

前言
近期公司内部将 Flink Job 从 Standalone 迁移至了 OnYarn,随后发现 Job 性能较之前有所降低:迁移前有 8.3W+/S 的数据消费速度,迁移到 Yarn 后分配同样的资源但消费速度降为 7.8W+/S,且较之前的消费速度有轻微的抖动。经过原因分析和测试验证,最终采用了在保持分配给 Job 的资源不变的情况下将总 Container 数量减半、每个 Container 持有的资源从 1C2G 1Slot 变更为 2C4G 2Slot 的方式,使该问题得以解决。
经历该问题后,发现深入理解 Slot 和 Flink Runtime Graph 是十分必要的,于是撰写了这篇文章。本文内容分为两大部分,第一部分详细的分析 Flink Slot 与 Job 运行的关系,第二部详细的介绍遇到的问题和解决方案。
Flink Slot
Flink 集群是由 JobManager(JM)、TaskManager(TM)两大组件组成的,每个 JM/TM 都是运行在一个独立的 JVM 进程中。JM 相当于 Master,是集群的管理节点,TM 相当于 Worker,是集群的工作节点,每个 TM 最少持有 1 个 Slot,Slot 是 Flink 执行 Job 时的最小资源分配单位,在 Slot 中运行着具体的 Task 任务。
对 TM 而言:它占用着一定数量的 CPU 和 Memory 资源,具体可通过 taskmanager.numberOfTaskSlots, taskmanager.heap.size 来配置,实际上 taskmanager.numberOfTaskSlots 只是指定 TM 的 Slot 数量,并不能隔离指定数量的 CPU 给 TM 使用。在不考虑 Slot Sharing(下文详述)的情况下,一个 Slot 内运行着一个 SubTask(Task 实现 Runable,SubTask 是一个执行 Task 的具体实例),所以官方建议 taskmanager.numberOfTaskSlots 配置的 Slot 数量和 CPU 相等或成比例。
当然,我们可以借助 Yarn 等调度系统,用 Flink On Yarn 的模式来为 Yarn Container 分配指定数量的 CPU 资源,以达到较严格的 CPU 隔离(Yarn 采用 Cgroup 做基于时间片的资源调度,每个 Container 内运行着一个 JM/TM 实例)。而 taskmanager.heap.size 用来配置 TM 的 Memory,如果一个 TM 有 N 个 Slot,则每个 Slot 分配到的 Memory 大小为整个 TM Memory 的 1/N,同一个 TM 内的 Slots 只有 Memory 隔离,CPU 是共享的。
对 Job 而言:一个 Job 所需的 Slot 数量大于等于 Operator 配置的最大 Parallelism 数,在保持所有 Operator 的 slotSharingGroup 一致的前提下 Job 所需的 Slot 数量与 Job 中 Operator 配置的最大 Parallelism 相等。
关于 TM/Slot 之间的关系可以参考如下从官方文档截取到的三张图:
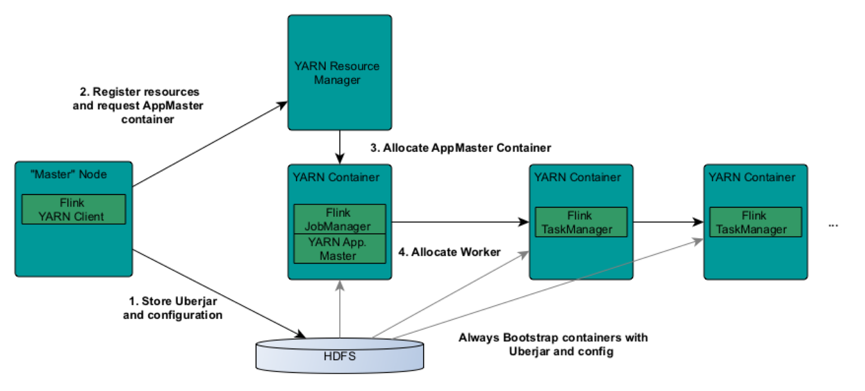
图一: Flink On Yarn 的 Job 提交过程,从图中我们可以了解到每个 JM/TM 实例都分属于不同的 Yarn Container,且每个 Container 内只会有一个 JM 或 TM 实例;通过对 Yarn 的学习我们可以了解到,每个 Container 都是一个独立的进程,一台物理机可以有多个 Container 存在(多个进程),每个 Container 都持有一定数量的 CPU 和 Memory 资源,而且是资源隔离的,进程间不共享,这就可以保证同一台机器上的多个 TM 之间是资源隔离的(Standalone 模式下,同一台机器下若有多个 TM,是做不到 TM 之间的 CPU 资源隔离的)。
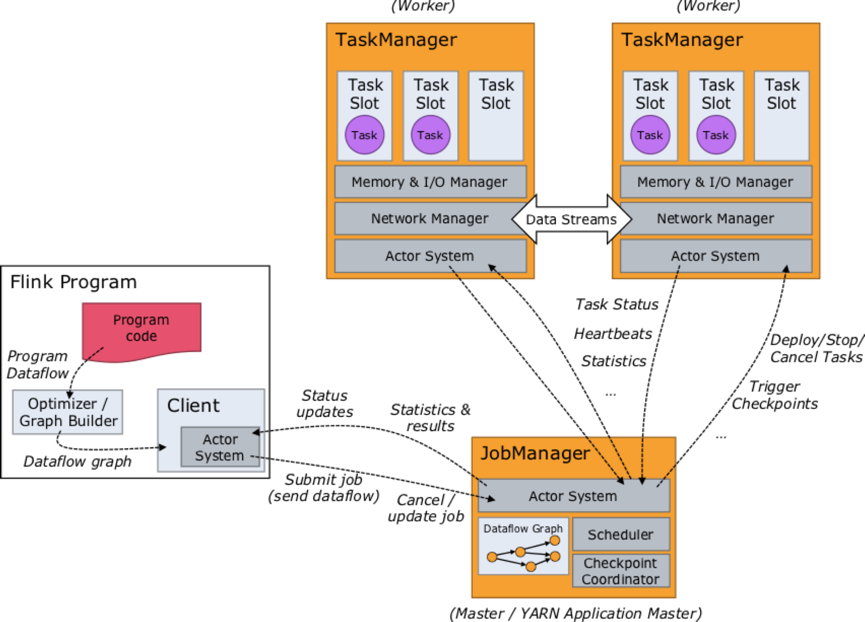
图二: Flink Job 运行图,图中有两个 TM,各自有 3 个 Slot,2 个 Slot 内有 Task 在执行,1 个 Slot 空闲。若这两个 TM 在不同 Container 或容器上,则其占用的资源是互相隔离的。在 TM 内多个 Slot 间是各自拥有 1/3 TM 的 Memory,共享 TM 的 CPU、网络(Tcp:ZK、 Akka、Netty 服务等)、心跳信息、Flink 结构化的数据集等。
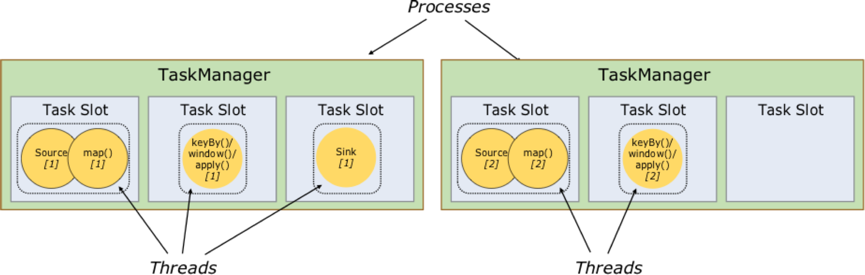
图三: Task Slot 的内部结构图,Slot 内运行着具体的 Task,它是在线程中执行的 Runable 对象(每个虚线框代表一个线程),这些 Task 实例在源码中对应的类是 org.apache.flink.runtime.taskmanager.Task。每个 Task 都是由一组 Operators Chaining 在一起的工作集合,Flink Job 的执行过程可看作一张 DAG 图,Task 是 DAG 图上的顶点(Vertex),顶点之间通过数据传递方式相互链接构成整个 Job 的 Execution Graph。
Operator Chain
Operator Chain 是指将 Job 中的 Operators 按照一定策略(例如: single output operator 可以 chain 在一起)链接起来并放置在一个 Task 线程中执行。Operator Chain 默认开启,可通过 StreamExecutionEnvironment.disableOperatorChaining()关闭,Flink Operator 类似 Storm 中的 Bolt,在 Strom 中上游 Bolt 到下游会经过网络上的数据传递,而 Flink 的 Operator Chain 将多个 Operator 链接到一起执行,减少了数据传递/线程切换等环节,降低系统开销的同时增加了资源利用率和 Job 性能。实际开发过程中需要开发者了解这些原理,并能合理分配 Memory 和 CPU 给到每个 Task 线程。
注: 【一个需要注意的地方】Chained 的 Operators 之间的数据传递默认需要经过数据的拷贝(例如:kryo.copy(…)),将上游 Operator 的输出序列化出一个新对象并传递给下游 Operator,可以通过 ExecutionConfig.enableObjectReuse()开启对象重用,这样就关闭了这层 copy 操作,可以减少对象序列化开销和 GC 压力等,具体源码可阅读 org.apache.flink.streaming.runtime.tasks.OperatorChain 与 org.apache.flink.streaming.runtime.tasks.OperatorChain.CopyingChainingOutput。官方建议开发人员在完全了解 reuse 内部机制后才使用该功能,冒然使用可能会给程序带来 bug。
Operator Chain 效果可参考如下官方文档截图:
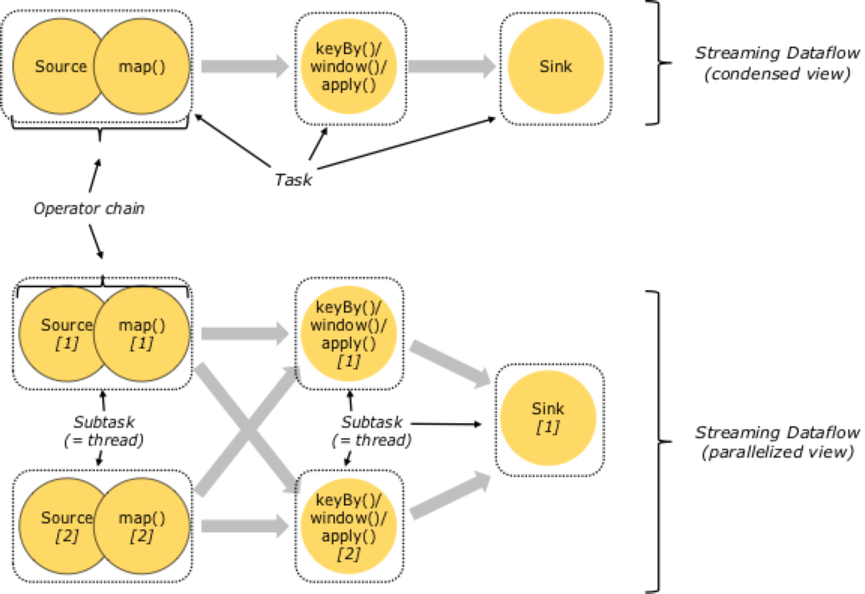
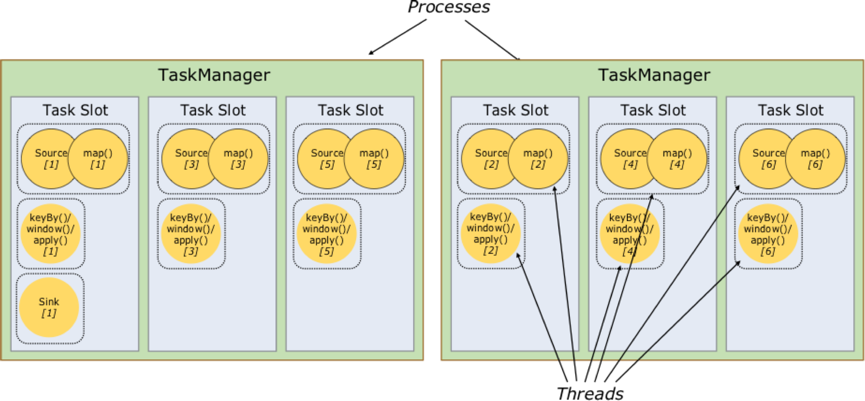
图四: 图的上半部分是 StreamGraph 视角,有 Task 类别无并行度,如图:Job Runtime 时有三种类型的 Task,分别是 Source->Map、keyBy/window/apply、Sink,其中 Source->Map 是 Source()和 Map()chaining 在一起的 Task;图的下半部分是一个 Job Runtime 期的实际状态,Job 最大的并行度为 2,有 5 个 SubTask(即 5 个执行线程)。若没有 Operator Chain,则 Source()和 Map()分属不同的 Thread,Task 线程数会增加到 7,线程切换和数据传递开销等较之前有所增加,处理延迟和性能会较之前差。补充:在 slotSharingGroup 用默认或相同组名时,当前 Job 运行需 2 个 Slot(与 Job 最大 Parallelism 相等)。
Slot Sharing
Slot Sharing 是指,来自同一个 Job 且拥有相同 slotSharingGroup(默认:default)名称的不同 Task 的 SubTask 之间可以共享一个 Slot,这使得一个 Slot 有机会持有 Job 的一整条 Pipeline,这也是上文提到的在默认 slotSharing 的条件下 Job 启动所需的 Slot 数和 Job 中 Operator 的最大 parallelism 相等的原因。通过 Slot Sharing 机制可以更进一步提高 Job 运行性能,在 Slot 数不变的情况下增加了 Operator 可设置的最大的并行度,让类似 window 这种消耗资源的 Task 以最大的并行度分布在不同 TM 上,同时像 map、filter 这种较简单的操作也不会独占 Slot 资源,降低资源浪费的可能性。
具体 Slot Sharing 效果可参考如下官方文档截图:
图五: 图的左下角是一个 soure-map-reduce 模型的 Job,source 和 map 是 4 parallelism,reduce 是 3 parallelism,总计 11 个 SubTask;这个 Job 最大 Parallelism 是 4,所以将这个 Job 发布到左侧上面的两个 TM 上时得到图右侧的运行图,一共占用四个 Slot,有三个 Slot 拥有完整的 source-map-reduce 模型的 Pipeline,如右侧图所示;注:map 的结果会 shuffle 到 reduce 端,右侧图的箭头只是说 Slot 内数据 Pipline,没画出 Job 的数据 shuffle 过程。
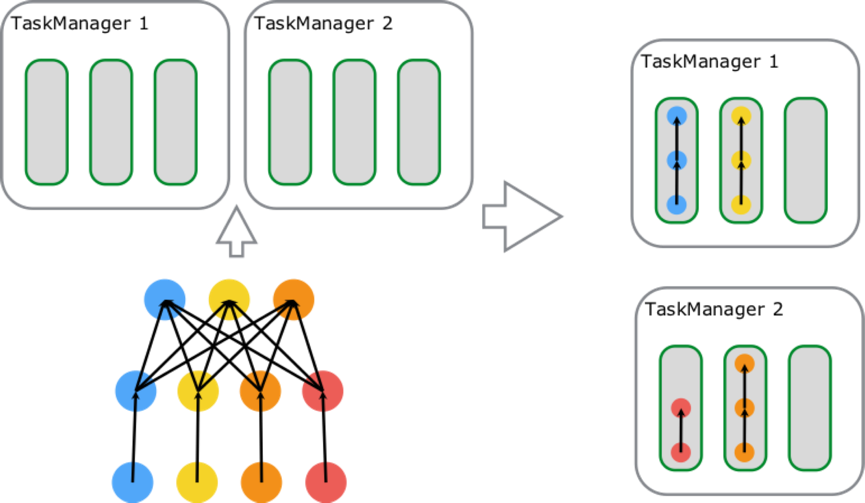
图六: 图中包含 source-map[6 parallelism]、keyBy/window/apply[6 parallelism]、sink[1 parallelism]三种 Task,总计占用了 6 个 Slot;由左向右开始第一个 slot 内部运行着 3 个 SubTask[3 Thread],持有 Job 的一条完整 pipeline;剩下 5 个 Slot 内分别运行着 2 个 SubTask[2 Thread],数据最终通过网络传递给 Sink 完成数据处理。
Operator Chain & Slot Sharing API
Flink 在默认情况下有策略对 Job 进行 Operator Chain 和 Slot Sharing 的控制,比如:将并行度相同且连续的 SingleOutputStreamOperator 操作 chain 在一起(chain 的条件较苛刻,不止单一输出这一条,具体可阅读 org.apache.flink.streaming.api.graph.StreamingJobGraphGenerator.isChainable(…)),Job 的所有 Task 都采用名为 default 的 slotSharingGroup 做 Slot Sharing。但在实际的需求场景中,我们可能会遇到需人为干预 Job 的 Operator Chain 或 Slot Sharing 策略的情况,本段就重点关注下用于改变默认 Chain 和 Sharing 策略的 API。
StreamExecutionEnvironment.disableOperatorChaining(): 关闭整个 Job 的 Operator Chain,每个 Operator 独自占有一个 Task,如上图四所描述的 Job,如果 disableOperatorChaining 则 source->map 会拆开为 source(), map()两种 Task,Job 实际的 Task 数会增加到 7。这个设置会降低 Job 性能,在非生产环境的测试或 profiling 时可以借助以更好分析问题,实际生产过程中不建议使用。
someStream.filter(…).map(…).startNewChain().map(): startNewChain()是指从当前 Operator[map]开始一个新的 chain,即:两个 map 会 chaining 在一起而 filter 不会(因为 startNewChain 的存在使得第一次 map 与 filter 断开了 chain)。
someStream.map(…).disableChaining(): disableChaining()是指当前 Operator[map]禁用 Operator Chain,即:Operator[map]会独自占用一个 Task。
someStream.map(…).slotSharingGroup(“name”): 默认情况下所有 Operator 的 slotGroup 都为 default,可以通过 slotSharingGroup()进行自定义,Flink 会将拥有相同 slotGroup 名称的 Operators 运行在相同 Slot 内,不同 slotGroup 名称的 Operators 运行在其他 Slot 内。
Operator Chain 有三种策略 ALWAYS、NEVER、HEAD,详细可查看 org.apache.flink.streaming.api.operators.ChainingStrategy。startNewChain()对应的策略是 ChainingStrategy.HEAD(StreamOperator 的默认策略),disableChaining()对应的策略是 ChainingStrategy.NEVER,ALWAYS 是尽可能的将 Operators chaining 在一起;在通常情况下 ALWAYS 是效率最高,很多 Operator 会将默认策略覆盖为 ALWAYS,如 filter、map、flatMap 等函数。
迁移 OnYarn 后 Job 性能下降的问题
JOB 说明:
类似 StreamETL,100 parallelism,即:一个流式的 ETL Job,不包含 window 等操作,Job 的并行度为 100;
环境说明:
Standalone 下的 Job Execution Graph:10TMs * 10Slots-per-TM ,即:Job 的 Task 运行在 10 个 TM 节点上,每个 TM 上占用 10 个 Slot,每个 Slot 可用 1C2G 资源,GCConf:-XX:+UseG1GC -XX:MaxGCPauseMillis=100;
OnYarn 下初始状态的 Job Execution Graph:100TMs * 1Slot-per-TM,即:Job 的 Task 运行在 100 个 Container 上,每个 Container 上的 TM 持有 1 个 Slot,每个 Container 分配 1C2G 资源,GCConf:-XX:+UseG1GC -XX:MaxGCPauseMillis=100;
OnYarn 下调整后的 Job Execution Graph:50TMs * 2Slot-per-TM,即:Job 的 Task 运行在 50 个 Container 上,每个 Container 上的 TM 持有 2 个 Slot,每个 Container 分配 2C4G 资源,GCConfig:-XX:+UseG1GC -XX:MaxGCPauseMillis=100;
注: OnYarn 下使用了与 Standalone 一致的 GC 配置,当前 Job 在 Standalone 或 OnYarn 环境中运行时,YGC、FGC 频率基本相同,OnYarn 下单个 Container 的堆内存较小使得单次 GC 耗时减少。生产环境中大家最好对比下 CMS 和 G1,选择更好的 GC 策略,当前上下文中暂时认为 GC 对 Job 性能影响可忽略不计。
问题分析:
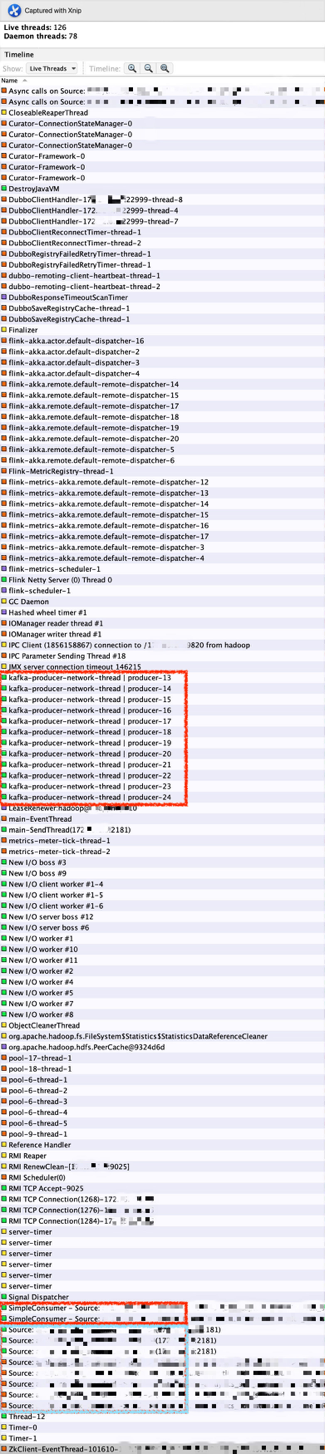
引起 Job 性能降低的原因不难定位,从这张 Container 的线程图(VisualVM 中的截图)可见:
图 7:在一个 1C2G 的 Container 内有 126 个活跃线程,守护线程 78 个。首先,在一个 1C2G 的 Container 中运行着 126 个活跃线程,频繁的线程切换是会经常出现的,这让本来就不充裕的 CPU 显得更加的匮乏。其次,真正与数据处理相关的线程是红色画笔圈出的 14 条线程(2 条 Kafka Partition Consumer、Consumers 和 Operators 包含在这个两个线程内;12 条 Kafka Producer 线程,将处理好的数据 sink 到 Kafka Topic),这 14 条线程之外的大多数线程在相同 TM、不同 Slot 间可以共用,比如:ZK-Curator、Dubbo-Client、GC-Thread、Flink-Akka、Flink-Netty、Flink-Metrics 等线程,完全可以通过增加 TM 下 Slot 数量达到多个 SubTask 共享的目的。
此时我们会很自然的得出一个解决办法:在 Job 使用资源不变的情况下,在减少 Container 数量的同时增加单个 Container 持有的 CPU、Memory、Slot 数量,比如上文环境说明中从方案 2 调整到方案 3,实际调整后的 Job 运行稳定了许多且消费速度与 Standalone 基本持平。
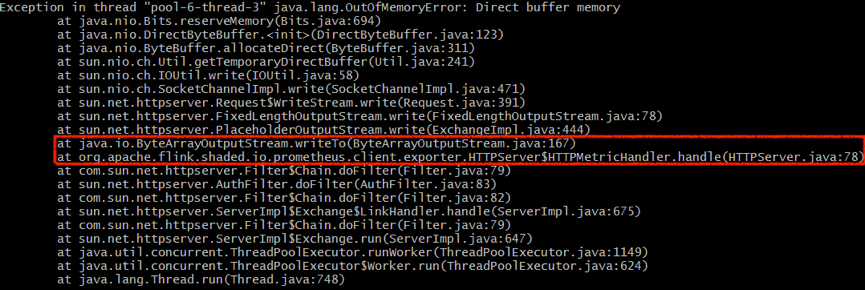
注: 当前问题是内部迁移类似 StreamETL 的 Job 时遇到的,解决方案简单但不具有普适性,对于带有 window 算子的 Job 需要更仔细缜密的问题分析。目前 Deploy 到 Yarn 集群的 Job 都配置了 JMX/Prometheus 两种监控,单个 Container 下 Slot 数量越多、每次 scrape 的数据越多,实际生成环境中需观测是否会影响 Job 正常运行,在测试时将 Container 配置为 3C6G 3Slot 时发现一次 java.lang.OutOfMemoryError: Direct buffer memory 的异常,初步判断与 Prometheus Client 相关,可适当调整 JVM 的 MaxDirectMemorySize 来解决。所出现异常如图 8:
总结
Operator Chain 是将多个 Operator 链接在一起放置在一个 Task 中,只针对 Operator;Slot Sharing 是在一个 Slot 中执行多个 Task,针对的是 Operator Chain 之后的 Task。这两种优化都充分利用了计算资源,减少了不必要的开销,提升了 Job 的运行性能。此外,Operator Chain 的源码在 streaming 包下,只在流处理任务中有这个机制;Slot Sharing 在 flink-runtime 包下,似乎应用更广泛一些(具体还有待考究)。
最后,只有充分的了解 Slot、Operator Chain、Slot Sharing 是什么,以及各自的作用和相互间的关系,才能编写出优秀的代码并高效的运行在集群上。
参考资料:
作者简介:
王成龙,TalkingData 数据工程师。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论