
【编者按】Mesos 是 Apache 下的开源分布式资源管理框架,它被称为是分布式系统的内核。Mesos 最初是由加州大学伯克利分校的 AMPLab 开发的,后在 Twitter 得到广泛使用。InfoQ 接下来将会策划系列文章来为读者剖析 Mesos。本文是整个系列的第一篇,简单介绍了 Mesos 的背景、历史以及架构。
注:本文翻译自 Cloud Architect Musings ,InfoQ 中文站在获得作者授权的基础上对文章进行了翻译。
在深入浅出 Mesos 系列的第一篇文章中,我对相关的技术做了简要概述,在第二篇文章中,我深入介绍了 Mesos 的架构。完成第二篇文章之后,我本想开始着手写一篇 Mesos 如何处理资源分配的文章。不过,我收到一些读者的反馈,于是决定在谈资源分配之前,先完成这篇关于 Mesos 持久化存储和容错的文章。
持久化存储的问题
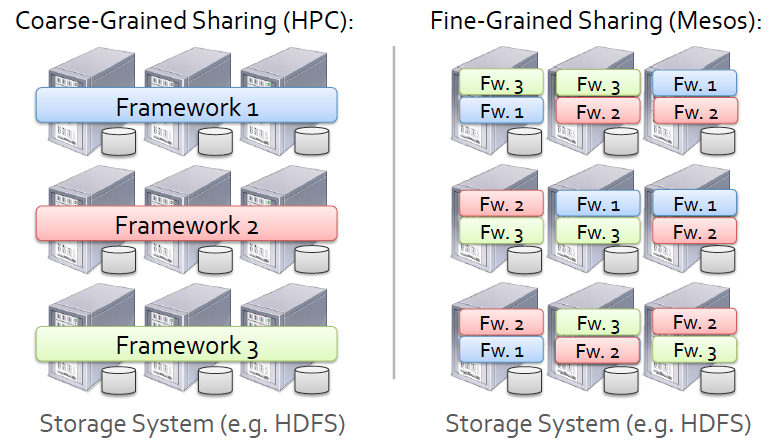
正如我在前文中讨论过的,使用 Mesos 的主要好处是可以在同一组计算节点集合上运行多种类型的应用程序(调度以及通过 Framework 初始化任务)。这些任务使用隔离模块(目前是某些类型的容器技术)从实际节点中抽象出来,以便它们可以根据需要在不同的节点上移动和重新启动。
由此我们会思考一个问题,Mesos 是如何处理持久化存储的呢?如果我在运行一个数据库作业,Mesos 如何确保当任务被调度时,分配的节点可以访问其所需的数据?如图所示,在 Hindman 的示例中,使用 Hadoop 文件系统(HDFS)作为 Mesos 的持久层,这是 HDFS 常见的使用方式,也是 Mesos 的执行器传递分配指定任务的配置数据给 Slave 经常使用的方式。实际上,Mesos 的持久化存储可以使用多种类型的文件系统,HDFS 只是其中之一,但也是 Mesos 最经常使用的,它使得 Mesos 具备了与高性能计算的亲缘关系。其实 Mesos 可以有多种选择来处理持久化存储的问题:
-
分布式文件系统。如上所述,Mesos 可以使用 DFS(比如 HDFS 或者 Lustre)来保证数据可以被 Mesos 集群中的每个节点访问。这种方式的缺点是会有网络延迟,对于某些应用程序来说,这样的网络文件系统或许并不适合。
-
使用数据存储复制的本地文件系统。另一种方法是利用应用程序级别的复制来确保数据可被多个节点访问。提供数据存储复制的应用程序可以是 NoSQL 数据库,比如 Cassandra 和 MongoDB。这种方式的优点是不再需要考虑网络延迟问题。缺点是必须配置 Mesos,使特定的任务只运行在持有复制数据的节点上,因为你不会希望数据中心的所有节点都复制相同的数据。为此,可以使用一个 Framework,静态地为其预留特定的节点作为复制数据的存储。
-
不使用复制的本地文件系统。也可以将持久化数据存储在指定节点的文件系统上,并且将该节点预留给指定的应用程序。和前面的选择一样,可以静态地为指定应用程序预留节点,但此时只能预留给单个节点而不是节点集合。后面两种显然不是理想的选择,因为实质上都需要创建静态分区。然而,在不允许延时或者应用程序不能复制它的数据存储等特殊情况下,我们需要这样的选择。
Mesos 项目还在发展中,它会定期增加新功能。现在我已经发现了两个可以帮助解决持久化存储问题的新特性:
- 动态预留。Framework 可以使用这个功能框架保留指定的资源,比如持久化存储,以便在需要启动另一个任务时,资源邀约只会发送给那个 Framework。这可以在单节点和节点集合中结合使用 Framework 配置,访问永久化数据存储。关于这个建议的功能的更多信息可以从此处获得。
- 持久化卷。该功能可以创建一个卷,作为 Slave 节点上任务的一部分被启动,即使在任务完成后其持久化依然存在。Mesos 为需要访问相同的数据后续任务,提供在可以访问该持久化卷的节点集合上相同的 Framework 来初始化。关于这个建议的功能的更多信息可以从此处获得。
容错
接下来,我们来谈谈 Mesos 在其协议栈上是如何提供容错能力的。恕我直言,Mesos 的优势之一便是将容错设计到架构之中,并以可扩展的分布式系统的方式来实现。
-
Master。故障处理机制和特定的架构设计实现了 Master 的容错。
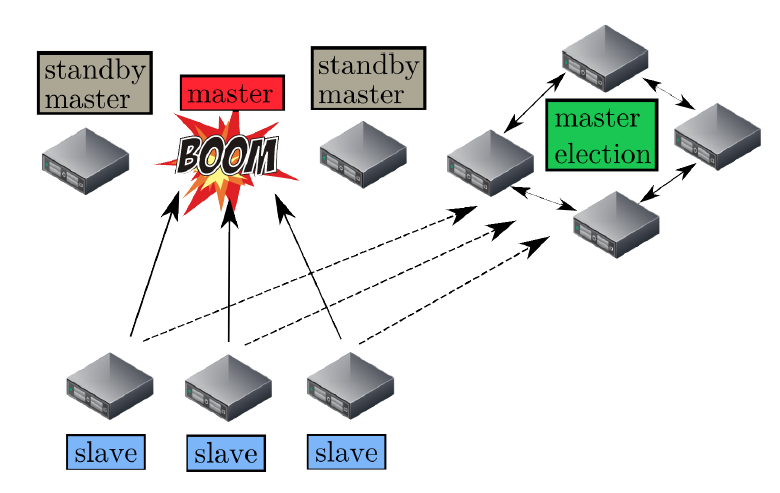
首先,Mesos 决定使用热备份(hot-standby)设计来实现 Master 节点集合。正如 Tomas Barton 对上图的说明,一个 Master 节点与多个备用(standby)节点运行在同一集群中,并由开源软件 Zookeeper 来监控。Zookeeper 会监控 Master 集群中所有的节点,并在 Master 节点发生故障时管理新 Master 的选举。建议的节点总数是 5 个,实际上,生产环境至少需要 3 个 Master 节点。 Mesos 决定将 Master 设计为持有软件状态,这意味着当 Master 节点发生故障时,其状态可以很快地在新选举的 Master 节点上重建。 Mesos 的状态信息实际上驻留在 Framework 调度器和 Slave 节点集合之中。当一个新的 Master 当选后,Zookeeper 会通知 Framework 和选举后的 Slave 节点集合,以便使其在新的 Master 上注册。彼时,新的 Master 可以根据 Framework 和 Slave 节点集合发送过来的信息,重建内部状态。
-
Framework 调度器。Framework 调度器的容错是通过 Framework 将调度器注册 2 份或者更多份到 Master 来实现。当一个调度器发生故障时,Master 会通知另一个调度来接管。需要注意的是 Framework 自身负责实现调度器之间共享状态的机制。
-
Slave。Mesos 实现了 Slave 的恢复功能,当 Slave 节点上的进程失败时,可以让执行器 / 任务继续运行,并为那个 Slave 进程重新连接那台 Slave 节点上运行的执行器 / 任务。当任务执行时,Slave 会将任务的监测点元数据存入本地磁盘。如果 Slave 进程失败,任务会继续运行,当 Master 重新启动 Slave 进程后,因为此时没有可以响应的消息,所以重新启动的 Slave 进程会使用检查点数据来恢复状态,并重新与执行器 / 任务连接。
如下情况则截然不同,计算节点上 Slave 正常运行而任务执行失败。在此,Master 负责监控所有 Slave 节点的状态。
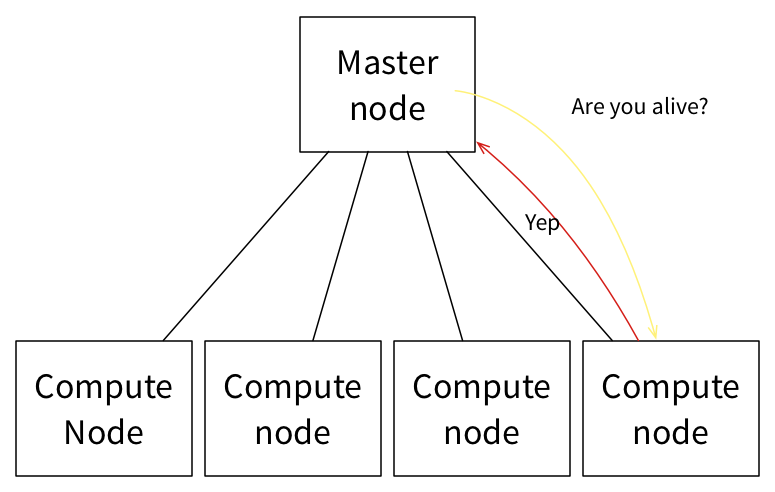
当计算节点 /Slave 节点无法响应多个连续的消息后,Master 会从可用资源的列表中删除该节点,并会尝试关闭该节点。
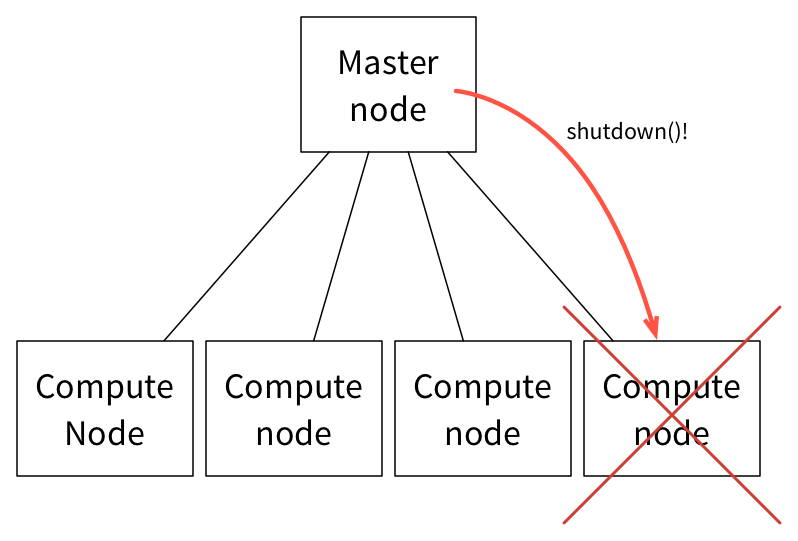
然后,Master 会向分配任务的 Framework 调度器汇报执行器 / 任务失败,并允许调度器根据其配置策略做任务失败处理。通常情况下,Framework 会重新启动任务到新的 Slave 节点,假设它接收并接受来自 Master 的相应的资源邀约。
- 执行器 / 任务。与计算节点 /Slave 节点故障类似,Master 会向分配任务的 Framework 调度器汇报执行器 / 任务失败,并允许调度器根据其配置策略在任务失败时做出相应的处理。通常情况下,Framework 在接收并接受来自 Master 的相应的资源邀约后,会在新的 Slave 节点上重新启动任务。
结论
在接下来的文章中,我将更深入到资源分配模块。同时,我非常期待读者的反馈,特别是关于如果我打标的地方,如果你发现哪里不对,请反馈给我。我非全知,虚心求教,所以期待读者的校正和启示。我也会在 twitter 响应你的反馈,请关注 @hui_kenneth。
查看英文原文: DEALING WITH PERSISTENT STORAGE AND FAULT TOLERANCE IN APACHE MESOS
感谢郭蕾对本文的策划和审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 )。
)。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论