

强化学习,特别是深度强化学习,近年来取得了令人瞩目的进展。除了应用于模拟器和游戏领域,它在工业领域也取得了长足进步,如降低数据中心能耗、训练工业机器人等。Ray 是一个为强化学习或类似场景设计的机器学习框架。日前,Ray 合并了在 Kubernetes 上实现 Ray 集群自动伸缩的代码请求,因此我希望在本文中介绍这一新特性,以及上游社区采取的设计方案和其中的考量。
01 强化学习简介
首先,我简单介绍下 Ray 面向的场景:强化学习。
强化学习是机器学习方法的一种,它可以被抽象为代理(agent)与环境之间的互动关系。
环境即代理所处的外部环境,它会与代理产生交互。在每次迭代时,代理会观察到部分或者全部环境,然后决定采取某种行动,而采取的行动又会对环境造成影响。不同的行动会收到来自环境的不同反馈(Reward),代理的目标就是最大化累积反馈(Return)[1]。
对于采取何种行动,代理的行动空间(Action Space)可能是离散的,如围棋等;也可能是连续的。而不少的强化学习算法只能支持连续的空间或者离散的空间。
在采取行动时,代理会根据某种策略(Policy)选择行动。它的策略可以是确定性的,也可以是带有随机性的。在深度强化学习中,这些策略会是参数化的,即策略的输出是输入是一组参数的函数(参数比如神经网络的权重和 bias)。

强化学习经典案例:Flappy Bird AI
强化学习领域有一个非常生动的例子:游戏 Flappy Bird 的 AI [2]。在这个例子中,代理就是玩家控制的小鸟,而环境就是充满管道的飞行环境。小鸟的行动空间只有两个动作:向上飞或者什么都不做(原地下坠)。小鸟的目标就是不断续命,一直飞行下去。这一问题可以被很好地用强化学习的方法建模解决,具体可见参考文献 [2]。
02 Ray 架构
在介绍 Ray 如何在 Kubernetes 上实现自动伸缩之前,这里我先大致介绍一下如何使用 Ray:Ray 本身其实并没有实现强化学习的算法,它是一个基于 Actor 模型实现的并行计算库。
万物先从 Hello World 开始,Ray 的 Hello World 如下图所示:

尽管很简单,这一例子还是用到了许多 Ray 特有的功能。首先是@ray.remote的注解。这一注解的作用是声明这一函数可以被远程且异步地执行。
为了实现远程执行,函数的返回并不是在函数中定义的 Hello world!,而是一个 Object ID(确切地说是一个 Future 对象),它随后创建一个任务(Task),并且会在未来的某个时刻交由一个 Worker 进程执行,其结果可以利用 Object ID 通过ray.get(object_id)获得。
Ray 的论文中有一个整体架构图,但由于相比开源实现,其论文发布时间过早,因此两者存在不少出入。这里我以代码实现为主,介绍一下 Ray 的关键组件。
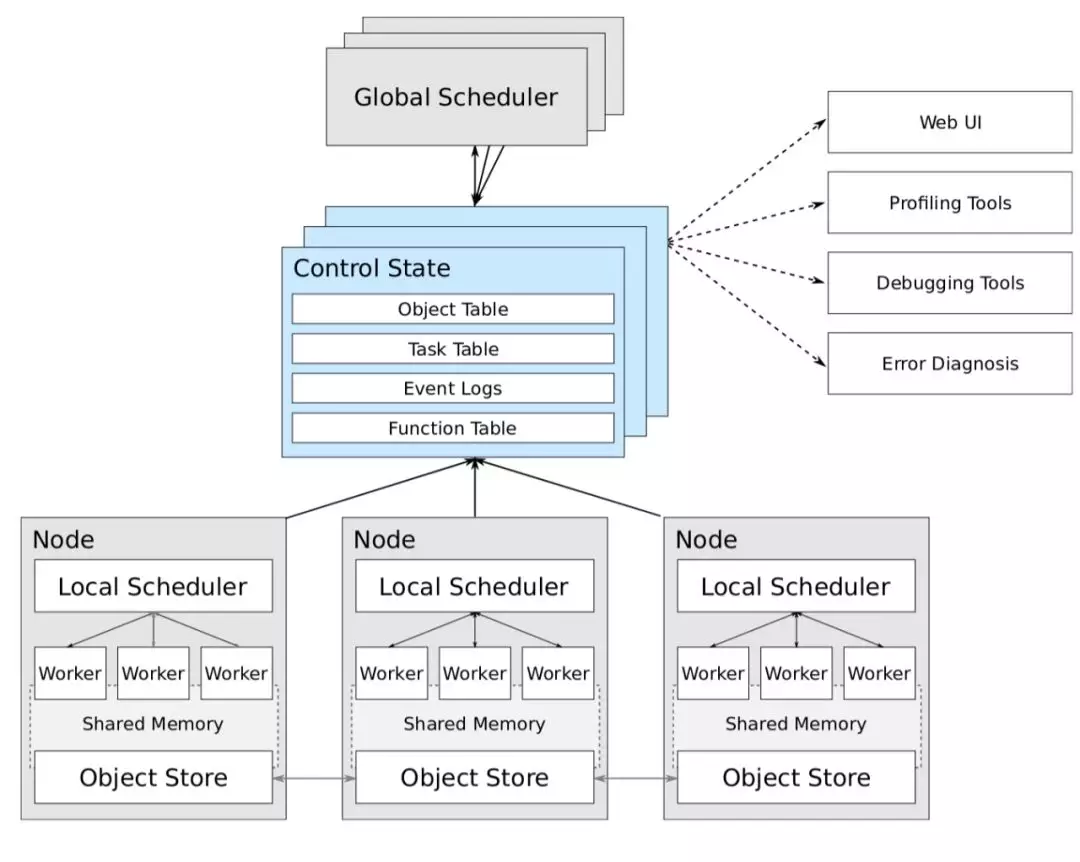
Ray 论文中的架构图
Ray 的节点需要运行两个进程,一个是 RayLet 进程,一个是 Plasma Store 进程(对应图中的 Object Store)。
其中,RayLet 进程中维护着一个 Node Manager 和一个 Object Manager。Ray 提供了 Python 的 API,而 RayLet 是用 C++ 实现的。Node Manager 充当论文中 Local Scheduler 的角色,主要负责管理 Node 下的 Worker,调度在 Node 上的任务,管理任务间的依赖顺序等。Object Manager 主要提供了从其他的 Object Manager Pull/Push Object 的能力。
Plasma Store 进程,是一个共享内存的对象存储进程。原本 Plasma 是 Ray 下的,目前已经是 Apache Arrow 的一部分。正如前文所述,Ray 在执行带有remote注解的函数时并不会立刻运行,而是会将其作为任务分发,其返回也会被存入 Object Store 中。这里的 Object Store 就是 Plasma[4]。
而论文中的 Control State,在实现中被叫做 GCS,是基于 Redis 的存储。而 GCS 是运行在一类特殊的节点上的。这类特殊的节点被称作 Head Node。它不仅会运行 GCS,还会运行对其他节点的 Monitor 进程等。
Ray 提交任务的方式与 Spark 非常类似,需要利用 Driver 来提交任务,而任务会在 Worker 上进行执行。Ray 支持的任务分为两类,分别是任务(Task)和 Actor 方法(ActorMethod)。其中任务就是之前的例子中的被打上了remote注解的函数,而 Actor 方法是被打上了remote注解的类(或叫做 Actor)的成员方法和构造方法。
两者的区别在于任务都是无状态的,而 Actor 会保有自己的状态,因此所有的 Actor 方法需要在 Actor 所在的节点才能执行。这也是 Ray 跟 Spark 最大的不同。Spark 提交的是静态的 DAG,而 Ray 提交的是函数。
03 Ray 的集群化运行
因此,如果需要一个 Ray 集群,我们一共需要两个角色的节点:Head 和 Worker。除了常规方法,这里我介绍一种相对更简单的方式,就是利用 Ray Autoscaler 自动创建集群。
Autoscaler 是 Ray 实现的一个与 Kubernetes HPA 类似的特性,它可以根据集群的负载情况,自动调整集群的规模。
其需要的配置大致如下:
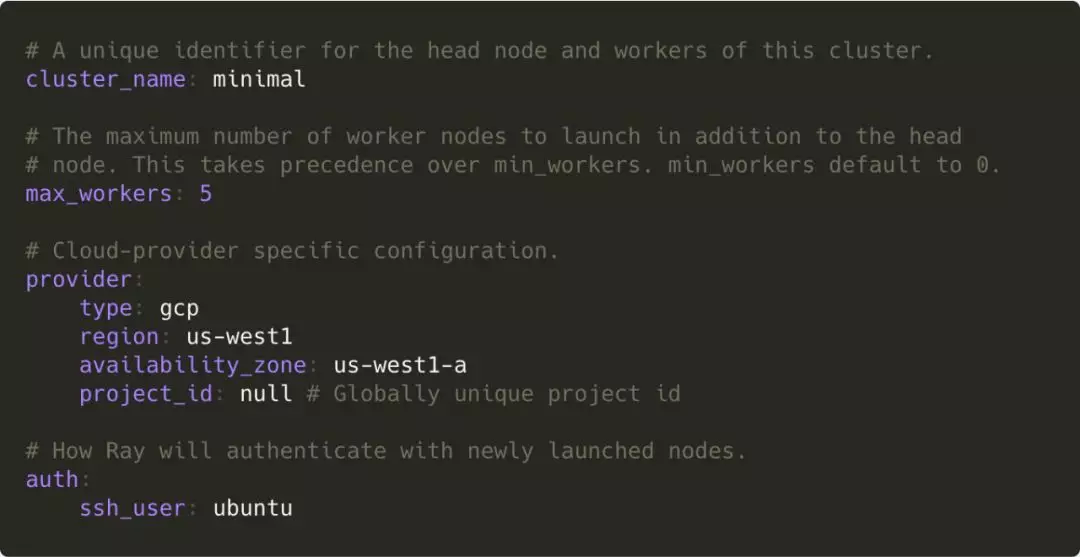
用户只需提供期望的 Worker Node 数量,以及节点资源的提供者(上面的例子中是 GCP),Ray 就会根据负载(默认阈值是 80%)进行自动扩缩容。
04 自动扩缩容在 K8s 上的设计与实现
自动扩缩容是一个非常具有吸引力的特性。Ray 之前只支持在 Kubernetes 上运行集群,而不支持自动扩缩容。这一功能最近刚被实现并且合并到了代码库中。在实现的过程中,Ray 社区尝试了不少思路。
Kubernetes Native 的实现思路
首先是 K8s Native 的实现思路,社区创建了ray-project/ray-operator。
这一思路有两个探索性质的实现:
gaocegege/ray-operatorsilveryfu/ray-operator
前者定义了一个 CRDray,利用 Deployment 创建 Head 和 Worker 节点。一个最小化的配置如下:
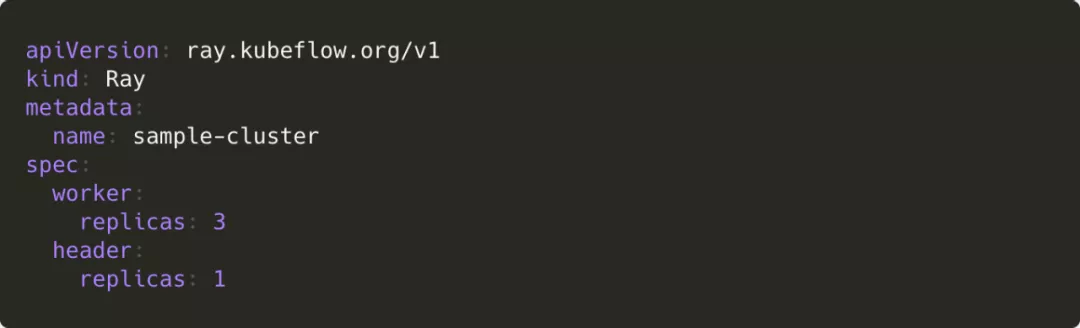
这样的设计允许直接依赖 Kubernetes HPA 进行自动伸缩。但它有一个比较严重的缺陷:Ray 在做 Scale Down 时会根据 Worker 节点的一些状态来判断最适合被回收的节点,而目前的 Kubernetes HPA 不支持如此细粒度的逻辑。
在 HPA 的实现中,它是通过操纵 Deployment 的 Replicas 来实现自动扩缩容的。Deployment 需要通过 ReplicaSet 来删除多余的实例,而 ReplicaSet Controller 在删除时需要通过排序来确定应该删除的实例。由于排序算法本身不具备扩展性,它会先从 UnReady 的 Pod 开始依次删除,直到所有实例都被删除或者删除到了指定数量。
Readiness Gate 可以实现这样的特性,但这一特性目前还比较新,在 v1.14 才刚刚 Stable。此外,这样的实现方式需要非常多的 Dirty Work,比较难以维护和调试。
后者的实现定义了两个 CRD:RayHead和RayWorker。它同样采取 Deployment 来创建 Head 和 Worker,因此同样具备上述缺陷。
Ray Native 的实现思路
既然利用 Kubernetes HPA 很难实现精细化的 Scale Down,考虑到 Ray 本身也有节点的概念,那么利用 Ray 自身的 Autoscaler 抽象,是否可以实现这样的特性呢?
答案是肯定的,社区目前的实现也是如此思路。
之前介绍 Ray 的扩缩容的时候,我提到过节点资源的提供者这样一个概念,这其实就是 Ray 为了支持不同的平台的扩缩容的抽象而自身提供的。任何平台,只要可以实现Provider接口,就可以利用 Ray 原生的命令进行集群的扩缩容:
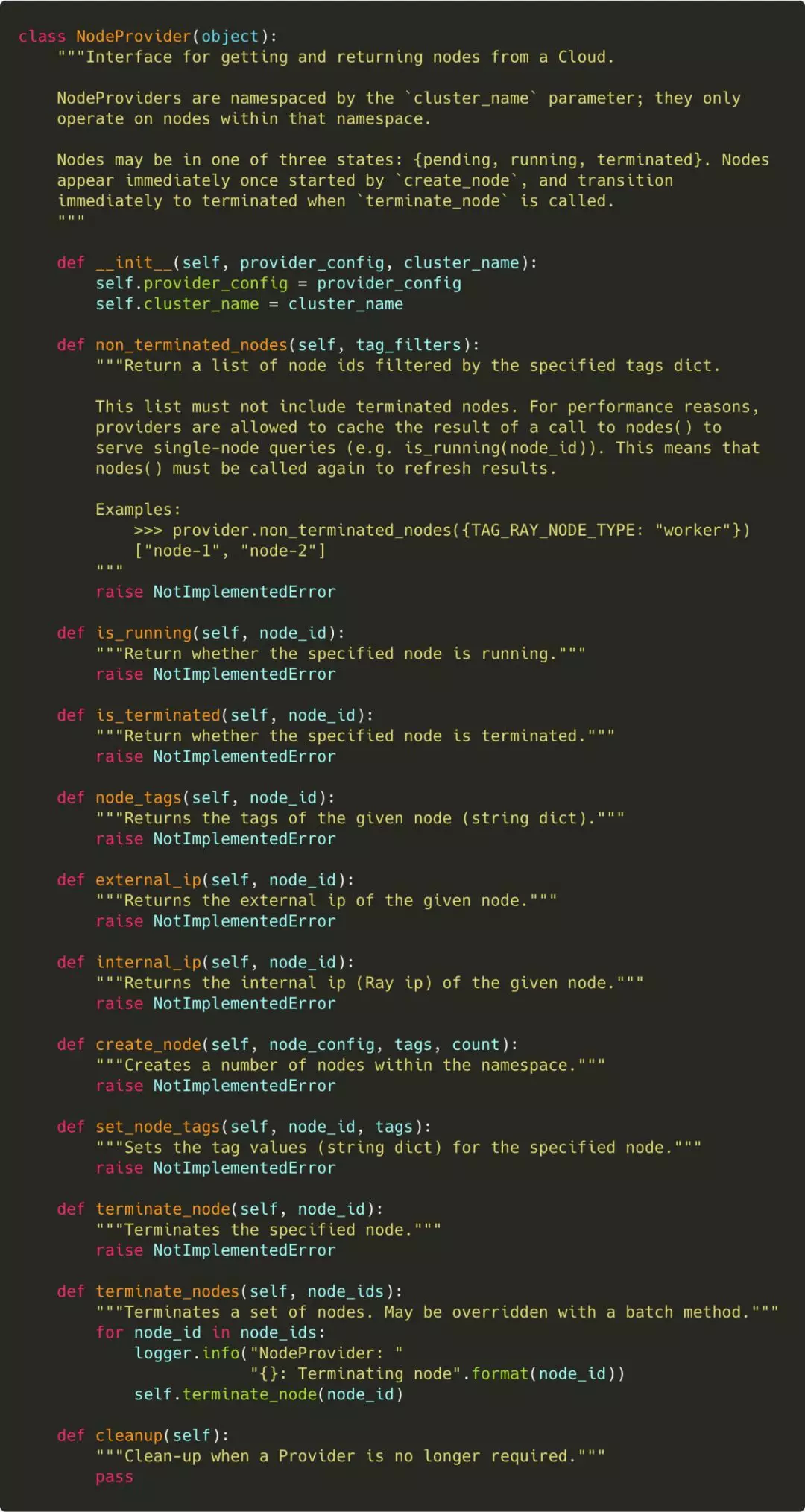
仔细观察接口,你就会发现其实这些接口都可以利用 Python 的 kubernetes client 来完成。
比如non_terminated_nodes,这一接口的返回是当前集群还在运行的节点,我们可以获得 Ray 所有的实例 Pod,进而排除 Failed/Unknown/Succeeded/Terminating 的 Pod 获得。
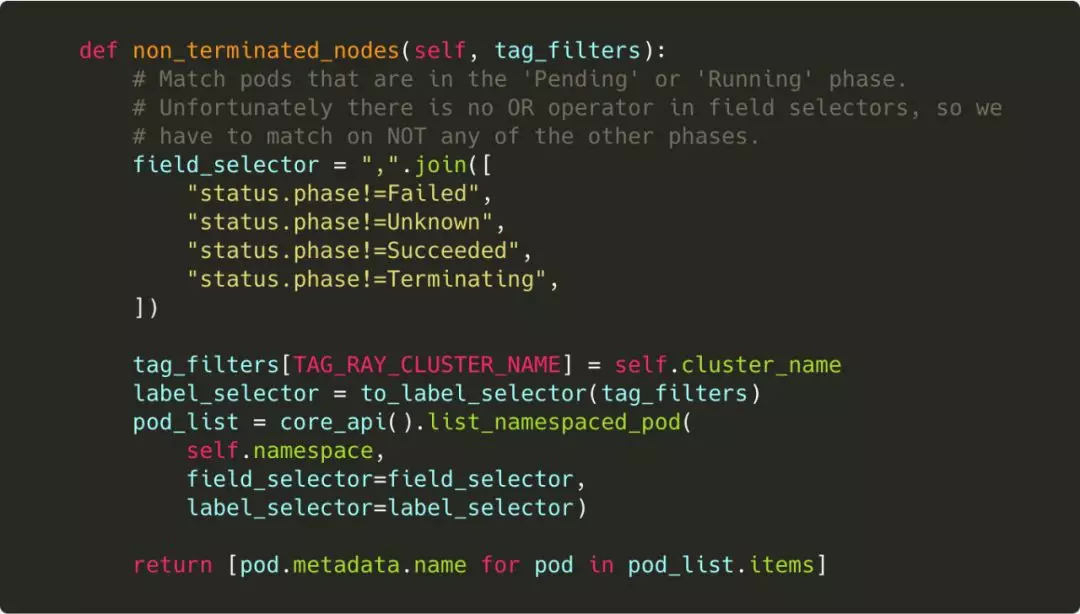
其他接口也有类似的实现。通过这样的方式,用户可以利用 Ray 原生的命令,实现在 Kubernetes 集群上的扩缩容,具有非常统一的用户体验。
04 结语
以上就是我们才云技术团队对 Ray 在 Kubernetes 上进行自动伸缩设计的想法和理解,篇幅所限,这里我不再赘述,但这方面值得深入的内容仍然有很多,如:
Spark 目前可以直接利用 Kubernetes 作为 Executor,利用
spark-submit把 Spark 应用提交给 Kubernetes 执行。那么 Ray 是否也可以采取同样的方式呢?在不需要自动扩缩容的场景下,Kubernetes Native 的实现是否具有一定的优势?
……
本文转载自公众号才云 Caicloud(ID:Caicloud2015)。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论