

本文来自 DataFun 社区
标签使用场景
首先介绍下为什么使用标签以及标签的使用场景:
1. 什么是视频标签
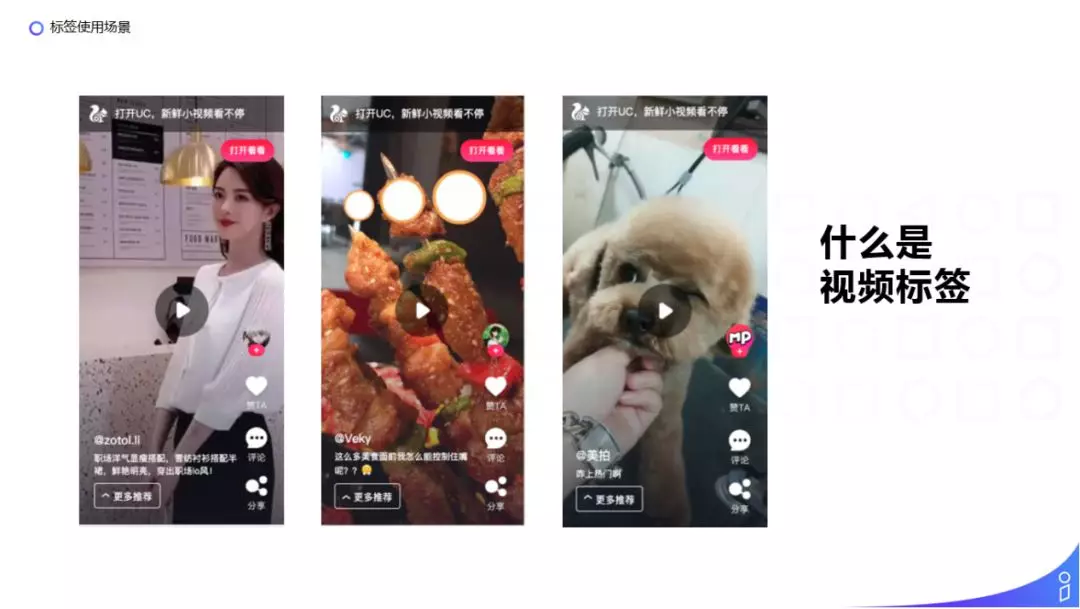
UC 信息流推荐比较多的内容都是新闻资讯类的,每天新的内容都非常多,如果没有内容理解结构化的信息,是比较难做内容冷启动的。视频标签可以理解成描述一个视频的几个关键词,当我们看到视频标签的时候就可以大概知道这个视频的内容。这几张图片是我们信息流小视频的几张截图,大家可以看下可以给这几个小视频打上什么样的标签,比如第一个视频会打上时尚、穿搭、小姐姐等标签,第二个视频会打上美食、烧烤等标签。当我们提取这样的标签之后,该如何使用呢?
2. 标签在推荐中的使用
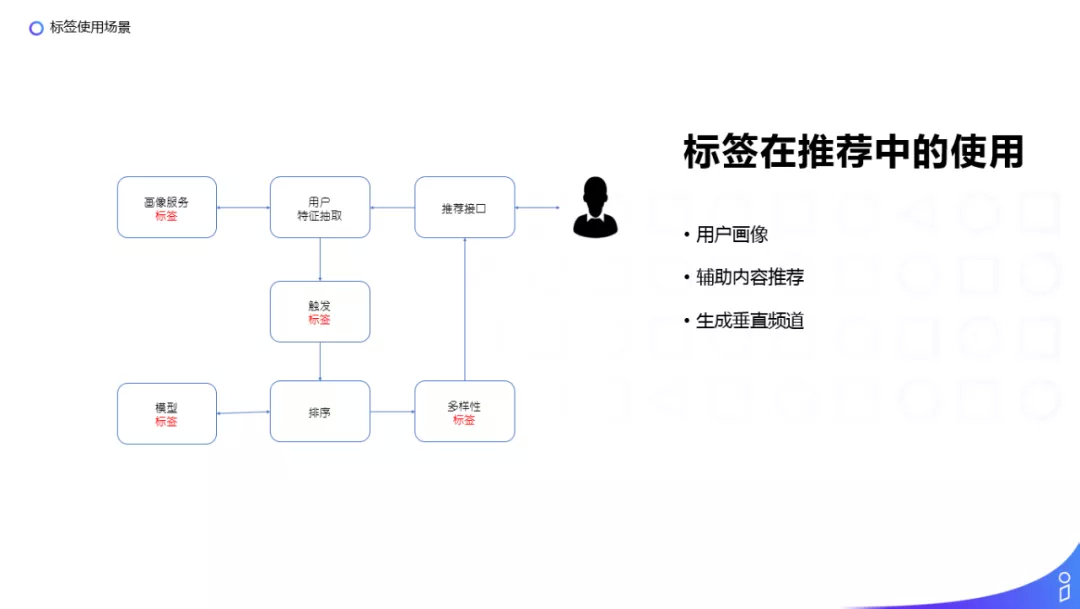
标签在推荐中的使用大概有三个场景:
① 构建用户画像:当用户点击前面时尚穿搭的视频,我们可以大概推测用户可能是对时尚比较感兴趣的女性用户,然后我们会通过对用户一系列的历史行为更精准的刻画用户的画像。
② 辅助内容推荐:当用户触发一次刷新时,可以参考左边的图片,会调用推荐的接口拉取用户画像中用户的特征表示,然后从用户特征中匹配对应的标签作为 Key 来拉取候选的视频或资讯,放入一系列的排序模型中排序(这样的排序模型也会使用标签作为特征进行训练),再对排序之后的候选列表使用标签来控制多样性,避免推荐单一内容使用户产生烦感(我们会使用标签训练一些相似性的模型来判断两个资讯的相似度做一些过滤或者直接限制每一刷同样标签出现的次数),最后对经过排序和过滤之后的候选列表通过阈值截断,把最终的结果返回给用户。
③ 生成垂直频道:比如有娱乐、搞笑、美女等垂直频道,可以方便用户直接获取感兴趣的内容。
标签识别系统架构
接下来介绍下标签识别的系统架构:
1. 标签体系
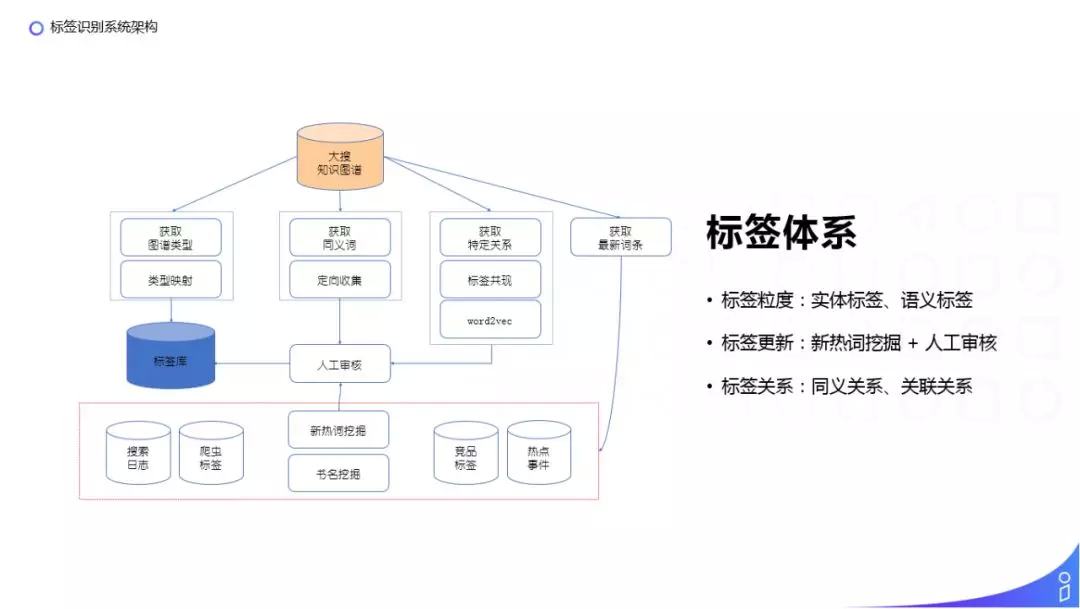
我们需要知道什么样的词适合当做标签来使用,因此,需要维护一套标签体系:
① 标签粒度:在信息流的场景下,标签分为实体标签和语义标签,以一部影视剧为例,具体的某一部电影就可以是一个实体标签,某一类电影,比如喜剧片或者动作片,就是一个语义标签。
② 标签更新:由于不断的有新的词出现,需要不断的更新标签库,标签来源(图中红框部分):搜索日志、爬虫标签、竞品标签、热点事件等。我们会从来源中挖掘出新的候选标签,然后从大搜的知识图谱中拉取标签对应的属性,根据标签属性和标签库已经存在的标签挖掘它的同义词以及关联关系,再经过人工审核把标签和标签对应的属性入到标签库,供后续的使用。
③ 标签关系:同义关系、关联关系(上一步已经介绍,不再复述)
2. 标签系统架构
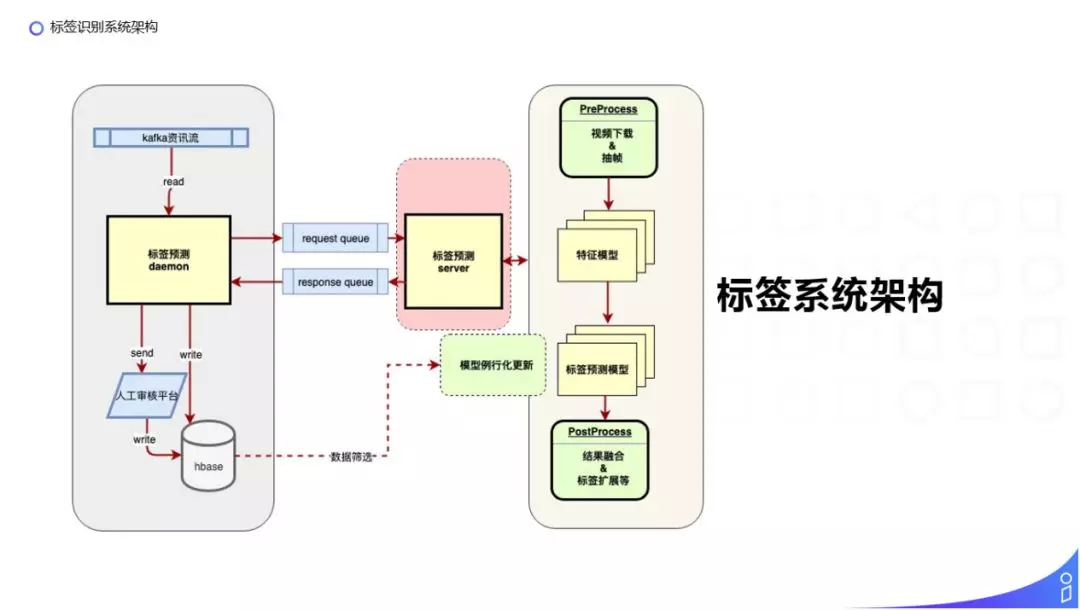
下面介绍下标签的整体架构:
我们会用标签预测的 daemon 不断的消费 kafka 的资讯流,kafka 的资讯流包含新入库和属性发生变化的资讯。标签预测的 daemon 会去筛选新入库的资讯或者包含有模型依赖属性发生变化的资讯去请求标签预测的服务,通过把请求写入 kafka request queue。标签的预测服务会按照右边的流程做预测。首先把视频下载下来,进行抽帧或者文本的预处理,然后把预处理之后的数据拿到特征模块中抽取图像、视频、文本等特征,然后把抽取的特征输入到一系列的标签预测的模型中,把得到的每个模型预测出的结果放入后处理的模块中做融合、去重或者扩展,得到最终返回的标签预测结果,同样把结果写到 kafka response queue 中,然后返回到标签预测的 daemon,标签预测的结果直接写入 HBase 或者推到审核平台,经过人工审核之后再写入 HBase。由于有一些领域的标签变化是比较快的,比如影视剧或者综艺的标签,对于这样的标签预测模型,我们会定期重新拉取数据做例行化的训练。
标签识别算法
接下来主要介绍下标签识别的算法:

我们会使用 NextVlad 进行全局视频标签识别,在整体的标签识别上得到不错的效果,但是对一些长尾的和专业领域的标签处理的还不够好,对于一些专业领域的标签会再用更适合的模型做处理。比如使用 3D 识别行为标签和使用 mtcnn+InsightFace 识别人物标签。
1. NextVlad
最初方案:
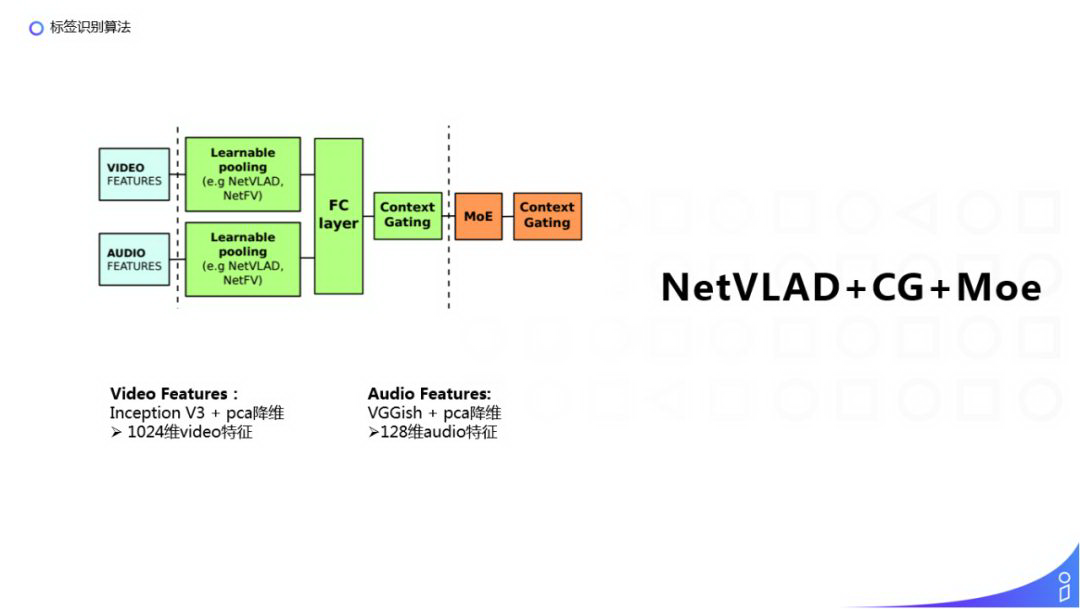
NetVlad 是 2017 年 YouTube 8M 视频理解比赛(主要给 YouTube 的视频打标)中提出来的一个网络结构,主要分为三个部分:左边是特征的输入,中间是视频的特征提取,右边是模型的分类阶段。
① 视频特征:通过 Inception V3+pca 降维得到的一个 1024 维的视频特征;音频特征:经过音频的预处理,使用 VGGish+pca 降维得到的 128 维音频特征,会每秒进行一次采样,相当于每秒会得到一个 128 维的音频特征,VGGish 模型训练使用的是 Audio set 数据集,类似于在图片领域的 ImageNet 这样的模型,主要是做的是声音的分类,包括动物的声音、机械的声音或者音乐的风格等。
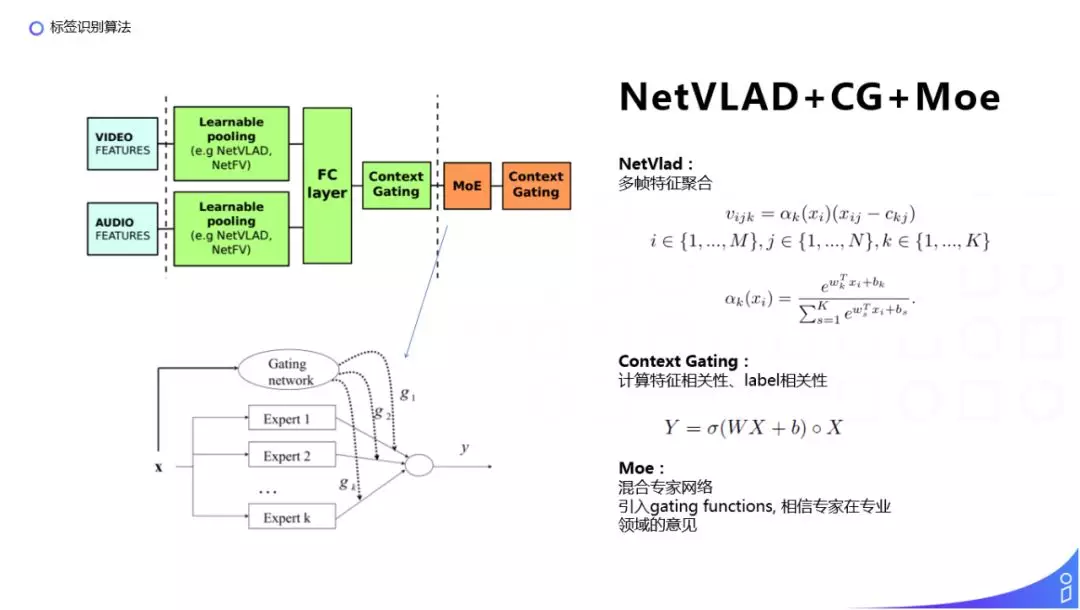
② 特征提取:中间的特征提取层使用了双流的 NetVlad 模块,分别提取视频和音频的特征,之后拼接一个全连接层,然后通过 Context Gating 的机制来重新计算特征的相关性。NetVlad 的主要作用是(由于视频的长短可能是不一致的,输入的特征维度是不一样的。)通过把局部的特征聚合为整体特征的方式,得到一个固定长度的向量表示。
我们看下右边的公式:
NetVlad:
多帧特征聚合:
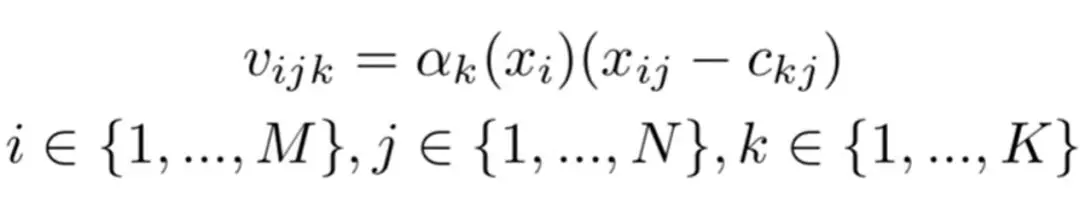
i 表示第 M 帧,j 表示第 N 维特征,k 表示聚类的个数 K。αk(xi) 类似 Softmax 函数计算得到的是第 i 帧属于第 k 个聚类的概率,再乘上 j 维特征与 k 个聚类第 j 维的距离得到每一帧的 N x K 维的向量,通过对所有的 M 帧的 N 维向量进行累加,得到 N x K 维的视频级别向量:
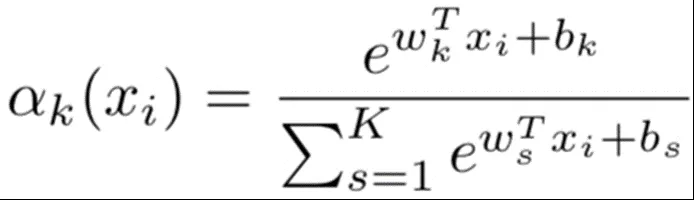
Context Gating 作用:
一方面,计算特征的相关性,使得比较重要的权重变的更大,不相关的权重变得比较小;
另一方面,引入一些非线性,使其效果更好。
Moe:
③ 分类阶段:使用的是混合专家网络(如左下图),把输入 X 分别放入 K 个专家网络,每个专家的单元可以看做一个简单的分类器,再用 gating 网络训练每个分类器的权重,通过线性的加和得到最终预测的效果。这样做的目的是,我们认为每一个专家在他自己的专业领域里会做的比较好,最终的结果是相信了每个专家在他专业领域中的意见,对其进行整合,得到更好的效果。
NextVlad:
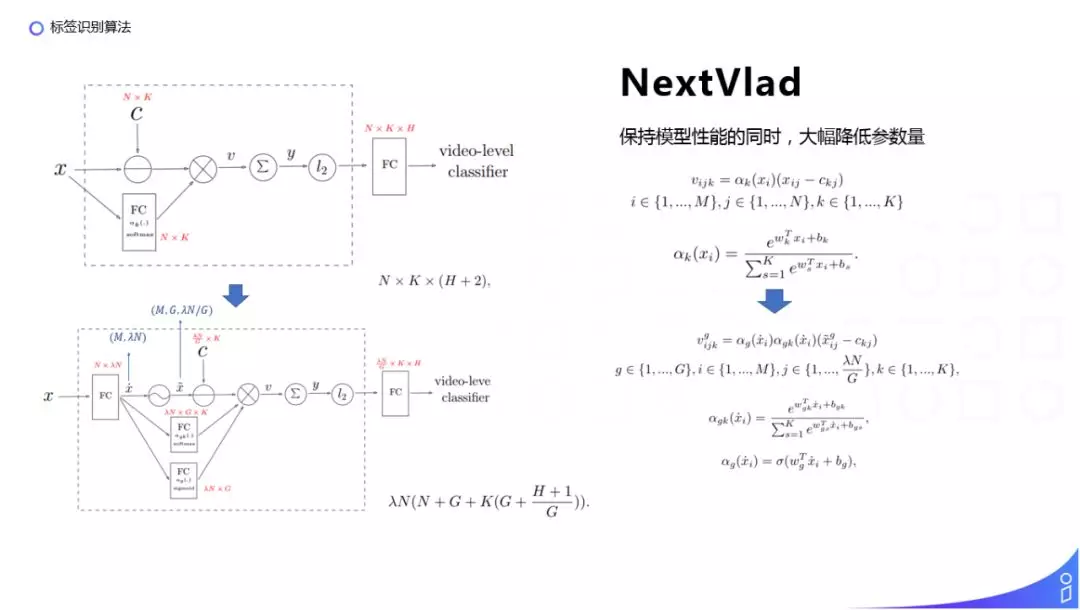
我们使用的 NextVlad 模型是在 NetVlad 的基础上进行改进的。NextVlad 是 2018 年 YouTube 8M 比赛中提出来的网络结构,在保持模型性能的同时,大幅降低了参数的数量。上面是原始的 NetVlad 单元的网络结构,下面是改进之后 NextVlad 的网络结构,标红的部分表示需要训练的参数量。NextVlad 首先是把输入 x 的 N 维特征扩张到 λN 维特征,得到 ,再对 做 reshape,得到 ( M,G,λN/G ) 的 x 波,这样在我们训练分类的时候,降到了 λN/G x K 的维度, 然后使用 Softmax 计算 属于第 K 个聚类的概率,使用 sigmoid 的门函数计算 group 权重,再通过一个连乘得到 i x G 个的聚类维度乘以 K 的向量,然后通过累加得到了一个 λN/G x K 的 y 维向量,这样在进入到全连接层,全连接层的维度就从 N x K x H 降到了 λN/G x K x H 的维度,这样做的话就使我们在方框内的特征 encoding 阶段整体的特征参数是增加的,可能更好的做特征表达,而在特征全连接层的特征量是下降的,达到了整体的参数量有所下降,而模型性能仍然能保持的效果。
Squeeze-and-Excite-gating:
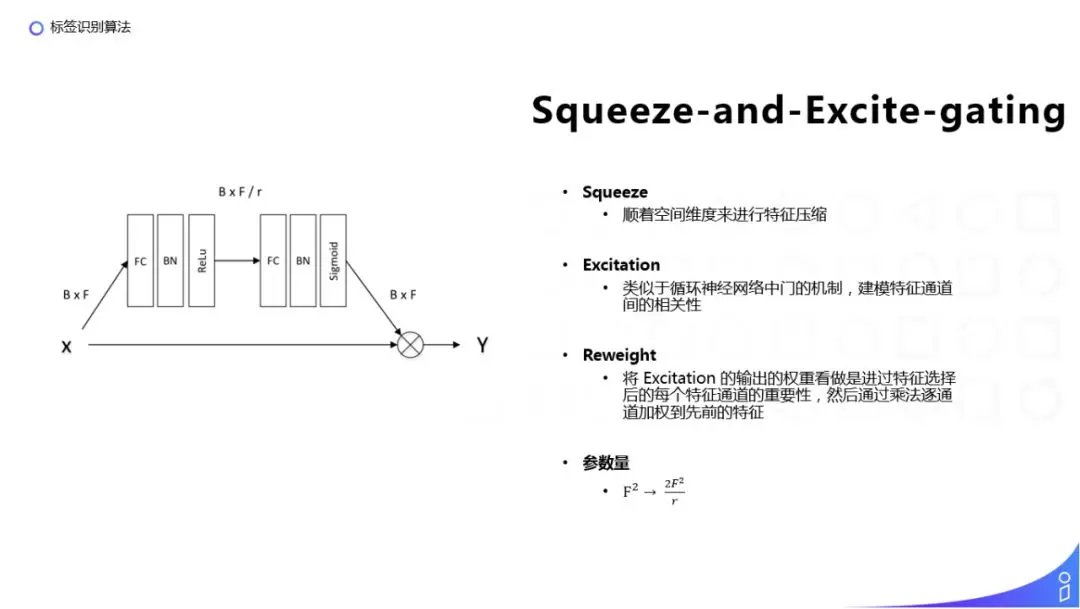
提出 NextVlad 的那篇 paper 同时还改进了 Context Gating 结构,通过把 squeeze 阶段的输 入 B x F,即 batch size 乘以 F 维的向量特征,通过全连接压缩到 F/r 维,然后再加入一个全连接层,把 F/r 维重新放大到 F 维,再加上一个 sigmoid 得到一个 gate 权重,通过 x 乘上 gate 的权重得到最终的输出 Y,这样一方面减少了参数量,另一方面通过两层的全连接层,增加了它的非线性。
Chaining Moe:
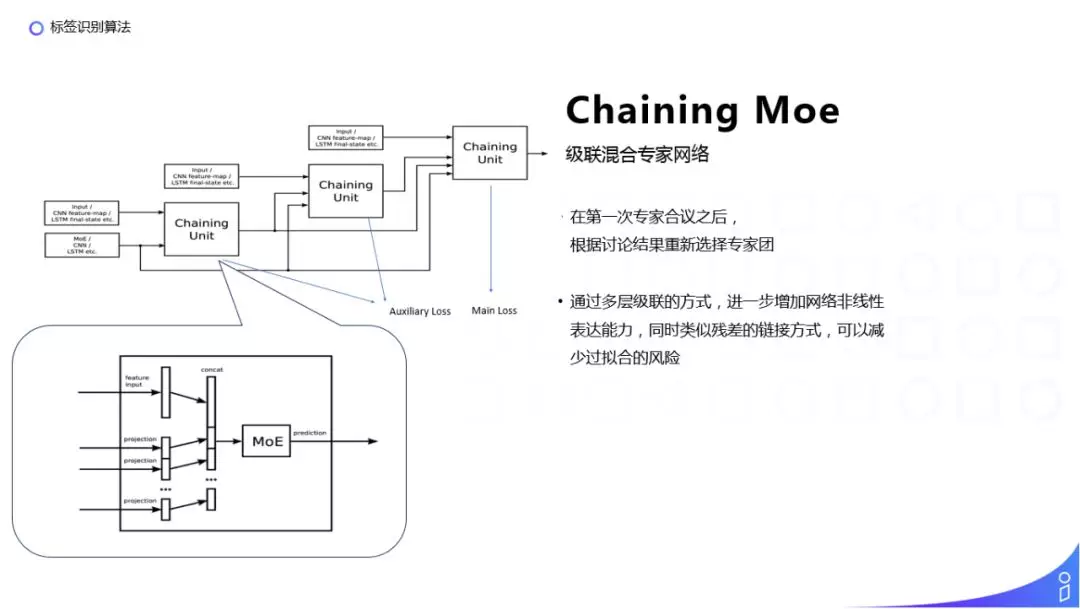
在分类阶段,使用 Chaining Moe 替代原始的 Moe,其网络结构如上图,每个 Chaining Unit 是把原始输入拼接上前面 Chaining Unit 的输出结果,再输入到 Moe 中。这样做相当于每次我们都选取了一批专家,每次在专家讨论结果之后,再重新选择一个专家团。一方面进一步提升了非线性表达能力,另一方面可以减少过拟合。
Knowledge Distillation with On-the-fly Navie Ensemble:
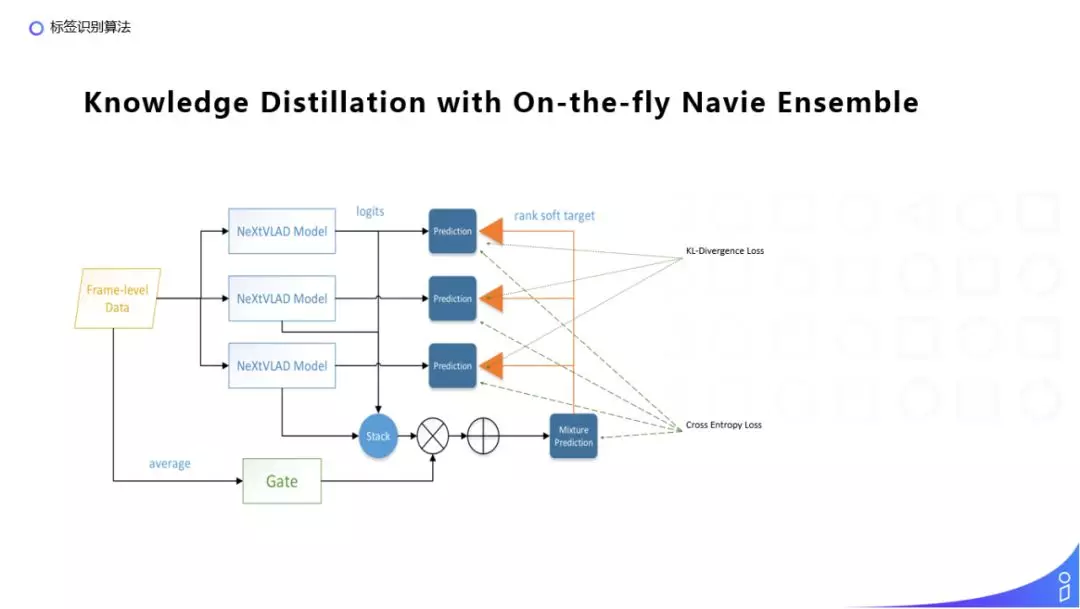
NextVlad 的作者还提出了使用知识蒸馏的方式来做 On-the-fly 的 Ensemble,Mixture Prediction 相当于一个老师模型,上面的 3 个 Prediction 相当于 3 个学生模型,老师模型是通过原始输入求平均之后,训练一个门函数得到每一个学生模型的权重,然后再进行线性加和,得到最终老师模型的输出。老师模型训练的 loss 是原始的视频分类的交叉熵损失函数。每个学生模型是在原始的交叉熵损失函数的基础上加上了老师预测模型的结果,得到的一个 KL 散度 loss 来作为每个学生模型的损失函数。这样做是为了让简单的模型通过学习复杂老师模型的预测结果,使用比较少的参数量也能训练得到比较好的效果。
最终方案:
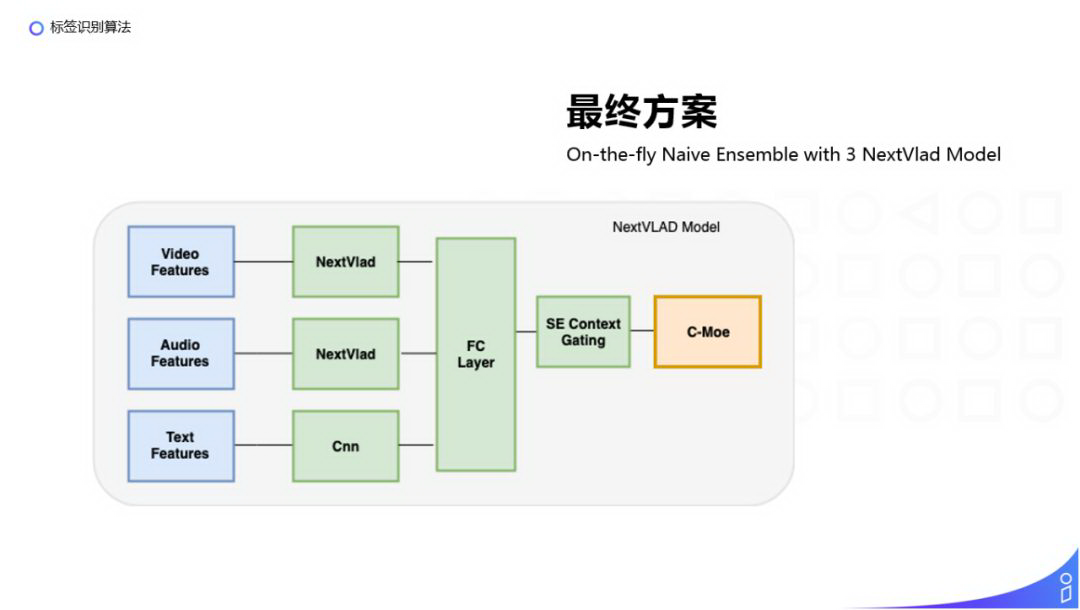
我们最终的线上方案使用了知识蒸馏,用了 3 个 NextVlad 的子模型,每个子模型的结构如上图:对视频和音频的特征分别使用 NextVlad 进行提取,然后对于文本的特征使用 CNN 提取,再把提取到的多模态特征拼接起来输入到一个全连接层,然后输入到 SE Context Gating 中,最后输入到 C-Moe 中训练分类。
2. 行为标签

我们可以看到前面的 NextVlad 模型没有用老视频的前后帧的顺序,一个时空的特征,很多行为是跟时间发生的先后顺序是比较相关的,比如跳起和落下,根据出现的顺序,会是两个完全不同的动作。我们在行为识别上引入了光流特征(可以理解为把 3D 的运动投影到 2D 的图片上),图中的 (a) (b) 是视频中的连续的两帧,© 是计算出来的光流信息,为了使用光流信息,我们会把它储存为一个水平的图片和一个垂直的图片,分别包含水平和垂直维度的向量,这样得到的两张图片可以用传统的图片模型进行训练。
3D ConvNet:
另外一个方案,使用图片的时空特征,通过 3D 卷积(在 2D 卷积的基础上,feature 又增加了一个维度,除了水平和垂直外又增加一个时空维度,它的窗口除了在水平和垂直上进行滑动,也会在时空上滑动)进行训练。
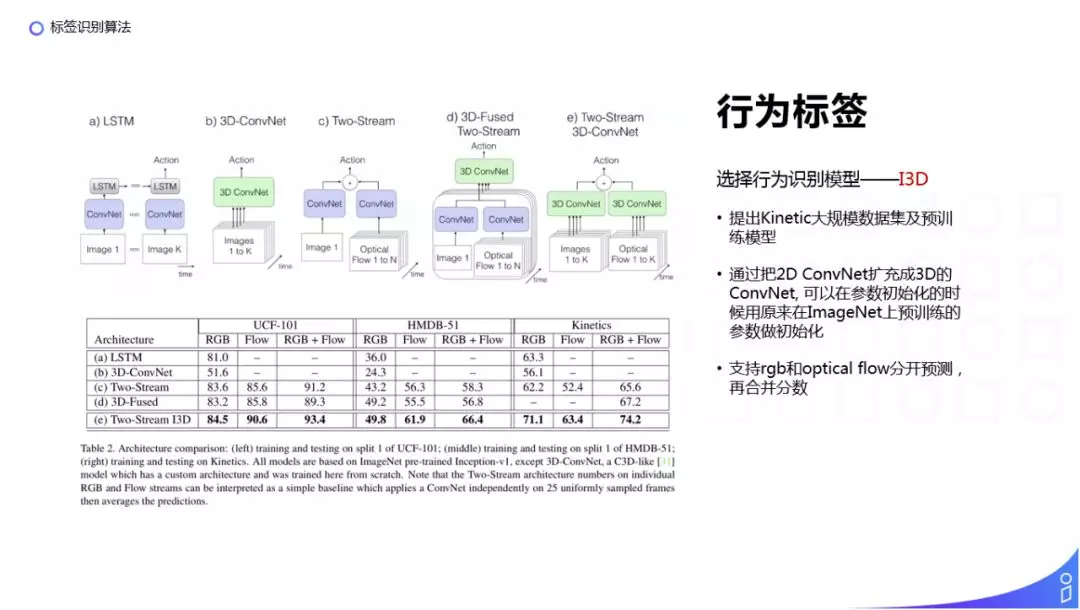
上图为目前比较主流的行为识别模型,有用到 3D 卷积网络,另外一个比较主流的是把每张图片对应的光流信息拼接起来,然后输入到卷积网络,再合并起来预测动作,我们使用的是 (e) I3D 模型,把每张图片对应的光流信息依次排列分别输入到 3D 卷积网络中,然后把 3D 卷积网络训练的特征拼接在一起预测行为。I3D 模型的主要贡献为:
提出了 Kinetic 大规模数据集及预训练模型,可以在视频数据比较少的情况下,训练得到一个不错效果;
通过把 2D ConvNet 扩充成 3D 的 ConvNet,可以在参数初始化的时候用原来在 ImageNet 上预训练的参数做初始化;
支持 rgb 和 optical flow 分开预测,再合并分数。
图中还对比了几种行为识别方法以及最终得到的效果,可以看到 I3D 模型在几个公开的数据集上都有比较好的表现。
3. 人物标签
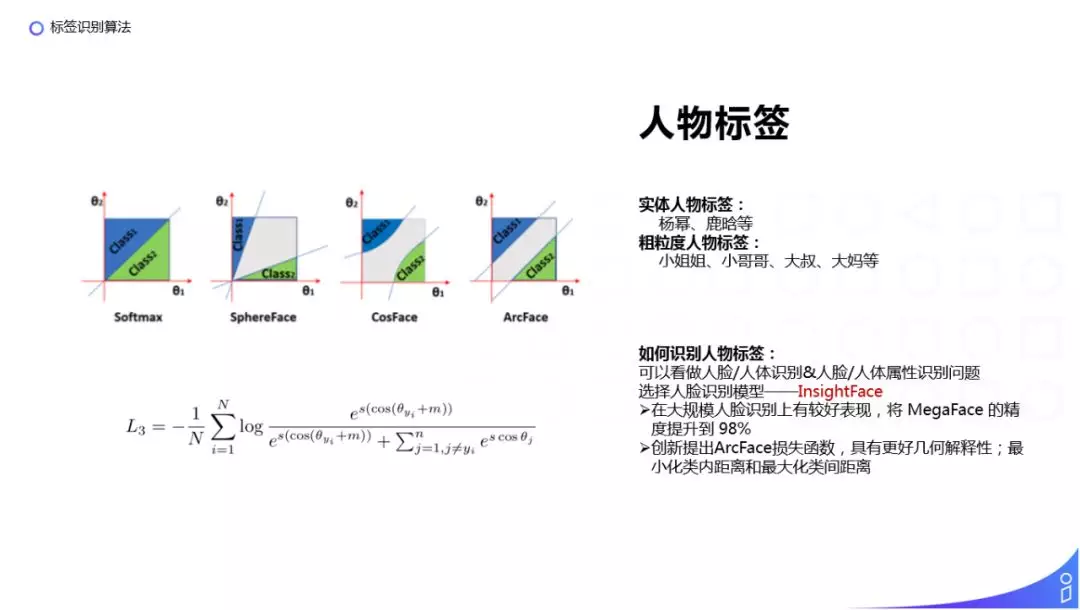
人物标签比较不同的地方,根据人物标签不同的粒度,需要采取不同的方法进行识别。人物标签的识别,可以理解成人脸或者人体的识别问题,我们在现有的模型中,选择了 InsightFace 模型:
在大规模人脸识别上有较好表现,将 MegaFace 的精度提升到 98%;
创新提出 ArcFace 损失函数,在 Softmax 以及之前在人脸识别领域对 loss 做优化的 SphereFace 和 CosFace 基础上,进一步优化了分类平面,具有更好的几何解释性,使类间的距离是更大的,类内距离是更小的。
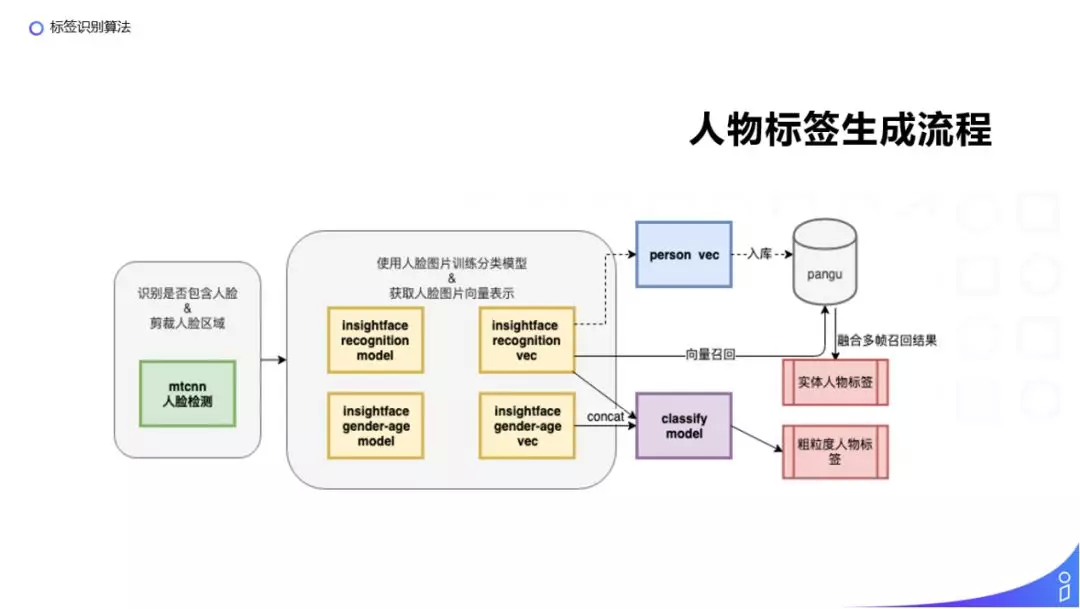
人物标签生成的流程:
① 首先会用 mtcnn 检测视频帧中是否存在人脸,并且通过 mtcnn 把人脸区域剪裁出来,然后把检测出来的人脸输入到 Insightface 训练的人脸识别模型和 Insightface 训练的年龄性别模型中分别提取全连接层的向量。
② 对于实体人物标签我们会对需要识别的具体某一个人使用一批他的人脸图片得到一批他的人脸向量,通过计算得到这个人平均脸的向量,再把这个向量入库到 pangu 中。当有一个新的视频过来的时候,我们对单帧图片识别人脸并计算得到人脸向量,召回 pangu 中最相似的人脸向量,如果召回的人脸向量相似度满足阈值,我们认为图片中出现了对应的人物。
③ 我们对视频会采取多帧,对多帧分别预测,再通过融合来得到最终这个视频里出现的人物。
④ 对于年龄和性别这样的粗粒度的标签,我们会把通过 InsightFace 训练的人脸向量和年龄性别的向量拼接起来,然后把他们输入到一个分类模型中分类,得到他具体是某一个类型的人物标签。
未来的工作

我们目前还是有很多特征没有使用到,比如视频的一些场景特征和物体检测的特征,包括有些视频它的核心内容体现在视频中的 ocr 或语音上,这些是未来我们打算去尝试的特征。
利用更多的标签的关联关系,优化我们目前的打标结果。
参考资料
这是我们工作中,参考的一些论文,大家感兴趣的话,可以去看一下,今天的分享就到这里,谢谢大家。

作者介绍:
雪萌
阿里巴巴 | 算法专家
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论