

本文由 dbaplus 社群授权转载。
我相信每一个集群管理员,在长期管理多个不同体量及应用场景的集群后,都会多少产生情绪。其实这在我看来,是一个很微妙的事,即大家也已经开始人性化的看待每一个集群了。
既然是人性化的管理集群,我总是会思考几个方向的问题:
集群的特别之处在哪儿?
集群经常生什么病?
对于集群产生的突发疾病如何精准地做到靶向定位?
应急处理故障之后如何避免旧除新添?
在长期大规模集群治理实践过程中,也针对各个集群的各种疑难杂症形成了自己的西药(trouble shooting)丶中药(Returning for analysis)丶健身预防(On a regular basis to optimize)的手段及产品。
下面通过自我的三个灵魂拷问来分享一下自己对于大规模集群治理的经验及总结。
灵魂拷问 1
集群量大,到底有啥特点?
集群数量多,规模大:管理着大小将近 20 个集群,最大的 xxx 集群和 xx 集群达到 1000+节点的规模。
灵魂拷问 2
平时集群容易生什么病,都有哪些隐患呢?
集群在整体功能性,稳定性,资源的使用等大的方面都会有一些痛点问题。
常见的文件数过多丶小文件过多丶 RPC 队列深度过高,到各个组件的版本 bug,使用组件时发生严重生产故障,以及资源浪费等都是集群治理的常见问题。
灵魂拷问 3
对于集群的突发疾病如何精准地解决故障?
对于集群突发的故障,平台应具备全面及时的监控告警,做到分钟级发现告警故障,推送告警通知,这是快速解决故障的前提保障。
对于集群的慢性疾病,应该从底层收集可用的详细数据,分析报告加以利用,通过长期的治理来有效的保障集群的深层次健康(具体请阅读《运维老司机都想要掌握的大数据平台监控技巧》),并开发形成能实实在在落地企业的数据资产管理丶数据治理产品。
下面将针对上面的 9 个集群问题或故障逐一解答如何解决。
1、底层计算引擎老旧,业务加工占用大量资源且异常缓慢。
集群底层使用 MR 计算引擎,大量任务未进合理优化,大多数任务占用上千 core,上百 TB 内存,且对集群造成了大量的 IO 读写压力。
解决手段:通过监控“拎大头”,找出消耗资源巨大的任务,通过业务,计算引擎,参数调优来优化集群资源使用,提高集群算力。
业务优化:从业务角度明确来源数据,减少加载数据量。
计算引擎优化 :MR 转 Spark。
参数调优:小文件合并优化,内存内核调优,并发量调优,防止数据倾斜。
2、xx 集群 RPC 故障问题。
现象概述:XX 产线集群提交作业执行慢; 业务数据加工逻辑为读取 HDFS 新增文件>>>入库 HBase; 遍历列表文件周期为 5s。
根因分析:
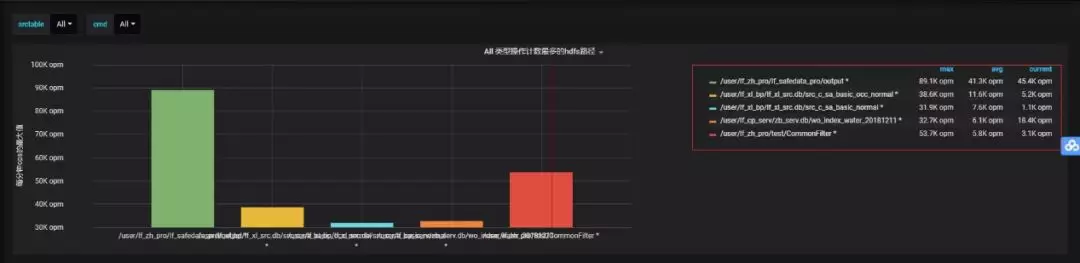
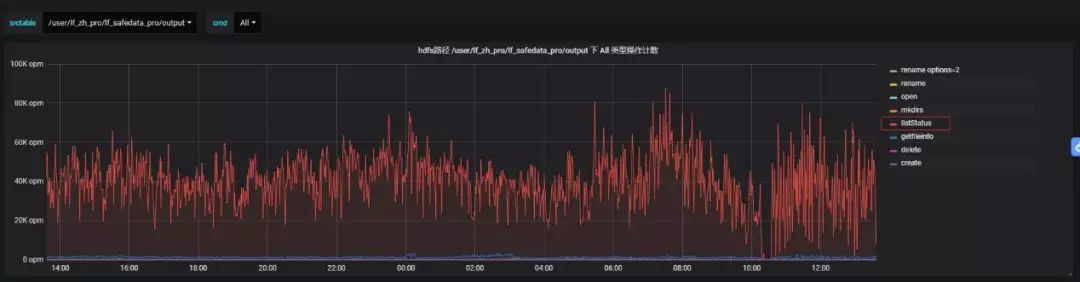

解决方案:
阅读 RPC 源码:动态代理机制+NIO 通信模型。
调整 NN RPC 关键参数,做对比实验。
1)优化系统参数配置:
2)将 HDFS 千万级目录扫描周期从 5s 调整为 5 分钟
3)增加集群 RPC 请求分时段分业务模型深度监控
3、xx 集群由于承载对外多租户,面对各个租户提出的集群生产环境的需求都不一致,造成集群环境复杂化,yarn 资源打满,并且容易出现负载过高的接口机,加重运维成本。
解决手段:
集群环境多版本及异构管理:
配置多版本 Python 环境,并搭建私有第三方库。

配置多版本 Spark,Kafka 环境。

实时监控 yarn 队列资源使用,监控 yarn 应用任务,重点优化。
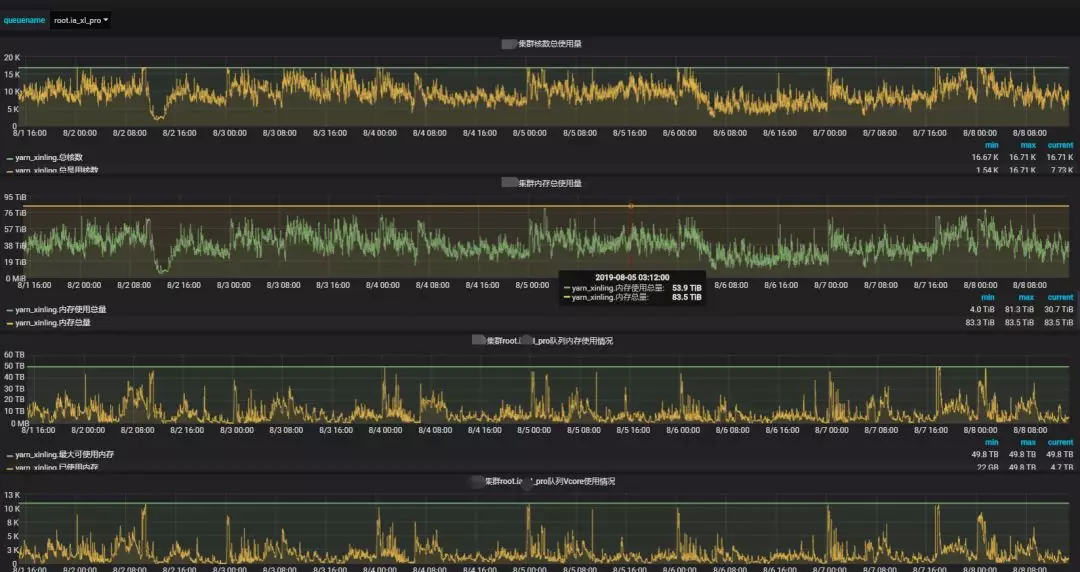
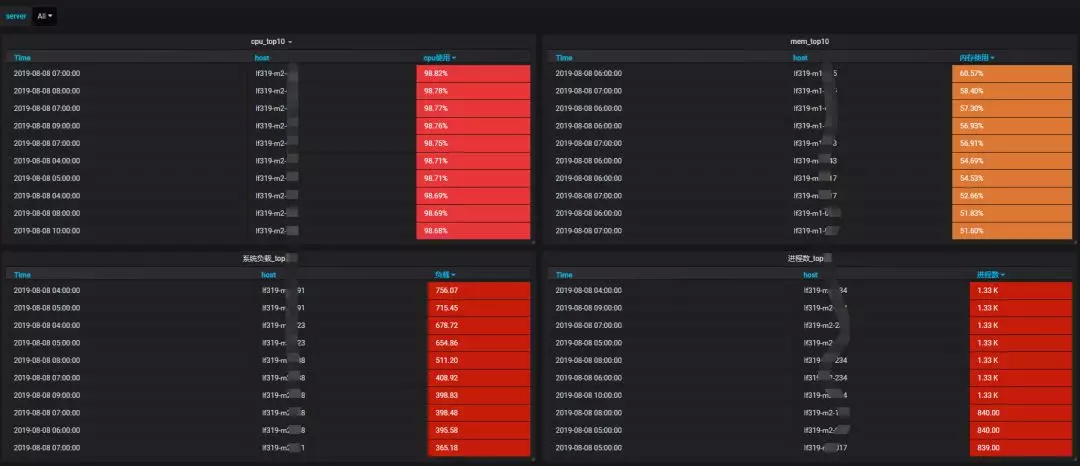
配置明细接口机监控,优化接口机负载。
接口机从基础指标,top 分析,CPU 内存消耗过大的进程多维度监控,及时的合理调整优化接口机的调度任务,降低接口机负载。
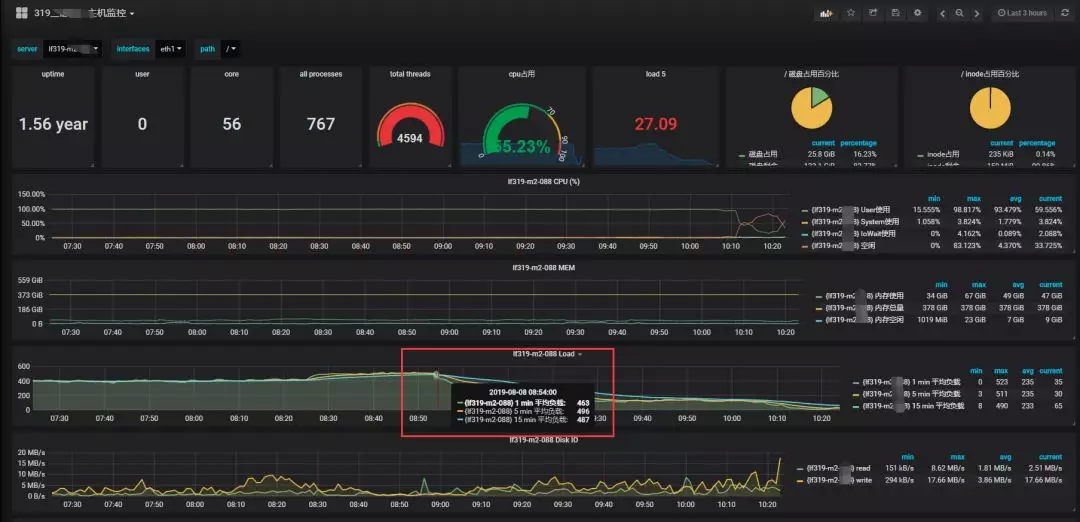
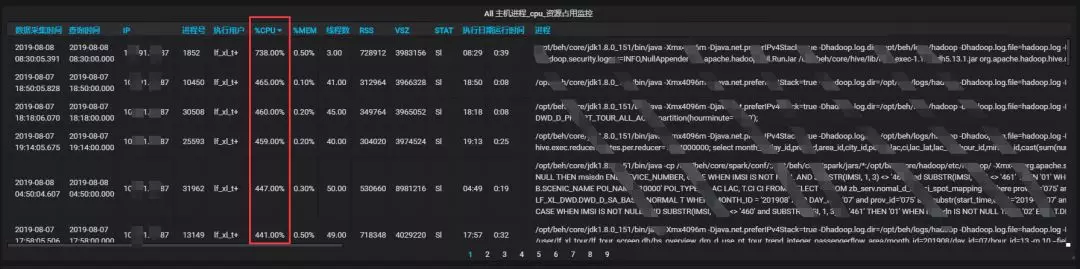
4、xxx 集群由于文件数过多,导致集群运行缓慢,NameNode 进程掉线。
集群的文件对象达到九千多万。且集群的读写 IO 是写多读少。NameNode 启动需要加载大量的块信息,启动耗时过长。
解决手段:
计算引擎优化 :尽量使用 Spark,有效率使用内存资源,减少磁盘 IO 读写。
周期性清理:根据 HDFS 业务目录存储增量,定期协调业务人员清理相关无用业务数据。
块大小管理:小文件做合并,增加 block 大小为 1GB,减少小文件块数量。
深度清理:采集监控 auit 日志做 HDFS 文件系统的多维画像。深入清理无用数据表,空文件,废文件。
5、HDFS 数据目录权限管理混乱,经常造成数据误删或丢失。
由于下放的权限没有及时回收,或者一些误操作造成了数据的误删和丢失。
解决办法:
业务划分:明确梳理各个业务对应权限用户,整改当前 HDFS 数据目录结构,生产测试库分离控制。
数据生命周期管理:
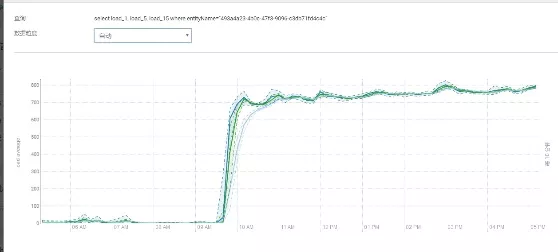
6、yarnJOB 造成节点负载过高影响了其他 job 运行。
某些节点 CPU 负载很高影响了 job 任务的运行,发现有些节点的负载从 9:30 到现在一直很高,导致 job 任务执行了大概 7 个小时。
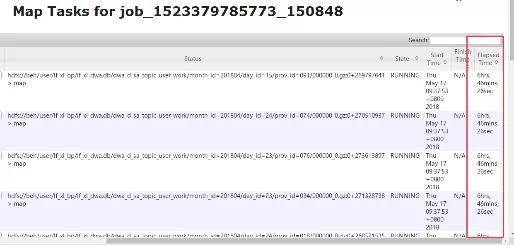
解决办法:
找到耗时 task 执行的节点,确实发现负载很高,并找到了此任务对应的进程。
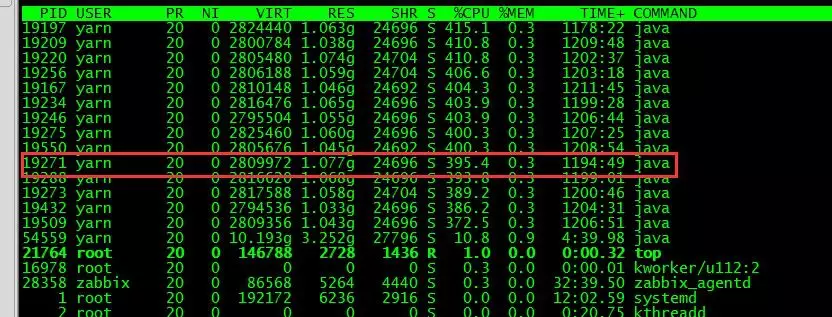
查看此进程的堆栈信息,发现 Full GC 次数很多,时长很长大概 6 个小时,频繁的 Full GC 会使 CPU 使用率过高。

查看 job 进程详情发现,java heap 内存只有 820M,task 处理的记录数为 7400 多万,造成堆内存不足频繁出发 Full GC。
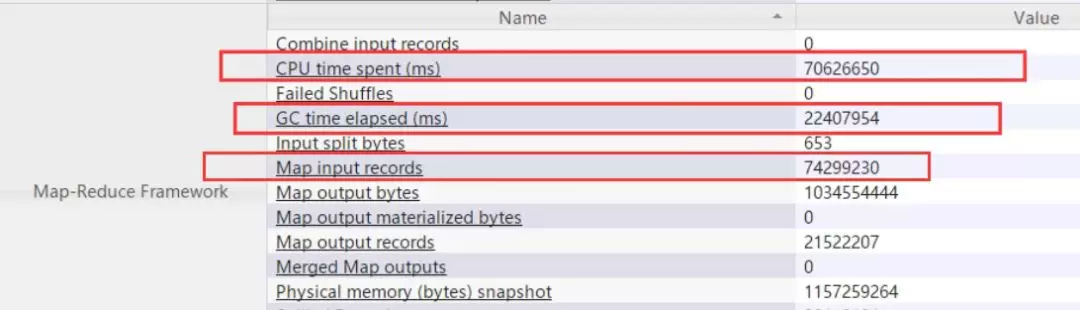
推荐下次执行任务时设置如下参数大小:
7、NameNode 切换后部分 Hive 表无法查询。
小集群 NameNode 发生切换,并出现 Hive 某库下的表和其有关联的表无法使用的情况报错如下:

截图报错,表明当前 NameNode 节点为 stanby 节点。经过排查发现,Hive 的 Metadata 中有些 partition 列的属性还保留之前配置的 NameNode location。
解决办法:
备份 Hive 所在的 MySQL 元数据库 # mysqldump -uRoot -pPassword hive > hivedump.sql;
进入 Hive 所在的 MySQL 数据库执行,修改 Hive 库下 SDS 表下的 location 信息,涉及条数 9739 行。把指定 IP 的 location 替换成 nameservice ;
切换 NameNode 验证所影响 Hive 表是否可用;
业务全方面验证 ;
变更影响范围:本次变更可以在线进行实施,避开业务繁忙段,对业务无影响;
回退方案:从备份的 mysqldump 文件中恢复 mysql hive 元数据库 mysql -uUsername -pPassword hive < hivedump.sq。
8、Spark 任务运行缓慢,且经常执行报错。
产线集群提交作业执行报错,个别 Task 执行耗时超过 2h: ERROR server.TransportChannelHandler: Connection to ip:4376 has been quiet for 120000 ms while there are outstanding requests. Assuming connection is dead; please adjust spark.network.timeout if this is wrong.
根因分析:
报错表象为 shuffle 阶段拉取数据操作连接超时。默认超时时间为 120s。
深入了解 Spark 源码:在 shuffle 阶段会有 read 和 write 操作。
首先根据 shuffle 可使用内存对每一个 task 进行 chcksum,校验 task 处理数据量是否超出 shuffle buffer 内存上限。该过程并不是做全量 chcksum,而是采用抽样的方式进行校验。
其原理是抽取 task TID ,与 shuffle 内存校验,小于 shuffle 内存上限,则该区间的 task 都会获取 task data 遍历器进行数据遍历 load 本地,即 HDFS Spark 中间过程目录。
这样会导致一些数据量过大的 task 成为漏网之鱼,正常来说,数据量过大,如果被校验器采样到,会直接报 OOM,实际情况是大数据量 task 没有被检测到,超出 buffer 过多,导致 load 时,一部分数据在内存中获取不到,进而导致连接超时的报错假象。
解决方案:
1)调优参数配置:
spark.shuffle.manager(sort),spark.shuffle.consolidateFiles (true),spark.network.timeout(600s)。报错解决,运行耗时缩短一小时。
2)excutor 分配内存从 16g 降为 6g。内存占用节省三分之二,运行耗时增加一小时。
9、某 HBase 集群无法 PUT 入库问题处理。
集群情况介绍:HDFS 总存储 20+PB,已使用 75+%,共 600+ 个 DN 节点,大部分数据为 2 副本(该集群经历过 多次扩容,扩容前由于存储紧张被迫降副本为 2),数据分布基本均衡。集群上只承载了 HBase 数据库。
故障描述:因集群部分 DN 节点存储使用率非常高(超过 95%),所以采取了下线主机然后再恢复 集群中这种办法来减轻某些 DN 存储压力。
且集群大部分数据为 2 副本,所以在这个过程 中出现了丢块现象。通过 fsck 看到已经彻底 miss,副本数为 0。
因此,在重启 HBase 过程中,部分 region 因 为 block 的丢失而无法打开,形成了 RIT。
对此问题,我们通过 hadoop fsck –delete 命令清除了 miss 的 block。然后逐库通过 hbase hbck –repair 命令来修复 hbase 在修复某个库的时候在尝试连接 ZK 环节长时间卡死(10 分钟没有任何输出),被迫只能 中断命令。
然后发现故障表只有 999 个 region,并且出现 RIT,手动 assign 无效后,尝试了重启库及再次 repair 修 复,均无效。
目前在 HDFS 上查看该表 region 目录总数为 1002 个,而 Hbase UI 上是 999 个,正常值为 1000 个。
问题处理:后续检查发现在整个集群的每张 HBase 表都有 region un-assignment 及 rowkey 存在 hole 问题(不是单张表存在问题)。
运行 hbase hbck -details -checkCorruptHFiles 做集群状态检查,检查结果如下:
每张表可用(online)的 region 数都少于 1000,共存在 391 个 inconsistency,整个集群基本不可用。
因为每张表都不可用,所以通过新建表并将原表的 HFile 文件 BulkLoad 入新表的方案基本不可行。
第一、这种方案耗时太长;第二、做过一个基本测试,如果按照原表预 分区的方式新建表,在 BulkLoad 操作后,无法在新表上查询数据(get 及 scan 操作均 阻塞,原因未知,初步估计和预分区方式有关)。
基于以上分析,决定采用 hbck 直接修复原表的方案进行,不再采用 BulkLoad 方案。
运行命令 hbae hbck -repair -fixAssignments -fixMeta,报 Repair 过程阻塞异常。
查 HMaster 后台日志,发现是某个 RegionServer(DSJ-XXXXXX-XX-XXX/xx.xxx.x.xxx)的连接数超多造成连接超时。重启该 RegionServer 后再次运行 hbck -repair -fixAssignments -fixMeta 顺序结束,并成功修复了所有表的 region un-assignment、hole 及 HBase:meta 问题。
应用层测试整个集群入库正常,问题处理完成。
10、Kafka 集群频频到达性能瓶颈,造成上下游数据传输积压。
Kafka 集群节点数 50+,集群使用普通 SATA 盘,存储能力 2000TB,千亿级日流量,经常会出现个别磁盘 IO 打满,导致生产断传,消费延迟,继而引发消费 offset 越界,单个节点 topic 配置记录过期等问题。
1)降低 topic 副本:
建议如果能降低大部分 topic 的副本,这个方法是简单有效的。
降副本之后再把集群的拷贝副本所用的 cpu 核数降低,可以由 num.replica.fetchers=6 降低为 num.replica.fetchers=3。磁盘 IO 使用的 num.io.threads=14 升为 num.io.threads=16。num.network.threads=8 升为 num.network.threads=9。此参数只是暂时压榨机器性能,当数据量递增时仍会发生故障。
2)设定 topic 创建规则,针对磁盘性能瓶颈做分区指定磁盘迁移:
如果降低副本收效甚微,考虑到目前集群瓶颈主要在个别磁盘读写 IO 达到峰值,是因磁盘的 topic 分区分配不合理导致,建议首先做好针对 topic 分区级别 IO 速率的监控,然后形成规范合理的 topic 创建分区规则(数据量,流量大的 topic 先创建;分区数*副本数是磁盘总数的整数倍),先做到磁盘存储的均衡,再挑出来个别读写 IO 到达瓶颈的磁盘,根据监控找出读写异常大分区。
找出分区后再次进行针对 topic 的分区扩容或者针对问题分区进行指定磁盘的迁移。这样集群的整体利用率和稳定性能得到一定的提升,能节省集群资源。
3)Kafka 版本升级及 cm 纳管:
将手工集群迁移至 cm 纳管,并在线升级 Kafka 版本。
4)zk 和 broker 节点分离:
进行 zk 和 broker 节点的分离工作,建议进行 zk 节点变化而不是 broker 节点变化,以此避免数据拷贝带来的集群负荷,建议创建测试 topic,由客户端适当增加批大小和减少提交频率进行测试,使集群性能达到最优。
作者介绍:
小火牛,项目管理高级工程师,具有多年大数据平台运维管理及开发优化经验。管理过多个上千节点集群,擅长对外多租户平台的维护开发。信科院大数据性能测试、功能测试主力,大厂 PK 获得双项第一。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论