
AIGC 技术兴起以来,行业对 AI 在安全场景的应用出现了很多积极的探索。在 InfoQ 举办的 QCon 全球软件开发大会(北京站)上,来自蚂蚁集团的资深算法专家、安全大模型负责人刘焱发表了题为《复杂业务场景下 AIGC 赋能安全运营的实践》的演讲,他重点介绍了如何通过以原生安全范式构建原生安全底座,安全平行切面为数据采集和干预底座,将 DKCF(Data/Knowledge/Collaboration/Feedback,即数据 / 知识 / 协同 / 反馈) 可信推理范式构建智能化底座,落地安全运营与安全治理领域。该体系的落地经验,对于其他专业领域可信落地大模型,同样存在较大的借鉴意义。
预告:将于 10 月 23 - 25 召开的 QCon 上海站也策划了「大模型安全」专题,本专题讨论的方向有大模型的内在安全能力、大模型的外部安全围栏、大 / 小模型协同的综合检测实践等等。浙江大学研究员王庆龙博士、 阿里云高级算法专家申晨、腾讯玄武实验室高级研究员陈昱博士、网易算法专家胡宜峰将倾情分享,敬请关注。
以下是演讲实录(经 InfoQ 进行不改变原意的编辑整理)。
大模型产业应用挑战
大模型火热以来,我们一直在思考它如何在产业里有效落地。网络安全领域有一个典型例子,我们发现一位研发部门同学的机器上有个进程访问了代码库。查看代码乍一看好像没什么问题。我们用这个事件询问大模型,大模型说这是很正常的,他是研发人员,访问代码库没有什么问题。但如果我们发现他是数据库研发的同学,但却使用会议软件,使用一个公共的 Key 去访问我们的代码库,同时访问的是一个转账的应用。加了这些定语后,我们突然发现访问行为确实是一个很可疑的行为。
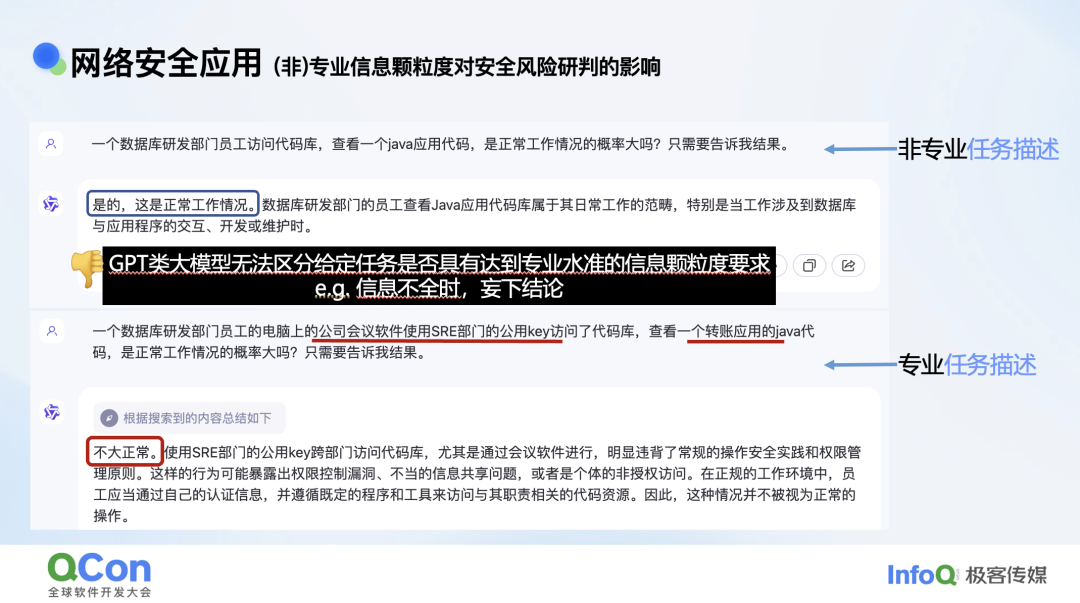
我们发现大模型在做这种分析时,如果你给它一个不具体、不专业的描述,它也会告诉你答案,并不会思考提供的信息是否充足。但如果我们给它一个很详细的描述,比如说什么样的进程,什么样的权限访问,什么样的代码库,访问者自己什么身份,这时它给出的判断就准确了很多。
也就是说,如果我们给大模型输入的信息不够全,大模型本身并没有做残差分析,它不会去思考你给它的信息全不全,只是凭着自己的感觉给你一个答案,这个是大模型存在的一个比较严重的问题。
所谓残差分析,就是会去思考你给我的信息数据是否充足,还有我自己的能力是否充足,这是两个很重要的因素。通常如果是人,我们发现你给我的信息不足,我会多问你几句这是什么进程什么样的权限。另外如果发现这个知识点我不够了解,比如说有些差异是我不太懂,我自己不会主动给结论,而可能会去查一些资料。但大模型有个特点,它不知道自己不会,它一定会给你个答案,它是一种讨好型的人格。
下一个比较典型的例子是在医疗领域。在这个例子中找了 400 多位医生,又找了一些典型的呼吸衰竭医疗案例,要医生去做检测,一共有 45 个案例。每个案例里会有病情描述、CT 图像等信息。医生会随机从这 45 个案例里挑取 9 个,在 AI 辅助下进行诊断。
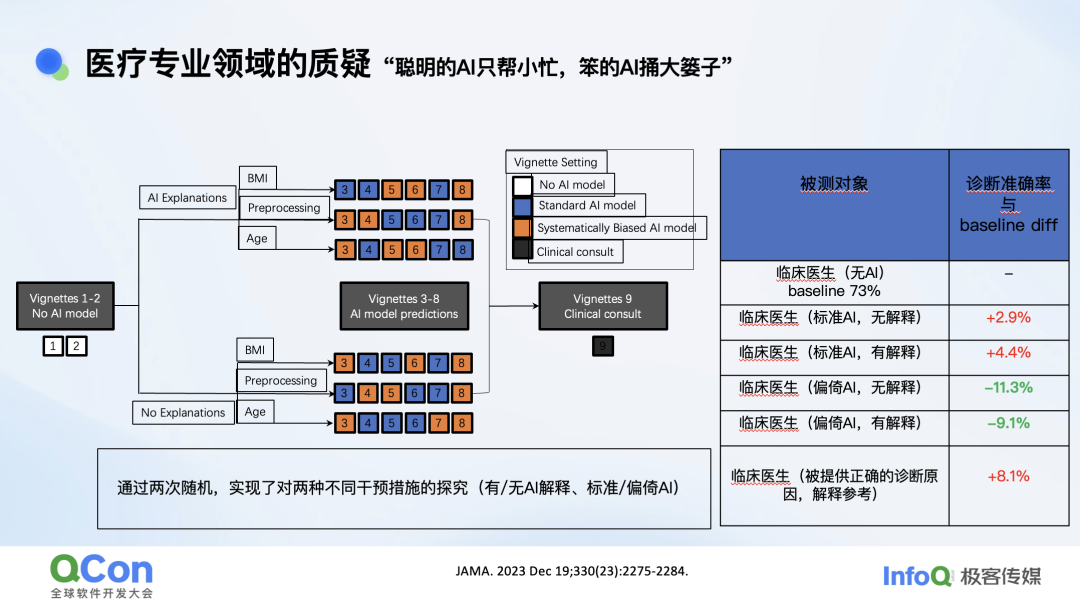
我们也会关注 AI 辅助医疗工具在给出具体诊断解释和不给解释的情况下会有哪些影响。另一方面,我们还会考察当模型训练的数据有偏差,也就是有歧视的情况下对医生诊断的效果有怎样的影响。
这 9 个案例有不同的设置,其中第一个和第二个案例就是不给医生任何提示,凭医生自己的本事来判断病人是否有疾病。第三号到第八号案例是给医生一定的 AI 辅助。这些辅助的案例又分了两类,一类是给解释,另一类是不给解释,直接给出 AI 的诊断结果。AI 模型也有两种,一种是有偏见的,另一种是没偏见的。
结果,医生在没有 AI 辅助医疗的情况下诊断准确率是 73%。如果给他没有偏见的正常 AI,同时没有解释的情况下,准确率的提升是 2%。如果是标准 AI 同时也有解释,提升是 4%。但相对于之前的 73% 的准确率,我们发现 AI 辅助医疗的帮助并没有想象中那么大。但如果给医生正确的辅助信息,准确率就可以增加 8.1%,这是 AI 模型达不到的。
与此同时,如果你的 AI 模型本来就是有偏差,数据集是有偏移的,情况就会很差。在我们的测试用例里有三个因素有偏移,分别是年龄、BMI 和预处理。比如数据集里体重偏高的病患比较多,就会造成 BMI 偏移,CT 照片质量分布不均导致预处理偏移,年龄偏大的病患较多导致年龄偏移。模型有歧视时,给出的诊断又不附加解释,结果会让准确率下降 11%,有解释时也会下降 8%。这说明有相当部分医生还是会相当信任 AI 辅助工具的错误答案。也就是说,聪明的 AI 会帮你一个小忙,愚蠢的 AI 可以闯出大祸。上述研究的另一个洞察是,如果 AI 模型能够将思考过程告知医生,可以多少提升一些准确率。因为医生可以从思考过程中发现一些明显的错误,有亡羊补牢做核验的机会。
所以无论是安全还是医疗等垂直领域,我们对大模型的应用还是秉承比较谨慎的态度。我们相信新技术确实会带来提升,但这个过程还是会比想象中漫长一点。
总结大模型在产业应用中面临的挑战,可以分为四点:

推理核验与残差分析。大模型存在表演倾向,不会分析自己的能力与数据是否充足。
专业知识工程。比如说一个对话机器人,我们就问一下天文地理没问题,但如果问一些理财信息,问报警怎么处理,问疾病怎么去看,这时它的通用知识不足以解决这些行业问题,它缺乏行业的具体数据信息。又比如说企业应用时,它缺乏企业内部的运营数据。这些在实际应用中确实会影响运营及研判的结果。
反馈循环效率。大模型比较依赖 bad case,需要通过 SFT、RLHF 等手段向模型提供反馈,但这个过程非常缓慢,不利于大模型能力快速迭代。
万用能力及信息汇聚单点。以安全为例,以前整个互联网企业的访问入口是防火墙,现在是大模型。很多权限控制手段从传统系统移到了大模型上,大模型成了总的访问入口,导致安全防护工作遇到了很大挑战。因为管控的节点出现了很大变化,能力和信息的汇聚点变成了大模型和智能体平台。如果这样的平台存在安全管控能力缺失,影响就会非常大。
DKCF 安全框架
针对上面的问题,我们提出了一个针对大模型安全的框架,DKCF。这里 D 指的是数据,K 指的是知识,C 指的是协同和能力,F 指的是反馈。

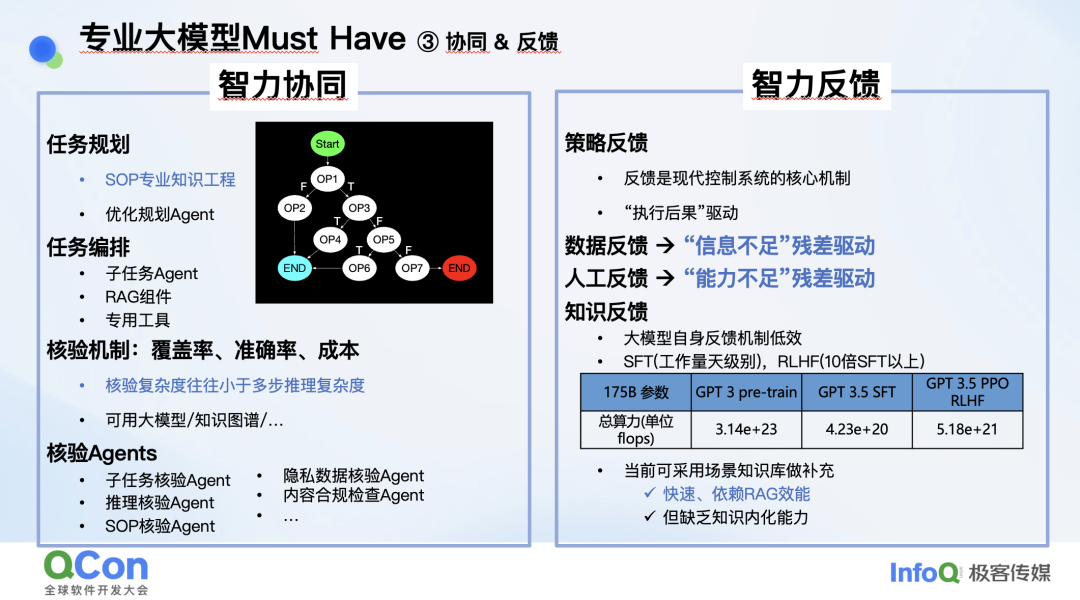
基座大模型最重要的思维能力是逻辑能力、数学能力和推理能力。所有大模型在训练时都会关注这三个能力,它们决定了它在行业应用中是否好用。大模型的另一个重要维度是知识,不同行业的知识积累也不一样。比如医疗、金融行业就有很齐全的知识图谱,但安全领域就不够完善。同时知识图谱本身需要可计算,可查询的。验证能力也很重要,大模型内置的专业知识需要有验证的手段。
下一个重要维度是推理与核验。具体到安全领域,解决一个问题时需要有完善的任务规划,比如处理一类报警,首先要分为几个步骤,然后要对每个步骤做核验。

举一个例子,我看天气预报说明天要刮大风,然后发现会场附近的北京地铁线路都停运了,导致我没法来做参会了。我将这个信息告诉会议对接的同学,对方对我的分析一步步做了核验,检查了公告停运的各条线路,结果发现一条地铁线路其实并没有停运,我认为它停运是因为我的理解错误。同样的道理,大模型给出分析的时候每一个关键步骤都要核验,需要看模型是不是在胡说八道。通常来说核验要比推理简单,而且不需要核验所有步骤,只核验关键步骤即可。
通过我们之前一些实践我们还发现一个问题。比如说很多同学都会拿自己身边的一些常见场景去找大模型实验,跑到第十个样本可行时,你会认为这样就可以申请新的项目了,但确实很有可能跑第十一个的时候它就会挂掉。所以大模型在很多领域应用时有一句话,“上线两周,落地两年”。它的上线可能比较快,但在运行的过程中,你会发现它不一定每次运行都是对的,不一定每个执行步骤的答案都是合理的,所以一定要去做核验。
残差分析是下一个关键。大模型在处理问题的时候,如果发现这个知识点它不掌握,它要识别出这个信息,主动退出并转人工。转人工总比做出错的结论要强很多。根据我们自己落地的经验,大模型落地最难的一个是核验,一个是残差分析。
还有一个维度是智力协同,分为几个层面。首先是智能体之间的协同,还有工具的协同,以及模型之间的协同。另一个维度是智力的反馈,当遇到 bad case 时要大模型学习迭代速度是非常慢的。而在安全领域我们希望问题修复的速度非常快,那这时还是需要用规则或者小模型来解决问题。
再回到安全的本质,大模型变成我们整个信息和管控的入口后,它自身的安全性又变得很重要。之前一个案例是,模型发给服务器调用时没有做鉴权,攻击者可以在发送的载荷里放一些攻击载荷,偷到一些凭证来访问大模型服务,盗取 GPU 算力。我们发现大模型本身的安全防护缺乏一些指导思想,所以提出了管控机制,分别是 OVTP 和 NBSP。

这里讲一下 OVTP,它强调的是,每一次主体对于客体的访问,我们都会校验它的权限是否是对的,比如说你要大模型做个转账,你发给大模型这句话里没有携带任何个人信息。但如果这句话发给大模型要去执行,就要判断它这个权限到底对不对?如果你信任大模型,在发送内容里提供身份信息,这就有问题。对于这种访问我们只能溯源到它发送的主体到底有什么样的权限。
结合刚才提的这些问题,我们提出了 DKCF 范式。这里的 D 是指数据,有两个层面,一个层面是推理所用的数据获取,这里我们依赖平行切面技术,可以抓取到一些底层数据。另外一个层面是结果数据。K 是指通用知识和安全领域的专业知识。C 和 F 是指协同和反馈,这里的反馈指的是核验,比如 COT 思考的过程分为很多步骤,我们都会进行验证,防止它跑飞,这是非常重要的。
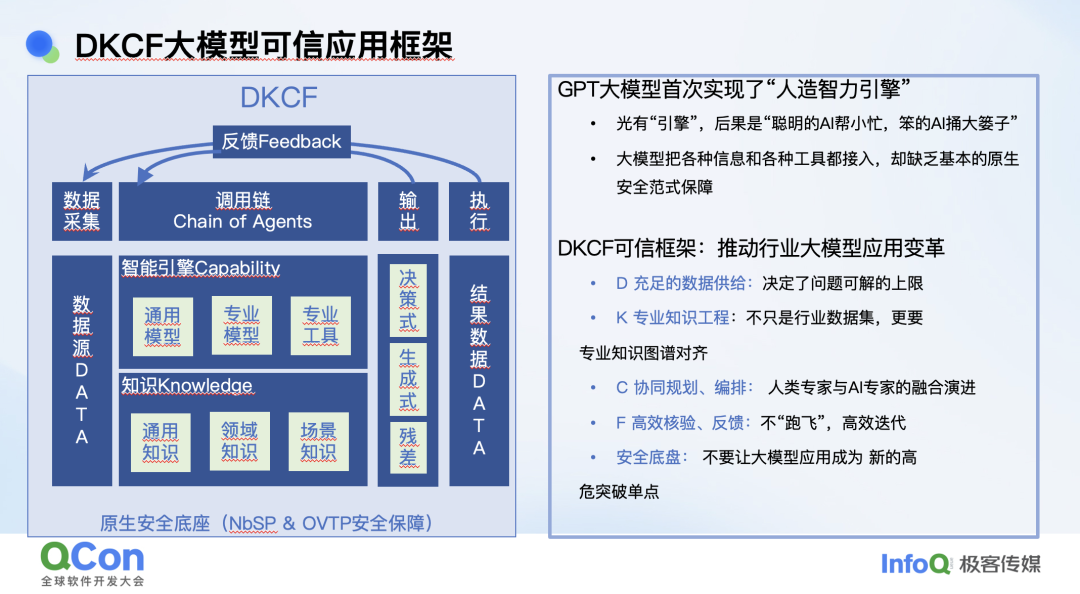
为了将 DKCF 范式落地,我们提出了切面融合智能的方法。这里的切面是获取数据的比较重要的手段,融合智能讲的是如何基于切面的数据来更好地让大模型提供安全能力。
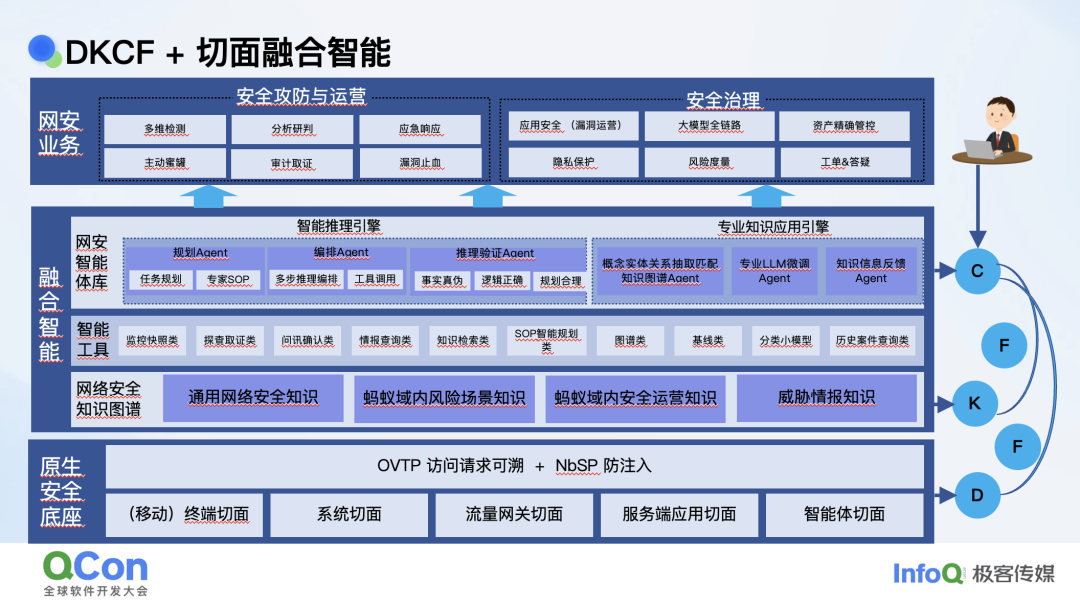
我们的技术框架在最底层是原生的安全底座,分为几部分,一部分就是切面,是一种数据获取以及管控的方式,比如说可以在程序里通过底层获取数据,另外一方面也获得了一些底层的干预能力。又比如说在移动端收集这些信息,我们在流量终端,包括像服务端、智能体端都可以抓到一些底层的数据并进行一些控制。
早期的切面只能收集数据作为观测,后来我们在这些切面上也有了管控能力,包括终端和流量端。在原生的安全底座上,切面是帮我们收集数据并进行底层的管控,然后用 OVTP、NBSP 作为我们的安全范式,构成了我们的原生安全底座。
融合智能是基于安全底座构建的,它包括一些安全知识图谱、智能工具和安全智能体,对应安全攻防和安全治理的应用。
实践案例
这里讲个具体的例子。我们提出了 OVTP 这个范式,它的关键是每一次访问都会校验主体对于客体的访问权限。比如说我之前做入侵检测,发现在流量里有一个疑似 DNS 隧道的流量。如果我只看流量,可能会产生误报。实践中我们会还原是具体哪个流量,到底是哪个终端发起的,终端的哪个进程发起的,它是向哪个业务发起的,然后它是用什么样的权限去发起的。在浏览过程中,我们还要溯源到是哪个进程,看到最终的主体是哪个进程访问了哪个服务器的服务。然后再去校验权限,看一些终端进程认证的权限,这样去对比才真正还原主体到客体的一个访问过程,得到一个完整的访问链。
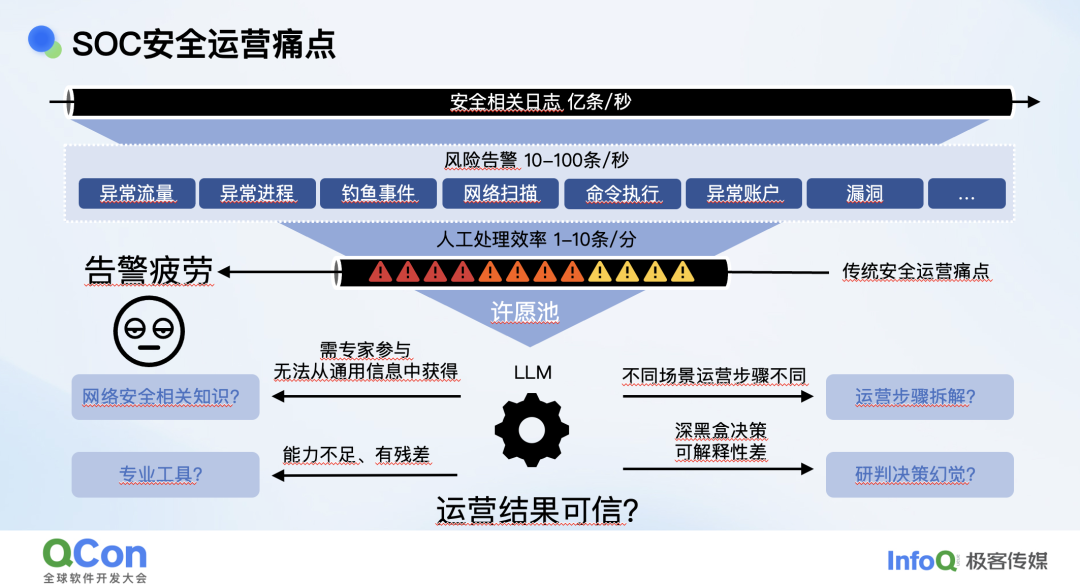
安全运营时我们遇到的一个很典型的问题是每秒钟就可能有几亿条原始日志。基于原始的日志我们写了一堆规则,最后可能一秒钟有 10~100 个告警,结果发现一个人一分钟最多处理 1~10 条,这就相当于是一个典型的漏斗。然后我们会发现大家会淹没在告警中,产生大量的告警疲劳。
这时我们的处理方法是,一种情况下,我们大量的风险场景有完整的 SOP,比如我们知道这些告警该怎么处理,DNS 隧道该怎么看,病毒邮件怎么过滤等等。有 SOP 的情况下我们针对 SOP 拆解成 COT 让模型执行,然后每一步执行的过程、结果我们都会进行核验。
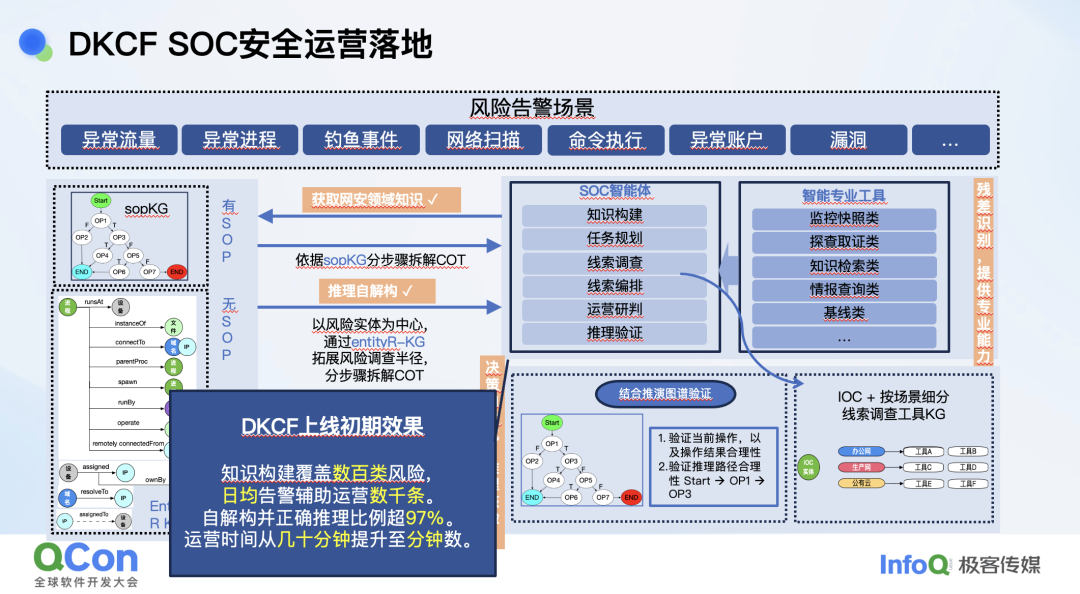
更多的场景并没有 SOP,这时我们就把风险相关的主体展开 1 度到 n 度。
我们定义的风险主体是 IP、域名、设备号等一共 6 类,然后组成了一个知识图谱。在这个图里我们再去展开跟它相关的,比如说风险报警,它相关的 IP 还访问过谁,这个设备还攻击过谁或者访问过谁,最后形成一个 1 到 n 度的子图。然后根据这一个子图,不同的设备可能用不同的工具去展开一些风险,最后得到一个相当长的风险描述,针对这个风险描述进行研判。这样就是模拟人在处理告警的时候进行的排查工作,现在换成大模型来研判,然后研判的每一步再进行核验,最后得到结论。
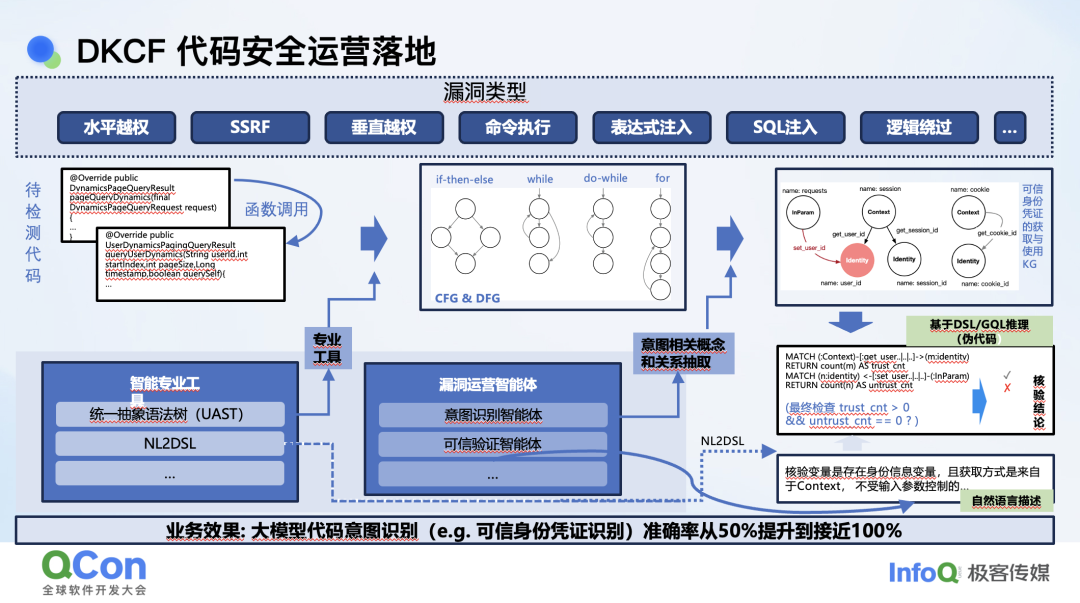
最后处理的每条报警的延时从几十分钟缩短到了几分钟,这是大模型在安全方面的落地效果。时间所限,本次分享主要介绍 DKCF 的一些理念,将来有机会我们还会介绍更深入的内容。
嘉宾介绍
刘焱,蚂蚁集团基础安全部副总经理,资深安全专家,清华大学高等研究院 - 蚂蚁集团“隐私计算与区块链联合研究中心 ”副主任,研究方向集中在网络安全、AI 安全和隐私计算,在无人驾驶、人脸识别以及大模型领域具有多年工业级攻防经验,多项研究成果在国际顶级工业界会议 Defcon、Blackhat 以及 BIG4 等顶级学术会议发表,拥有五十余项安全领域专利,国内 AI 安全领域启蒙书籍《 Web 安全之机器学习入门》《AI 安全之对抗样本入门》作者。作为主要负责人,领导并推动了国内著名开源安全项目 AdvBox 和 OpenRASP 的研发与运营推广。




