
作者 | 蔡芳芳
采访嘉宾 | 刘京娟、贾扬清、王峰
作为开源大数据项目的发端,Hadoop 兴起至今已经超过十五年。在过去这十数年里,开源大数据领域飞速发展,我们见证了多元化技术的兴起和变迁。
为了从代码托管平台汇聚的海量数据里,通过数据处理和可视化的方式,深刻洞察开源大数据技术的过去、现在和未来,并为企业和开发者在开源大数据技术领域的应用、学习、选型和技术研发等方面提供有益参考,开放原子开源基金会、X-Lab 开放实验室、阿里巴巴开源委员会共同发起了「2022 开源大数据热力报告」项目。
报告从 Hadoop 发展的第 10 年,即 2015 年起,收集相关公开数据进行关联分析,研究开源大数据进入新阶段后的技术趋势,以及开源社区的运作模式对技术走向的助推作用。
经过对最活跃的 102 个开源大数据项目进行研究,报告发现:每隔 40 个月,开源项目热力值就会翻一倍,技术完成一轮更新迭代。在过去 8 年里,共发生了 5 次较大规模的技术热力跃迁,多元化、一体化、云原生成为当前开源大数据发展趋势的最显著特征。
开放原子开源基金会副秘书长刘京娟表示,报告希望重点对如下人群有所帮助:
(1)从事大数据技术研发的企业和开发者。他们可以通过报告,了解大数据技术的发展趋势,从而指引学习方向并提升自身的技能,从技术活跃度的角度为应用开发的技术选型提供一定的参考。
(2)有志于为开源项目贡献代码的开发者。开源大数据细分领域众多、百花齐放,但也存在一些相对薄弱的环节,比如数据安全和数据管理等,开发者可以从多个细分领域切入,帮助这些领域更好地发展。
(3)开源大数据项目的运营者或者维护者。他们能够从优秀项目的热力发展趋势中,获取经验和规律,从而用更成熟的方式运营开源项目。
对于大数据从业者们来说,开源大数据项目热力迁徙背后的技术发展逻辑是怎样的?大家应该如何应对新技术趋势带来的挑战?针对这些问题,近日 InfoQ 与阿里巴巴集团副总裁、阿里巴巴开源委员会主席、阿里云计算平台事业部负责人贾扬清,Apache Flink 中文社区发起人、阿里巴巴开源大数据平台负责人王峰(花名莫问)聊了聊。
用户需求多样化推动技术多元化
以 Hadoop 为核心的开源大数据体系,从 2015 年开始转变为多元化技术并行发展。
一方面,原有 Hadoop 体系的产品迭代趋于稳定。部分 Hadoop 生态项目(如 HDFS)成为其他新兴技术的基础依赖,一些常见的开源大数据组件组合,比如 Flink+Kafka、Spark+HDFS 等,经过开源生态市场的检验,比较成熟也容易上手,已经成为相对固定的标准化选择。
另一方面,开发者的热情分别涌向「搜索与分析」、「流处理」、「数据可视化」、「交互式分析」、「DataOps」、「数据湖」六大技术热点领域,每个热点领域集中解决某个特定场景问题。
报告呈现出的热点领域热力跃迁(热力值大幅度跳变)情况与此相符:「数据可视化」在 2016 和 2021 年经历了两次热力跃迁,「搜索与分析」和「流处理」 在 2019 年热力跃迁, 「交互式分析」和 「DataOps」从 2018 年和 2021 年经历了两次热力跃迁、 「数据湖」在 2020 年热力跃迁。
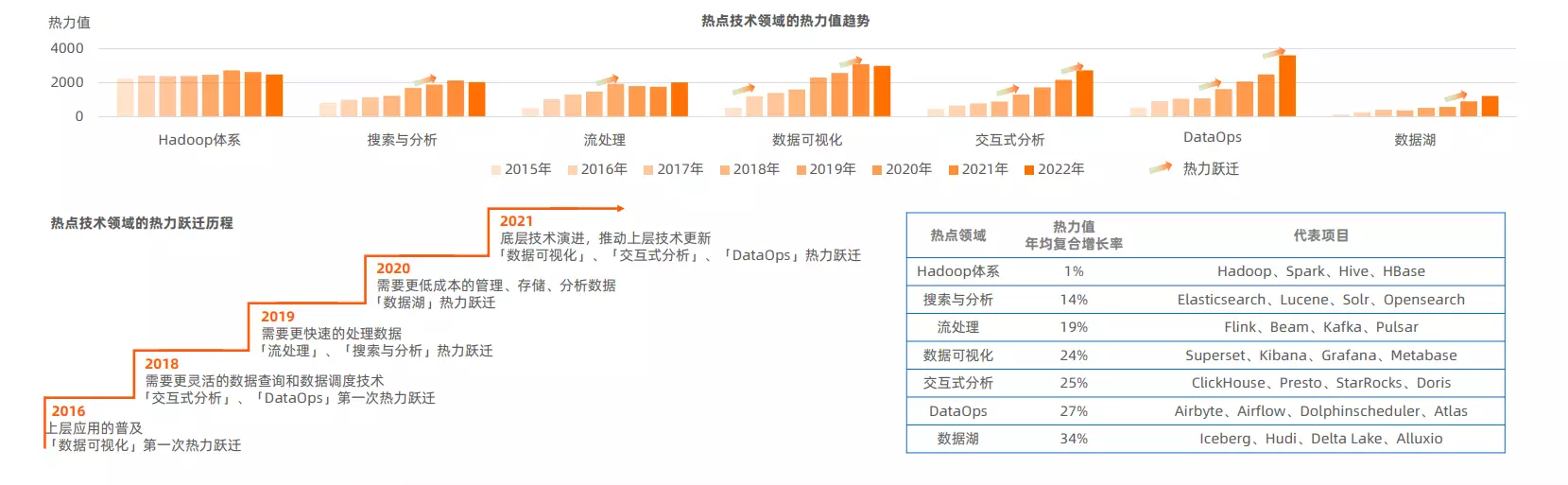
这也呼应了大数据应用场景和规模变化的趋势:从上层数据可视化应用普及,到数据处理技术升级,再到数据存储和管理的结构性演变,最终,数据基础设施能力的提升又反过来推动上层应用技术革新。
贾扬清认为,热力跃迁背后体现了技术发展是一个螺旋上升的过程,用户侧需求推进技术往前一步之后,就需要系统侧再往前一步,以实现更好的可扩展性、更低的成本和更高的灵活性;当系统侧达到了一个能够承载更大规模数据计算处理分析的状态,大家又会开始寻求是不是可以把用户侧或业务侧的数据分析、可视化等做得更好。比如,流行的开源大数据可视化工具 Apache Superset,其背后的商业公司 Preset 最近就在 BI 方面做新的探索。
相比已经趋于稳定的原 Hadoop 体系,新场景之下,如数据治理分析、流式计算+OLAP、数据湖等,开源大数据组件仍然在不断推陈出新,未来存在比较多变数。
随着这些后起的大数据开源组件越来越庞杂,开发者们驾驭开源数据平台的难度也与日俱增。这其实给想要利用开源组件构建企业级大数据平台的企业带来了相当大的挑战。
首先,大部分业务场景都需要多个大数据组件互相配合使用,这就要求技术团队同时掌握很多不同的大数据组件,并且要能融会贯通、知道如何将这些组件更好地组合到一起。但大部分中小公司或传统企业并没有足够的大数据基础人才。因此企业可能需要一个比较专业的大数据团队,为他们提供设计、咨询以及指导,让他们能够把开源大数据的组件串联在一起形成一整套解决方案。
其次,当业务规模增大,企业对大数据平台的稳定性、安全性和高可用能力的要求也会随之提高,必然会增加构建大数据平台的复杂性。比如系统出现问题时,到底问题在哪里,怎么去诊断、分析、报警,做到实时可观测,这些配套能力都是开源大数据组件本身不具备的。这需要在开源生态上做出配套的工具或产品,帮助企业更好的发现问题、定位问题和解决问题。
以上挑战,在贾扬清和王峰看来,都可以通过云上标准化产品在一定程度上解决掉。但从另一个角度来看,云本身其实也给大数据技术栈带来了一些新的挑战。
云原生带来的变化和挑战
报告显示,2015 年后出现的新项目,无一例外均在云原生方向进行了积极的技术布局。Plusar、 DolphinScheduler、JuiceFS、Celeborn、Arctic 等诞生于云原生时代的开源项目如雨后春笋般破土成长。这些新项目在 2022 年的热力值占比已经达到 51%,其中,数据集成、数据存储、数据开发与管理等领域都发生了非常大的项目更迭,新项目热力值占比已经超过了 80%。从 2020 年开始, Spark、 Kafka、Flink 等主流项目也陆续正式支持 Kubernetes。
云原生趋势下,开源大数据技术栈正处于重构之中。其中数据集成领域的重构相比其他细分领域走得更快一些。
随着云端多样化数据收集需求的爆发,以及下游数据分析逻辑的变化,数据集成从“劳动密集型”ETL 工具演进到灵活高效易用的“数据加工流水线”。传统数据集成工具 Flume、 Camel 处于平稳维护状态, Sqoop 已于 2021 年从 Apache 基金会退役。与云原生结合更紧密的 Airbyte、Flink CDC、 SeaTunnel、 InLong 等项目飞速发展。
在报告的热力趋势中可以看到,云原生数据集成在 2018 年超越了传统数据集成,从 2019 年开始,这一演进历程加速,热力值逐年翻倍。不少新孵化的项目热力值年均复合增长率超过 100%,增长势头强劲。
过去几年,数据源和数据存储逐步迁移到云端,更多元化的计算负载也运行到了云端。云底座实际上改变了开源大数据的很多前提,作为这场变革的亲历者,王峰感触颇深。
十多年前,王峰就参与了基于 Hadoop 做大数据开发的工作,当时他还是比较初级的工程师,大部分工作还基于本地机器,需要考虑的问题包括选择什么机型、多大磁盘、磁盘大还是内存大等。
如今,大数据的底座变成了云上的虚拟机、容器、对象存储、云存储,所有开源项目从一开始就要考虑弹性架构、要考虑如何具备很好的可观测性、要考虑怎么跟 Kubernetes 等云原生生态天然对接,等等,这些问题已经存在于大家的潜意识里,改变了很多开源项目在初始阶段的预期。
同时在云上运行之后,数据架构也会发生变化。比如计算与存储分离已经成为大数据平台的标准架构,是现在大家默认一定要考虑的问题,因此不管是什么大数据组件(Flink、Hive、Presto 等等),在做数据 Shuffle 的时候都要考虑到不能再依赖本机、不能假设会有本地磁盘,因为在云上机器是必定会迁移的。这就需要一个通用的 shuffle 服务来协助完成这项工作,把云上资源模型变化考虑进去做自适应地调度。前不久阿里捐献给 Apache 基金会的开源项目 Celeborn,做的就是帮助计算引擎提升数据 shuffle 性能的工作。
技术层面,云给原有的开源大数据体系带来的挑战不止于此。比如调度基础,以前大家都默认在 Hadoop 上做资源管理和调度,上云之后大家则都拥抱 Kubernetes 生态,基于 Kubernetes 来做编排和调度。但 Kubernetes 作为在线调度服务,调度大规模数据计算任务存在瓶颈,阿里内部本身对 Kubernetes 做了非常多改进。
另外,比如云存储虽然优势多多,但也存在传输带宽、数据 locality 方面的缺陷。一些后起的开源项目如 JuiceFS、Alluxio 等,就是为了解决云存储加速的问题而生,阿里云 EMR 上的大数据存储加速服务 JindoData 也在做这方面的工作。王峰表示,开源大数据体系还在不断进化,仍需要走一段路,才能真正与云原生彻底结合。
大数据从业者如何面向未来发展?
作为技术创新的实验场,云原生带来了更灵活的资源弹性和更低的存储、运维成本,让很多企业可以更大胆地在云上做一些尝试,提升了大家试错、试新的意愿,自然也更有利于创新技术或软件的成功。贾扬清观察到,海外有很多新软件或新引擎会走“先吸引用户、然后把用户转化为客户”的路。在他看来,这将来在国内可能也会成为一个趋势,因为云确实提供了一个很好的资源以及软件分发环境。
不过云只是给了大家一把很好的锤子,如果一个人能力不强,用的时候也可能会砸到自己的脚。比如,由于用户在云上获得资源更加容易,可能就会比较随意地进行数据存储和计算,进而造成浪费。因此从业务角度,云服务商与用户其实是一体的,云服务商在大规模开源数据体系之上,需要根据企业的需求做更多数据治理方面的工作,帮助用户用好云这把锤子,避免资源浪费。贾扬清表示,如何更有效地使用云平台、云资源已经成为企业越来越关注的需求,现在主要是企业级软件在做这方面的工作,将来可能会有更多开源工具出现。
畅享未来的数据工程趋势,贾扬清认为有三个方向是大数据从业者可以重点关注的。首先是云化,即用云来解决系统架构的问题,涵盖了离线实时一体化、大数据 AI 一体化、流批一体化、湖仓一体化四个层面。现在不管是开源项目还是闭源产品其实都在朝着更加一体化的方向发展,Flink 社区新的子项目 TableStore 也是在这个方向上做的一个探索,追根究底是为了在一定程度上降低大数据技术栈的复杂度,未来计算引擎可能也会更多地跟数据治理、数据编排工具结合成为一体化的数据解决方案。
其次是上层数据应用会变得更加简单,从长远来看,对于最终用户,所有的数据都可以使用通用的 SQL 方式进行分析。最后,将来会有更多的生态发展起来,无论是阿里云的 Flink、EMR 还是海外的 Databricks、Snowflake、Bigquery 都还只是工具平台,在这些数据平台之上需要有更多类似于 Saleforce 的企业来做出更丰富的垂直解决方案,最终形成更加繁荣的数据生态,当然前提是数据平台先做好标准化。
王峰同样很看好数据生态未来的发展,尤其对于开源大数据来说,生态更加关键。现在欧美很多数据领域的公司,虽然各有特色,但相互之间也能形成协同,这样大家就会处于一个良性的竞争状态。王峰认为,这有助于推进各厂商的产品走向标准化,能够给用户和客户带来很多好处。从整个应用市场的角度来说,形成标准化之后,各方能够比较低成本地去接入这个数据工程生态,反过来可以一起把整个市场蛋糕做大。
身处快速发展的数据工程领域,大数据从业者如何面向未来发展?将来岗位角色、职责是否会发生变化?
贾扬清认为,系统工程师、数据工程师、数据科学家这些角色未来会继续存在。但云已经解决了很多系统问题,所以越来越多工程师角色会开始往上层业务走。偏系统搭建的底层工作,即系统工程师角色,可能会更多聚集在提供标准化服务的云数据服务商、数据引擎服务商等,其他企业则会更加关注业务本身,把人力更多投入在偏数据科学以及上层业务里,不再需要那么多系统工程师。这是社会分工精细化的必然结果。
对于数据科学家、数据工程师,他们的职责会更多地偏重于利用数据实现业务价值,包括根据业务需求做数据建模、数据治理等工作,不用再像以前一样去解底层系统和运维等问题,因为这些问题已经被系统工程师、被云解得很好了。




