于因果描述,里面的句子基本上都有一些 because、since、with 等等这样一些表达因果的模式在里面,这个是完全从数据里面学到的。
如果大家关心的话,这里有生成的一些例子,这是从用户画像去生成用户简历的一个例子,通过在模板变量里面做不同的采样,我们可以得到不同的模板值,把它与表格里面学到的内容变量合并之后我们可去生成不同的句子,不同的句子长度和写作风格都有很大的差别,这样就得到了比较多样,并且质量比较高的一些句子。

利用类似的解耦表示学习(Disentangled Representation Learning)的方法,我们也可以去学到句子的语法表示以及语义表示。

这个语法表示和语义表示有什么作用?我们可以做一个非常有趣的实验,叫『句子嫁接』。例如有两个句子,“There is an apple on the table”,“The dog is behind the door”。我们可以从从第一个句子里面学到它的语法表示,从第二个句子里面学到它的语义表示,把前者语法表示和后者语义表示合并起来,通过 DSSVAE 模型 [7],生成另外一个句子,“There is a dog behind the door”。从形式上,它非常接近第一个句子,都是 there-be 句型;从语义上,它更接近第二个句子,这就是句子嫁接。有了句子嫁接之后,我们可以利用这个技术在质量非常高的文章上面去学一些模型。比如一些业余作者要写文章的时候,我们就可以用这些高质量文章上面学出的模型去帮助业余的作者改进他们的写作内容。这是第二部分,文本生成的深度隐变量模型(Deep Latent Variable Models for Text generation)。
第三部分我将介绍一下,如果文本生成过程当中有额外的条件限制,如何高效地去做生成。这个问题是我们在火山引擎的实践当中发现的。
受限文本生成的蒙特卡洛方法
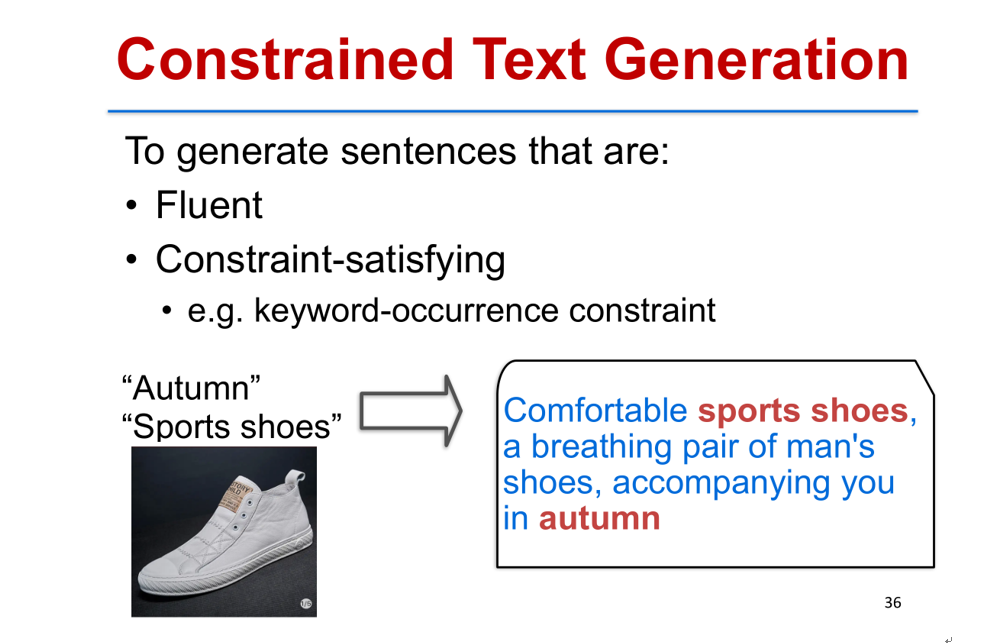
假如说我们要广告主设计一个广告,希望在广告文案当中出现一些给定的关键词,这个问题可以描述成受限文本的生成(Constrained Text Generation)。这里具体的限制是 keyword-occurrence constraint,即这些词必须要在句子当中出现。针对关键词限制(keyword occurrence),传统的算法是格束搜索(grid beam search) [8]。通过格束搜索,我们能够去生成一些句子,句子中必然会包含给定的关键词,但是这种方法并不能保证会生成质量比较高的句子。

我们提出了一个新的基于采样的文本生成框架。首先我们把目标问题和目标函数拆解成两部分,第一部分是预训练好的语言模型表征句子概率(pre-trained language model),这部分代表了句子本身的通顺程度,所以可以用以前训练好的语言模型来表示,对应图中橘黄色的部分。第二部分代表的是受限的文本,这可以用指示函数(indicator function)来表示图中蓝色的部分。而我们目标的句子,实际上是这两部分的交集,也就是图中红色的部分。
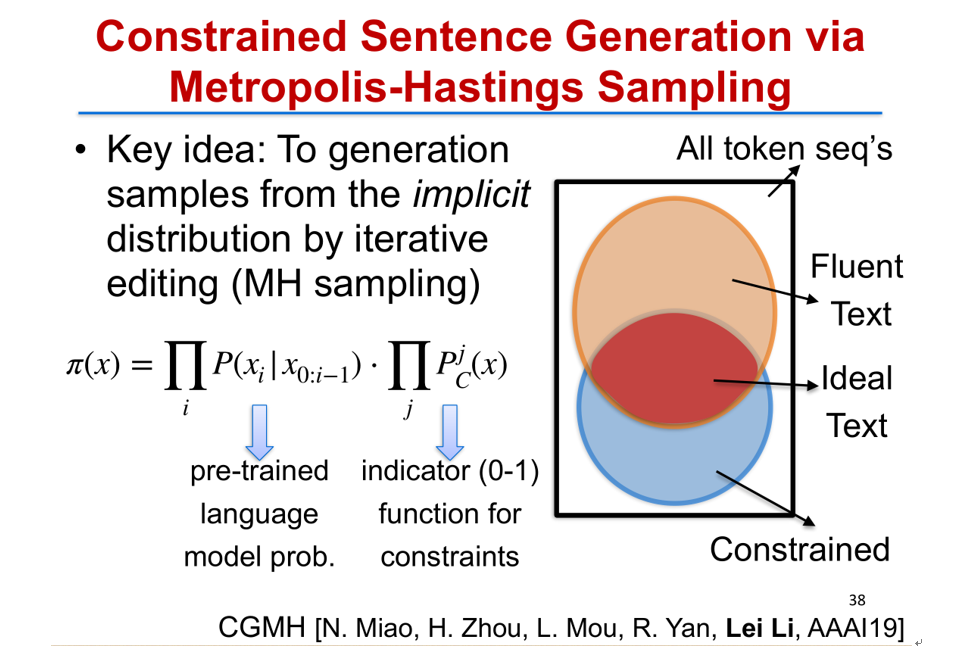
我们的目标是从红色的部分里面去生成既通顺又满足约束的高质量句子。所有的文本生成问题几乎都可以用这样一个框架来表示。而有了这样一个目标问题的表示之后,我们发现这个目标函数实际上不是一个合理的、有效的概率分布,因为它并没有归一化,要直接去找出其中的概率最高的样本点是比较困难的。
我们提出了一个新方法——CGMH [9]。
首先我们从原始语料当中可以预训练一个语言模型,例如现在比较流行的 GPT2 或者 GPT3 [10]。然后我们从一个初始的句子出发,不断地修改这个句子,每一步都可以插入、替换、或删掉一个词。对于得到的新句子,我们再用梅特罗波利斯-黑斯廷斯算法(Metropolis-Hastings)去计算是否接受这个改动还是保留原来的句子。通过这样不断迭代式的改动之后,我们最终就可以得到一些比较高质量的句子。这是整个 CGMH 的核心思想。


我们也在之前介绍的关键词约束的文本生成任务上做了实验,这张图是 CGMH、格束搜索(GBS,即 grid beam search)以及 LSTM 等算法的对比。上图是自动评估 NLL(Negative Log-likelihood)分数,越低越好;下图是人工评价的指标,越高越好。在上下两个图当中,CGMH 方法(红色柱子)都得到了最好分数。

我们已经将 CGMH 部署到大规模线上广告创作平台,去为我们的广告主服务。它已经被超过 10 万个广告主以及组织采纳,每天生成非常多广告,广告文案的采纳率约达 75%以上,也就是说 CGMH 生成的广告质量实际上是非常高的。
利用类似的思想,我们还可以去做对抗文本的生成。在机器学习里面,很多机器学习分类模型都是非常脆弱的,非常容易受到一些噪声(Noises)或者攻击(Attacks)的影响。如果要去分析它会受到哪些影响,我们就要去生成对抗样本,而在文本里面,如果要生成比较像人说的话且具有对抗性质的文本,实际上是非常难的。而我们用 CGMH 同样的思想去建模之后,就可以快速找到比较高质量并且真正具有对抗性质的样本。例如,我们有一个情感分类器,要对影评文本做情感分类。原来对于句子「I really like this movie」,可以正确地进行情感分类,是 99%的正向(Positive),通过 MHA 算法,在不改动语义的情况下,我们的算法只小小改动了几个词,把它改成「we truely like the show」,这个时候就会让情感分类器混淆了,它甚至会认为这个句子是 59%的负向(Negative) [10]。

更复杂的限制(Constraints)是我们有一些逻辑的或者组合的限制,在这个情况下,要去做生成实际上就非常难了。比如我要把一个陈述句改成一个疑问句,同时关键信息要保留,不能缺失,就需要加上比较多的组合的限制以及逻辑语义上的限制。逻辑语义上的限制加了之后如何去做生成,这是比较难的一个问题。

同样,我们把它建模成采样的形式,把目标函数分成两部分,第一部分有语言模型,第二部分有限制,不过这里的限制根据逻辑公式去做了一个构造,根据这个限制去做生成,我们提出了一个新的算法,叫 TSMH(Tree Search enhanced Metropolis-Hastings),这个算法可以高效地针对目标函数去做采样 [11]。这是介绍的带限制的文本如何去做生成。

接下来我将介绍一下我们在神经网络机器翻译方面最新研究的方法,如何去提升神经网络机器翻译的性能。首先我要介绍镜像生成式模型(Mirror Generative Model),这是 2020 年发表在 ICLR 会议上面的一个新方法。

镜像生成式模型如何提升神经网络机器翻译
我们知道,神经网络机器翻译是非常吃数据的,一个好的翻译模型需要大量的平行双语语料来训练。有很多的语对之间并没有这么大量的平行语料,例如对于中文到印第语的翻译,实际上是无法找到中文和印第语之间大量的平行语料的。自然的一个问题是:我们能否利用单一语料去做训练,例如英语到泰米尔语的翻译当中,我们有大量的英语或者泰米尔语的单语语料,我们利用单语的语料和少量的平行语料一起来做更好的训练。
如何做到这一点呢?实际上当我们观察人的语言能力,我们从中得到一个启发。当一个人会中文和英文的时候,他必然同时具有四种能力:能用中文造句,能用英文造句,能把中文翻译成英文,也能把英文翻译成中文。实际上这里代表了四种语言能力,我们把前两种对应到神经网络里面的语言模型,把后两种对应到神经网络里面的两个翻译方向。
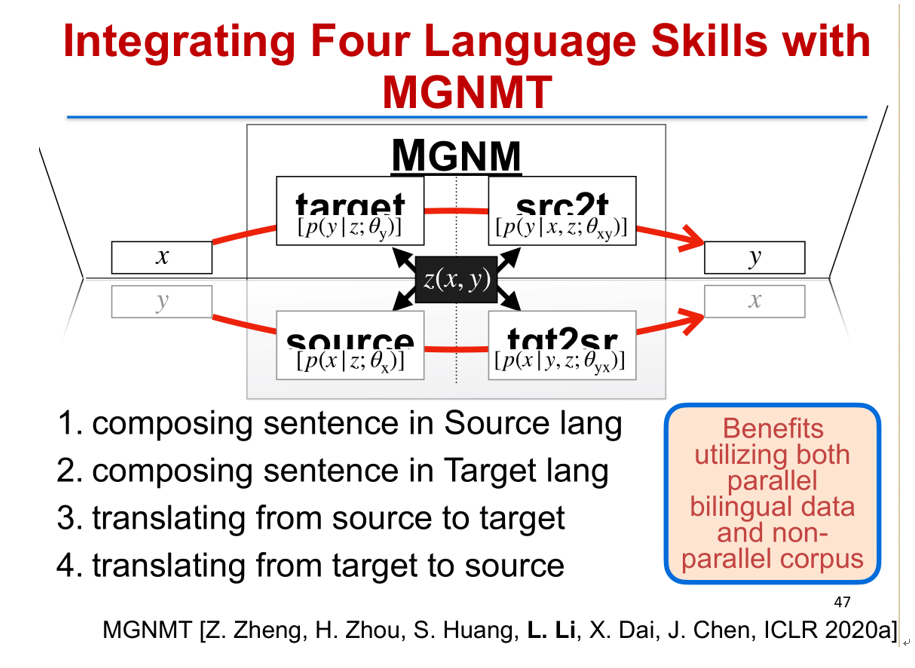
那么,我们能否做一个模型,使得它像人一样只要会两种语言,就会与这两种语言相关的四种语言技能?答案是肯定的。我们可以在两个语言句子 X、Y 之间引入一个隐变量 Z,这个隐变量同时跟原语言以及目标语言有关。把它作为一个桥梁之后,我们把四种技能都整合到一个模型里面,做目标语言的生成,就是 P(Y|Z),原语言到目标语言的翻译就是 P(Y|X、Z),原语言的语言模型就是 P(X|Z),而目标语言到原语言的翻译模型就是 P(X|Y,Z)。如何把这四个概率都放到一个框架里面去呢?我们有一个重要的发现,就是镜像性(Mirror property),我们发现生成概率 P(X,Y|Z),实际上可以写成这样对称的形式,最终把它分解成四项,而这四项分别代表了原语言和目标语言的生成能力,以及原语言到目标语言、目标语言到原语言的翻译能力。而把四个放到一起之后,我们就可以去联合做优化,也就是我们提出的镜像生成式神经机器翻译模型(MGNMT) [12]。

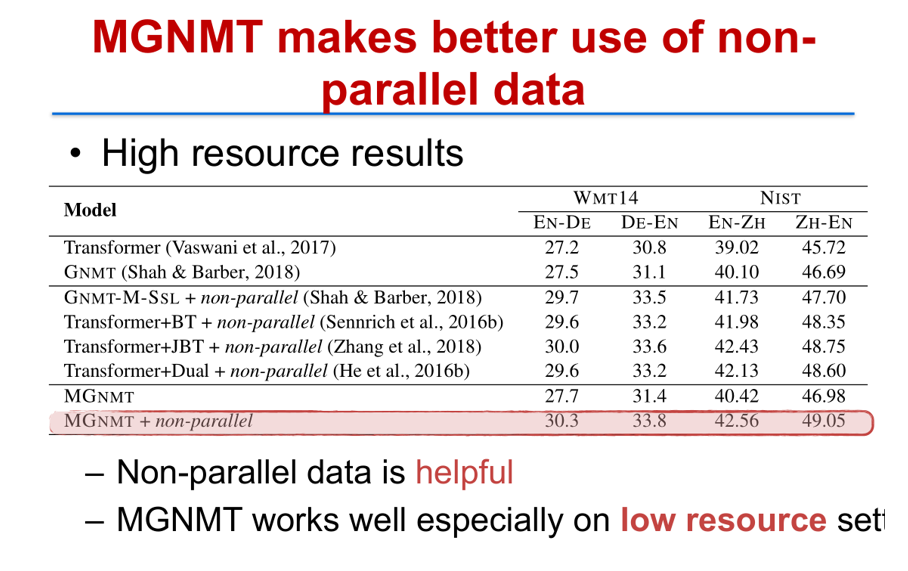
利用这个镜像生成模型(MGNMT),我们在多个数据上都得到了最好的翻译结果。在低资源的情况下,相对于传统的 Transformer 或者 Transformer 联合反向翻译(Back Translation)的方式,MGNMT 都有比较一致的、显著的提高。
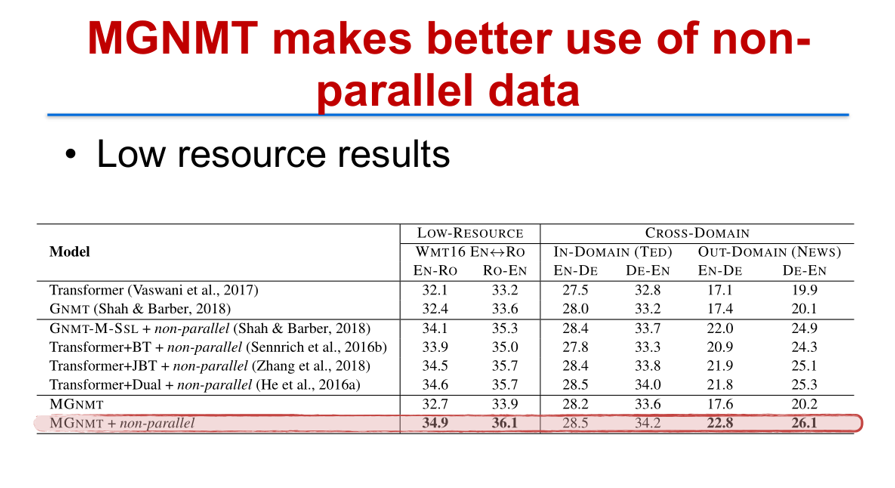
在高资源的情况下(例如英德语向),利用 MGNMT 加上额外的非平行语料之后,我们可以依然比 Transformer 加上反向翻译的方法有明显提升,并且验证了非平行语料的数据是非常有用的,而 MGNMT 在低资源语向的提升会更大一些。
多语言翻译预训练
刚才提到两个语言之间的翻译,我们下一步要介绍的是我们如何做更多语言的翻译。我们在最新的发表在今年 EMNLP 会议上的工作 mRASP 的论文当中就提出了一个多语言预训练的方法。mRASP 是一个全新的范式去训练一个多语言翻译模型,并且在很多场景里面进行少量微调之后,就可以让它在目标语对之间的翻译有较大的提升 [13]。

世界上有非常非常多的语言,如果你数一下,真正有人使用的人类语言有超过 6900 种,我们这里的目标是去构建一个统一的翻译模型,能够自动翻译任何语对。这当然是机器翻译的最终目标,这个目标也是非常具有挑战性的。

我们为什么要把很多门语言放在一起训练?第一个现实的原因是,要训练一个好的机器翻译的模型需要大量的平行语对,而很多语对之间并没有平行语料,所以很多语对之间是非常稀疏的。第二个原因是,根据我们的直观经验,在语对之间有很多共同的信息是可以迁移的。我们知道,如果一个人学德语需要花一年时间,他学法语也需要花一年的时间,这是单独学习的情况。如果他花一年时间先学了德语之后,再去学法语,只需要花三个月时间就可以学会法语了。也就是说,当一个人有了学习德语的能力之后,再去学另一门语言,可以大大缩短他学习其他语言的时间,这就是常说的触类旁通。这就给我们一个很大的启示,我们在做多语言翻译的时候,也许把很多语言放在一起学,总的代价可以比单独学习各门语言的代价总和要小得多。

从模型上来讲,我们还有一个更深层次的目标,更偏数学的一个直观想法是:假如单独学习英语、法语、西班牙语、德语、意大利语等语言的翻译,我们可能学到一个比较好的表示,但是这些表示之间都没有相互的关系。其实这些语言之间,我们依然可以找到一些双语的语对把它们连接起来,这些语对具有相同的意思。
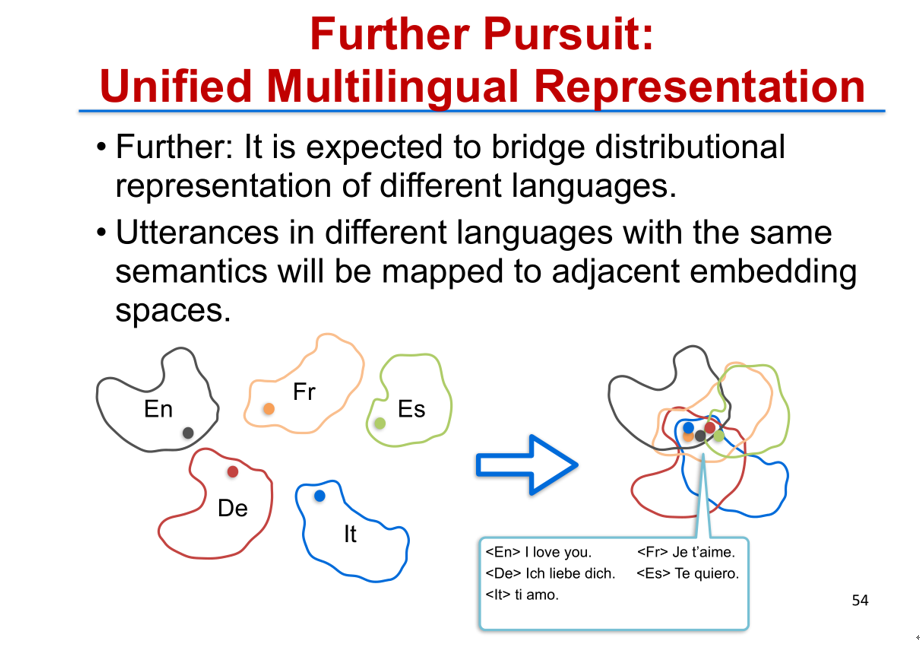
我们就希望通过这些具有相同意思、并且在各个语言里面都出现的一些句子作为锚点,有了这个锚点之后,我们再去统一地学习所有的语言的表示,这样就会学到一个更好的表示。在这个表示的框架下,一个句子即使在不同的语言里面,只要它有同样的语义,就会映射到同样一个表示空间里面的向量上面去。
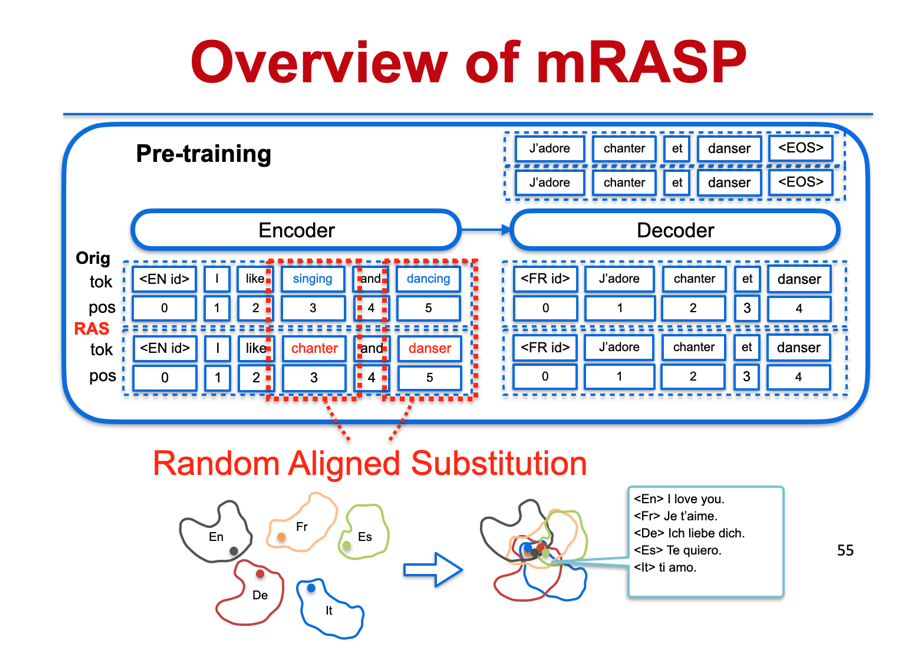
这也是我们提出的 mRASP 核心思想。mRASP 翻译的模型是用基于 Transformer 的编解码器(Encoder-Decoder),我们在输入端加了编码器(Encoder)的语言标识符去表示它输入的语种,在解码器(Decoder)做了一个额外的输入是目标语言的语言标识符,表示它需要翻译的语种。
除了使用大量的双语平行句对来训练之外,我们还利用这些平行句对做了一个数据增强。通过发明的随机对齐替换(Random Aligned Substitution)的方法,我们把原句里面一些词通过同义词词典找到它对应的另外一种语言里面的同义词,然后做随机替换,之后把替换后的源端句子和真正的目标句子再组合成一个伪平行句对,通过这样的方式去做训练之后,就可以得到一个比较好的模型。
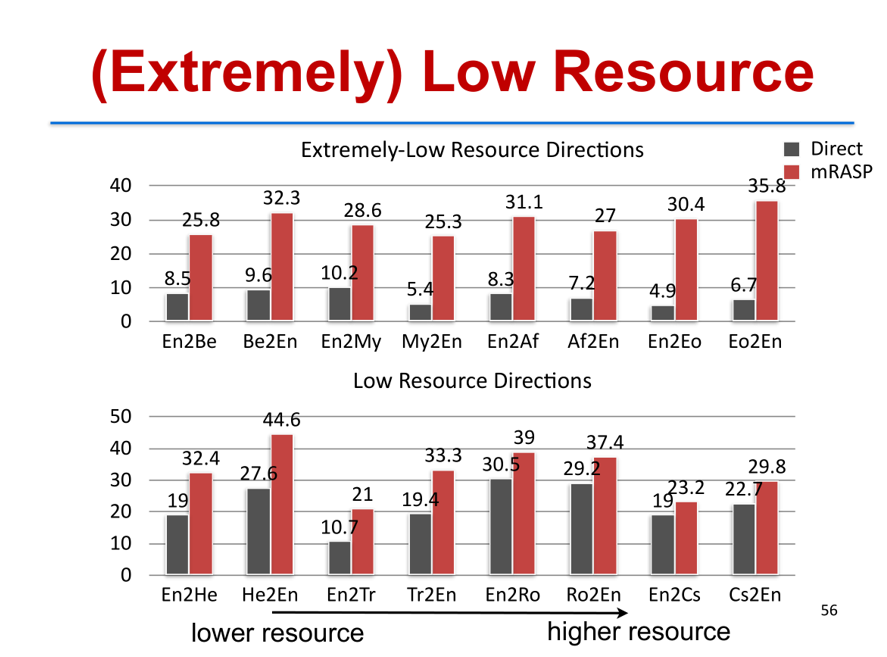
通过 mRASP 这个方法,我们在很多场景下去做了多种语言翻译的测试,这里面显示了我们通过 mRASP 训练了一个初始的模型,这个统一的模型我们在具体语对平行数据上又去微调。比如说这里英语到白俄罗斯语(Be),我们应用 mRASP 预训练好的模型在英语到白俄罗斯语微调之后得到的翻译模型,和在英语到白俄罗斯语双语语料上面直接训练出一个 Transformer 翻译模型做比较之后,发现 mRASP 可以大大提升翻译的性能。在极低资源方向(Extremely-Low Resource Directions)以及低资源方向(Low Resource Directions)这两种场景下,我们都发现 mRASP 这样做预训练微调之后会得到更好的翻译,提升都在 10 个点以上。
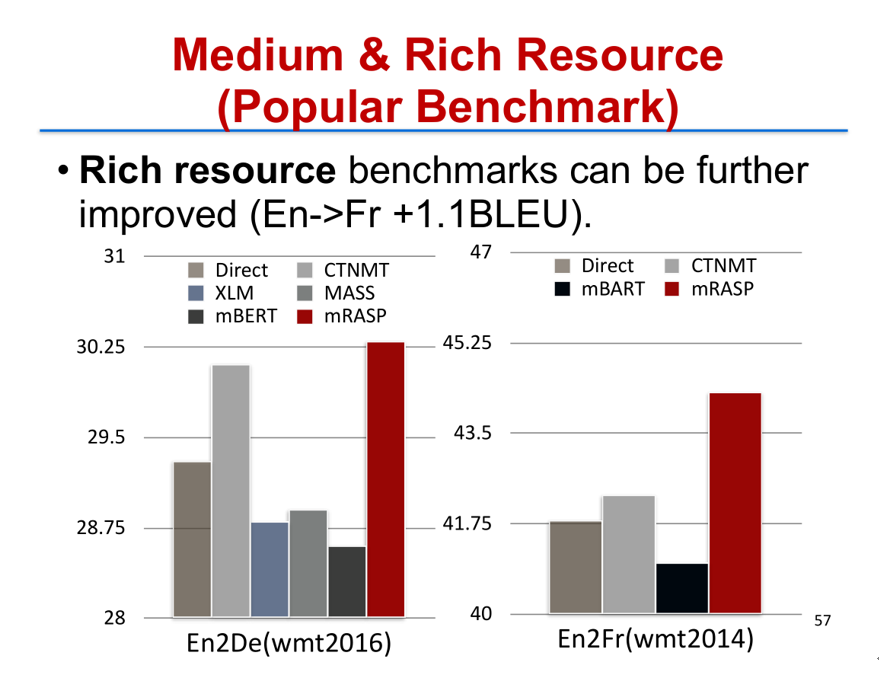
在中等资源(Medium Resource)和高资源(Rich Resource,指双语语对有 100 万以上的平行语料)两个场景下,我们发现 mRASP 方法仍然有比较大的提升,我们也和之前提出的所有其他方法做了对比,包括 XLM、CTNMT、MASS 以及 mBART 等。
我们也做了另外一个实验,mRASP 是否对未见语种也有效?通过 mRASP 训练了之后,我们在一些从来没有见过的语对上面去做微调,例如从荷兰语(Nl)到葡萄牙语(Pt)。这两个语言都没有在 mRASP 的预训练语料里面出现过,而且微调阶段双语平行语料只有 1.25 万,非常少,如果直接在这个语对上面用 Transformer 去训练的话,得不到任何有意义的结果,BLEU SCORE 会是 0。用 mRASP 预训练好的模型,在荷兰语到葡萄牙语的语料上面去微调之后,会得到一些有意义的翻译结果,而 BLEU SCORE 也有了 10 个点的提升(从 0 涨到 13)。

简单总结下我的演讲内容。这里我介绍了多模态协作机器人 Xiaomingbot,也介绍了两种从数据当中学到解耦隐表示(Disentangled Latent Representation)的方法,包括变分模板机 VTM,用来做数据到文本的生成(Data-to-Text Generation)。以及 DSSVAE,从数据当中学到文本和语义隐层表示的。以及 DEMVAE 方法,如何从原始文本数据当中学到有意义的隐表示和语义聚类。我也介绍了在文本生成当中如果有额外的限制,如何用比较好的一些方法去生成高质量的句子,并且符合这些限制,如 CGMH、MHA 和 TSMH 等方法。最后我介绍了两个机器翻译的新方法,一个是镜像式生成模型 MGNMT,可以把平行语料和非平行语料联合在一起去学到两个语言之间的四种语言能力。而 mRASP 更是把机器翻译预训练推广到非常多的语对之间,把这些语对联合起来训练一个比较好的模型,然后在下游的翻译任务上做微调,能够非常有效地提升翻译性能。

我们也开源了一些算法还有工具,包括 mRASP。我们已经把训练后的以及训练好的模型开源。我们最近也发布了一个高性能的序列推理工具 LightSeq [14],针对 Nvidia 的 GPU 做性能优化,重写了序列生成的计算内核,并且在序列生成机器翻译等任务上相对 tensorflow 版本,有 10 倍以上的速度提升。
最后,我们推出了火山翻译系统,如果大家感兴趣,欢迎到 translate.volcengine.cn 网站去体验。目前火山引擎 AI 中台也集合了包括视频翻译、机器翻译、智能同传等模块功能,同时欢迎到火山引擎官网 volcengine.cn 详细了解。
作者介绍:
李磊,字节跳动 AI Lab 总监。字节跳动杰出科学家,卡耐基梅隆大学计算机科学博士,致力于机器翻译、机器写作、智能机器人的研发。
火山引擎是字节跳动旗下的数字服务与智能科技品牌,基于公司服务数亿用户的大数据、人工智能和基础服务等技术能力,为企业提供系统化的全链路解决方案,助力企业务实地创新,给企业带来持续、快速增长。火山引擎围绕数据智能、视觉智能、语音智能、智能应用、多媒体技术和云原生等六大方向,面向企业级市场推出了数十款技术产品与服务,从开发、应用到运营,满足不同类型企业在生命周期不同阶段业务发展的核心需求。
参考文献:

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论 1 条评论