

今天,在 Spark+AI 峰会首日主题演讲中,Databricks 带来了一系列重磅发布:推出用于实现高性能查询的 Delta Engine 原生执行引擎;收购数据可视化开源项目 Redash 背后的公司;发布 Koalas 1.0 等。这些动作无一不标志着 Databricks 正在朝着统一数据分析平台的目标大步迈进。为了帮助读者快速获取重要信息,InfoQ 将今日主题演讲中的亮点汇总整理如下:
终极愿景:Data Lakehouse
数据仓库在决策支持和商业智能应用方面拥有悠久的历史。但数据仓库并不适用于处理现代企业中常见的非结构化、半结构化和流式数据。因此很多企业在约十年前就开始构建存储原始数据的数据湖。数据湖虽然适用于存储数据,但缺少一些关键功能:不支持事务,不强调数据质量,并且缺乏一致性/隔离性,导致其几乎不可能混合处理追加和读取、以及批处理和流式作业。由于这些原因,数据湖的许多承诺尚未实现,并且在很多情况下失去了数据仓库的许多好处。Databricks 过去几年在许多客户案例和使用场景中看到了一种新的数据管理范式:lakehouse。
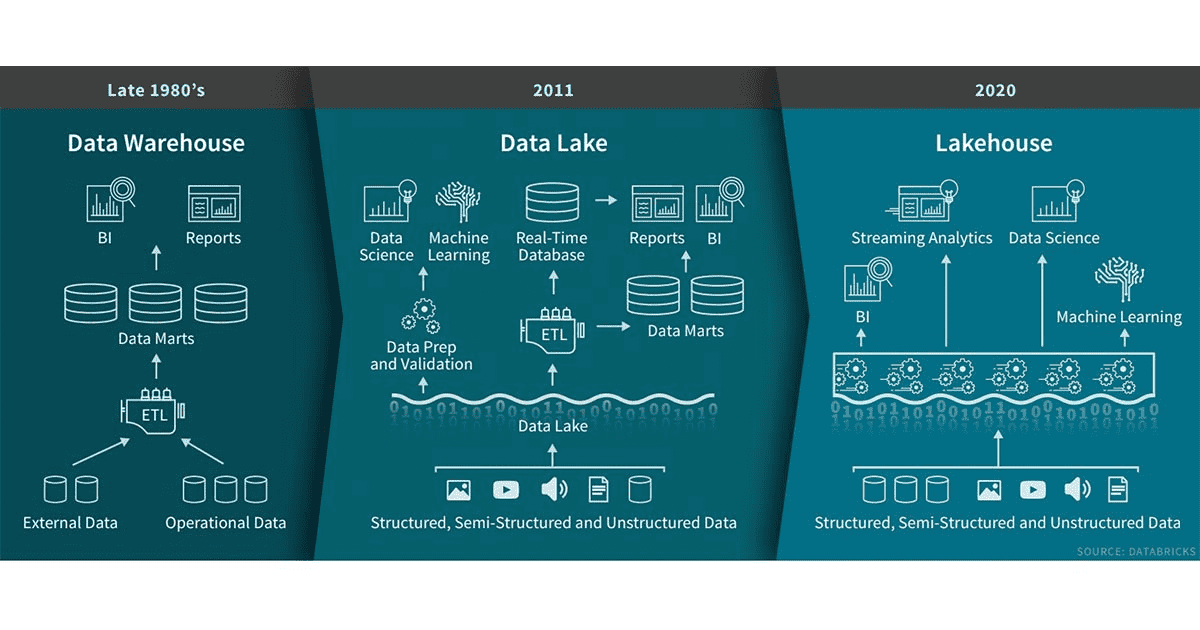
数据存储的发展,从数据仓库到数据湖再到 Lakehouse
Lakehouse是一种新的数据管理范式,它结合了数据湖和数据仓库的最佳元素:直接在用于数据湖的低成本存储上实现与数据仓库类似的数据结构和数据管理功能。
Data Lakehouse 需要具备以下关键特征:
支持事务:在企业内部 lakehouse,通常会有许多数据管道同时读取和写入数据,支持 ACID 事务可以确保一致性。
模式执行和治理(schema enforcement and governance):Lakehouse 应该支持模式执行和演进,支持 DW schema 范式(例如 star/snowflake-schemas),能够推理数据完整性,并且应该具有健壮的治理和审计机制。
支持 BI:Lakehouses 可以直接在源数据上使用 BI 工具。这样可以减少数据过时(staleness)并提高新近性(recency),减少延迟,并降低必须在数据湖和数据仓库中操作两个数据副本的成本。
存储计算分离:实际上,这意味着存储和计算使用单独的集群,因此系统能够扩展到更多并发用户和更大的数据量。有一些现代数据仓库也具备这一属性。
开放性:使用开放和标准化的存储格式,如 Parquet,并提供 API,这样各种工具和引擎(包括机器学习库和 Python/R 库)都可以直接高效地访问数据。
支持从非结构化数据到结构化数据的多种数据类型:Lakehouse 可用于存储、优化、分析和访问许多新数据应用所需的不同数据类型,包括图像、视频、音频、半结构化数据和文本。
支持各类工作负载:包括数据科学、机器学习以及 SQL 和分析。要支持所有这些工作负载可能需要多种工具,但它们都基于同一个数据存储库。
端到端流:实时报告是许多企业的标准需求。支持端到端流,企业就不需要单独再开发一个专门用于服务实时数据应用的系统。
以上是 lakehouse 的关键属性,当然,企业级系统还需要更多功能,比如安全和访问控制工具、数据发现工具等。
目前业界已有一些 Data Lakehouse 数据管理范式的早期案例:Databricks平台具备 lakehouse 的架构特性;微软的 Azure Synapse Analytics 服务与 Azure Databricks 集成在一起,也可以实现类似 lakehouse 的模式;其他托管服务(例如 BigQuery 和 Redshift Spectrum)也具备上面列出的部分 lakehouse 功能,但它们主要针对 BI 和其他 SQL 应用;还有一些公司正在通过开源表格式(如Delta Lake、Apache Iceberg、Apache Hudi)构建自己的 lakehouse。
今天在 Spark+AI 峰会上发布原生执行引擎 Delta Engine 和收购数据可视化开源项目 Redash 背后的公司,都可以视作 Databricks 为实现 Data Lakehouse 数据管理范式采取的行动。
Delta Engine:实现高性能查询的原生执行引擎
Delta Engine是为了实现高性能查询而打造的原生执行引擎,该引擎由三个部分组成,包括:100%与 Apache Spark 兼容的矢量化查询引擎,以充分发挥现代 CPU 架构的性能;基于 Spark 3.0 查询优化器的进一步优化;以及作为 Databricks Runtime 7.0 的一部分推出的缓存功能。这些功能特性结合在一起将显著提高数据湖(尤其是由Delta Lake支持的数据湖)上的查询性能,从而使用户可以更轻松地采用和扩展lakehouse架构。
过去几年的主要硬件趋势之一是 CPU 时钟速度已趋于平稳。我们必须找到新的方法来以超出原始计算能力的速度更快地处理数据。最有效的方法之一是提高可以并行处理的数据量。但是,数据处理引擎需要经过专门设计才能有效利用这种并行性。
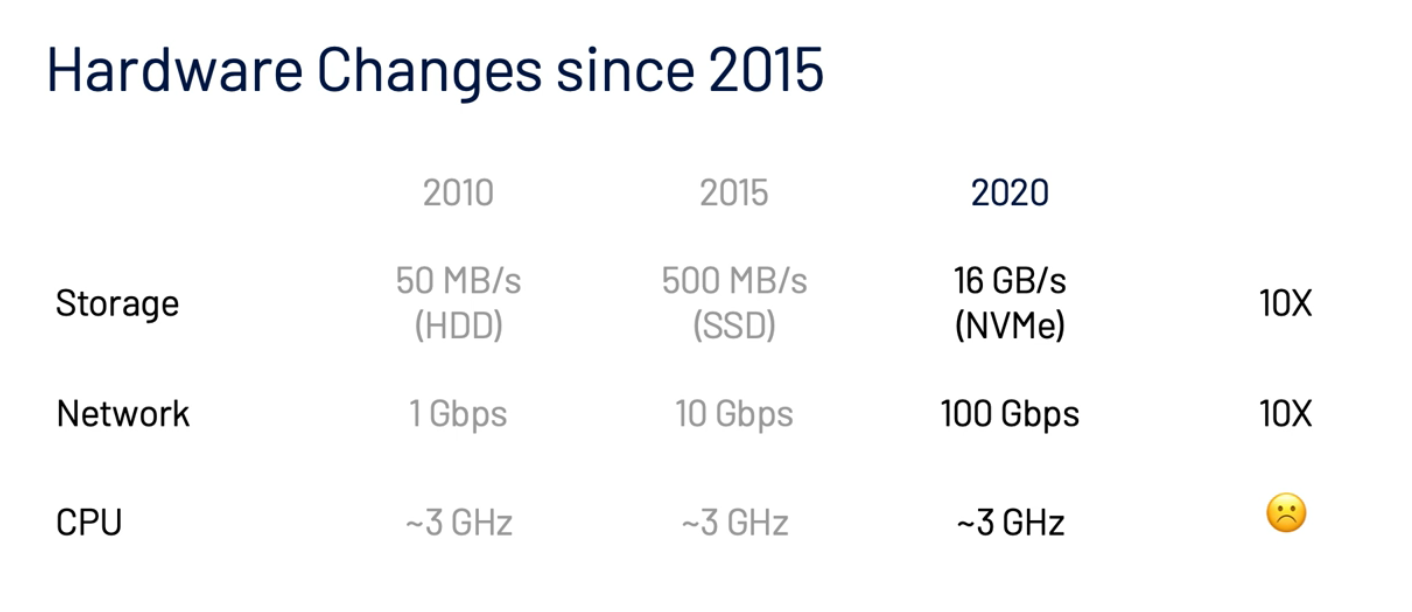
此外,随着业务发展日益加快,数据团队可以用于数据建模的时间越来越少。如果为了更好的业务敏捷性而牺牲建模质量,就会导致查询性能变差。Databricks 希望能找到同时让敏捷性和性能最大化的方法,Delta Engine 由此而生。
Delta Engine 通过三个组件来提高 Delta Lake 的 SQL 和数据帧工作负载的性能:改进的查询优化器,位于执行层和云对象存储之间的缓存层,以及使用 C ++编写的原生矢量执行引擎(Native Execution Engine)。
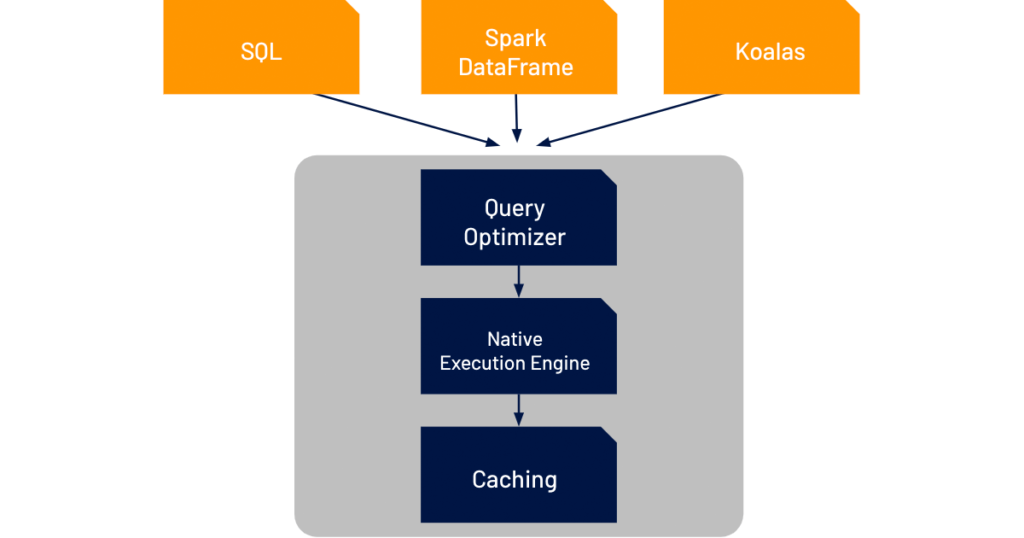
Delta Engine 通过多个组件为所有数据工作负载带来更高的性能
改进的查询优化器对 Spark 3.0 中已有的功能(基于成本的优化器,自适应查询执行和动态运行时过滤器)做了更多扩展,能够将星型架构的工作负载性能提高最多 18 倍。
Delta Engine 的缓存层会为用户自动选择要缓存的输入数据,并以更高效的 CPU 格式对代码进行转码,以更好地利用不断提高的 NVMe SSD 存储速度。基于这一点,几乎所有工作负载的扫描性能都能得到提升,最高可加快 5 倍。
不过,Delta Engine 解决当今数据团队所面临挑战的最大创新是中间的原生执行引擎,Databricks 内部称之为 Photon。这个执行引擎针对 Databricks 进行了彻底的重写,旨在充分利用现代云计算硬件的新变化使性能最大化。它能够改进所有工作负载类型的性能,同时仍与开放的 Spark API 完全兼容。
Databricks 表示接下来会另写一篇文章对 Photon 的工作原理和具体性能表现做具体介绍,InfoQ 届时会第一时间带来中文版本,敬请期待。
收购 Redash:增强数据可视化功能
在今天早上的 Spark+AI 峰会上,Databricks 宣布收购Redash,后者是流行的同名开源项目背后的公司。通过此次收购,Redash 将与 Apache Spark、Delta Lake 和 MLflow 共同构成一个更大、更繁荣的开源系统,为数据团队提供一流的工具。目前 Redash 仅在私有预览版本中可用,未来 Redash 将完全集成到 Databricks 平台中,以打造更丰富的可视化和仪表板体验。

Redash 是一个协作式的可视化和仪表板平台,目标是使所有人(无论他们的技术水平如何)都可以在团队内部和团队之间共享见解。SQL 用户利用 Redash 来探索、查询、可视化和共享来自任何数据源的数据。而他们的工作反过来又使他们所在公司中的所有人都可以使用数据。目前,全球成千上万个组织中的数百万用户都在使用 Redash 开发见解并制定数据驱动的决策。
Redash 包括以下功能:
查询编辑器:通过 schema 浏览器和自动完成功能快速整合 SQL 和 NoSQL 查询。
可视化和仪表板:可以通过简单的拖拽创建漂亮的可视化效果,并将它们组合成一个仪表板。
共享:通过共享可视化及相关查询,可以轻松地进行协作,进而对报告和查询进行同行审查。
定期刷新:可以根据用户配置的间隔时间定期自动更新图表和仪表盘。
告警:支持自定义条件并在数据更改时立即收到告警通知。
REST API:所有可以使用 UI 进行的操作都可以通过 REST API 使用。
广泛支持各类数据源:数据源 API 可扩展,原生支持众多常见的 SQL、NoSQL 数据库和平台。
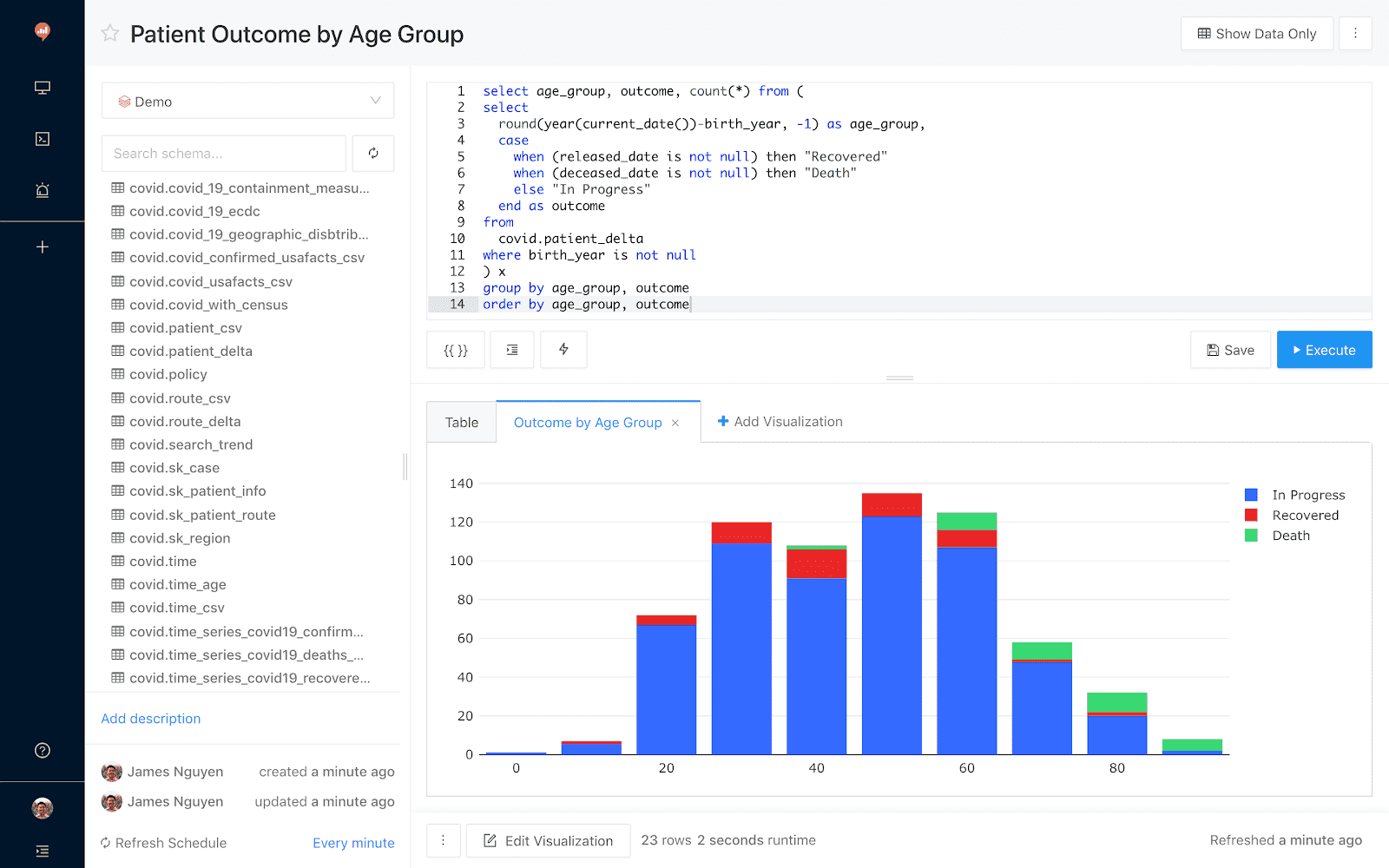
使用 Redash 快速将结果转换为可视化效果
Databricks 表示,集成后的 Redash 服务将帮助 SQL 分析师、数据科学家和数据工程师更轻松地查询和可视化 Delta Lakes 和其他数据源中的数据。Redash 将与现有的 Databricks 平台无缝集成:Databricks 运营的所有数据中心都会提供该服务;统一的身份管理和数据治理,无需额外配置;SQL 端点将在 Redash 中自动填充;两款产品共享目录和元数据。
Databricks 强调,Redash 的加入旨在帮助公司更好地实现为所有数据团队创建一个开放统一的数据分析平台的愿景。Databricks 希望通过这样一个平台为每个团队提供各自工作所需的工具和一个可以协作的共享平台,让所有数据团队共同实现成功。通过将数据湖和数据仓库的最佳功能结合在一个统一的架构中,每个团队可以在同一个完整且权威的数据源上共同工作,这将帮助 Databricks 实现 lakehouse 数据管理范式的终极目标。
Koalas 1.0 发布
经过一年多的开发,Koalas 1.0 版本正式发布,新版本实现了将近 80%的 pandas API,同时支持Apache Spark 3.0、Python 3.8、Spark 访问器、新的类型提示和更好的就地(in-place)操作。目前 Koalas 在 PyPI 上的月下载量已迅速增长到 85 万,并以每两周发布一次的节奏快速演进。
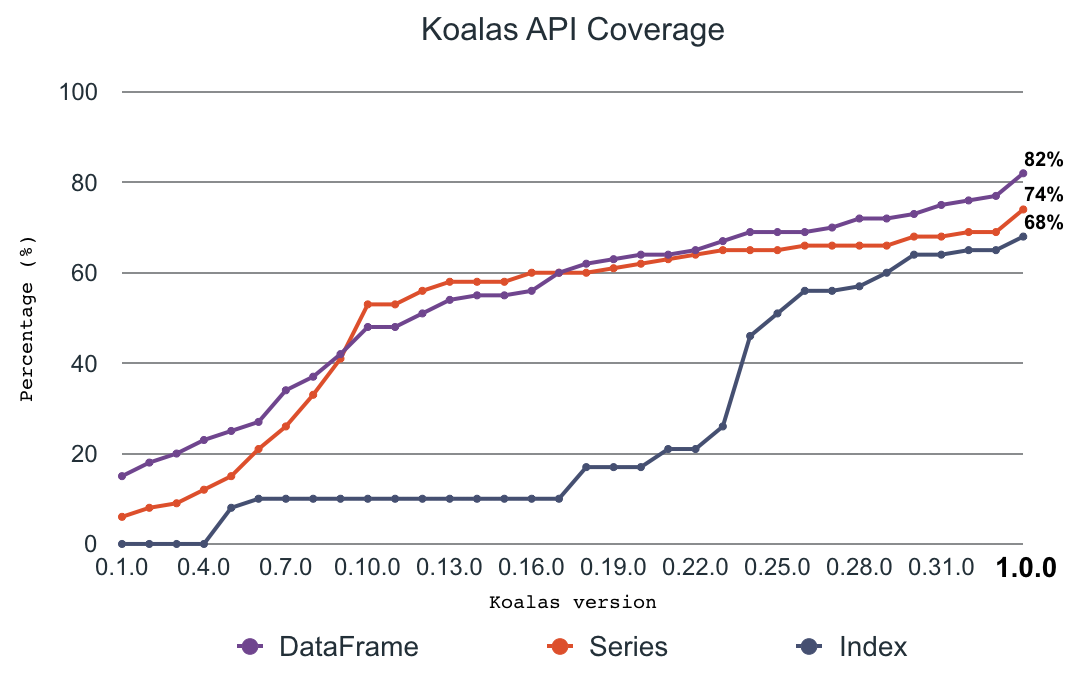
以下是 1.0 版本重要新特性的概览,详细介绍可以点此查看。
更好的 pandas API 覆盖率
Koalas 实现了几乎所有被广泛使用的 pandas API 和功能,如 plotting、grouping、windowing、I/O 和转换。
另外,诸如 transform_batch 和 apply_batch 之类的 Koalas API 可以最大化利用 pandas API,因此在 Koalas 1.0.0 中只需要做非常少的更改就可以做到使几乎所有 pandas 工作负载转换为 Koalas 工作负载。
支持 Apache Spark 3.0、Python 3.8 和 pandas 1.0
Koalas 1.0.0 支持 Apache Spark 3.0,Koalas 用户可以几乎零更改地切换其 Spark 版本。 Apache Spark 3.0 版本包含了 3400 多个修复补丁,而 Koalas 许多组件共享了这些修复,详情参阅Apache Spark 3.0重要特性解读。
基于 Apache Spark 3.0,Koalas 支持最新的 Python 3.8 版本。Koalas 开放了许多类似于 pandas 的 API,以便在 DataFrame 上执行原生 Python 代码,这将从 Python 3.8 支持中受益。另外,Koalas 充分利用了 Python 中大量开发的 Python 类型提示。Koalas 中的某些类型提示功能可能只在较新的 Python 版本才允许使用。
Koalas 1.0.0 的目标之一是跟进最新的 pandas 版本,并涵盖 pandas 1.0 中的大多数 API。除了与 API 更改和弃用保持同步之外,Koalas 还对 API 的覆盖范围进行了衡量和改进。另外,Koalas 也支持将最新的 pandas 版本作为 Koalas 的依赖项,因此使用最新 pandas 版本的用户可以轻松尝试 Koalas。
Spark 访问器(accessor)
Koalas 1.0.0 引入了 Spark 访问器,以使 Koalas 用户可以更轻松地利用现有的 PySpark API。
更快的性能
许多 Koalas API 依赖于 pandas UDF。Apache Spark 3.0 引入了新的 pandas UDF,Koalas 内部通过它们来提高性能,例如 DataFrame.apply(func)和 DataFrame.apply_batch(func)。
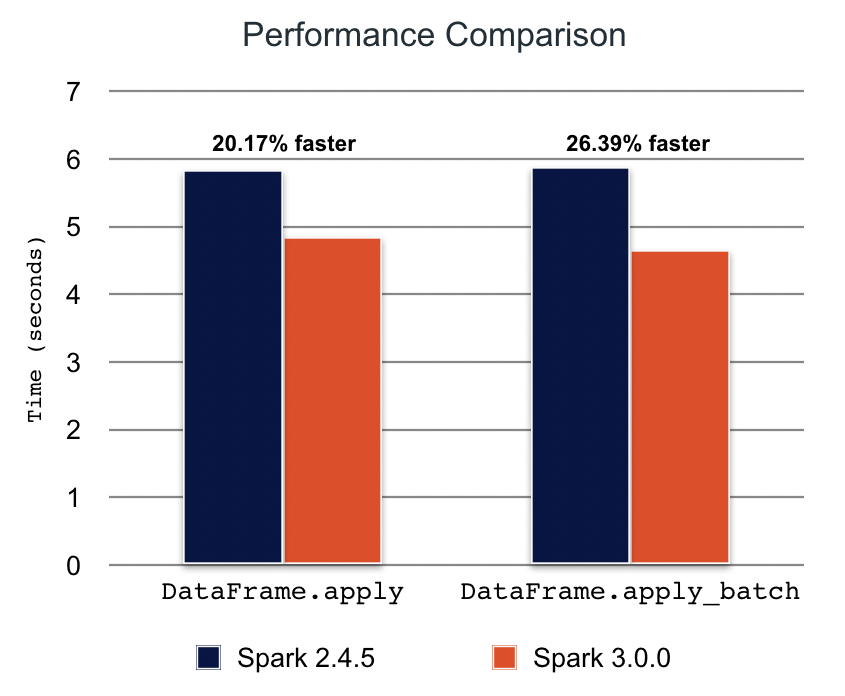
在基于 Spark 3.0.0 的 Koalas 1.0.0 中,基准测试的性能提高了 20%到 25%。
更好的类型提示支持
大多数执行 Python 原生功能的 Koalas API 实际上都采用并输出 pandas 实例。 过去,需要使用 Koalas 实例来返回类型提示,这些提示看起来有些尴尬。
在 Koalas 1.0.0(基于 Python 3.7 或更新版本),开发者也可以在返回类型中使用 pandas 实例:
另外,Koalas 1.0.0 实验性地引入了新的类型提示,以允许用户在类型提示中指定列名称:
支持更多绘图功能
在 Koalas 1.0.0 中,Koalas 的绘图功能 API 覆盖率已达到 90%。现在开发者可以像在 pandas 中一样轻松地在 Koalas 中实现可视化效果。
更广泛的就地(in-place)更新支持
在 Koalas 1.0.0 中,Series 中的就地更新可以很自然地应用到 DataFrame 中,就像 DataFrame 是完全可变的一样。
更好地支持缺失值、NaN 和 NA
在处理 PySpark 和 pands 的缺失数据时,存在一些细微的差异。 例如,缺失数据在 PySpark 中通常表示为“None”,而在 pandas 中则表示为“ NaN”。 此外,pandas 还引入了新的实验性 NA 值,目前在 Koalas 中支持的不是很好。
其中大部分问题已经得到解决,目前 Koalas 正在大力开发以更全面地解决上述问题。举个例子,Series.fillna 在 Koalas 1.0.0 中已经可以正确处理 NaN。

InfoQ主编

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论