本文借助多任务学习端到端框架 MKR,从知识图谱中找出电影间的潜在特征,并借助该特征及电影评分数据集,实现基于电影的推荐系统。
本文摘选自电子工业出版社出版、李金洪编著的《深度学习之TensorFlow工程化项目实战》一书的实例 38:TensorFlow 结合知识图谱实现基于电影的推荐系统。
知识图谱(Knowledge Graph,KG)可以理解成一个知识库,用来存储实体与实体之间的关系。知识图谱可以为机器学习算法提供更多的信息,帮助模型更好地完成任务。
在推荐算法中融入电影的知识图谱,能够将没有任何历史数据的新电影精准地推荐给目标用户。
实例描述
现有一个电影评分数据集和一个电影相关的知识图谱。电影评分数据集里包含用户、电影及评分;电影相关的知识图谱中包含电影的类型、导演等属性。
要求:从知识图谱中找出电影间的潜在特征,并借助该特征及电影评分数据集,实现基于电影的推荐系统。
本实例使用了一个多任务学习的端到端框架 MKR。该框架能够将两个不同任务的低层特征抽取出来,并融合在一起实现联合训练,从而达到最优的结果。有关 MKR 的更多介绍可以参考以下链接:
https://arxiv.org/pdf/1901.08907.pdf
一、准备数据集
在上述论文的相关代码链接中有 3 个数据集:图书数据集、电影数据集和音乐数据集。本例使用电影数据集,具体链接如下:
https://github.com/hwwang55/MKR/tree/master/data/movie
该数据集中一共有 3 个文件。
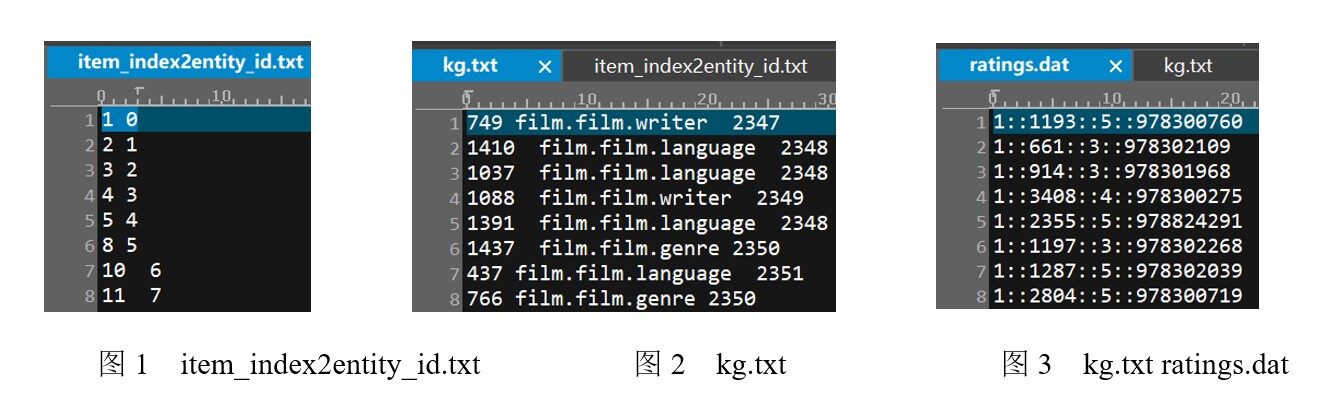
item_index2entity_id.txt:电影的 ID 与序号。具体内容如图 1 所示,第 1 列是电影 ID,第 2 列是序号。
kg.txt:电影的知识图谱。图 2 中显示了知识图谱的 SPO 三元组(Subject-Predicate-Object),第 1 列是电影 ID,第 2 列是关系,第 3 列是目标实体。
ratings.dat:用户的评分数据集。具体内容如图 3 所示,列与列之间用“::”符号进行分割,第 1 列是用户 ID,第 2 列是电影 ID,第 3 列是电影评分,第 4 列是评分时间(可以忽略)。
二、预处理数据
数据预处理主要是对原始数据集中的有用数据进行提取、转化。该过程会生成两个文件。
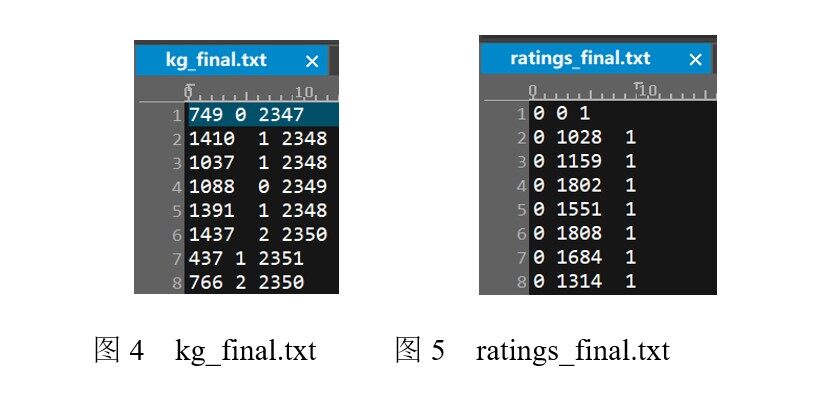
kg_final.txt:转化后的知识图谱文件。将文件 kg.txt 中的字符串类型数据转成序列索引类型数据,如图 4 所示。
ratings_final.txt:转化后的用户评分数据集。第 1 列将 ratings.dat 中的用户 ID 变成序列索引。第 2 列没有变化。第 3 列将 ratings.dat 中的评分按照阈值 5 进行转化,如果评分大于等于 5,则标注为 1,表明用户对该电影感兴趣。否则标注为 0,表明用户对该电影不感兴趣。具体内容如图 5 所示。
三、搭建 MKR 模型
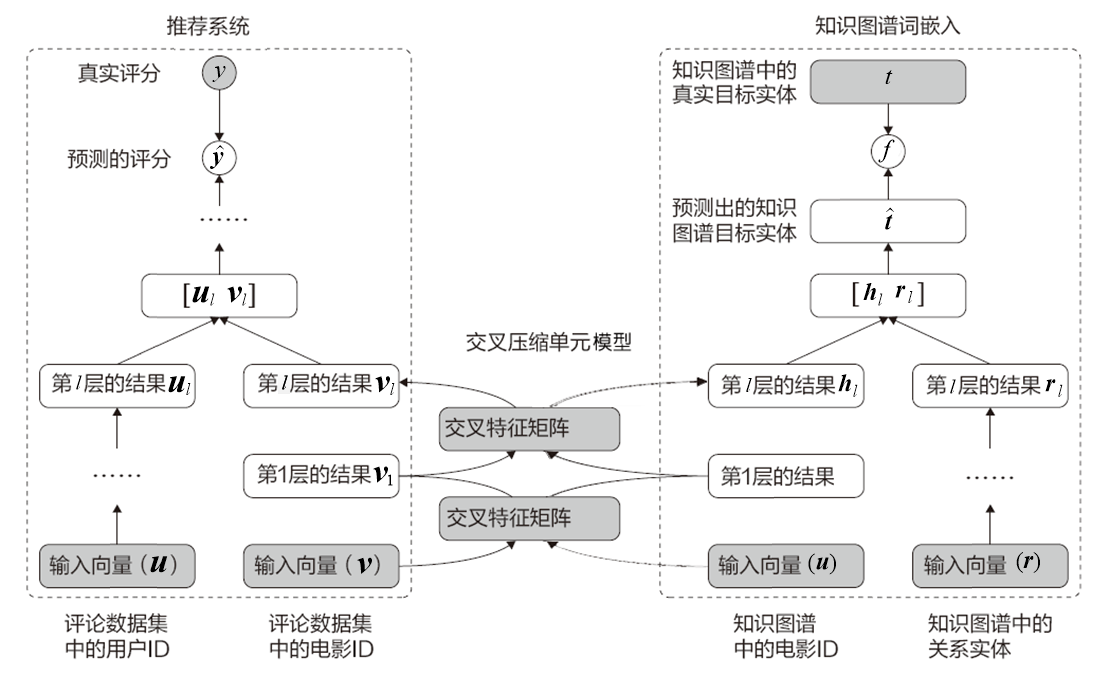
MKR 模型由 3 个子模型组成,完整结构如图 6 所示。具体描述如下。
推荐算法模型:如图 6 的左侧部分所示,将用户和电影作为输入,模型的预测结果为用户对该电影的喜好分数,数值为 0~1。
交叉压缩单元模型:如图 6 的中间部分,在低层将左右两个模型桥接起来。将电影评分数据集中的电影向量与知识图谱中的电影向量特征融合起来,再分别放回各自的模型中,进行监督训练。
知识图谱词嵌入(Knowledge Graph Embedding,KGE)模型:如图 6 的右侧部分,将知识图谱三元组中的前 2 个(电影 ID 和关系实体)作为输入,预测出第 3 个(目标实体)。
图 6 MKR 框架
在 3 个子模型中,最关键的是交叉压缩单元模型。下面就先从该模型开始一步一步地实现 MKR 框架。
1. 交叉压缩单元模型
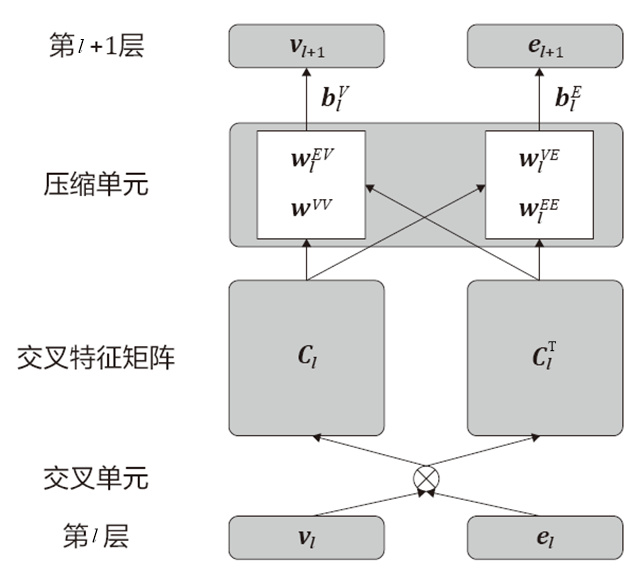
交叉压缩单元模型可以被当作一个网络层叠加使用。如图 7 所示的是交叉压缩单元在第 l 层到第 l+1 层的结构。图 7 中,最下面一行为该单元的输入,左侧的 v_l 是用户评论电影数据集中的电影向量,右侧的 e_l 是知识图谱中的电影向量。
图 7 交叉压缩单元模型的结构
交叉压缩单元模型的具体处理过程如下:
(1)将 v_l 与 e_l 进行矩阵相乘得到 c_l。
(2)将 c_l 复制一份,并进行转置得到 c_l^T。实现特征交叉融合。
(3)将 c_l 经过权重矩阵 w_l^vv 进行线性变化(c_l 与 w_l^vv 矩阵相乘)。
(4)将 c_l^T 经过权重矩阵 w_l^ev 进行线性变化。
(5)将(3)与(4)的结果相加,再与偏置参数 b_l^v 相加,得到 v_(l+1)。v_(l+1)将用于推荐算法模型的后续计算。
(6)按照第(3)、(4)、(5)步的做法,同理可以得到 e_(l+1)。e_(l+1)将用于知识图谱词嵌入模型的后续计算。
用 tf.layer 接口实现交叉压缩单元模型,具体代码如下。
代码 7-14 MKR
import numpy as npimport tensorflow as tffrom sklearn.metrics import roc_auc_scorefrom tensorflow.python.layers import base
class CrossCompressUnit(base.Layer): #定义交叉压缩单元模型类 def __init__(self, dim, name=None): super(CrossCompressUnit, self).__init__(name) self.dim = dim self.f_vv = tf.layers.Dense(1, use_bias = False) #构建权重矩阵 self.f_ev = tf.layers.Dense(1, use_bias = False) self.f_ve = tf.layers.Dense(1, use_bias = False) self.f_ee = tf.layers.Dense(1, use_bias = False) self.bias_v = self.add_weight(name='bias_v', #构建偏置权重 shape=dim, initializer=tf.zeros_initializer()) self.bias_e = self.add_weight(name='bias_e', shape=dim, initializer=tf.zeros_initializer())
def _call(self, inputs): v, e = inputs #v和e的形状为[batch_size, dim] v = tf.expand_dims(v, dim=2) #v的形状为 [batch_size, dim, 1] e = tf.expand_dims(e, dim=1) #e的形状为 [batch_size, 1, dim]
c_matrix = tf.matmul(v, e)#c_matrix的形状为 [batch_size, dim, dim] c_matrix_transpose = tf.transpose(c_matrix, perm=[0, 2, 1]) #c_matrix的形状为[batch_size * dim, dim] c_matrix = tf.reshape(c_matrix, [-1, self.dim]) c_matrix_transpose = tf.reshape(c_matrix_transpose, [-1, self.dim])
#v_output的形状为[batch_size, dim] v_output = tf.reshape( self.f_vv(c_matrix) + self.f_ev(c_matrix_transpose), [-1, self.dim] ) + self.bias_v
e_output = tf.reshape( self.f_ve(c_matrix) + self.f_ee(c_matrix_transpose), [-1, self.dim] ) + self.bias_e #返回结果 return v_output, e_output
复制代码
代码第 10 行,用 tf.layers.Dense 方法定义了不带偏置的全连接层,并在代码第 34 行,将该全连接层作用于交叉后的特征向量,实现压缩的过程。
2. 将交叉压缩单元模型集成到 MKR 框架中
在 MKR 框架中,推荐算法模型和知识图谱词嵌入模型的处理流程几乎一样。可以进行同步处理。在实现时,将整个处理过程横向拆开,分为低层和高层两部分。
具体实现的代码如下。
代码 7-14 MKR(续)
class MKR(object): def __init__(self, args, n_users, n_items, n_entities, n_relations): self._parse_args(n_users, n_items, n_entities, n_relations) self._build_inputs() self._build_low_layers(args) #构建低层模型 self._build_high_layers(args) #构建高层模型 self._build_loss(args) self._build_train(args)
def _parse_args(self, n_users, n_items, n_entities, n_relations): self.n_user = n_users self.n_item = n_items self.n_entity = n_entities self.n_relation = n_relations
#收集训练参数,用于计算l2损失 self.vars_rs = [] self.vars_kge = []
def _build_inputs(self): self.user_indices=tf.placeholder(tf.int32, [None], 'userInd') self.item_indices=tf.placeholder(tf.int32, [None],'itemInd') self.labels = tf.placeholder(tf.float32, [None], 'labels') self.head_indices =tf.placeholder(tf.int32, [None],'headInd') self.tail_indices =tf.placeholder(tf.int32, [None], 'tail_indices') self.relation_indices=tf.placeholder(tf.int32, [None], 'relInd') def _build_model(self, args): self._build_low_layers(args) self._build_high_layers(args)
def _build_low_layers(self, args): #生成词嵌入向量 self.user_emb_matrix = tf.get_variable('user_emb_matrix', [self.n_user, args.dim]) self.item_emb_matrix = tf.get_variable('item_emb_matrix', [self.n_item, args.dim]) self.entity_emb_matrix = tf.get_variable('entity_emb_matrix', [self.n_entity, args.dim]) self.relation_emb_matrix = tf.get_variable('relation_emb_matrix', [self.n_relation, args.dim])
#获取指定输入对应的词嵌入向量,形状为[batch_size, dim] self.user_embeddings = tf.nn.embedding_lookup( self.user_emb_matrix, self.user_indices) self.item_embeddings = tf.nn.embedding_lookup( self.item_emb_matrix, self.item_indices) self.head_embeddings = tf.nn.embedding_lookup( self.entity_emb_matrix, self.head_indices) self.relation_embeddings = tf.nn.embedding_lookup( self.relation_emb_matrix, self.relation_indices) self.tail_embeddings = tf.nn.embedding_lookup( self.entity_emb_matrix, self.tail_indices)
for _ in range(args.L):#按指定参数构建多层MKR结构 #定义全连接层 user_mlp = tf.layers.Dense(args.dim, activation=tf.nn.relu) tail_mlp = tf.layers.Dense(args.dim, activation=tf.nn.relu) cc_unit = CrossCompressUnit(args.dim)#定义CrossCompress单元 #实现MKR结构的正向处理 self.user_embeddings = user_mlp(self.user_embeddings) self.tail_embeddings = tail_mlp(self.tail_embeddings) self.item_embeddings, self.head_embeddings = cc_unit( [self.item_embeddings, self.head_embeddings]) #收集训练参数 self.vars_rs.extend(user_mlp.variables) self.vars_kge.extend(tail_mlp.variables) self.vars_rs.extend(cc_unit.variables) self.vars_kge.extend(cc_unit.variables) def _build_high_layers(self, args): #推荐算法模型 use_inner_product = True #指定相似度分数计算的方式 if use_inner_product: #内积方式 #self.scores的形状为[batch_size] self.scores = tf.reduce_sum(self.user_embeddings * self.item_embeddings, axis=1) else: #self.user_item_concat的形状为[batch_size, dim * 2] self.user_item_concat = tf.concat( [self.user_embeddings, self.item_embeddings], axis=1) for _ in range(args.H - 1): rs_mlp = tf.layers.Dense(args.dim * 2, activation=tf.nn.relu) #self.user_item_concat的形状为[batch_size, dim * 2] self.user_item_concat = rs_mlp(self.user_item_concat) self.vars_rs.extend(rs_mlp.variables) #定义全连接层 rs_pred_mlp = tf.layers.Dense(1, activation=tf.nn.relu) #self.scores的形状为[batch_size] self.scores = tf.squeeze(rs_pred_mlp(self.user_item_concat)) self.vars_rs.extend(rs_pred_mlp.variables) #收集参数 self.scores_normalized = tf.nn.sigmoid(self.scores)
#知识图谱词嵌入模型 self.head_relation_concat = tf.concat( #形状为[batch_size, dim * 2] [self.head_embeddings, self.relation_embeddings], axis=1) for _ in range(args.H - 1): kge_mlp = tf.layers.Dense(args.dim * 2, activation=tf.nn.relu) #self.head_relation_concat的形状为[batch_size, dim* 2] self.head_relation_concat = kge_mlp(self.head_relation_concat) self.vars_kge.extend(kge_mlp.variables) kge_pred_mlp = tf.layers.Dense(args.dim, activation=tf.nn.relu) #self.tail_pred的形状为[batch_size, args.dim] self.tail_pred = kge_pred_mlp(self.head_relation_concat) self.vars_kge.extend(kge_pred_mlp.variables) self.tail_pred = tf.nn.sigmoid(self.tail_pred)
self.scores_kge = tf.nn.sigmoid(tf.reduce_sum(self.tail_embeddings * self.tail_pred, axis=1)) self.rmse = tf.reduce_mean( tf.sqrt(tf.reduce_sum(tf.square(self.tail_embeddings - self.tail_pred), axis=1) / args.dim))
复制代码
代码第 73~90 行(书中第 115~132 行)是推荐算法模型的高层处理部分,该部分有两种处理方式:
代码第 90 行(书中第 132 行),通过激活函数 sigmoid 对分值结果 scores 进行非线性变化,将模型的最终结果映射到标签的值域中。
代码第 94~110 行(书中第 136~152 行)是知识图谱词嵌入模型的高层处理部分。具体步骤如下:
(1)将电影向量和知识图谱中的关系向量连接起来。
(2)将第(1)步的结果通过全连接层处理,得到知识图谱三元组中的目标实体向量。
(3)将生成的目标实体向量与真实的目标实体向量矩阵相乘,得到相似度分值。
(4)对第(3)步的结果进行激活函数 sigmoid 计算,将值域映射到 0~1 中。
3. 实现 MKR 框架的反向结构
MKR 框架的反向结构主要是 loss 值的计算,其 loss 值一共分为 3 部分:推荐算法模型模型的 loss 值、知识图谱词嵌入模型的 loss 值和参数权重的正则项。具体实现的代码如下。
代码 7-14 MKR(续)
def _build_loss(self, args): #计算推荐算法模型的loss值 self.base_loss_rs = tf.reduce_mean( tf.nn.sigmoid_cross_entropy_with_logits(labels=self.labels, logits=self.scores)) self.l2_loss_rs = tf.nn.l2_loss(self.user_embeddings) + tf.nn.l2_loss (self.item_embeddings) for var in self.vars_rs: self.l2_loss_rs += tf.nn.l2_loss(var) self.loss_rs = self.base_loss_rs + self.l2_loss_rs * args.l2_weight
#计算知识图谱词嵌入模型的loss值 self.base_loss_kge = -self.scores_kge self.l2_loss_kge = tf.nn.l2_loss(self.head_embeddings) + tf.nn.l2_loss (self.tail_embeddings) for var in self.vars_kge: #计算L2正则 self.l2_loss_kge += tf.nn.l2_loss(var) self.loss_kge = self.base_loss_kge + self.l2_loss_kge * args.l2_weight
def _build_train(self, args): #定义优化器 self.optimizer_rs = tf.train.AdamOptimizer(args.lr_rs).minimize(self.loss_rs) self.optimizer_kge = tf.train.AdamOptimizer(args.lr_kge). minimize(self. loss_kge)
def train_rs(self, sess, feed_dict): #训练推荐算法模型 return sess.run([self.optimizer_rs, self.loss_rs], feed_dict)
def train_kge(self, sess, feed_dict): #训练知识图谱词嵌入模型 return sess.run([self.optimizer_kge, self.rmse], feed_dict)
def eval(self, sess, feed_dict): #评估模型 labels, scores = sess.run([self.labels, self.scores_normalized], feed_dict) auc = roc_auc_score(y_true=labels, y_score=scores) predictions = [1 if i >= 0.5 else 0 for i in scores] acc = np.mean(np.equal(predictions, labels)) return auc, acc
def get_scores(self, sess, feed_dict): return sess.run([self.item_indices, self.scores_normalized], feed_dict)
复制代码
代码第 22、25 行(书中第 173、176 行), 分别是训练推荐算法模型和训练知识图谱词嵌入模型的方法。因为在训练的过程中,两个子模型需要交替的进行独立训练,所以将其分开定义。
四、训练模型并输出结果
训练模型的代码在本书配套的“7-15 train.py”文件中,读者可以自行参考。代码运行后输出以下结果:
……
epoch 9 train auc: 0.9540 acc: 0.8817 eval auc: 0.9158 acc: 0.8407 test auc: 0.9155 acc: 0.8399
在输出的结果中,分别显示了模型在训练、评估、测试环境下的分值。
本文摘选自电子工业出版社出版、李金洪编著的《深度学习之TensorFlow工程化项目实战》一书,更多实战内容点此查看。
本文经授权发布,转载请联系电子工业出版社。
系列文章:
TensorFlow 工程实战(一):用 TF-Hub 库微调模型评估人物年龄
TensorFlow 工程实战(二):用 tf.layers API 在动态图上识别手写数字
TensorFlow 工程实战(三):结合知识图谱实现电影推荐系统(本文)
TensorFlow 工程实战(四):使用带注意力机制的模型分析评论者是否满意
TensorFlow 工程实战(五):构建 DeblurGAN 模型,将模糊相片变清晰
TensorFlow 工程实战(六):在 iPhone 手机上识别男女并进行活体检测

















评论