
在这个博客文章系列中,你将学习到三种用来构建流应用程序的强大的 Flink 模式:
动态更新应用程序逻辑
动态数据分区(混排),在运行时控制
基于自定义窗口逻辑的低延迟警报(不使用窗口 API)
这些模式带来了更多使用静态定义的数据流实现的功能,并提供了满足复杂业务需求的构建块。
应用程序逻辑的动态更新允许 Flink 作业在运行时更改,而不会因停止和代码重新提交而导致停机。
动态数据分区提供了在运行时更改 Flink 分配事件和分组方式的能力。当使用可动态重新配置的应用程序逻辑构建作业时,往往会自然而然需求这样的能力。
自定义窗口管理展示了当原生窗口API与你的需求不完全匹配时,如何使用底层进程函数API。具体来说,你将学习如何在 Windows 上实现低延迟警报以及如何使用计时器限制状态增长。
这些模式都是建立在 Flink 核心功能的基础上的,但框架的文档可能不够一目了然,因为不用具体的场景举例的话,往往很难解释和展示这些模式背后的机制。所以我们将通过一个实际示例来展示这些模式,这个示例为 Apache Flink 提供了一个真实的使用场景,那就是一个欺诈检测引擎。我们希望本系列文章能帮助你将这些功能强大的方法放到自己的工具箱中,从而执行一些激动人心的新任务。
在该系列的第一篇博文中,我们将介绍这个演示应用程序的高级架构,描述它的各个组件及其交互。然后,我们将深入研究该系列中第一个模式的实现细节——动态数据分区。
你可以在本地完整运行这个欺诈检测演示应用程序,并通过随附的 GitHub 存储库查看实现的细节。
欺诈检测演示
我们的欺诈检测演示的完整源代码都是开源的,可以在线获取。要在本地运行它,请访问以下存储库并按照自述文件中的步骤操作:
https://github.com/afedulov/fraud-detection-demo
你会看到该演示是一个自包含的应用程序——它只需要从源构建 docker 和 docker-compose,并且包含以下组件:
带有 ZooKeeper 的 Apache Kafka(消息代理)
Apache Flink(应用程序集群)
欺诈检测 Web 应用
这款欺诈检测引擎的高级目标是消费一个金融交易流,并根据一组规则对其进行评估。这些规则会经常更改和调整。在实际的生产系统中,我们需要在运行时添加和删除它们,而不会因停止和重新启动作业而带来高昂的代价。
在浏览器中转到演示 URL 时,将显示以下 UI:
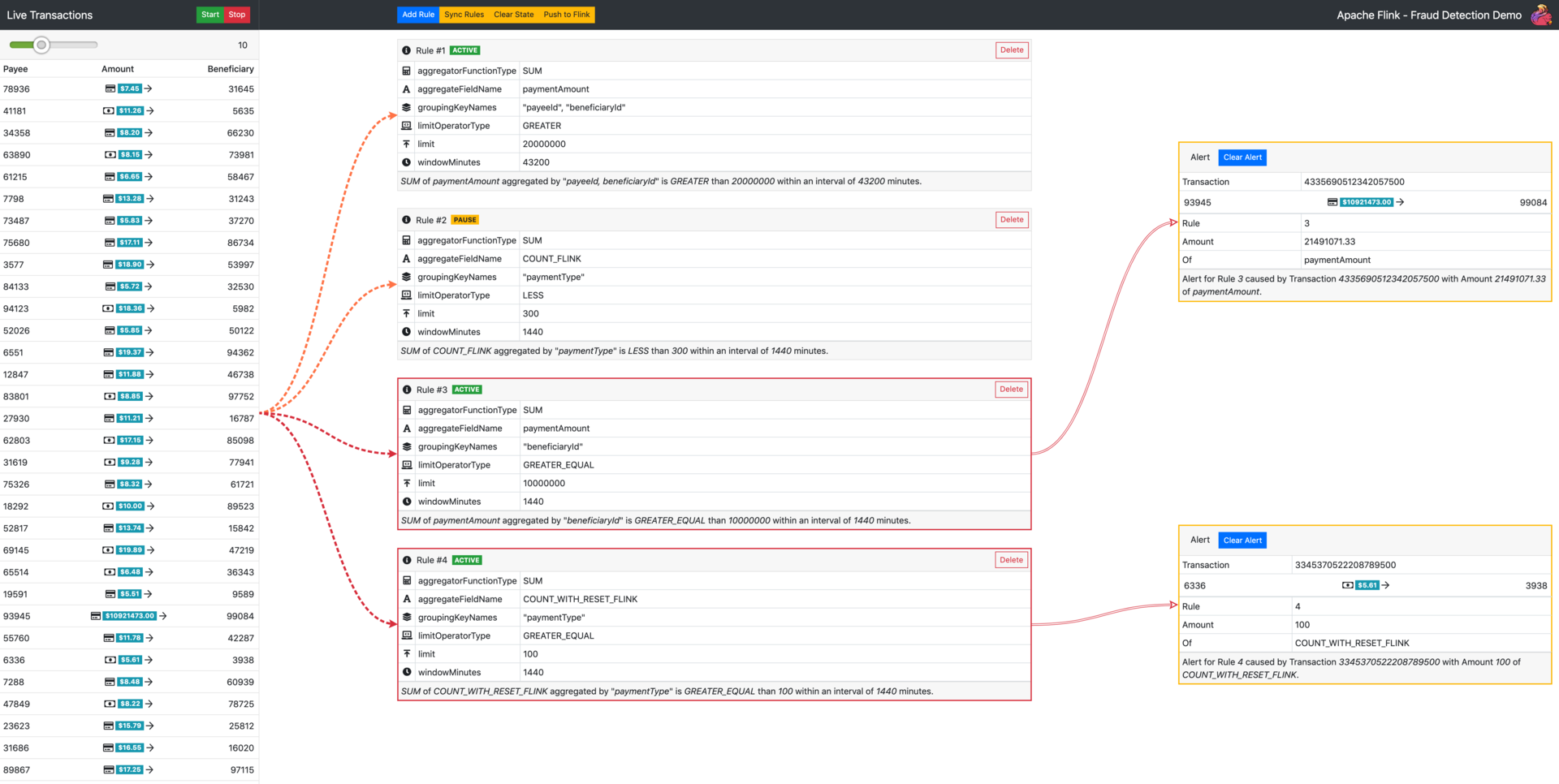
图 1:欺诈检测演示 UI
单击“Start”按钮后,你可以在左侧看到在系统中流动的财务交易的直观表示。可以使用顶部的滑块控制每秒生成的交易数。中间部分用来管理 Flink 评估的规则。在这里,你可以创建新规则以及发出控制命令,例如清除 Flink 的状态。
演示自带一组预定义的示例规则。你可以单击 Start 按钮,一段时间后就能观察到 UI 右侧部分中显示的警报。这些警报是 Flink 根据预定义规则针对生成交易流的评估结果。
我们的欺诈检测示例系统包含三大组件:
前端(React)
后端(SpringBoot)
欺诈检测应用程序(Apache Flink)
主要元素之间的交互如图 2 所示。
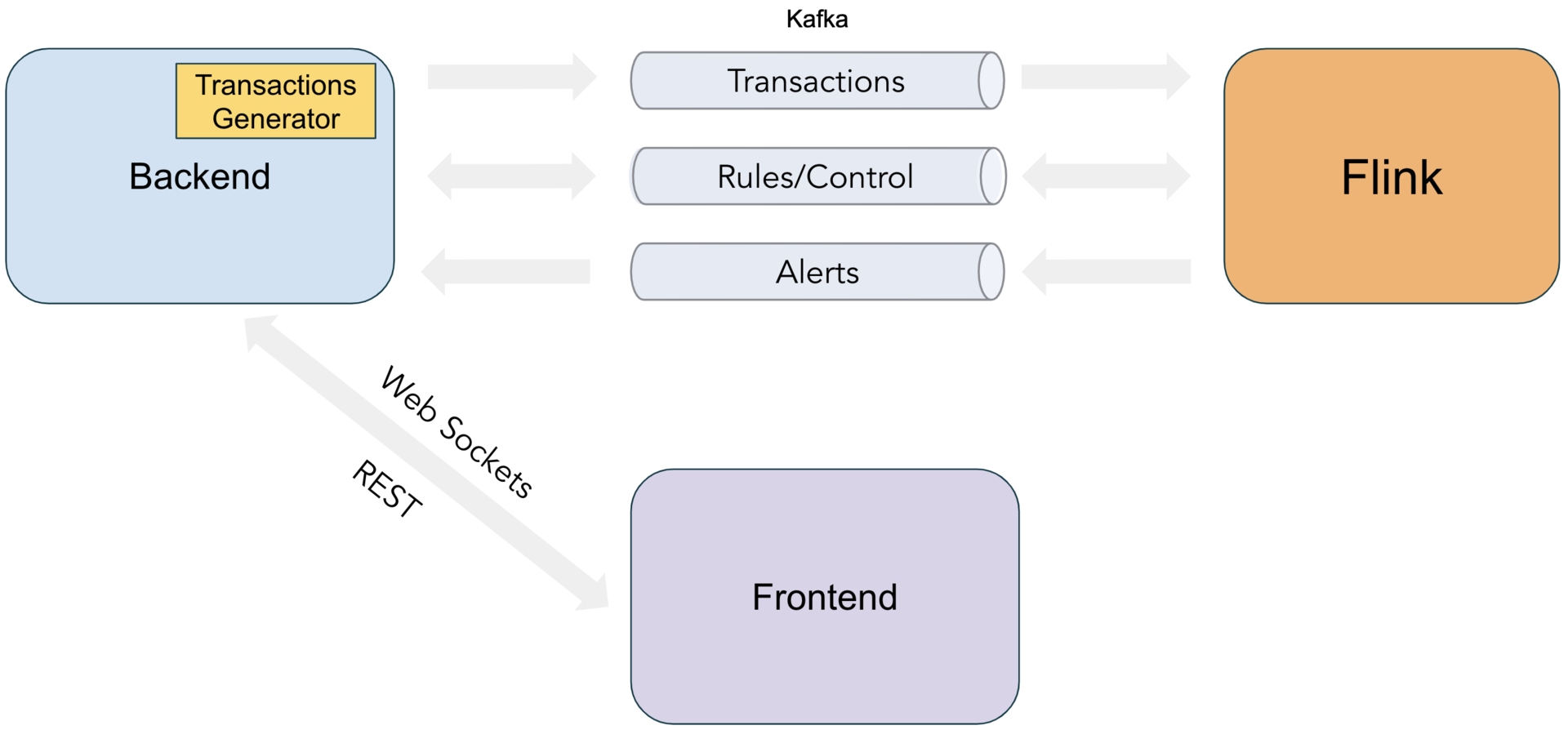
图 2:欺诈检测演示组件
后端向前端公开了一个 REST API,用于创建/删除规则以及发布控制命令来管理演示应用的执行。然后通过一个“Control”Kafka 主题将这些前端动作转发给 Flink。后端还包括一个 Transaction Generator(交易生成器)组件,该组件通过单独的“Transactions”主题将模拟的汇款事件流发送到 Flink。由 Flink 生成的警报由后端的“Alerts”主题的消费,并通过 WebSockets 转发到 UI。
现在你已经熟悉了我们这款欺诈检测引擎的总体布局和目标,现在我们来详细介绍实现这种系统所需的条件。
动态数据分区
我们要研究的第一个模式是动态数据分区。
如果你过去曾经使用过 Flink 的 DataStream API,那么你无疑会熟悉 keyBy 方法。Keying 一个流会重排所有记录,以便将具有相同 key 的元素分配给同一分区。这意味着所有具有相同 key 的记录将由下一个运算符的同一个物理实例处理。
在典型的流应用程序中,key 的选择是固定的,由元素内的某些静态字段确定。例如,当构建一个简单的基于窗口的交易流聚合时,我们可能总是按交易账户 ID 进行分组。
这种方法是在众多用例中实现水平可扩展性的主要构建块。但如果应用程序试图在运行时提供业务逻辑的灵活性,这种方法还不够用。为了理解为什么会发生这种情况,我们首先以一个功能需求的形式为这款欺诈检测系统制定一个现实的示例规则定义:
“只要在一周内从同一付款人向同一收款人的累计付款总额超过 1,000,000 美元,就会发出警报。”
在这个公式中,我们可以发现许多能够在新提交的规则中指定的参数,甚至可能稍后在运行时修改或调整它们:
汇总字段(付款金额)
分组字段(付款人+收款人)
汇总函数(总和)
窗口持续时间(1 周)
限制(1000000)
限制运算符(更大)
因此,我们将使用下面这样简单的 JSON 格式来定义上述参数:
在这里,重要的是要了解 groupingKeyNames 确定的是事件的实际物理分组——必须将具有相同指定参数值(例如,25 号付款人->12 号收款人)的所有交易汇总到评估运算符的同一个物理实例中。自然,在 Flink API 中以这种方式分发数据的过程是通过一个 keyBy()函数实现的。
Flink 的keyBy()文档)中的大多数示例都使用硬编码的 KeySelector,其会提取特定固定事件的字段。但是,为了支持所需的灵活性,我们必须根据规则的定义以更加动态的方式提取它们。为此,我们将不得不使用一个额外的运算符,该运算符为每个事件做准备以将其分发到正确的聚合实例。
在高级层面上,我们的主要处理管道如下所示:
先前我们已经确定,每个规则都定义一个 groupingKeyNames 参数,该参数用来指定将哪些字段组合用于传入事件的分组。每个规则都可以使用这些字段的任意组合。同时,每个传入事件都可能需要根据多个规则进行评估。这意味着这些事件可能需要同时出现在与不同规则相对应的评估运算符的多个并行实例上,因此需要进行分叉。用 DynamicKeyFunction()来确保此类事件的分派。
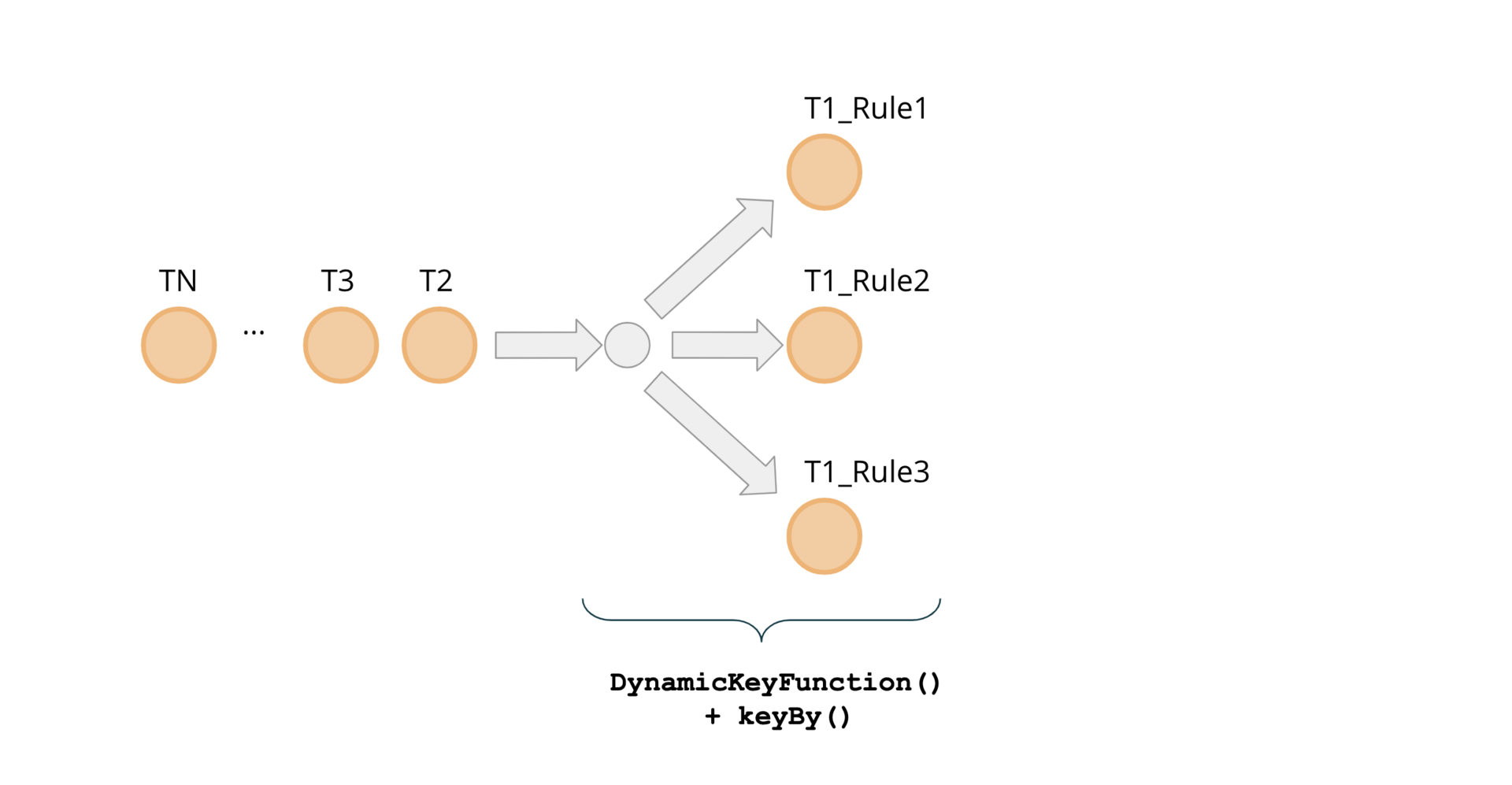
图 3:具有动态 Key 函数的分叉事件
DynamicKeyFunction 迭代一组已定义的规则,并提取所需的分组 key 来为每个要由 keyBy()函数处理的事件作准备:
KeysExtractor.getKey()使用反射来从事件中提取 groupingKeyNames 字段的必需值,并将它们组合为单个串联的字符串 key,例如“ {beneficiaryId = 25; payeeId = 12}”。Flink 将计算该 key 的哈希值,并将此特定组合的处理分配给集群中的特定服务器。这将跟踪 25 号付款人和 12 号收款人之间的所有交易,并在期望的时间窗口内评估定义的规则。
注意,这里引入了具有以下签名的包装类 Keyed,作为 DynamicKeyFunction 的输出类型
该 POJO 的字段包含以下信息:wrapped 是原始交易事件,key 是使用 KeysExtractor 的结果,id 是导致事件分配的 Rule 的 ID(根据特定于规则的分组逻辑)。
这种类型的事件将成为主处理管道中 keyBy()函数的输入,并允许在实现动态数据混排的最后步骤中使用一个简单的 lambda 表达式作为一个(KeySelector)。
有了 DynamicKeyFunction,我们可以隐式复制事件,以便在 Flink 集群中并行执行各条规则评估。这样一来,我们获得了一个重要的属性——规则处理的水平可扩展性。我们的系统将能够通过向集群添加更多服务器来处理更多规则,也就是提高并行度。实现此属性的代价是重复数据,这可能会成为一个问题,具体取决于特定的参数集,例如传入数据速率、可用网络带宽和事件负载大小等。在实际场景中可以应用其他优化,例如合并具有相同 groupingKeyNames 的规则评估,或添加一个过滤层,以在处理特定规则时剥离所有字段中不需要的事件。
结束语
在这篇博文中,我们用一个示例用例(欺诈检测引擎)讨论了对 Flink 应用程序提供动态运行时更改能力的原因。我们描述了整体架构及其组件之间的交互,并提供了在 dockerized 设置中构建和运行示例欺诈检测应用程序的指引。然后,我们展示了将动态数据分区模式实现为第一个基础构建块以实现灵活的运行时配置的细节操作。
为了将重心放在描述模式的核心机制上,我们将 DSL 和基础规则引擎的复杂性降到了最低。走下去的话,不难想象我们会添加一些扩展,例如允许使用更复杂的规则定义,包括某些事件的过滤、逻辑规则链接以及其他更高级的功能。
在本系列的第二部分中,我们将描述规则如何进入正在运行的欺诈检测引擎。此外,我们将详细介绍管道的主要处理函数——DynamicAlertFunction()的实现细节。
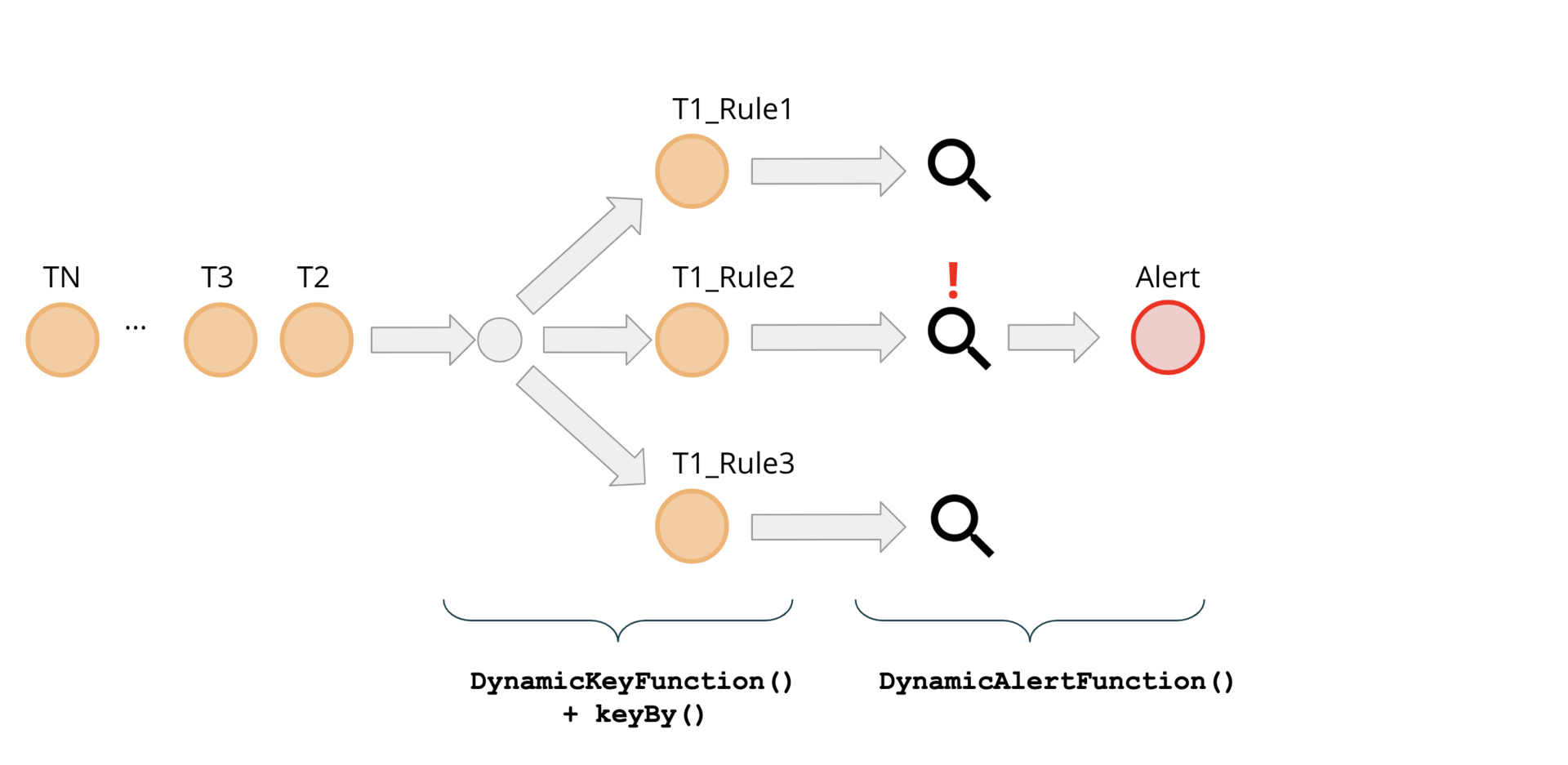
图 4:端到端管道
在下一篇文章中,我们将看到如何在运行时利用 Flink 的广播流来帮助指导欺诈检测引擎中的处理(动态应用程序更新模式)。
原文链接:
https://flink.apache.org/news/2020/01/15/demo-fraud-detection.html

极客邦科技 总编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论