

今天分享下 Pony.ai 在感知探索的过程中,使用的传统方法和深度学习方法。传统方法不代表多传统,深度学习也不代表多深度。它们都有各自的优点,也都能解决各自的问题。我们希望发挥它们的优点,并且结合起来。
本次分享的大纲:
感知 in Pony
2D 物体检测
3D 物体检测
一、感知 in Pony
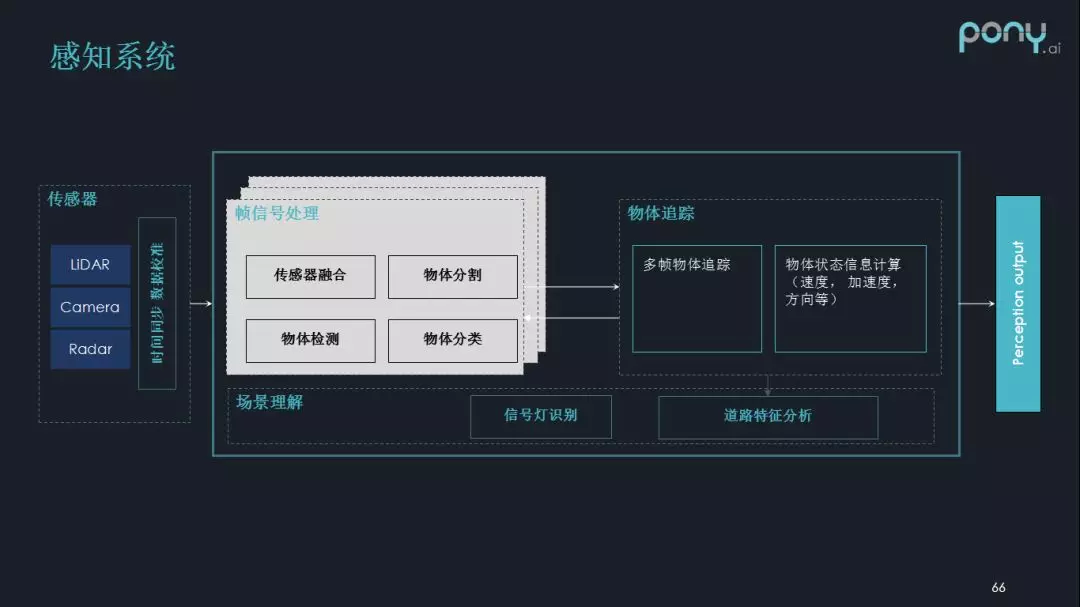
首先介绍下 Pony 感知系统。感知可以认为是对周围世界建模的过程,比如车辆在行驶过程中,需要知道物体的地理位置、速度、运动方向、加速度等各种各样的信息,接收这些信息之后,再通过后续的规划和控制模块,来对车的运动做真正的调节。
感知可以类比人类眼睛的功能,就是观察的过程:
-> 传感器:激光雷达、照相机、毫米波雷达等;
-> 帧信号处理:传感器融合、物体分割、物体检测、物体分类;
-> 物体追踪:当有多帧信息之后,可以推算速度、加速度、方向等更有意义的信息,甚至可以用多帧的信息调整分割的结果;
-> 道路特征分析:除了上述步骤,还需要对道路特征进行理解,比如交通信号灯、交通指示牌等。
感知可以认为是自动驾驶系统的基础部分,假如感知不到这个世界,就谈不上对这个世界作出反应,更谈不上后续的规划过程。
二、2D 物体检测
由于时间关系,本次分享主要介绍物体检测部分。因为必须有准确的检测和分割结果之后,才能对物体做准确的分类、追踪等等。首先介绍下 2D 物体检测:

2D 物体检测是指以 2D 信息作为 input 的物体检测过程,典型的 2D 信息是照相机。传统的 2D 信息检测方法,是使用检测框遍历图片,把对应的图片位置抠出来之后,做特征提取,用 Harris 算子检测角点信息,Canny 算子检测边缘信息等。把特征聚集在一起之后,做分类器,比如 SVM ,来判断提取的图中有没有物体,物体的类别是什么。
传统 2D 物体检测方法的缺点:
检测物体时,需要预置检测框,对不同物体需要设置不同的检测框;
我们需要的是高级的组合特征,而传统方法提取的特征维度比较低,对后续的分类会造成比较大的影响。
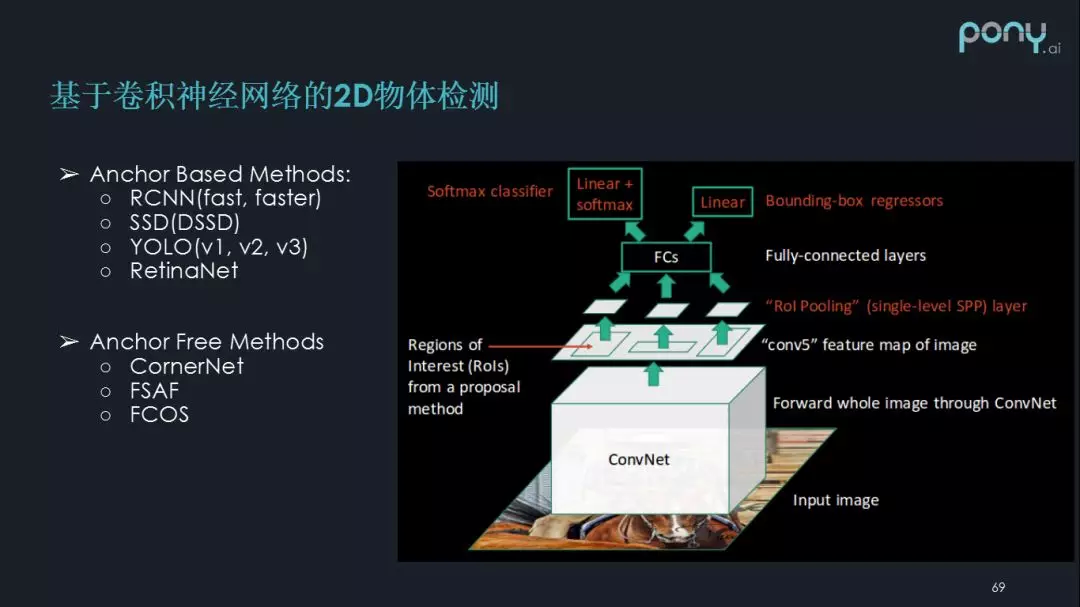
现在有了卷积神经网络,可以把传统方法上的一些问题解决掉。
卷积神经网络首先是多层感知机加卷积操作的结合,它的特征提取能力非常不错,卷积神经网络经常会有几十上百的卷积,这样就具备高维特征提取能力。其次,现在可以通过 roi pooling 和 rpn ,使整张图共享同样的特征,不用遍历整张图片,这样可以在单次操作中对图片中所有物体进行检测,这样真正具备了把物体检测模型应用到实际场景中的性能。
目前基于卷积神经网络的 2D 物体检测有俩个分支:
Anchor Based Methods:跟传统方法比较类似,先预置检测框,检测过程是对预设框的拟合过程。
RCNN(fast,faster)
SSD(DSSD)
YOLO(v1,v2,v3)
RetinaNET
Anchor Free Methods:直接对特征金字塔的每个位置,直接回归对应位置上,存不存在物体,它的大小是多少,这个方法是去年年底开始大量出现的,也是未来的一个发展方向。
CornerNet
FSAF
FCOS

这是 Pony 路测场景中的一个真实检测案例,2D 物体检测已经应用到检测一些小物体。
同时远距离物体检测也是我们在 2D 物体检测中比较关注的点,远距离物体受限于激光雷达和毫米波雷达的物理特征,缺乏良好的检测效果,而照相机在这方面比较有优势,可以和其他的检测方法进行互补。

但是用照相机做 2D 物体检测也面临一些问题。因为只有俩个维度,当俩个物体堆叠起来的时候,对一个网络来讲它的特征就比较聚集。所以,一般做物体检测的过程,会用一些非极大值抑制的方法,对检测结果进行后处理,当结果非常密集的时候,这种方法往往会受到影响。

因为照相机是可见光设备,会受到光照强度的影响,并且希望特征不管是在图中的那个位置,都有足够的表达。再一个,远处的车灯和路灯也很难区分开,可能会都检测成车或者路灯。在这种情况下,特征难以区分。
再一个很大的问题就是测距问题,因为照相机是被动光源的设备,不具备主动测距的能力,这样的话需要做很多的假设,或者求解一些变态的数学问题,去估算它的距离,这个结果通常是不如主动测距设备的,比如激光雷达和毫米波雷达。
三、3D 物体检测
正是因为照相机的这些问题,所以我们也采用了其他的传感器,来做物体检测,然后把它们的结果结合起来,达到更可靠的检测效果。

3D 物体检测,顾名思义就是把 3D 的一些数据坐标,聚集起来做物体检测,比如激光雷达,类似于我们拿一个激光笔不断的扫描周围,它是一个比较明显的信息。当把数据聚集起来之后,用来推测物体的位置,大小,朝向等等。

3D 物体检测一个很大的好处就是我们在 2D 物体检测中很难区分的物体,在有了距离信息之后,就可以在聚集的维度上分开,这样在做分割的时候就有更多的信息使用,达到一个更好的工作效率。
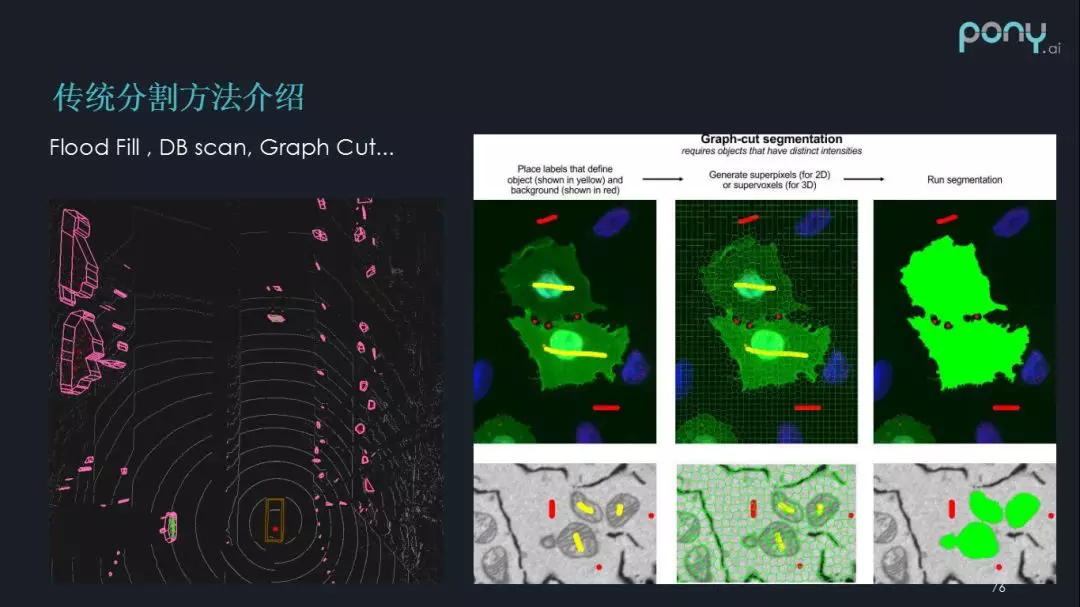
传统的 3D 分割方法:
Flood Fill
DB scan
Graph Cut
主要是利用一些点的距离信息、密度信息或者点的一些天然属性,比如它的强度,把物体聚类分割。

传统分割方法的限制:
过度分割:比如图中的车,车尾和车头之间有缝隙,就很容易在 3D 检测中被分割成多个物体,因为点和点之间有间隙,在激光雷达检测时呈现的是离散信息,就会出现过度分割。

分割不足:这个是 Pony 感知在早期出现的一个问题,我们称之为“三人成车”,就是当三个人离的很近的时候,很容易被系统识别成一辆车。
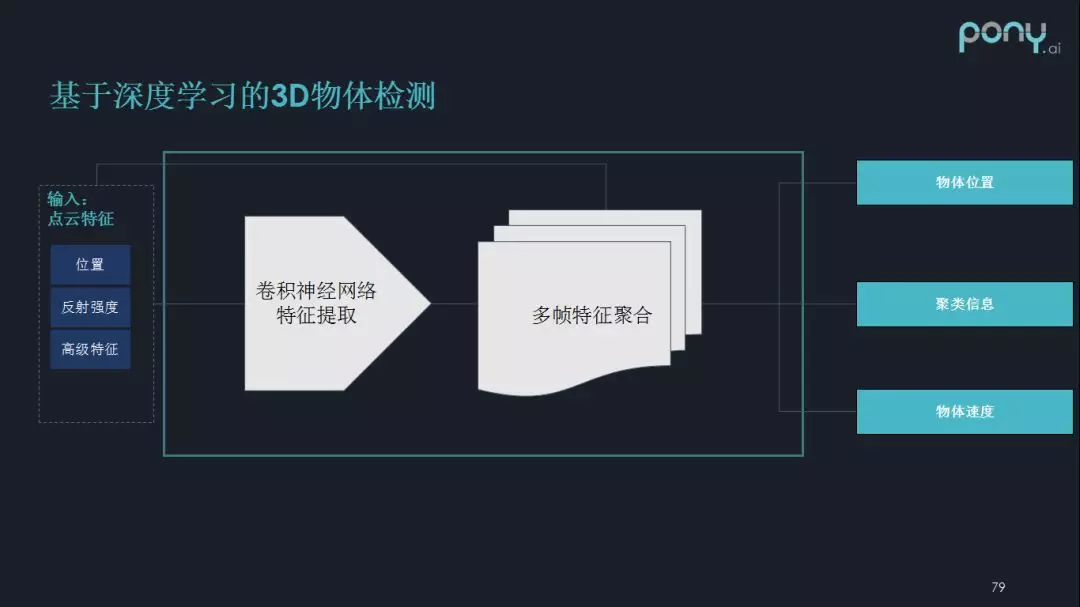
为了解决这些问题,就把一些深度学习跟卷积神经网络引入到 3D 物体检测中来。把点云信息进行特种工程,比如把点的位置、反射强度、高级特征聚合在一起,组织成类似图片或者图的关系,然后进行卷积神经网络特征提取,再进行多帧特征的聚合(它的意义是对运动的物体有一个更好的反映),最后得到物体的位置、聚类信息、物体速度。

通过上述方法,“三人成车”的情况一定程度上就会避免,用户不仅可以提取人的距离关系,还可以提取到更多的高级信息,比如在点云变化中,人类似长的柱体,而自行车类似于小山一样的点云分布,这样我们可以了解他们不应该属于同一物体,而割离开。
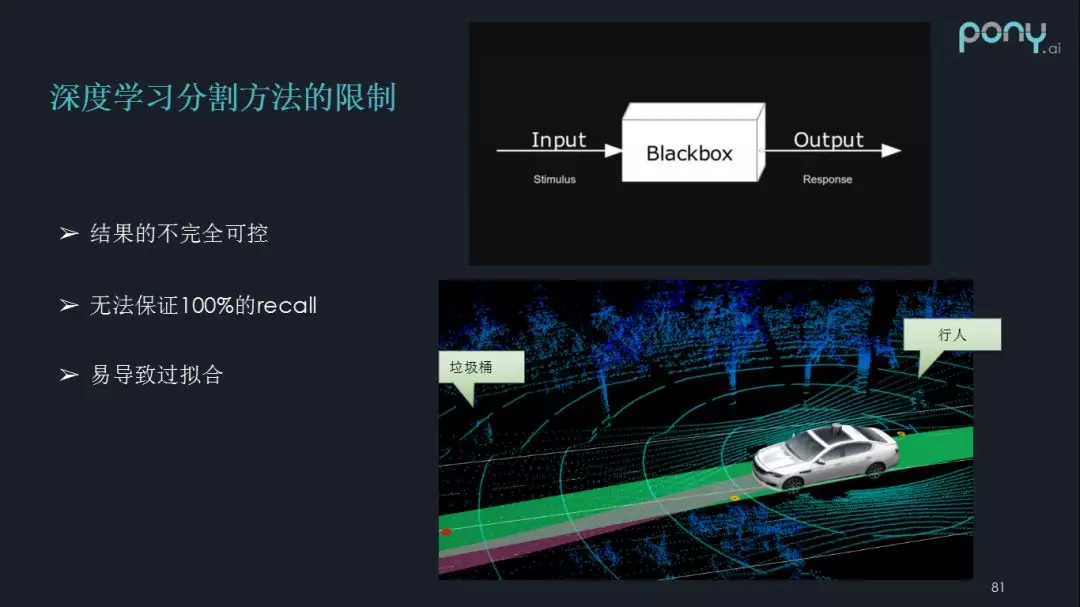
深度学习分割方法的限制:
结果的不完全可控:首先卷积神经网络经常有几百层的卷积层,参数总量可能有百万级,并且是自动学习的,导致对网络的输出没有很好的把控,就是我们无法预期 input 数据输入之后会得到怎样的数据,这在自动驾驶领域是比较致命的,因为自动驾驶是对召回率和精度有非常高要求的场景,比如车辆在行驶中,前面的一个人被 miss 掉,可能就是件严重的事件。
无法保证 100%的 recall:如图所示,垃圾桶和人的特征其实非常相似,可能就把人学成了垃圾桶,导致行人在系统中出现 miss 情况。
易导致过拟合:由于卷积神经网络有非常好的特征提取能力,可能在固定的数据集上导致网络过拟合,比如同样的数据集训练后,在北京的表现很好,但是当你到一个新的城市测试的时候,因为路面特征和北京有所区别,就可能导致在新的城市的效果,不如北京,这样的话对系统就非常不友好。

为了解决这些问题,我们的一个想法就把传统方法和深度学习方法的结果进行一定的结合。
使用深度学习的分割结果调整传统分割方法的结果;
使用传统分割方法的结果补足深度学习结果的召回;
基于多帧追踪的概率模型融合:比如利用马尔可夫分布的特点、贝叶斯的方法对多帧数据进行一定的平滑,得到更好的效果。
- 3.0x
- 2.5x
- 2.0x
- 1.5x
- 1.25x
- 1.0x
- 0.75x
- 0.5x
最后,和大家分享下 Pony 在真实场景中分割的一些表现,以及可能会出现的一些问题,视频中是 Pony 非常普通的一次路测。大家可以看到在 2D 上出现了大量的物体堆叠的情况,其实 3D 上也会存在一定的遮挡,但是好在有距离信息,可以有效的分割,但是对于远距离物体还是会存在一些问题。大家可以看到,我们的感知系统还是有很多改进空间的。
做自动驾驶真的是一个很崎岖的旅程,不断的解决问题之后又出现新的问题,不过正是因为过程的艰难,才带来更多的快乐。
感谢大家,今天的分享就到这里。
作者介绍:
黄凯宁,Pony.ai 资深研发工程师。CMU 机器人学硕士,目前负责 Pony.ai 自动驾驶 CV 方向核心研发工作,参与实现基于深度学习的物体分割和检测。曾就职于腾讯 AI lab,任计算机视觉领域 AI 研究员,深度参与“绝艺”项目。
本文来自 DataFun 社区
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论