
DeepSeek 引爆大模型在千行百业落地的背景下,存储与计算的协同优化正成为企业提升 AI 推理效率、降低运营成本的关键。KVCache 技术通过“以存换算”的创新模式,显著提升了推理性能,成为企业构建大模型基础设施的必要选择。此前,焱融科技率先推出 YRCloudFile 分布式文件系统的 KVCache 特性,支持 PB 级缓存扩展,大幅提高 KV 缓存命中率与长上下文处理能力,为大模型推理提供更优性价比技术方案。
在本篇文章中,焱融存储技术团队基于公开数据集和业界公认的测试工具,基于 NVIDIA GPU 硬件平台模拟真实的推理业务场景,进一步探索并发布 KVCache 在推理场景中的详细性能优化数据。测试结果显示,在相同规模和推理延迟 TTFT(Time-To-First-Token) 下,YRCloudFile KVCache 可支持更高并发查询请求,为用户提供更贴近实际使用场景的性能验证与优化方案。这些数据不仅验证了 KVCache 技术的有效性,并揭示了高性能 KVCache 给推理业务带来的可量化的价值。
实测 YRCloudFile KVCache 在推理场景中的性能优化数据
为了验证将 GPU 内存扩展至 YRCloudFile KVCache 对 token 处理效率的显著提升效果,并充分展示焱融 AI 存储架构的卓越性能,我们进行了多轮测试。通过针对不同 token 数量和配置的测试,深入探索该架构在实际应用中的优化潜力。以下测试均是基于原生 vLLM,以及 vLLM+YRCloudFile KVCache 进行的数据对比。
测试一:长上下文提问下,推理 TTFT 的对比数据
• 背景:输入长上下文,对比单次提问的回答总耗时(指超过 20K 长度的 token)
• 显卡:NVIDIA T4
• 模型:Qwen/Qwen2.5-7B-Instruct-GPTQ-Int4
• 测试方法:基于同样的上下文,使用相同的问题,通过 QA chatbot 上进行提问模拟
• 测试结论:在长上下文场景中,使用 YRCloudFile KVCache 可实现高达 13 倍的 TTFT 性能提升。这一显著优化得益于其高效缓存命中率和对大规模数据的快速处理能力,为大模型推理提供了更优的性能支持。
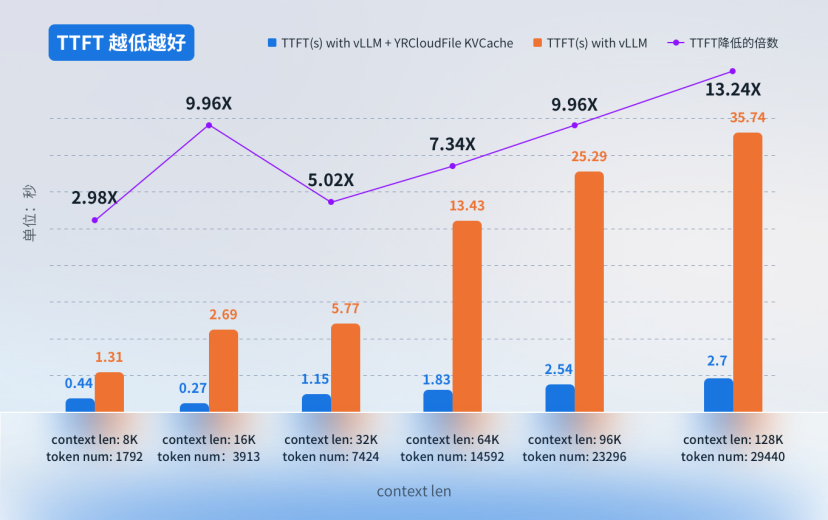
用户普遍能接受的 TTFT 在 2 秒以内。基于这一背景,我们设计了测试二,以验证系统在长上下文场景下的性能表现。
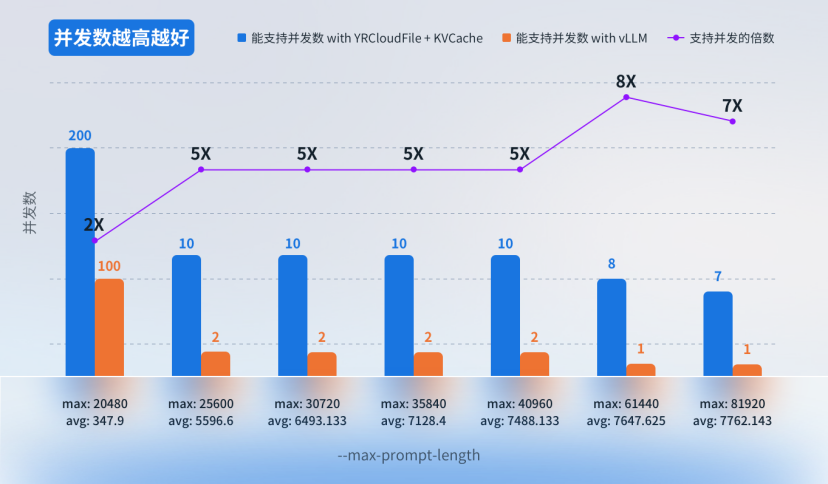
测试二:使用不同上下文长度,在 TTFT ≤ 2 秒时,相同 GPU 能支撑的并发数对比数据。
• 背景:在相同显卡配置与 2 秒 TTFT 延迟约束条件下,通过对比原生 vLLM 与集成 YRCloudFile KVCache 的解决方案在不同上下文长度(--max-prompt-length 参数)下的并发支持能力,验证存储扩展对并发推理请求的提升效果。
• 显卡:NVIDIA L20
• 模型:Qwen/Qwen2.5-7B-Instruct-GPTQ-Int4
• 测试工具:使用 evalscope 测试工具,--dataset 参数为 longalpaca,以及指定不同--max-prompt-length 参数值,进行测试。
• 测试结论:在相同 GPU 配置下,当 TTFT ≤ 2 秒时,YRCloudFile KVCache 可承载的并发数可提升 8 倍。这意味着,在相同数量的 GPU 配置下,系统能够满足更高并发请求的需求,显著优化了推理性能和资源利用率。
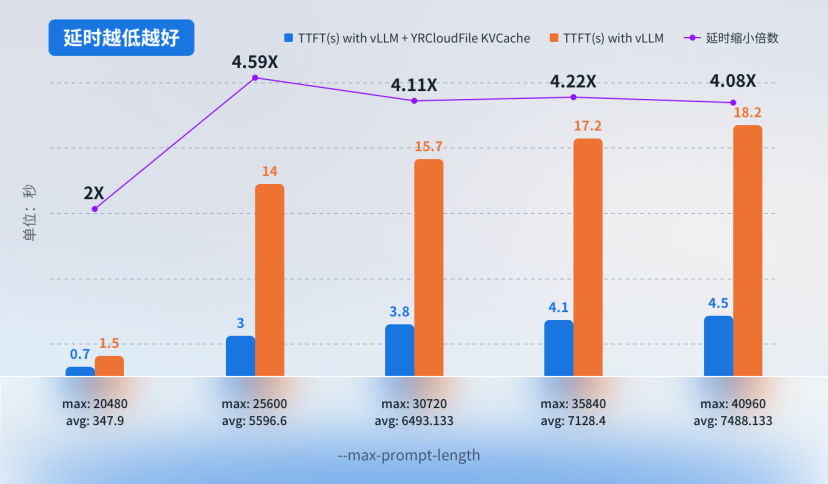
测试三:在相同 GPU 配置和较高并发数下,使用不同上下文长度的 TTFT 性能对比数据。
• 背景:在相同显卡配置下,通过设置不同的上下文长度(--max-prompt-length 参数),在并发数为 30 情况下,使用原生 vLLM,以及 vLLM+YRCloudFile KVCache 进行的数据对比。
• 显卡:NVIDIA L20
• 模型:Qwen/Qwen2.5-7B-Instruct-GPTQ-Int4
• 测试工具:evalscope,--dataset 使用 longalpaca,指定不同--max-prompt-length,并发为 30 的情况下,进行测试。
• 测试结论:在较高并发数下,对于不同的上下文长度,YRCloudFile KVCache 所提供的 TTFT 延迟可缩小 4 倍以上;这表明 YRCloudFile KVCache 在高并发场景下,能够有效优化推理性能,显著减少延迟,提升用户体验。
本次测试通过多维度验证表明,YRCloudFile KVCache 在长上下文处理与高并发场景中展现出显著性能优势:在 TTFT≤2 秒的严苛约束下,其支持的并发数提升达 8 倍,且在高并发负载中延迟可降低 4 倍以上。这一成果不仅印证了“存储-计算协同优化”对 AI 推理效率的核心价值,更揭示了通过分布式存储架构扩展显存资源的技术路径,能够有效突破传统 GPU 算力瓶颈,实现资源利用率的指数级提升。
当前,随着 DeepSeek 等大模型在千行百业的规模化落地,企业对推理效率与成本优化的需求愈发迫切。YRCloudFile KVCache 通过 PB 级缓存扩展能力,将存储资源转化为计算性能增益,为行业提供了兼顾高性能与低成本的实践范例。这种以存储架构创新驱动算力释放的模式,或将成为企业构建下一代 AI 基础设施的关键突破点,加速大模型从技术突破到商业闭环的演进进程。




