
今天给大家分享的主题是基于 NVIDIA GPU 和 RAPIDS 加速 Apache Spark 3.0,首先会介绍 Apache Spark 的 RAPIDS 加速器及工作原理,然后分享我们对于 Shuffle 的改进,最后介绍 RAPIDS 加速器 0.2 和 0.3 版本新特性。
用于 Apache Spark 的 RAPIDS 加速器

大家看这张图都能联想到 Hadoop 很经典的一个标志一头大象,现在都是大数据时代了,面对海量数据的这种场景一直在不断地演进一些新的适应的硬件、一些新的软件架构。从最早的 Google 发的包括 MapReduce、GFS 等等的一些新的 paper,然后到业界开源的一些新的软件生态体系,比如说 Hadoop 体系、基于 Hadoop 的文件系统、计算框架比如说 HDFS、Hive、Spark。现在在各个互联网大厂,甚至不只是互联网公司,其他包括工业界的应用也非常的多。传统的这种大数据的处理框架都是基于 CPU 硬件的,GPU 硬件已经发展了很多年,它其实在 AI 领域在深度学习领域已经取得了很好的效果。大家可能会有一个疑问,就是 GPU 能不能让大数据领域大数据处理跑得更快,对于传统的 ETL 流程能不能有一个比较好的加速效果?结果大家通过一些比较感知上的一些认识,可能会觉得还挺合适的,因为大数据天然的数据量非常的大,第二个特点是它的数据处理任务并行度非常高,这两个特点是非常适合 GPU 来执行的,对于 GPU 来说是非常亲和的。
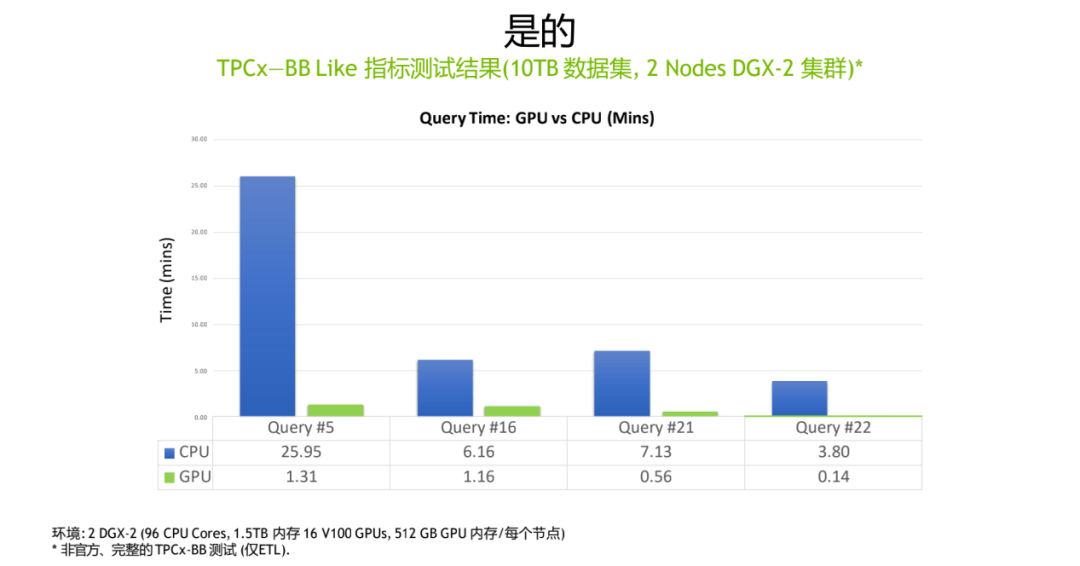
我们给的一个结论“是的”,通过 GPU 的加速,我们在 TPCX-BB Like 数据集上测试的一个结果(上图),可以看到相对于原始的 CPU 版本的 query,我们测了这个图中大概四个 query 它的执行时间分别是 25 分钟、6 分钟、7 分钟、3 分钟,经过 GPU 版本的执行,它的时间都缩短在一分钟上下左右,甚至最后的 query 只有 0.14 分钟。我们用的数据集是 10TB 的一个数据集,一个比较有参考性的大小,然后用的硬件规格是一个两节点的 DGX-2 集群,DGX-2 是一个搭载了 16 张 NVIDIA V100 显卡的 AI 服务器。
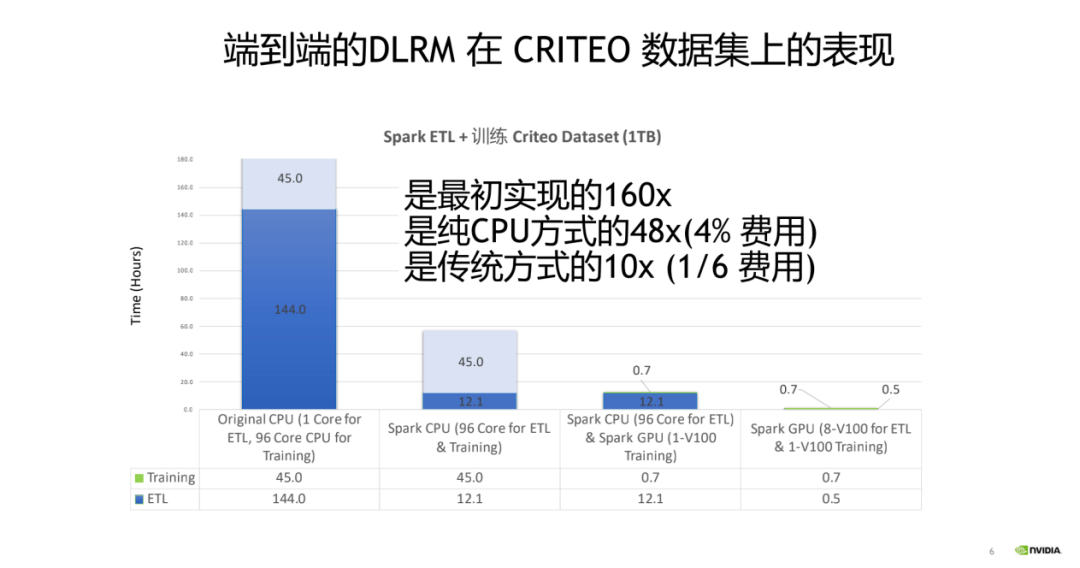
再比如说很多互联网场景推荐场景上,我们是不是能达到比较好加速效果?因为目前很多互联网公司推广搜推荐场景可能会涉及到,比如说短视频推荐、电商推荐、文本推荐,目前面临的一个问题是推荐场景本身,互联网公司它的业务覆盖的用户规模越来越大,内容本身也处在一个内容爆炸的一个时代,有海量的 UGC 的内容。一方面用户的数量的规模扩大,另一方面内容的数量量级的规模的扩大,对于整个的 ETL 训练的挑战都是非常大的。我们给出了一个 DLRM 经典的推荐模型在 CRITEO 数据集上的一个表现,达到了大概的一个加速效果是怎么样?我们依次看一下这四个版本的数据,最原始的版本还没有分布式的训练数据处理框架诞生之前,对于这种 ETL 的流程可能就是用一种单核或者说单机多核的这种方式去处理 ETL 的时间大概能到 144 小时,训练的时间我们用多核的去训练的达到 45 个小时。从最原始的版本的改进,我们可以说比如说用 Spark 这种形式比较先进的分布式计算框架去做 ETL,这个时候它的 ETL 的流程能缩短到 12 小时。我们还可以怎么继续改进,比如说我们在训练的这一段,从传统的多核的 CPU 切换到 GPU 训练,我们这边举了一个例子,是用了单张的 V100 去做训练,训练的时间从之前的 45 个小时缩短到 0.7 个小时,最终其实就是今天要 highlight 的主题,就是说我能把 ETL 这部分如果也切到 GPU 训练,大概能达到一个怎么样的效果?我们这边举的一个例子是用了 8 张 V100 显卡做 ETL,最终的 ETL 的时间能缩短到 0.5 小时,整体的加速比从最早的时间是大概提升了 160 倍,到比较先进的 CPU 方案仍然有个 48 倍的提升效果,只用了 4%的成本。比目前比较主流的方式就是 CPU 做 ETL,然后用 GPU 做训练,我们仍然能达到一个 10 倍的加速效果,但是只有 1/6 的成本。

这其实是去年的 GTC2020,老黄发布的其实是一个比较经典的一个语录,就是“买得越多,省得越多”。这句话不无道理,对于一些原本的一些大数据的处理流程,是不是可以利用一些新的一些硬件特性,新的一些处理范式,取得更好的一个性价比,达到一个更小的成本?其实给的这个答案是的。

如果我们想用 GPU 去做加速 Spark 处理,我们需要去改动多少的代码规模?其实这个是大数据工程师、数据分析师非常关心的一个问题,我们这块儿给的答案是对于 Spark SQL 和 DataFrame 代码其实并不需要做代码的任何的更改,也就是说你的业务代码是不用变,只不过是我们在配置项的时候,我们会看到第一行开头会把“spark.rapids.sql.enabled”设成 true,就是一个配置项的改懂,然后让 spark-rapids 生效,后面的这些业务代码都是保持不变,它的实施成本是非常低。

对于很多 Spark SQL 和 DataFrame 的里头的算子,这个算子的数目也是非常庞大的,我们也是需要去一个一个去做适配。目前我们可以整体的看一下这张图,就是说支持的算子规模应该是非常大的。没有再支持的这些算子,我们也非常欢迎大家反馈给我们,可以在 github 上去给我们提 feature request。我们也非常迫切的想知道工业界里头具体哪些算子其实是用的频率非常高,但是实际上我们还没有去尽早的支持,这对于我们改进这个产品也是非常重要。
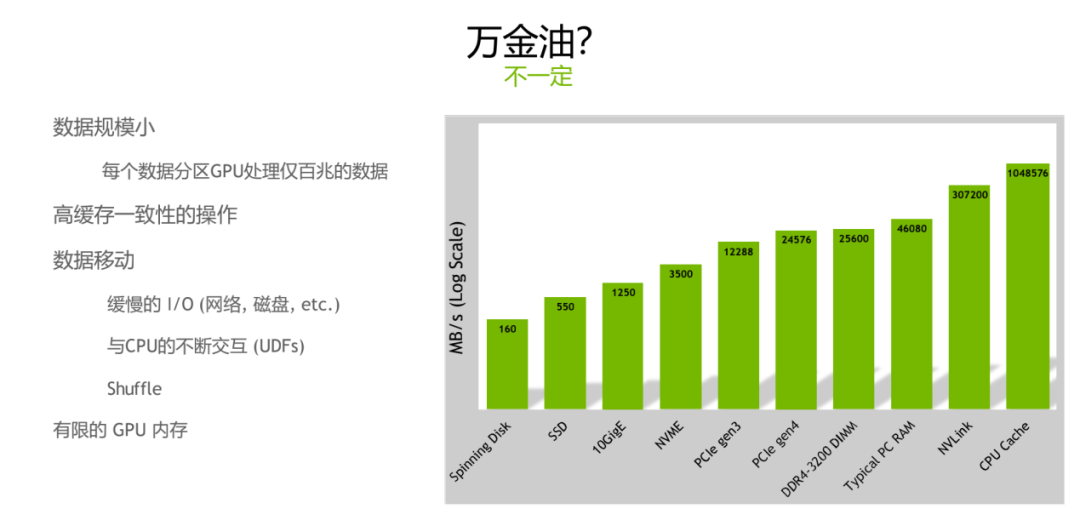
Spark 如果是跑在 GPU 上是不是能解决传统的 CPU 上的所有的问题?其实是不一定的,我们有一个客观的分析,对于某一些场景图左边举的这些例子,其实并不一定说在 GPU 上跑就能达到一个很好的效果。比如说数据规模特别的小,整个的数据的 size 可能会特别小,但具体到每个 partition 的话,如果我设的 partition 数也是比较多一点,其实可能 partition 它的数据大小只有几百兆,不一定适合跑在 GPU 上。第二种场景就是说高缓存一致性的操作,这一类的操作如果在你的公司的业务的 query 里头包含的比例非常高的话,也不一定是 GPU 是十分合适的。第三类就是说包含特别多的数据移动,比如说我的整个的这些 query 有各种各样的 shuffle,shuffle 的比例非常的多,可能我的整个的操作是 bound 在 IO 层面,可能有网络、也可能有磁盘。还有一种可能就是 UDF 目前的实现可能会经常串到 CPU,就是说还是会牵扯到 CPU 与 GPU 之间,可能会产生不断的一些数据的搬运。在这种情况下,就是数据移动特别多的情况下,GPU 也不一定是很合适的。最后一种场景就是说我的 GPU 的内存十分有限,主流的英伟达 GPU 的显存也都是看具体型号,最新的 A100 也都能支持到 80G,但是可能对于特定的场景来说,可能内存还有可能不够,如果是这种比较极端的情况下,也有可能说处理不了,也有可能说在 GPU 上的加速效果并不一定是十分的明显。右图非常清晰得展示了各个环节的吞吐大小是怎样的,从最左边看如果你是经常需要写磁盘、网络环境并不是十分高配的网络架构、数据移动比较多的话,经常会 bound 到这些地方。

但是我们在 GPU 上跑 spark 仍然还是有很多的一些任务,它是十分的适合 GPU 场景。我们举一些具体的例子:
1. 高散列度数据操作
比如说高散列度的这三类操作,比如 joins、aggregates、sort,这些其实都是一些基于 shuffle 的操作。高散列度具体指的是某一个 column,它不同的值的数量除以整个的 column 的数量,或者简单理解为不同的值的数量是不是比较大的,如果是高散列度的这种情况的,是比较适合用 GPU 来跑 Spark。
2. window 操作比较多
第二类是说 Windows 的 window 的操作特别多,特别是 Windows size 的比较大的情况下,也是比较适合于 GPU 的。
3. 复杂计算
第三类的话就是说复杂的计算,比如说写一个特别复杂的 UDF,也是比较适合 GPU 的。
4. 数据编码
最后的一个是说数据编码,或者说数据的序列化、反序列化读取和写入,比如说创建 Parquet、读 CSV,在这种情况下,因为 GPU 我们有一些特定的针对 IO 的一些优化,对于这一块来说性能加速比较好。
Spark Rapids 工作原理

1. ETL 技术栈
我们大概的介绍一下 Rapids Accelerator,它的工作原理是怎么样,整个的 ETL 的技术站可以如下图所示:
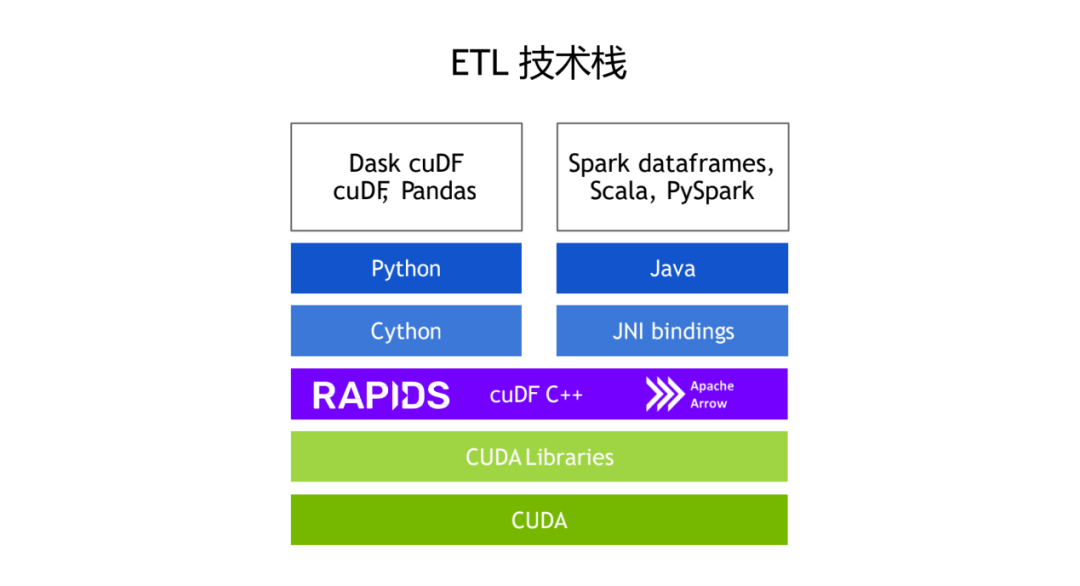
图左边的可以看一下是 Python 为主的技术栈,传统的包括我们用 Pandas Kaggle 竞赛,或者说做数据分析的时候可能用 Pandas 会比较多,操作 DataFrame 的数据,我们对应的也提供了 GPU 版本的 Pandas-like 实现,叫做 cuDF。在 cuDF 的基础上我们提供了分布式的 Dataframe 支持,它就是 Dask cuDF。这些基础库底层依赖的是 Python 和 Cython。最右边是 spark 技术栈上我们对应的一些优化,对于 Spark Dataframe 和 Spark SQL 都有了对应的加速,然后对于 Scala 和 PySpark 也都有一些对应的优化的实现。然后它底层依赖最上层是 Java,底层调用实际上是 cuDF 的 C++API,中间的通信是通过 JNI 来通信库。cuDF 也是依赖 Arrow 的内存数据格式。对于这类列式存储,我们在 CPU 的基础上,也提供了 GPU 的支持。最底层是依赖于英伟达的显卡的一个计算平台 CUDA,还有依赖 CUDA 基础上搭建的各种底层的一些实现的一些底层库。
2. RAPIDS ACCELERATOR FOR APACHE SPAK
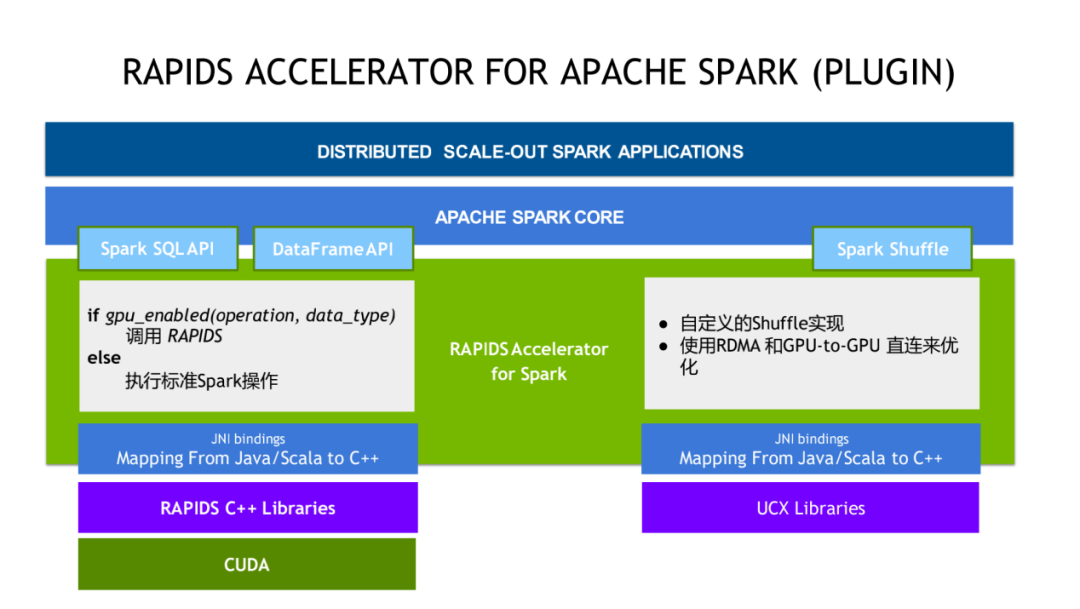
我们今天要关注的 RAPIDS Accelerator 它的整个架构是怎么样?可以先从上图中最顶上看,最顶上是具体的算法工程师或者说数据分析师写的 Spark 任务在中间这一层是 Spark core。左边这块我们目前已经实现加速的是 spark SQL 和 DataFrame 的 API。刚才前面也讲到,我们是不需要去更改任何的业务代码,对于所有的这些业务代码之中描述的这些操作,这些算子来说,我们提供了 RAPIDS Accelerator 可以自动的去识别对应的操作数据类型,是不是可以调用 Rapids 来进行 GPU 加速,如果是可以的话,就会调用 Rapids,如果是无法加速的话,就会执行标准的 CPU 操作,整个调度对于用户来说,对于实际写 Spark 应用的人来说是透明。右边这块是对于 Shuffle 的支持,Shuffle 也是 Spark 很关键的一个性能瓶颈。对于 Shuffle 的流程,我们具体是做了哪些优化?对于 GPU 和 RDMA/RoCE 这种网络架构下,我们实现了一套新的 Shuffle,在底层使用了 UCX 来达到一个更好的一个加速效果。
3. SPARK SQL & DATAFRAME 编译流程
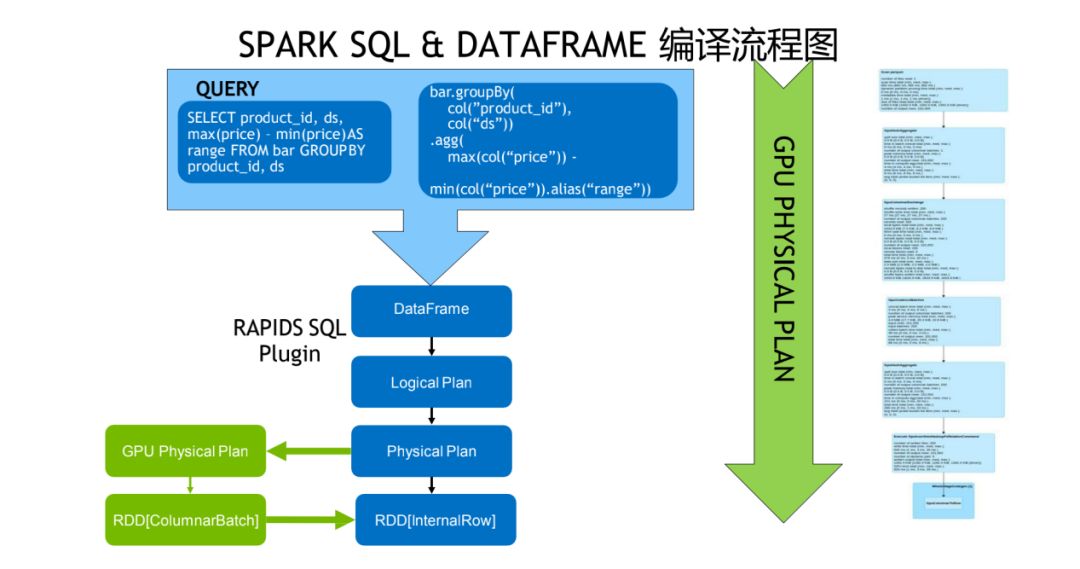
整个的 Spark SQL 和 DataFrame 的一个编译流程是如上图所示,最上层是 Dataframe 在 Logic Plan 这一层还是不变,经过 Catalyst 优化,生成 Physical Plan 之后,对应到 GPU 的版本我们会生成 GPU 的 Physical Plan,具体输出的数据是 ColumnarBatch 的 RDD。如果需要把数据转回 CPU 处理的话,会再把 RDD 转回 InternalRow 的 RDD。
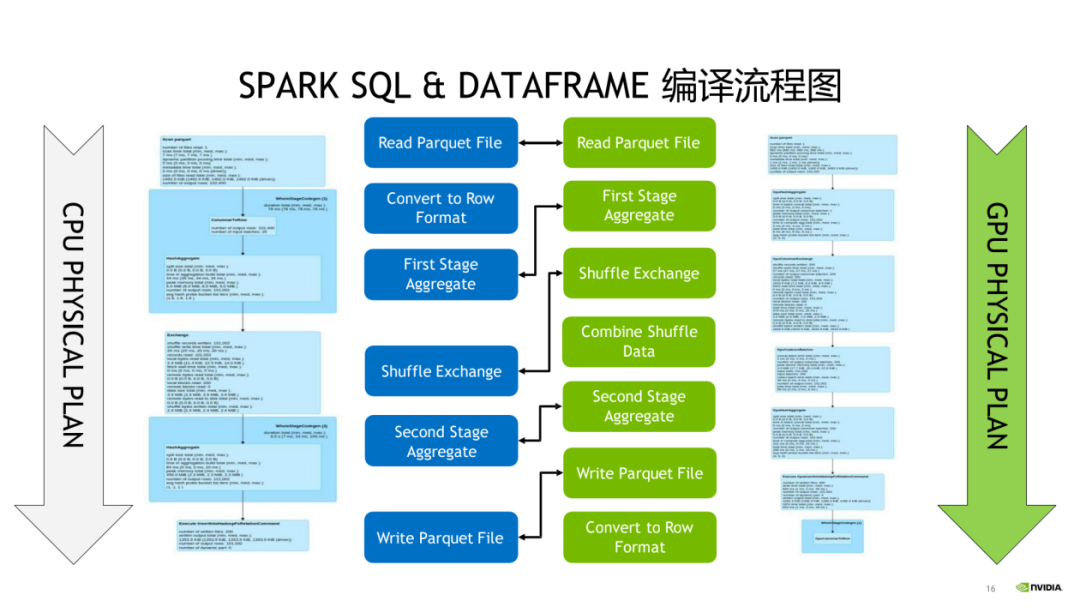
具体的 Spark SQL 和 DataFrame 的执行计划,会对应到 GPU 的 plugin,如果采用后会产生哪些变化,给出了一张比较详细的图。

大家可以感兴趣的话可以自己测试一下。具体是对应到一个 CPU 的 operation,如果是能用 GPU 优化的话,是能一对一的是去 map 到 GPU 的一个版本,如果说大家想自己去测一下 GPU 的版本 Spark 处理效果能达到一个怎么样的一个加速比,DataBricks 提供了一个比较标准的 Spark SQL 生成数据的一个工具。我们主要也是依赖这个工具去做了一些 benchmark,主要的参数可以参考一下,我们用的选择 scale factor 是用的 3TB,也用到了 decimals 和空类型。输入的 input partitions 的数目是 400,shuffle 的 partitions 是用的 200,所有的输出的结果会写到 S3 上。
4. 效果

整个的加速比的效果是怎么样?TPC-DS 数据集上它加速比是怎么样?我们可以看一下 QUERY 38 的加速效果。具体选用的 CPU 的硬件的标准和 GPU 的硬件标准,都是 AWS 的标准的硬件单元,价格也都是非常透明。如果是从查询时间上来看的话,相比于 CPU 版本的话,大概有三倍的提升。虽然可以看到最底下 GPU 的硬件,我们用的是一个 driver 是一个 CPU 的 driver,worker 是用一个八节点的单 GPU 的配置,在这种情况下,每小时的 cost 会是高一点,但是整个 query 时间有了三倍的提升,最终算下来的话,我们大概节省了 55%的成本。
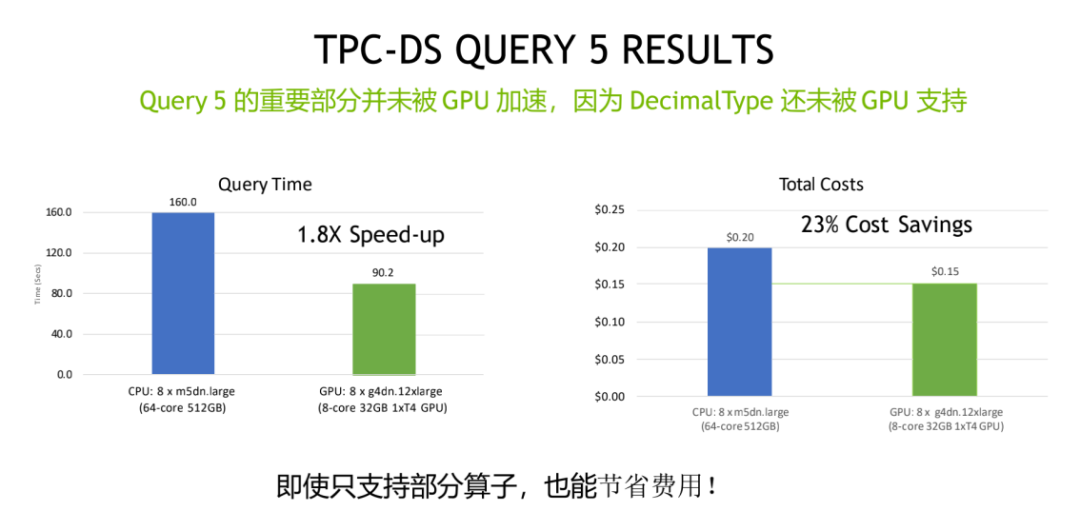
Query 5 也是一个比较经典的一个查询,它特别在哪儿?因为它重要部分都没有被 GPU 加速,只有少量部分被 GPU 加速,因为具体来说的话是它的 Decimal Type 还没有被 GPU 支持。在这种情况下,GPU 版本也取得了一个比较好的性价比收益,相对于它的查询时间来说,是有 1.8 倍的速度的提升,成本上来说仍然能节省 23%的成本。对于大家对于想从 Spark3.0 的集群 CPU 目前的架构过度到 GPU 架构的话,这是一个比较有参考性的一个例子,因为我们目前的 Rapids Accelerator 一直在紧锣密鼓的在迭代之中。目前的版本来说,即便不是所有的 query 都能被 GPU 加速,但是仍然还是能取得一个比较好的一个性价比。
加速 Shuffle
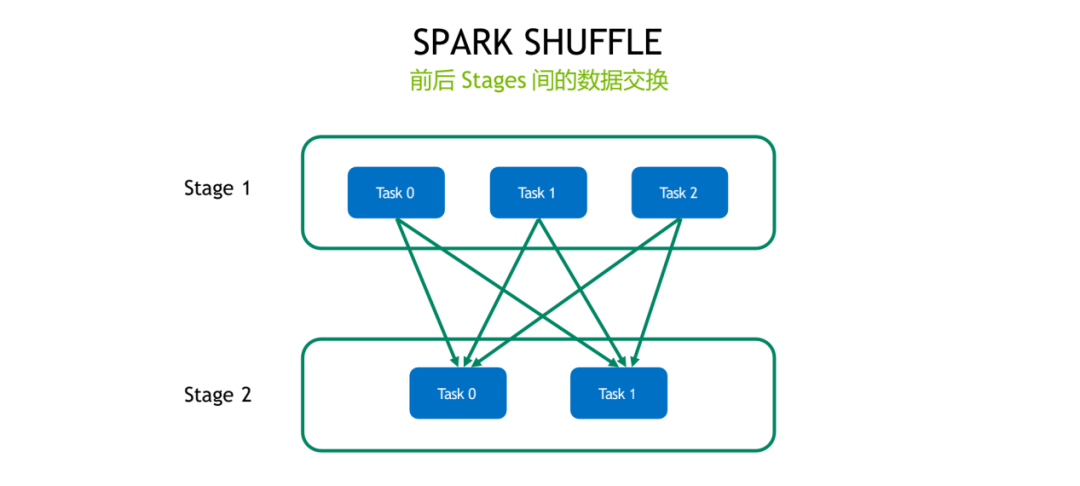
我们会主要讲一下 Shuffle,Spark Accelerator 做了什么,它为什么要针对 Shuffle 做加速。传统的 Shuffle 大家如果是对 Spark 比较熟悉的话,这块也不用再赘述了,其实就是牵涉到我们在某一些特定的一些操作,比如说 join、sort、aggregate,要牵涉到节点是节点之间,或者说 executor 跟 executor 之间要做一些数据的交换,要通过网络做一些数据的一些传输,前一个 stage 跟后一个 stage 之间会产生一些数据的一些传输,就是牵涉到前一个 stage 要做一些数据的一些准备,然后把数据写到磁盘,然后通过网络把数据拉取过来,这中间可能也会牵扯到一些磁盘 IO,然后把数据规整好。
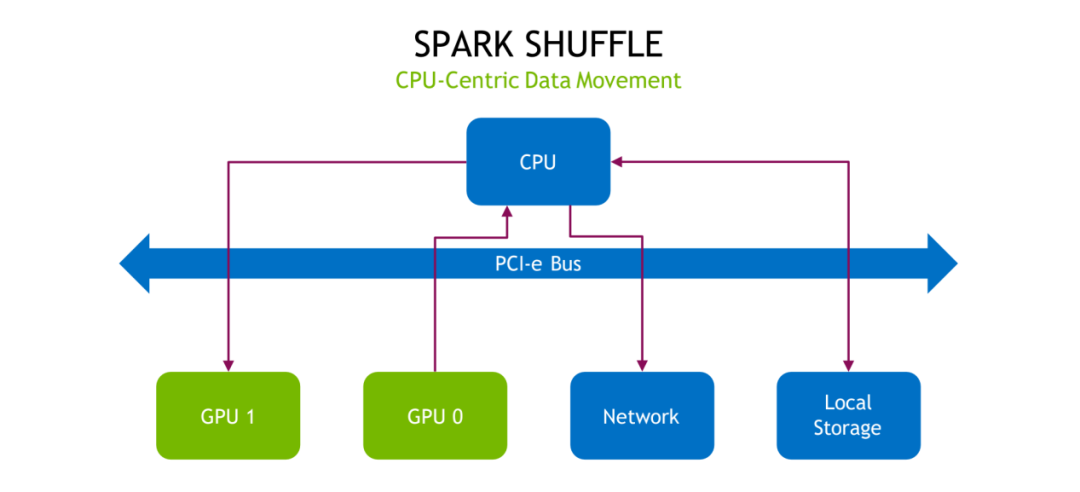
传统的 Shuffle 的它的流程如上图所示,这张图是基于 CPU 的目前的一个硬件环境,Shuffle 它的数据的搬移具体是怎么样一个流程,可以看到如果是我们不做任何的优化的话,即便是数据存在 GPU 的显存上,它也要经过比如经过 PCI-e,然后才能去走网络,走本地的存储。可以看到有很多不必要的一些步骤,然后产生了一些额外的开销,比如说没有必要一定要经过 PCI-e。
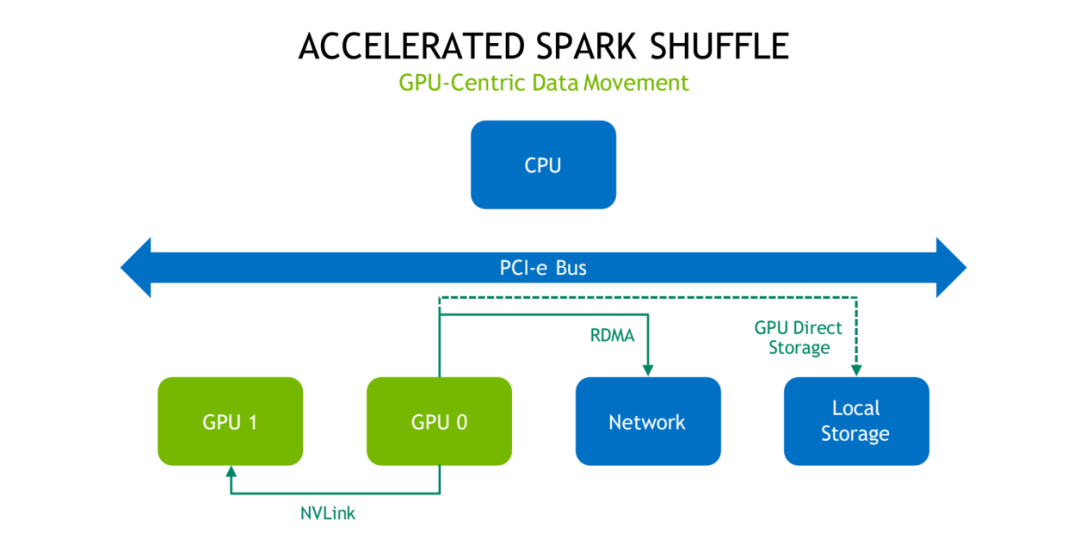
经过我们的优化的 Shuffle 之后,它大概的一个数据的移动是表现是怎么样?首先如上图所示,第一张图描述的是说 GPU 的 memory 是足够用的。这种情况下这时候的 Shuffle 是怎么走的?如果在同一个 GPU 内的话,数据本身不需要搬移。如果是在同一个节点,如果我们采用的节点也是有 NVLink 的情况下,这个数据可以直接通过 NVLink 来传输,而不用走 PCI-e,也不用经过 CPU。如果这个数据是存在本地存储 NVMe 接口的存储,可以通过 GPU Direct Storage 去直接做读取,如果是远程的数据,我们可以直接通过 RMDA 去做加速,同样用同样的也都是 bypass 掉了 CPU 和 PCI-e。
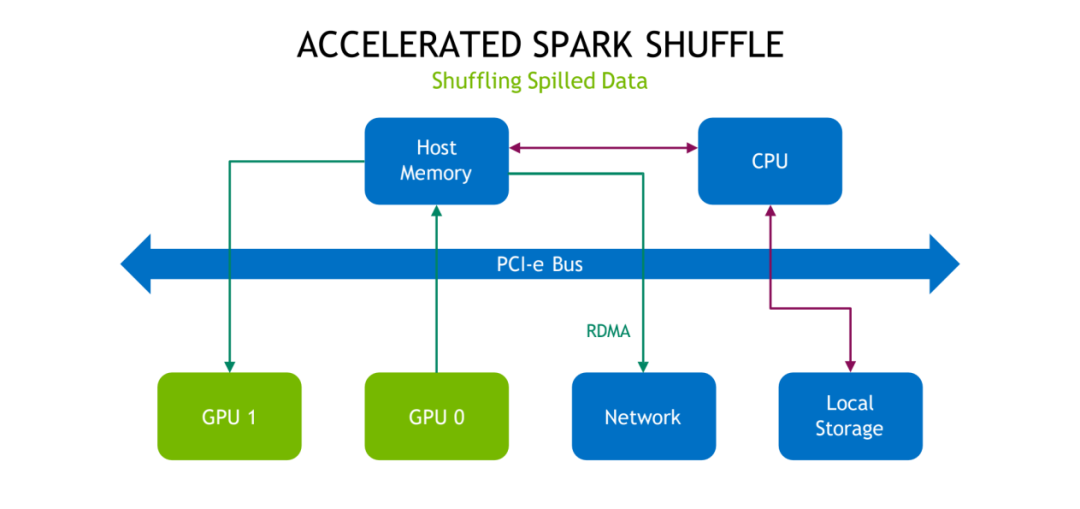
如果说 Shuffle 的时候,这时候数据规模是超出了显存容量的话,大家也都比较熟悉 Shuffle spill 机制,我们的 RAPDIS 的 Shuffle 是不是还是能有一定的优化?这个答案也肯定的。首先如果是 GPU 的 memory 超了之后,会往主存里头去写一部分,如果主存之后也写不下,其实类似于之前的 CPU 的方案,会把这个数据写到本地的存储里。但是对于储存的这部分数据来说,仍然可以通过 RDMA 获得加速。

我们底层依赖的具体依赖的技术的组件,我们是用了 UCX 这个库,它提供了一个抽象的通信接口,但是对于具体的底层的网络环境和资源,比如说是 TCP 还是 RDMA、有没有用 Shared Memory、是不是有 GPU,它都会根据具体的状况去选择一个最优的一个网络处理方案,对于用户来说是透明的,你不需要去具体的关心这些网络细节。能达到的一个效果是,如果是能利用上最新的性能最优的 RDMA 的话,我们是能达到一个零拷贝的一个 GPU 的数据的传输。RDMA 需要特定的一些硬件的一些支持。
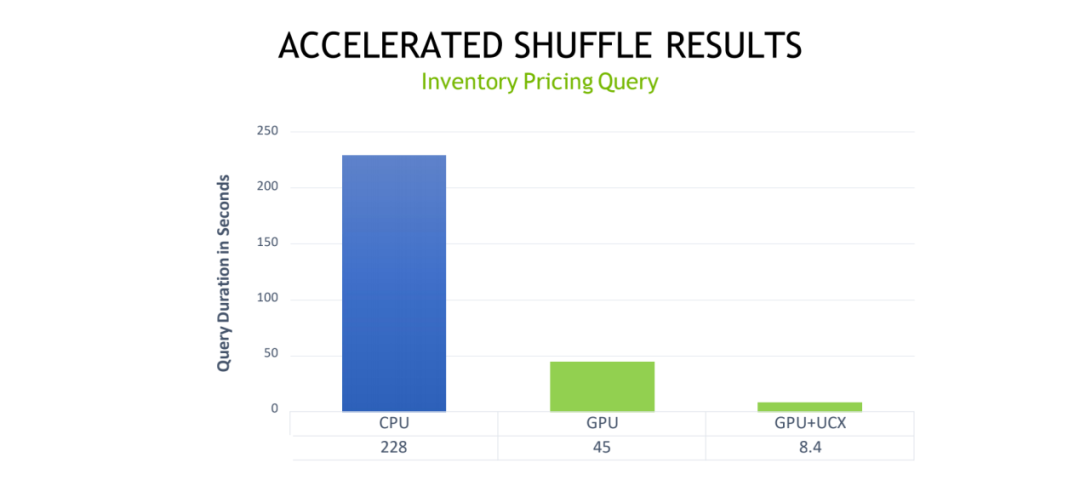
如果是采用 UCX,能用 RDMA 这种网络架构的话,能达到一个怎么样的一个性能收益?我们这边举了一个具体的库存定价 query 的例子,CPU 的执行时间不是 228 秒,相对于 GPU 它大概就能达到一个五倍的一个提升。如果在对于网络这块再做进一步的一些优化的话,其实可以看到是能缩短到 8.4 秒,整体看是有 30 倍左右的性能提升,这个提升还是非常明显。所以其实可以大家也可以看到,整个的计算流程其实主要是 bound 在网络这一块。
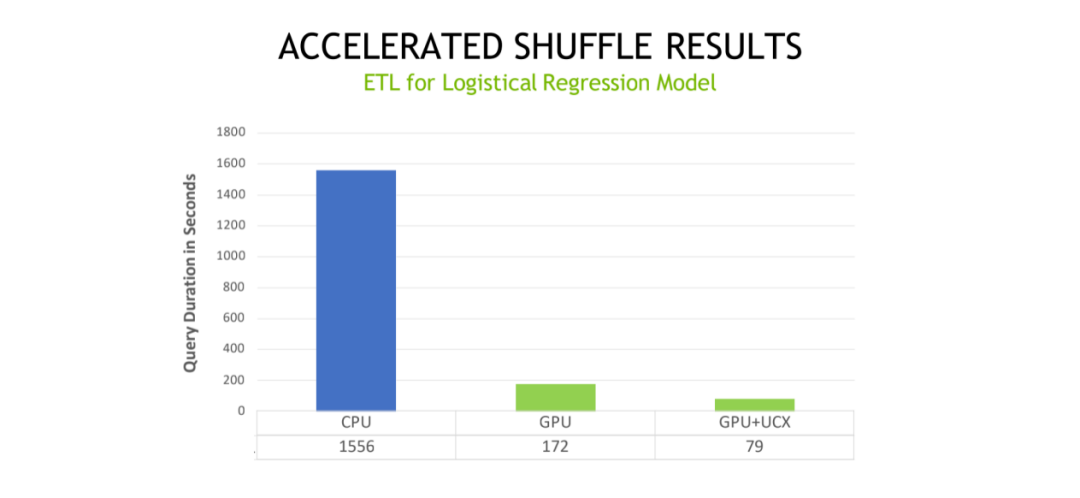
对于传统的逻辑回归模型,它的 ETL 的流程,也是能达到一个比较明显的一个收益,最原始版本是 1556 秒,最终优化的版本的话是 76 秒就可以执行完整个的 ETL 流程。
0.2 版本中的亮点

我们过一下,我们最近有 Rapids 的两个版本:0.2 版本和 0.3 版本,大概都包含哪些新的一些特性。
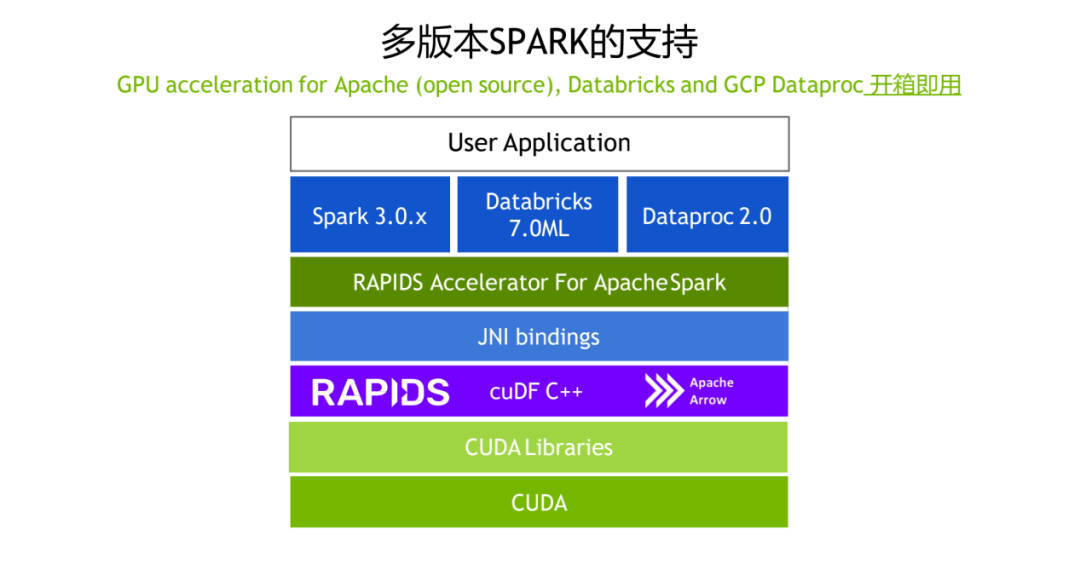
1. 多版本 SPARK 的支持
对于从 0.2 版本开始,除了对于 Apache 社区版本的支持,对于 Databricks 7.0ML 和 Google Dataproc 2.0,也都有对应的支持。
2. 读取小文件时的优化(PARQUET)
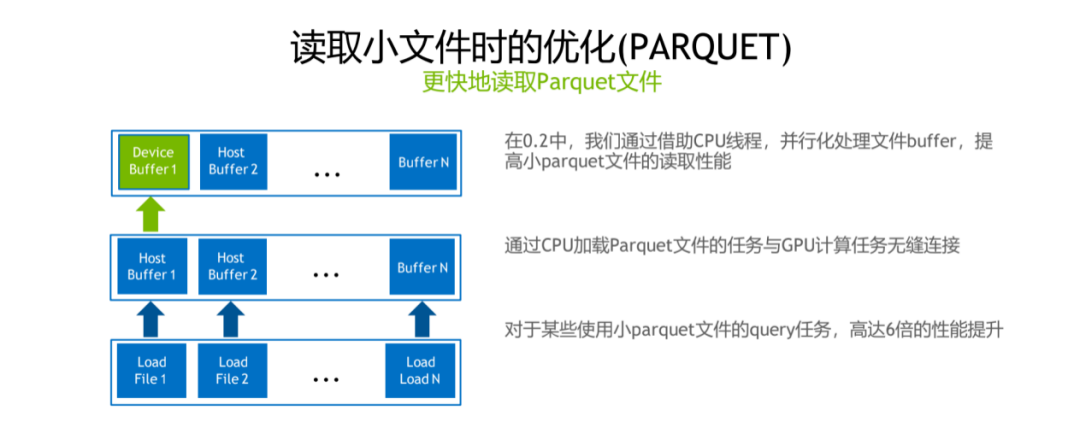
第二个 feature 是对于读取较小的 parquet 文件的时候做了一些性能的优化,简单来说可以借助 CPU 的线程去并行化处理 parquet 文件的读取,实现 CPU 任务跟 GPU 任务能够互相覆盖,GPU 在进行实际计算的时候,CPU 也会同时去 load data,能达到 6 倍的性能提升。
3. 初步支持 Scala UDF
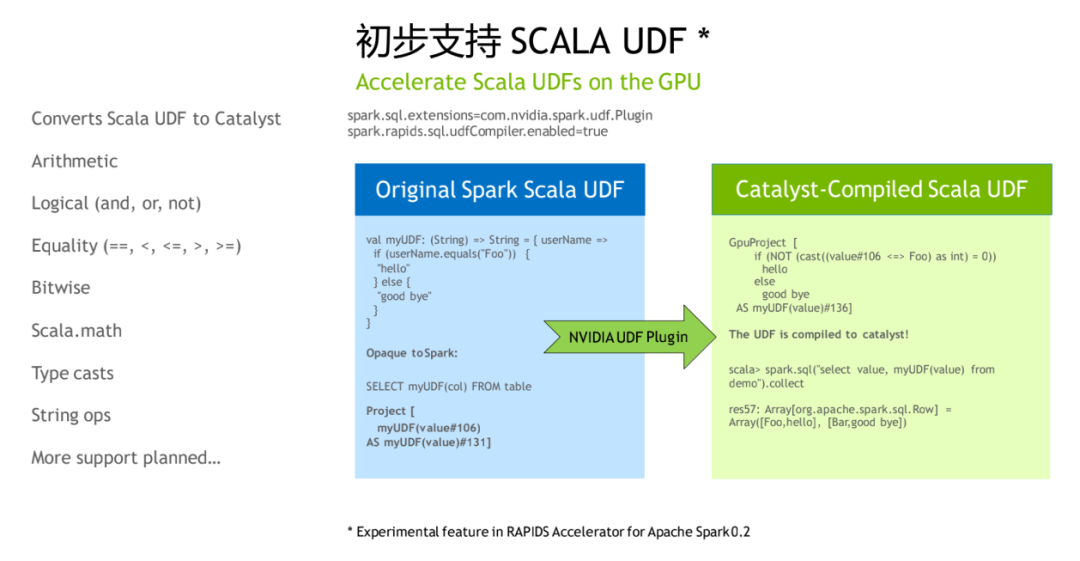
对于 Scala UDF 的话,也有了一些初步的支持,目前支持的算子不是特别多,但是也可以具体的跑一些例子可以看一下,就是说对应的实际的用到的 UDF 是不是已经可以被编译成 GPU 版本,如果是 GPU 版本的话,其实应该是能达到一个比较好的一个性能收益。
4. 加速 Pandas UDFS
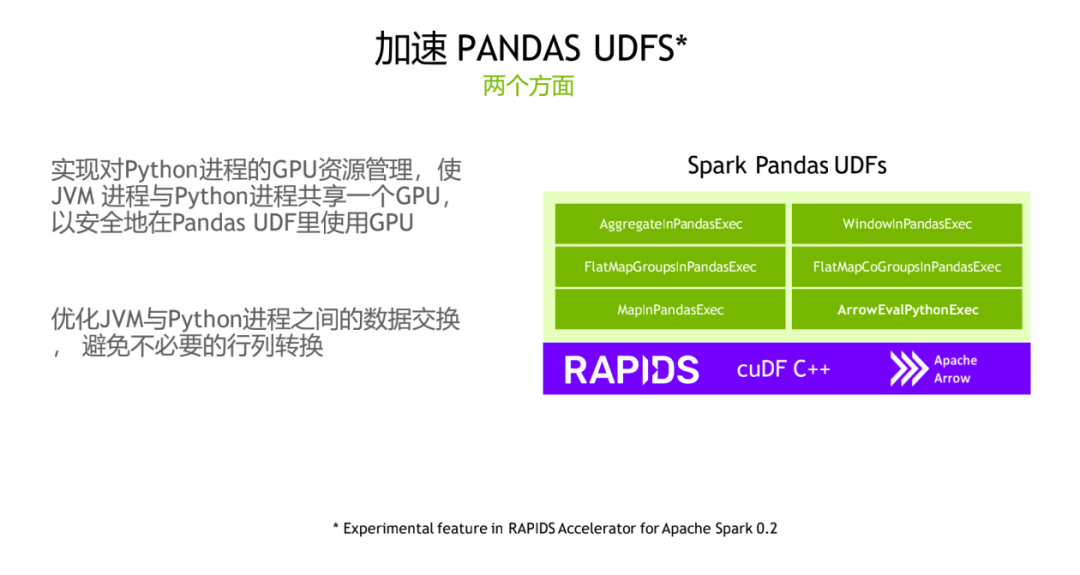
如果是 Pandas 用户的话可能会经常会用到 Pandas UDF,对于这一块来说是 RAPIDS 的加速器也做了实现,具体实现的细节其实是可以使 JVM 进程和 Python 进程共享一个 GPU,而且这样的一个好处是可以优化 JVM 进程跟 Python 进程之间的一些数据交换。

具体的实现细节可以如上图所示,目前的实现,单个 GPU 上我们可以跑一个 JVM 进程的同时,可以跑多个 Python 进程,可以配置具体的 Python 进程数,对于 Python 进程使用的 GPU 显存总量也都是可配置。
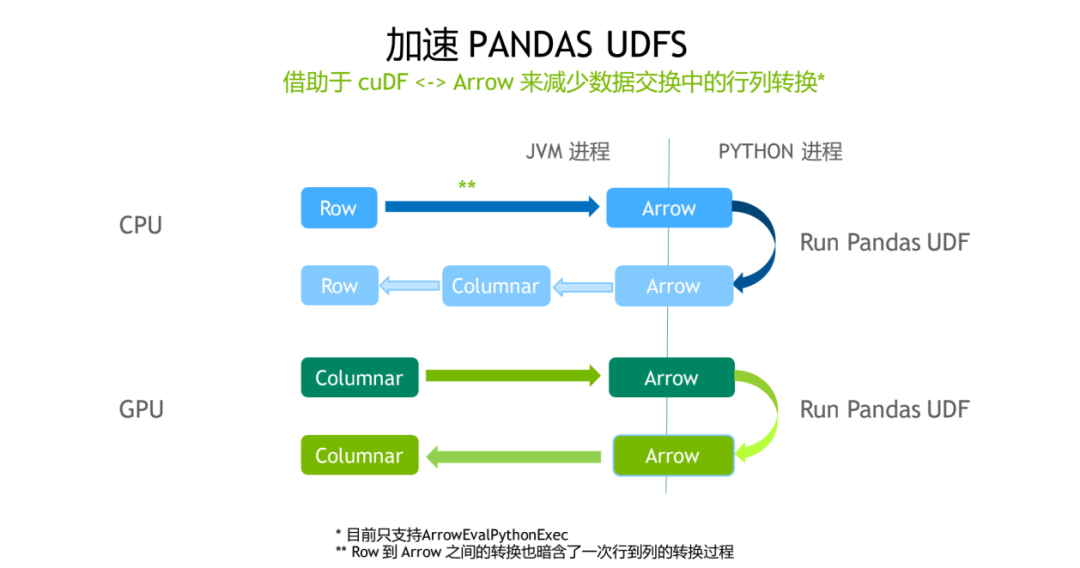
相比于传统的 CPU 方法的优化来说,GPU 版本其实是更加亲和的,因为都利用了列式存储,不牵扯到行式数据到列式数据转换的开销。在这种情况下加速收益还是比较明显。

RELEASE 0.3

实现了一个 per thread 的默认流,然后通过这种方式能够更好地提高 GPU 的利用率。对于 AQE,也有了进一步的优化,对于 3.0 版本,如果这一部分的执行是可以跑在 GPU 上的话,会自动搬到 GPU,在 GPU 上 AQE 总体达到可用状态。UCX 版本升到最新的 1.9.0。对于一些新的功能,对于 parquet 文件读取的支持,支持到 lists 和 structs,然后对于窗口操作的一些算子,新增了对 lead 和 lag 的支持。对于普通的算子,添加了 greatest 跟 least。

如果大家想要去获取 rapids accelerate for spark 的一些更多的一些信息的话,我们可以去直接通过 NVIDIA 的官网,可以直接联系到 NVIDIA 的 Spark Team,整个项目也是开源在 github 上。对于想获得 Spark Accelerator 比较新的、全面的信息的话,可以去下载 Spark 电子书,电子书目前是有中文版本。
分享嘉宾:
赵元青
NVIDIA | 深度学习架构师
赵元青 2013 年本科毕业于北京信息科技大学,曾就职于阿里大文娱优酷事业群、知乎和 OPPO。曾经在知乎负责过个性化推送算法侧和首页排序/重排序模块,在推荐系统领域有较深的钻研。目前在 NVIDIA 负责推荐系统领域的深度学习解决方案架构。
本文转载自:DataFunTalk(ID:dataFunTalk)




