
整理 | 华卫
近日,新一代“面壁小钢炮” MiniCPM4.0 端侧模型发布,拥有 8B 、0.5B 两种参数规模 。 一款 8B 稀疏闪电版,带来端侧性能大跃升;一款 0.5B “以小博大”,适配广泛终端场景。
模型相关链接
Github 链接:https://github.com/openbmb/minicpm
Huggingface 链接:https://huggingface.co/collections/openbmb/minicpm-4-6841ab29d180257e940baa9b
Model Scope 链接:https://www.modelscope.cn/collections/MiniCPM-4-ec015560e8c84d
截至目前,面壁小钢炮 MiniCPM 系列全平台下载量累计破 1000 万。
据介绍,MiniCPM4.0 -8B 是首个原生稀疏模型,5% 的极高稀疏度加持系统级创新技术的大爆发,让长文本、深思考在端侧真正跑起来。在 MMLU、CEval、MATH500、HumanEval 等基准测试中,MiniCPM4.0 -8B 以仅 22% 的训练开销,性能比肩 Qwen-3-8B,超越 Gemma-3-12B。
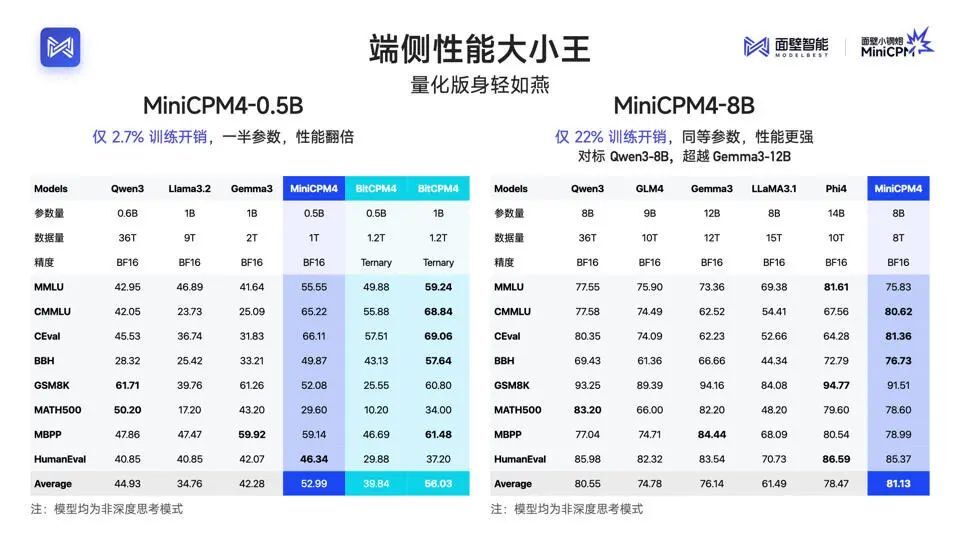
在 MMLU、CEval、BBH、HumanEval 等基准测试中,MiniCPM4.0 -0.5B 性能秒杀同级的 Qwen-3-0.6B、Llama 3.2、Gemma3,并通过原生 QAT 技术实现几乎不掉点的 int4 量化,并实现了 600 Token/s 的极速推理速度。
面壁表示,MiniCPM4.0 的代号是“前进四”,代表着极致的速度提升、性能的大迸发和端侧部署的极致优化。
面对此前端侧模型的长文本“龟速推理”难题,MiniCPM 4-8B “闪电稀疏版”,采用了新一代上下文稀疏高效架构,相较于 Qwen-3-8B、Llama-3-8B、GLM-4-9B 等同等参数规模端侧模型,实现了长文本推理速度 5 倍常规加速以及最高 220 倍加速(显存受限极限场景下测出),真正让端侧模型长文本推理实现了“快如闪电”的质变。此外,注意力机制上实现了高效双频换挡,长文本用稀疏,短文本用稠密,切换快如流。
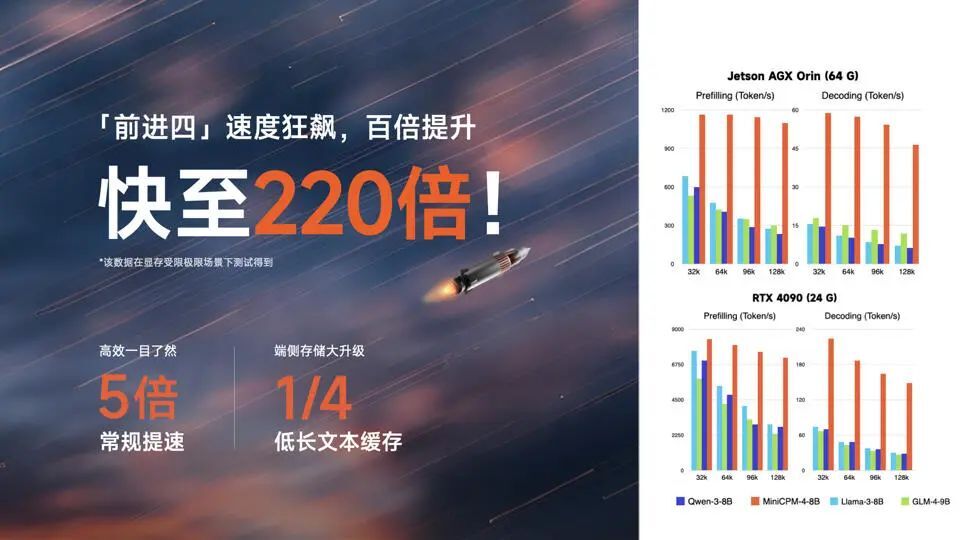
并且,MiniCPM 4.0 进一步实现了长文本缓存的大幅锐减,在 128K 长文本场景下,MiniCPM 4.0-8B 相较于 Qwen3-8B 仅需 1/4 的缓存存储空间。量化版身轻如燕,高达 90% 的模型瘦身,性能依然十分稳健。在速度、性能飙升的同时,又做到了模型极致压缩,让端侧算力不再有压力,成为业界最为友好的端侧模型。
在应用上,端侧长文本的突破带来更多可能。基于 8B 版本,团队微调出两个特定能力模型,分别可以用做 MCP Client 和纯端侧性能比肩 Deep Research 的研究报告神器 MiniCPM4-Surve。

与此同时,面壁智能也在持续推动 MiniCPM 4.0 的模型适配及应用拓展。截止目前,MiniCPM 4.0 已实现 Intel、高通、MTK、华为昇腾等主流芯片的适配。此外, MiniCPM 4.0 可在 vLLM、SGLang、llama.cpp、LlamaFactory、XTuner 等开源框架部署。同时加强了对 MCP 的支持,且性能超过同尺寸开源模型( Qwen-3-8B),进一步拓展了模型开发、应用潜力。
具体来说,这次面壁全开源的系统级上下文稀疏化高效创新,是基于新一代稀疏注意力架构 InfLLM 做了模型创新,并通过自研端侧推理三级火箭,自研 CPM.cu 极速端侧推理框架,从 投机采样创新、模型压缩量化创新、端侧部署框架创新几方面,带来 90% 的模型瘦身和极致速度提升。
模型架构大创新,获速度准度双效提升
引入稀疏注意力架构为什么在当下如此重要?一是长文本处理、深度思考能力成为人们对大模型愈来愈迫切的需求,而传统稠密模型上下文窗口受限;二是稀疏度越高,计算量越小,速度越快越高效。DeepSeek 等明星项目以稀疏模型架构撬动的“高效低成本”收益愈益得到认可。端侧场景天然因算力限制,对效率提升与能耗降低要求则更加迫切。
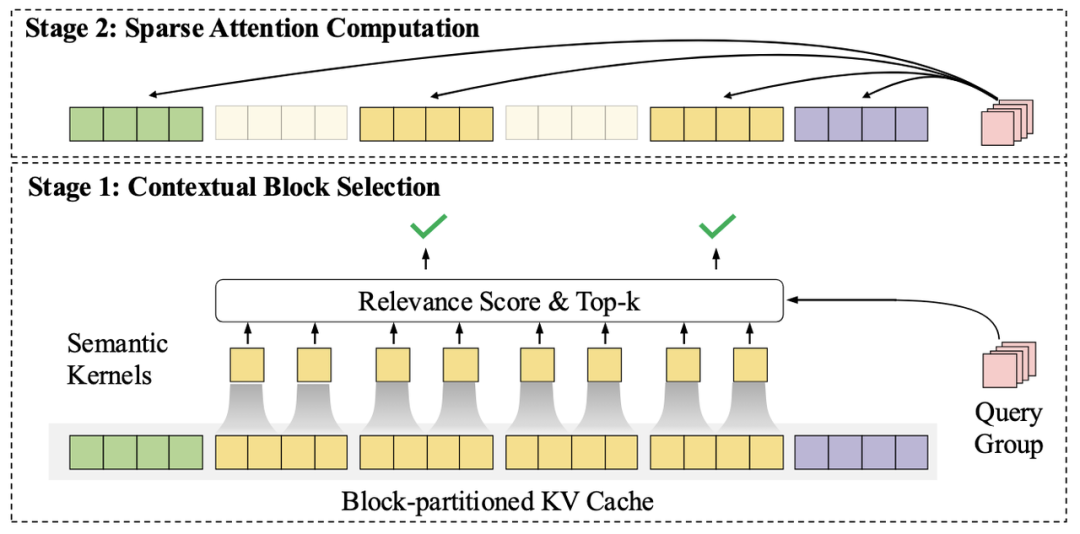
传统 Transformer 模型的相关性计算方式是每个词元都需要和序列中所有 词元进行相关性计算,造成了较高的计算代价 。
MiniCPM 4.0 模型采用的 InfLLMv2 稀疏注意力架构改变了传统 Transformer 模型的相关性计算方式,到分块分区域高效“抽查”——即对文本进行分块分区域处理后,通过智能化选择机制,只需对最有相关性的重点区域进行注意力计算“抽查”,摆脱了逐字重复计算的低效。InfLLMv2 通过将稀疏度从行业普遍的 40%-50%,降至极致的 5%,注意力层仅需 1/10 的计算量即可完成长文本计算。且对算子底层重写,进一步加速提升,并使得对文本相关性精准性大大提升。
主要创新点如下:
1)更精准的上下文块选择算法:在 InfLLM 中,每个上下文块由少量代表元构成单一的语义表示。InfLLM v2 引入了细粒度语义核的概念,每个上下文块由多个细粒度语义核构成。查询词元与上下文块的相关性分数为查询词元与该上下文块中包含的所有语义核相关性分数最大值。该方法使得模型能够更精准地选择上下文块。
2)更细粒度的查询词元分组:InfLLM 在预填充阶段将多个查询词元分成一组,使该组内所有查询词元选择相同的上下文块进行注意力计算。该方法会造成模型训练与推理的不统一。InfLLM v2 中采用了更细粒度的查询词元分组 —— 要求 Grouped Query Attention 中每组查询头共享相同的上下文块。该划分在保证了底层算子高效实现的同时,提升了模型上下文选择的准确性。
3)更高效的算子实现:为了 InfLLM v2 能够在训练与推理过程中充分发挥其理论加速优势,MiniCPM4 开发并开源了 InfLLM v2 的高效训练与推理算子。同时,为了能够快速地选取 TopK 上下文块,MiniCPM4 中提出了一种高效的 LogSumExp 估计算法。相比于 DeepSeek NSA 算法,MiniCPM4 中采用的 TopK 上下文选择方法,能够节省 60% 的计算开销。
值得一提的是,DeepSeek 使用的长文本处理架构 NSA(Native Sparse Attention)也引用并采用了与 InfLLM 相同的分块注意力计算思路,但其对于短文本的推理较慢,InfLLMv2 则很好的解决了 NSA 在短文本推理上的短板。
针对单一架构难以兼顾长、短文本不同场景的技术难题,MiniCPM 4.0-8B 采用“高效双频换挡”机制,能够根据任务特征自动切换注意力模式:在处理高难度的长文本、深度思考任务时,启用稀疏注意力以降低计算复杂度,在短文本场景下切换至稠密注意力以确保精度与速度,实现了长、短文本切换的高效响应。

自研全套端侧高性能推理框架
在推理层面,MiniCPM 4.0 通过 CPM.cu 自研推理框架、P-GPTQ 前缀敏感的模型训练后量化、BitCPM 极致低位宽量化、ArkInfer 自研跨平台部署框架等技术创新,实现了极致的端侧推理加速。
CPM.cu:轻量化高效 CUDA 推理框架
CPM.cu 端侧自研推理框架是一个专为端侧 NVIDIA 芯片优化的轻量化推理框架。除了静态内存管理和算子融合等基础功能外,还实现了高效的投机采样、前缀敏感的量化算法,并为 InfLLM v2 集成了高效的稀疏注意力算子,可以说是做到了稀疏、投机、量化的高效组合,最终实现了 5 倍速度提升。
其中,FR-Spec 轻量投机采样类似于小模型给大模型当“实习生”,并给小模型进行词表减负、计算加速。通过创新的词表裁剪策略,让小模型专注于高频基础词汇的草稿生成,避免在低频高难度词汇上浪费算力,再由大模型进行验证和纠正。

BitCPM 量化与 P-GPTQ 量化
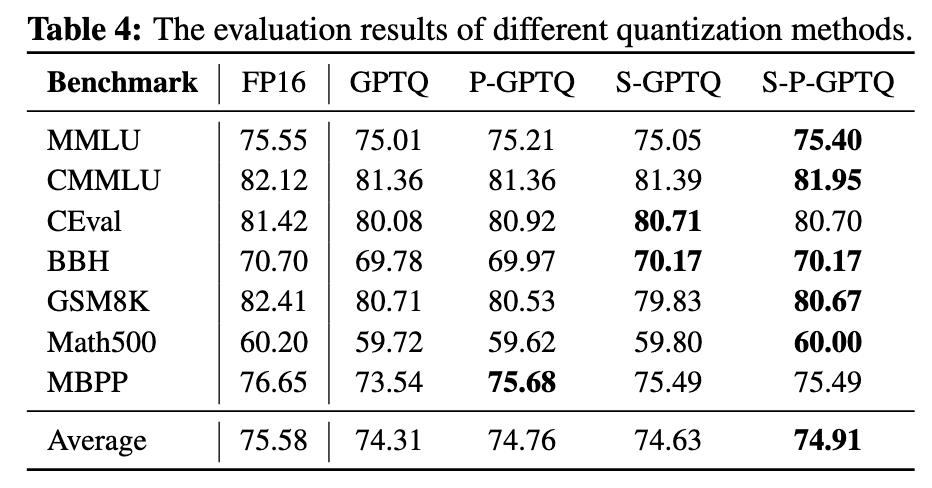
部署大模型面临高计算和内存需求的挑战。模型量化通过降低参数精度来解决这一问题,实现高效推理并减少资源消耗。此次,面壁智能采用了 P-GPTQ(前缀敏感的模型训练后量化)、以及 BitCPM 三值量化两种量化方法,来降低大模型部署中的计算与内存消耗。
P-GPTQ 的核心思想是在量化过程的 Hessian 矩阵计算时排除初始词元的干扰。实证分析发现,大模型初始位置的激活幅度比后续词元大 10 倍,将严重影响协方差运算。MiniCPM4 采用位置感知的校准策略,仅使用从第 4 个位置开始的稳定词元进行量化参数计算,有效消除了初始词元带来的统计偏差,且该方法与现有量化技术(如 Quarot 旋转方法和 AWQ 平滑方法)完全兼容,可无缝集成到现有量化流水线中。实验结果表明,在 INT4 量化设置下,P-GPTQ 相比其他量化方法取得了最优性能,显著减少了相对于 FP16 基线的性能退化。
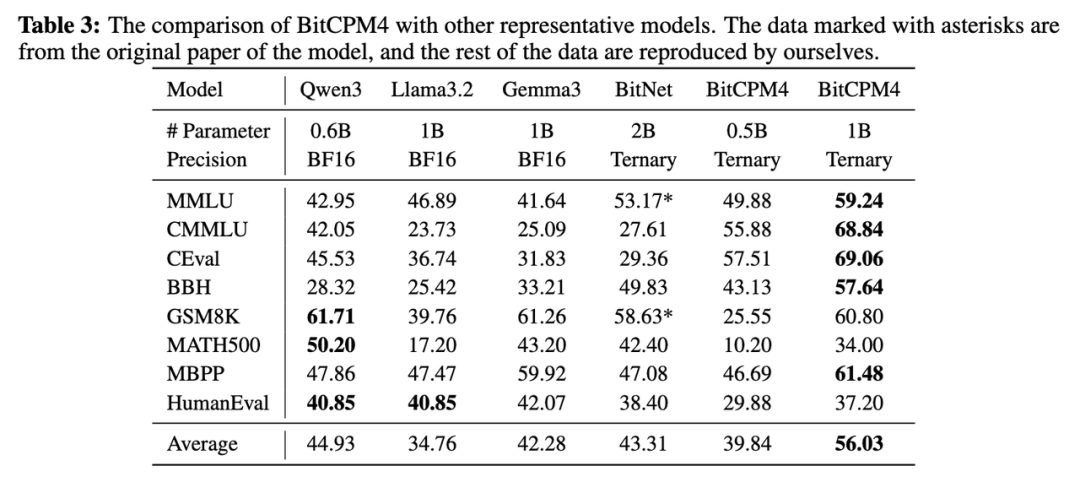
此外,面壁训练了两个规模的三值模型:BitCPM4-0.5B 和 1B 参数模型,整个训练过程使用了 350B 词元。实验结果显示,在 0.5B 参数级别,BitCPM4-0.5B 在知识相关任务上表现优异。
ArkInfer 跨平台部署框架
除了有限的计算资源挑战外,端侧芯片的碎片化是另一个重大障碍。芯片碎片化要求每次发布新模型时,都需要将模型适配到多个平台和芯片类型,导致复杂的适配和部署过程,这带来了巨大的工程工作量。
为了解决这些痛点,面壁提出了 ArkInfer,一个新颖的跨平台部署系统。通过引入了跨平台兼容的架构设计、可复用且高效的推测采样与约束解码方案以及可扩展的模型库前端等解决方案,提供高效的推理速度并作为各种模型应用的多功能跨平台兼容层,来克服端侧芯片的碎片化问题。

从训练到数据,科学化建模产线
好数据才有好模型,高效构建高质量数据,是高质量模型的基本盘。面壁在这一领域拥有诸多创新方法,并且悉数开源。
譬如,Ultra-FineWeb 高知识密度数据筛选机制,用“半成品加工法”来构造万亿数据,通过先训一个“半熟”模型, 再用新数据快速微调,如同预制菜快出成果,最终实现 90% 的验证成本降低。在大规模数据质检方面,利用轻量化的 FastText 工具,处理 15 万亿 token 数据仅需 1000 小时 CPU 时间。
同时,UltraChat-v2 合成了包含数百亿词元的高质量对齐数据,在知识类、指令遵循、长文本、工具使用等关键能力上进行定向强化。在高质量数据与高效训练策略的加持下,相比同尺寸开源模型,MiniCPM 4.0-8B 仅用 22% 的训练开销,即可达到相同能力水平。
在训练策略上,MiniCPM 4.0 应用了迭代升级后的风洞 2.0 方案(Model Wind Tunnel v2),通过在 0.01B-0.5B 小模型上进行高效实验,搜索最优的超参数配置并迁移到大模型,相比此前的 1.0 版本,风洞 2.0 将配置搜索的实验次数降低 50%。针对强化学习训练中的负载不均问题,Chunk-wise Rollout 技术通过分段采样策略,确保 GPU 资源的高效利用。工程层面还采用了 FP8 训练和 MTP 监督信号等前沿技术,进一步提升训练效率。




