

一、 前言
时间序列分析是统计学科的一个重要分支。它主要是通过研究随着时间的推移事物发展变化过程中的规律,来进行事物未来发展情况的预测。在我们的日常生活中,股票的价格走势,奶茶店每天的销售额,一年的降雨量分布,河水四季的涨落情况等都属于时间序列。时间序列的分析深入诸多行业。
时间序列的分类:
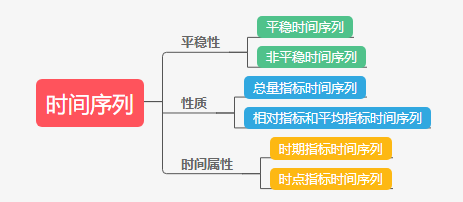
图 1
根据指标的平稳性,分为平稳时间序列和非平稳时间序列;
根据指标的性质分类,分为总量指标时间序列,相对指标和平均指标时间序列;
根据指标的时间属性分类,分为时期指标时间序列,时点指标时间序列;
时期指标时间序列是可以相加的,并且相加是有意义的,比如每天的订单量,一个月的订单量直接将这个月对应的每天的订单量相加即可。时点指标时间序列是不可以相加的,反映的是某一时间点达到的水平,比如每天库存量,库存量相加是没有统计意义的,每月总库存量不等于每天库存量加和。
对于互联网公司而言,业务量是公司经营关注的重要指标之一。实际情况的复杂性给业务量的分析预测带来了许多挑战:
具有业务特征的周期性影响
节假日等特定时序节点的变异
地域差异,空间的相互作用
受到库存、实际市场容量的影响
其他外生变量,不可控自然或社会因素
对于时间序列的分析,例如订单量,话务量,库存管理等,实现的方式有ANN,RNN,LR,ARIMA,Prophet等,这里我们重点关注ARIMA分析方法。
二、 时间序列分析实践
2.1 ARIMA模型简介
ARMA模型的全称是自回归移动平均模型,可以说是目前最常用的拟合平稳序列的模型。
ARMA模型由两部分组成:
p阶自回归模型AR§
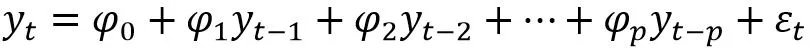
当 时,自回归模型又称为中心化AR§模型。非中心化的AR§序列也可以转化(通过平移)为中心化的AR§模型。
AR模型将某时刻t的值用过去若干时刻t-1到t-p的值通过线性组合以及噪声来表示。
q阶移动平均模型MA(q)
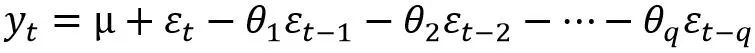
当 时,模型MA(q)称为中心化MA(q)模型,对于非中心化的MA(q)模型只要做简单的位移就可以转化为中心化的MA(q)模型。
MA模型是通过历史点的噪声线性组合来表示当前时刻的值。
ARMA模型其实就是AR§和MA(q)的组合:
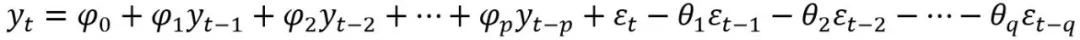
同样的,当 时该模型称为中心化的ARMA(p,q)模型。他结合了两个模型的特点,AR模型处理当前数据与后期数据之间的关系,MA则处理随机变动的影响。
对于平稳时间序列可以采用ARMA模型直接进行拟合,但是实际场景中,我们的时间序列都是有趋势的,即一般时序为非平稳的,所以需要做平稳处理,其中最常用的是差分处理,使得时序平稳后进行ARMA分析。
这一过程其实就是ARIMA,在原始非平稳时间序列基础上做一阶或二阶差分处理后的平稳时间序列上应用ARMA模型。ARIMA(p,d,q)模型是在ARMA(p,q)两元组阶数基础上增加差分d的三元组阶数模型。
2.2 ARIMA模型实践分析步骤
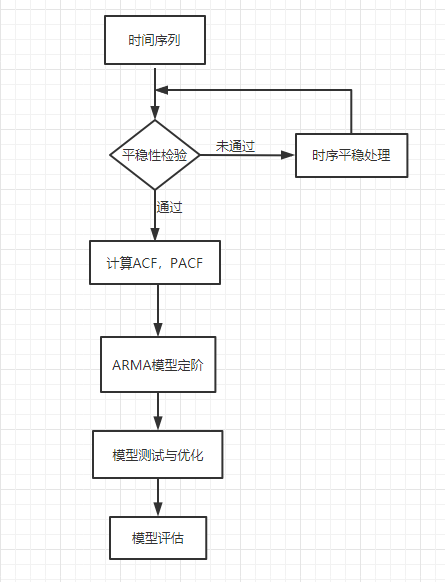
图2
具体实现以python为例。
Step1、读取时间序列
df = pd.read_csv('testdata.csv', encoding='gbk', index_col='ddate')
#时间序列索引转换为日期格式
df.index = pd.to_datetime(df.index)
#指标量转为float类型
df['cnt'] = df['cnt'].astype(float)
plt.figure(facecolor='white',figsize=(20,8))
plt.plot(df.index,df['cnt'],label='Time Series')
plt.legend(loc='best')
plt.show()
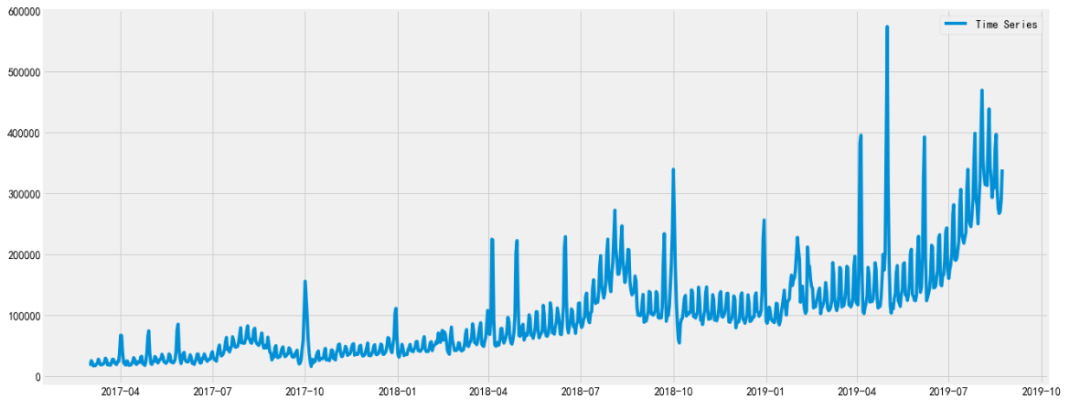
图3
Step2、时间序列平稳性检验
什么是平稳?
平稳分为严平稳和宽平稳,严平稳保证时间序列的任何有限维分布对于时间的平移是不变的,比如高斯白噪声就是严平稳序列;宽平稳则要求协方差结构随时间的平移而不变,或均值和方差是不变的。
为什么需要平稳?
ARIMA包含了AR模型,AR模型的实质是用历史时间点数据预测当前时间点对应的值。这就要求序列的相关性不会随着时间变化而变化。
from statsmodels.tsa.stattools import adfuller
def test_stationarity(timeseries):
dftest = adfuller(timeseries, autolag='AIC')
return dftest[1]
原始时间序列平稳性检验未通过(0.94)。从图3也可以看到,时间序列具有明显的上升趋势,所以需要尝试对时间序列进行差分处理,再次检验其平稳性。
Step3、差分处理后检验平稳性
pred_day = 7
train_start = datetime(2017,3,1)
train_end = datetime(2019,8,16)
pred_start = train_end+timedelta(1)
pred_end = train_end+timedelta(pred_day)
train_diff=df[train_start:train_end]
train_diff['cnt']=train_diff.diff()
print(test_stationarity(train_diff['cnt'][train_start+timedelta(1):train_end]))
plt.figure(facecolor='white',figsize=(20,8))
plt.plot(train_diff.index,train_diff['cnt'],label='Time Series after diff')
plt.legend(loc='best')
plt.show()
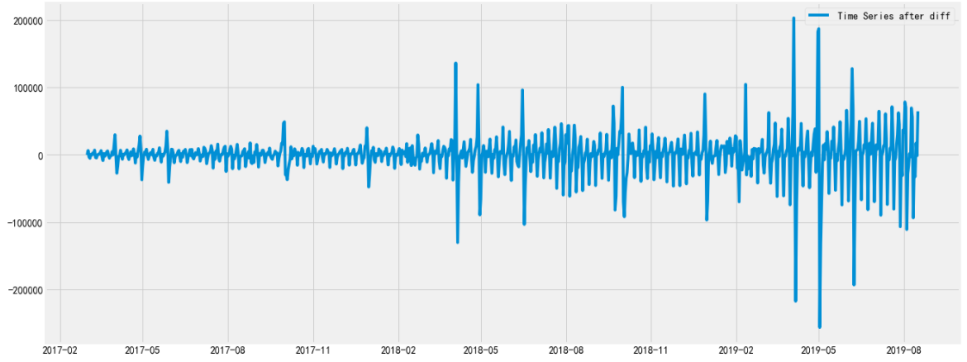
图4
差分后的时序平稳性检验值9.51*e(-15),说明差分后时序已经是平稳时间序列了,可以应用ARIMA模型。
Step4、画出ACF和PACF图
自相关函数ACF,反映了两个点之间的相关性。
偏自相关函数PACF则是排除了两点之间其他点的影响,反应两点之间的相关性。比如:在AR(2)中,即使y(t-3)没有直接出现在模型中,但是y(t)和y(t-3)之间也相关。
import statsmodels.api as sm
fig = plt.figure(figsize=(12,8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(train_diff['cnt'][1:], lags=20, ax=ax1)
ax1.xaxis.set_ticks_position('bottom')
fig.tight_layout()
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(train_diff['cnt'][1:], lags=20, ax=ax2)
ax2.xaxis.set_ticks_position('bottom')
fig.tight_layout()
plt.show()
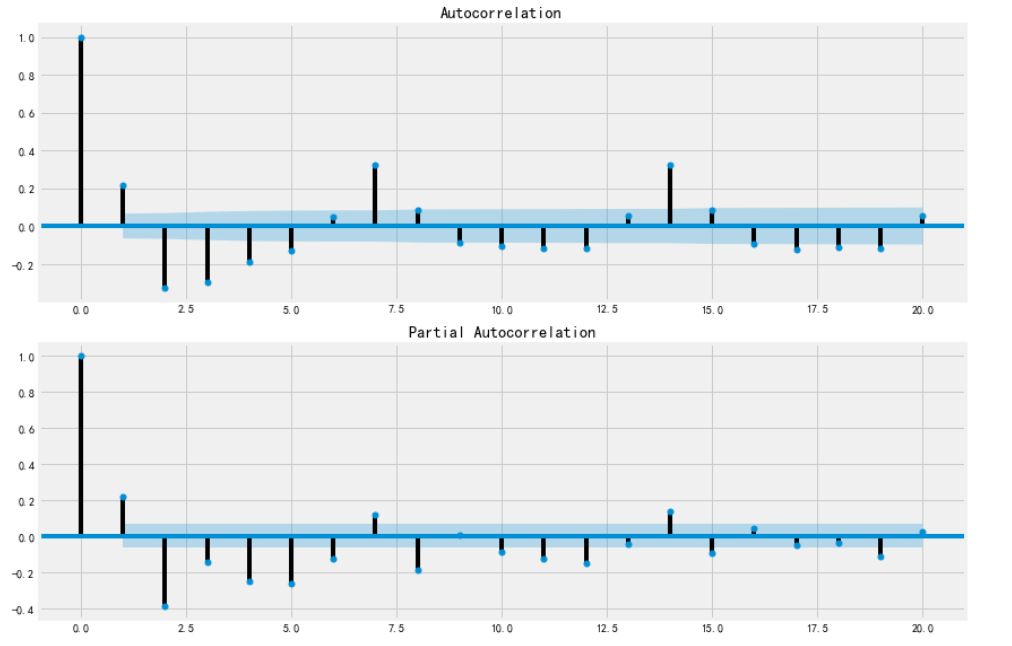
图5
严格来看,ACF和PACF显示存在一定程度的拖尾和振荡。但是,ACF和PACF在3阶后有骤降和平稳的趋势,考虑到是短期预测的场景,可进一步结合预测效果和模型检验来进行判断。
Step5、ARIMA模型定阶
虽然ACF和PACF为我们提供了选择模型参数的参考依据,但是一般实际情况中,我们总会需要通过模型训练效果确定最终采用的参数值。在ARMA模型中,我们通常采用AIC法则(赤池信息准则,AIC=2k-2ln(L),k为模型参数个数,n为样本数量,L为似然函数)。AIC鼓励数据拟合的有良性但是尽量避免出现过拟合的情况。所以实际操作中,我们会选择模型AIC值最小的那组参数。
#定阶
warnings.filterwarnings("ignore") # specify to ignore warning messages
pmax = 8
qmax = 8
aic_matrix = [] #aic矩阵
for p in range(1,pmax+1):
tmp = []
for q in range(1,qmax+1):
try: #存在部分报错,所以用try来跳过报错。
model = ARIMA(endog=df['cnt'],order=(p,1,q))
results = model.fit(disp=-1)
tmp.append(results.aic)
print('ARIMA p:{} q:{} - AIC:{}'.format(p, q, results.aic))
except:
tmp.append(None)
aic_matrix.append(tmp)
aic_matrix = pd.DataFrame(aic_matrix) #从中可以找出最小值
p,q = aic_matrix.stack().idxmin() #先用stack展平,然后用idxmin找出最小值位置。
print(u'AIC最小的p值和q值为:%s、%s' %(p+1,q+1))

图6
由于时间序列为1阶差分平稳时间序列,所以模型参数d=1,根据AIC最小原则得到p=7,q=7。
Step6、模型测试与优化
将训练得到的参数加入模型,分析模型效果。
model = ARIMA(endog=df['cnt'], order=(p,1,q)) #建立ARIMA(7, 1,7)模型
result_ARIMA = model.fit(disp=-1,method='css')
predict_diff=result_ARIMA.predict()
#一阶差分还原
df_shift=df['cnt'].shift(1)
predict=predict_diff+df_shift
plt.figure(figsize=(18,5),facecolor='white')
predict[train_start+timedelta(p+1):train_end].plot(color='blue', label='Predict')
df['cnt'][train_start+timedelta(p+1):train_end].plot(color='red', label='Original')
err=sum(np.sqrt((predict[train_start+timedelta(p+1):train_end]-df['cnt'][train_start+timedelta(p+1):train_end])**2)/df['cnt'][train_start+timedelta(p+1):train_end])/df['cnt'][train_start+timedelta(p+1):train_end].size
plt.legend(loc='best')
plt.title('Error: %.4f'%err)
plt.show()
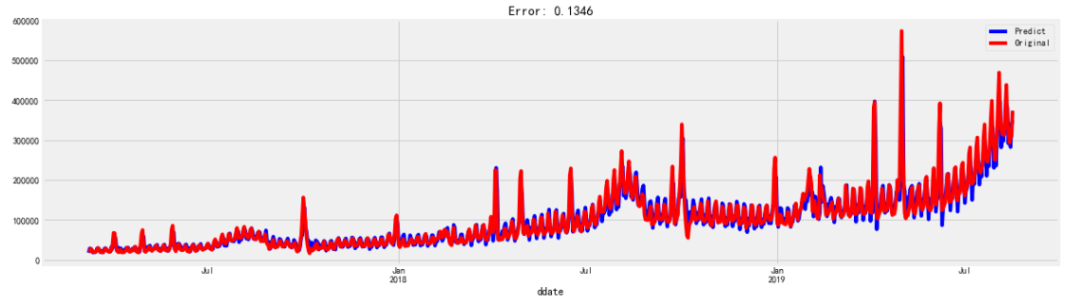
图7
用训练好的模型进行未来预测。
y_forecasted =result_ARIMA.forecast(steps=pred_day, alpha=0.01)[0] #作为期7天的预测
y_truth = df[pred_start:pred_end]['cnt']
# 均方根误差 #平均错误率
mse = np.sqrt( ((y_forecasted - y_truth) ** 2) ).mean()
error_rate = ( abs(y_forecasted - y_truth)/y_truth ).mean()
print('\nThe Mean Error rate of our forecasts is {}'.format(round(error_rate, 4)))
模型预测误差8.58%(【偏差/真实值】的均值),结果并不是太理想,所以我们需要对模型进行优化,考虑是因为指标受到了节假日和周的影响,所以在模型的外生变量里面我们加入节假日和周的识别参数。
加入exog外生变量后,需要重新定阶,重新训练模型,步骤与上类似。优化后的预测误差1.77%,相比之前有了很大程度的提升。
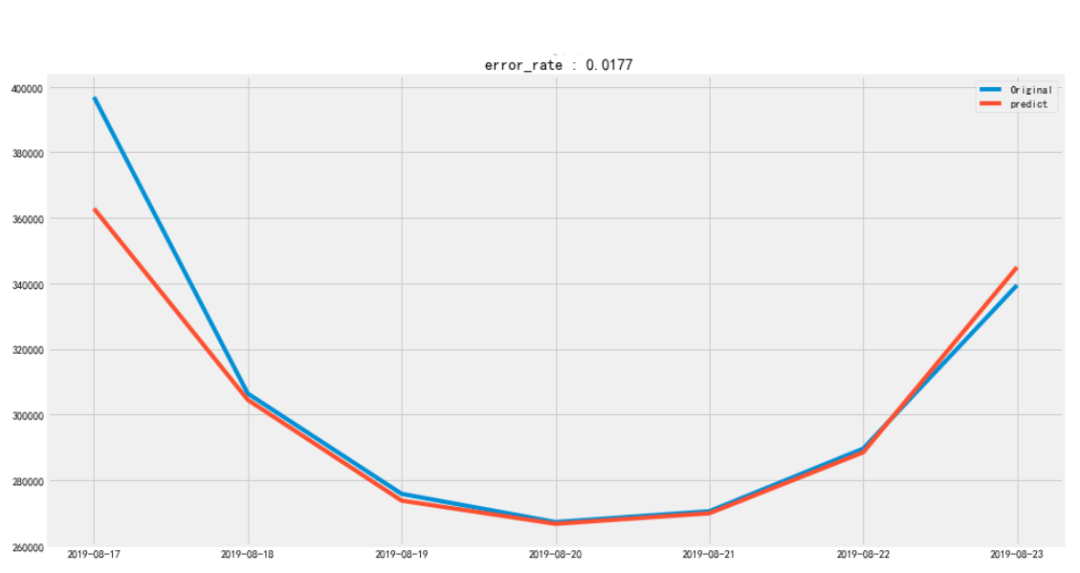
图8
Step7、模型检验
用模型残差来检验模型的合理性。
resid = result_ARIMA_improve.resid #赋值
plt.figure(figsize=(12,8))
qqplot(resid,line='q',fit=True)
#利用D-W检验,检验残差的自相关性
print('D-W检验值为{}'.format(durbin_watson(resid.values)))
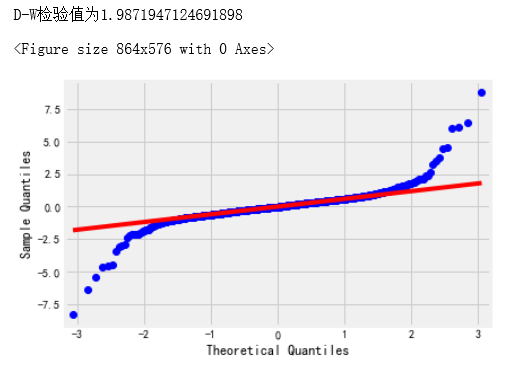
图9
通过图9的qq图可以看出,残差基本满足了正态分布。D-W检验结果值为1.99,接近于2,说明残差序列不存在自相关性,即模型较好。
三、总结与展望
对于时间序列的分析一定做好前期评估工作,直观的图表分析会助力我们的决策。多探索优秀的开源工具库,往往会使我们事半功倍。
模型选择至关重要,明确模型的适用场景,根据自身的时序选择适合的模型分析。
ARIMA模型在短时间内的预期效果还算可以,但是长时间比如未来一年的预测不太适用,因为偏差会逐渐增大。
现实中的复杂场景,单一模型很难解决,需要考虑多模型结合的方式实现分析预测。
作者介绍:
June,携程数据分析经理,对数仓搭建,数据治理,数据分析等方面有较浓厚的兴趣。
本文转载自公众号携程技术(ID:ctriptech)。
原文链接:

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论