编辑按:这篇文章由百度深度学习团队和 _CoreOS etcd_ 团队联合发布,经作者授权,由 InfoQ 翻译为中文版予以发布。
什么是 PaddlePaddle
PaddlePaddle 是一个易用的、高效的、灵活的和可扩展的深度学习平台,最初由百度开发,目的是将深度学习应用于百度自 2014 年之后的产品。
使用 PaddlePaddle 所支持的 15 个百度产品已经创造了 50 多项创新成果,其范围从搜索引擎、在线广告,到问答和系统安全。
在 2016 年 9 月,百度开源了 PaddlePaddle ,这马上就吸引了许多百度之外的贡献者。
为什么要在 Kubernetes 上运行 PaddlePaddle
PaddlePaddle 的旨在做成轻薄独立的计算架构。用户可以在 Hadoop、Spark、Mesos、Kubernetes 及其他框架之上运行它。我们对 Kubernetes 浓厚的兴趣产出自它的灵活性、效率及其丰富的功能。
我们在各种百度产品中应用 PaddlePaddle 的过程中,发现 PaddlePaddle 主要用于两个方面:研究和产品。研究数据不经常改动,关注点是快速实验去达成预期的科学测量。产品数据通常来自于由 Web 服务产生的日志消息,经常会变化。
成功的深度学习项目既包括研究也包括数据处理管道,有许多需要进行调整的参数。许多工程师同时投身于项目的不同部件。
为确保项目易于管理并有效地利用硬件资源,我们希望在同一架构平台上运行项目的所有部件。
平台应该提供:
- 容错性。它应该把管道的每一阶段抽象为服务,它由许多处理构成,通过冗余提供高吞吐率和健壮性。
- 自动扩展。在白天,通常会有许多活动的用户,平台应该扩展在线服务。而到了晚上,平台则应该释放一些资源进行深度学习实验。
- 任务打包和隔离。它应该能够把需要 GPU 的 PaddlePaddle 训练过程、需要大内存的后端服务以及需要磁盘 IO 的 CephFS 过程分配到同一节点上以充分利用其硬件。
我们想要的是一个在同一集群中运行深度学习系统、Web 服务器(比如 Nginx)、日志收集器(比如 fluentd)、分布式队列服务(比如 Kafka)、日志合并工具和其他用 Storm、Spark 和 Hadoop MapReduce 写成的数据处理器的平台。我们希望在同一集群中运行所有的任务(在线和离线)、生产和实验,所以我们应该充分利用该集群,因为不同类型的任务需要不同的硬件资源。
因为虚拟机带来的日常费用与我们的效率和利用率的目标是矛盾的,所以我们基于解决方案选择容器。
鉴于我们基于解决方案对不同容器的研究,Kubernetes 最适合我们的需求。
在 Kubernetes 上进行分布式训练
PaddlePaddle 天生就支持分布式训练。在 PaddlePaddle 集群中有两个职责:参数服务器和训练者。每个参数服务器过程维护一个公共模型的碎片。每个训练者有它自己本地的模型拷贝,并用自己的本地数据去更新这个模型。在训练过程期间,训练者发送模型更新到服务参数服务器,参数服务器负责收集这些更新,以便训练者能够用全局模型同步他们的本地拷贝。
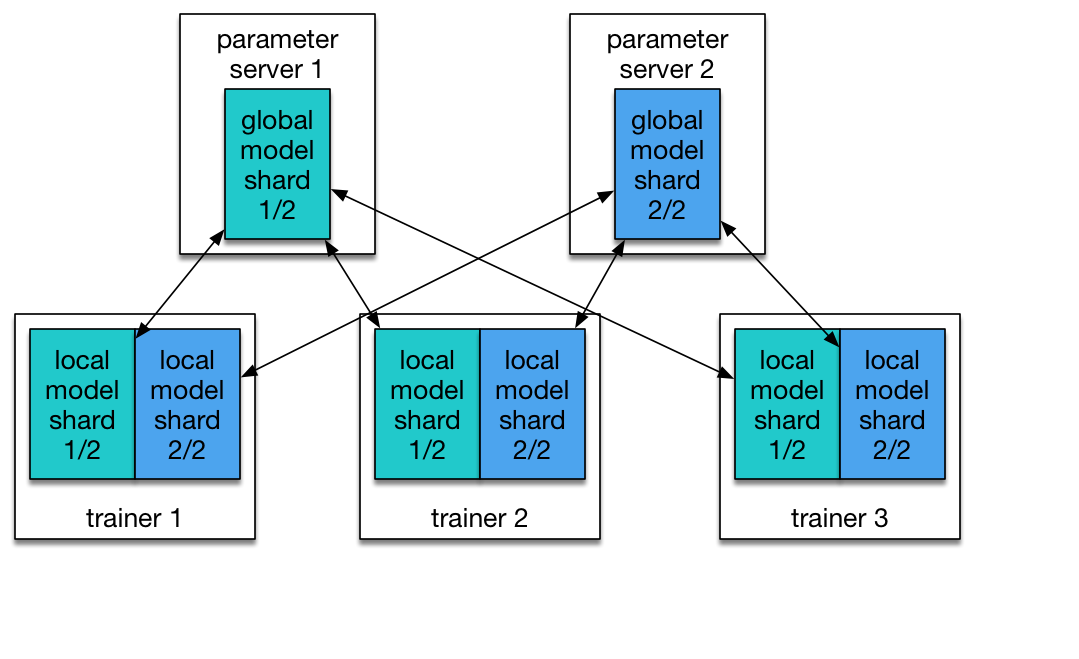
图 1:分割为两个碎片的模型。由两个参数服务器负责管理。
有些其他方式是使用一组参数服务器去共同持有一个非常巨大的模型,该模型处于多台主机上的 CPU 内存空间中。但实际上,我们通常不会有这么大的模型,因为受 GPU 内存所限处理这么大的模型应该效率极低。在我们的配置中,多台参数服务器大多是为了快速通信。假设与所有训练者一起工作的只有一台参数服务器,那么该参数服务器就必须得从所有训练者中收集渐变情况,于是就成了一个瓶颈。我们的经验表明,包含有同样数量的训练者和参数服务器是一项实验性的有效配置。而我们通常会在同一节点上运行一对训练者和参数服务器。在如下 Kubernetes 任务配置中,我们启动一个运行在 N 个 Pod 的任务,每个 Pod 上有一个参数服务器和一个训练者进程。
yaml
apiVersion: batch/v1
kind: Job
metadata:
name: PaddlePaddle-cluster-job
spec:
parallelism: 3
completions: 3
template:
metadata:
name: PaddlePaddle-cluster-job
spec:
volumes:
- name: jobpath
hostPath:
path: /home/admin/efs
containers:
- name: trainer
image: your_repo/paddle:mypaddle
command: ["bin/bash", "-c", "/root/start.sh"]
env:
- name: JOB_NAME
value: paddle-cluster-job
- name: JOB_PATH
value: /home/jobpath
- name: JOB_NAMESPACE
value: default
volumeMounts:
- name: jobpath
mountPath: /home/jobpath
restartPolicy: Never
我们可以看到这个配置中的 parallelism、completions 都设置为了 3。所以该任务将同时启动 3 个 PaddlePaddle pod,而且该任务将在所有三个 pod 结束时完成。
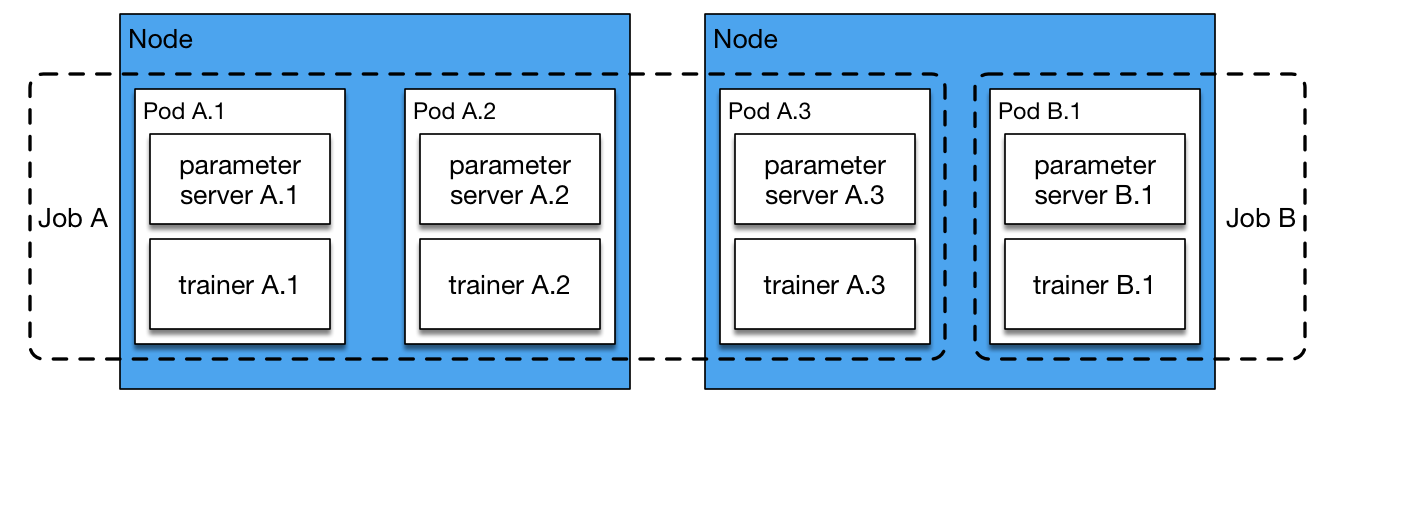
图 2:在两个节点上运行的一个 pod 的任务 B 和三个 pod 的任务 A。
每个 pod 的入口点是 start.sh 。它从一个存储服务中下载数据,以便训练者能从 pod 本地磁盘空间中快速读取。在下载完成之后,它运行一段 Python 脚本 start_paddle.py ,它启动了一个参数服务器,等到所有 pod 的参数服务器都准备就绪后,再启动该 pod 上的训练者进程。
这个等待是必须的,因为每个训练者需要与所有参数服务器对话,如图 1 所示。Kubernetes API 使训练者可以检查 pod 的状态,所以 Python 脚本应该等到所有参数服务器的状态都变为“运行中(running)”后再启动训练员进程。
一般,从数据碎片到 pod/ 训练员的映射是静态的。如果我们打算去运行 N 个训练者,就需要把数据分割为 N 个碎片,然后把每个碎片静态指定给每个训练者。我们再次依赖 Kubernetes API 把 pod 整理成列表放到任务中,把 pod/ 训练者从 1 到 N 进行编号,那么第 i 个训练者就可以读到第 i 个数据碎片了。
训练的数据通常在分布式文件系统上提供。实际上我们使用的是我们企业预置型集群上的 CephFS 和 AWS 上的 Amazon Elastic File System。如果你有兴趣构建运行分布式 PaddlePaddle 训练任务的 Kubernetes 集群,请阅读这个教程。
接下来的工作
我们正致力于让使用Kubernetes 的PaddlePaddle 更平稳地运行。
你可能注意到了,目前训练者调度完全依赖于基于静态分割映射的Kubernetes。这种方式易于上手,但可能会导致一些效率问题。首先,缓慢或停滞的训练者会阻碍整个任务。在初始部署之后没有可控的抢占或重新调度。第二,这种资源分配是静态的。所以如果Kubernetes 具有的可用资源超出我们的预料,那么就不得不去手工修改资源需求。这是一项枯燥乏味的工作,与我们效率和利用率的目标是不一致的。
为解决上述问题,我们将增加一个懂得Kubernetes API 的PaddlePaddle 主机,它能动态增加、移除资源能力,并以更加动态的方式把碎片分派给训练者。该PaddlePaddle 主机把etcd 作为动态映射碎片到训练者的容错性存储。因此,即使该主机崩溃了,映射也不会丢失。Kubernetes 可以重启该主机,任务仍将保持运行。
另一个可能的改进是更好的PaddlePaddle 任务配置。我们所提倡的具有同等数量的训练者和参数服务的经验主要是从特定目标集群的运用中收集而来的。这个策略在我们只运行PaddlePaddle 任务的集群上有明显的效果。然而,在运行许多种任务的多用途集群上,这个策略可能就未必合适了。
PaddlePaddle 训练者能利用多个 GPU 去加快计算。但 GPU 在 Kubernetes 中还不属于第一类资源。我们必须半手动地管理 GPU。我们将很愿意与 Kubernetes 社区共同去改进 GPU 的支持,确保 PaddlePaddle 在 Kubernetes 上以最佳状态运行。
你可以:
- 下载 Kubernetes
- 在 GitHub 上参与 Kubernetes 项目
- 在 Stack Overflow 上提问或回答问题
- 在 Slack 上与社区取得联系
- 在推特上 @Kubernetesio 咨询最新更新的事宜
编辑按:这篇文章由百度深度学习团队和 _CoreOS etcd_ 团队联合发布,经作者授权,由 InfoQ 翻译为中文版予以发布。




