

在移动端高效的模型设计中,卷积拆分和分组几乎是不可缺少的思想,那么它们究竟是如何高效,本身又有哪些发展呢。
什么是卷积拆分
一个多通道的普通 2D 卷积包含了三个维度,分别是通道,长,宽,如下图(a)。
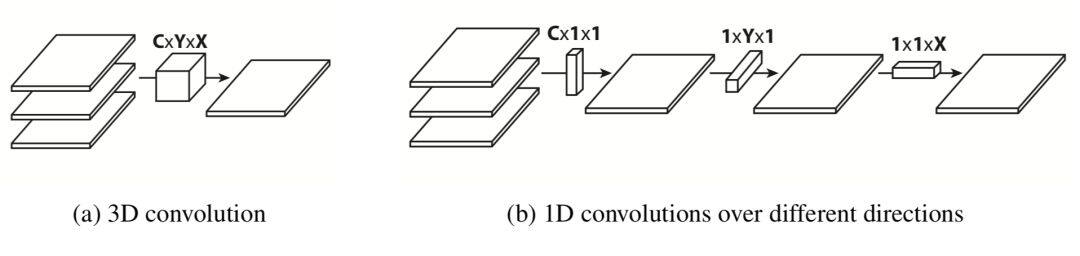
然后将这个卷积的步骤分解为 3 个独立的方向[1],即通道方向,X 方向和 Y 方向,如上图(b),则具有更低的计算量和参数量。
假如 X 是卷积核宽度,Y 是卷积核高度,C 是输入通道数,如果是正常的卷积,那么输出一个通道,需要的参数量是 XYC,经过上图的分解后,参数量变为 X+Y+C,一般来说 C>>X 和 Y,所以分解后的参数对比之前的参数约为 1/(XY)。
对于 3×3 的卷积,相当于参数量降低一个数量级,计算量也是相当,可见这是很高效的操作。
当然,还可以只分解其中的某些维度,比如在 Inception V3 的网络结构中,就将 7×7 的卷积拆分为 1×7 和 7×1 两个方向。从另一个角度来看,这还提升了网络的深度。
什么是通道分组
2.1 分组卷积的来源
标准的卷积是使用多个卷积核在输入的所有通道上分别卷积提取特征,而分组卷积,就是将通道进行分组,组与组之间相关不影响,各自得到输出。
通道分组的思想来自于 Laurent Sifre 在 Google 实习的时候提出的 separable convolution,相关的内部报告可以参考 YouTube 视频https://www.youtube.com/watch?v=VhLe-u0M1a8,具体的实现在它的博士论文[2]中,如下示意图。
对于平移,旋转等刚体运动来说,它们可以被拆分成不同的维度,因此使用上面的 separable convolution,实现起来也很简单,就是先进行通道的分组,这在 AlexNet 网络中还被当作一个训练技巧。
2.2 从 Xception 到 MobileNet
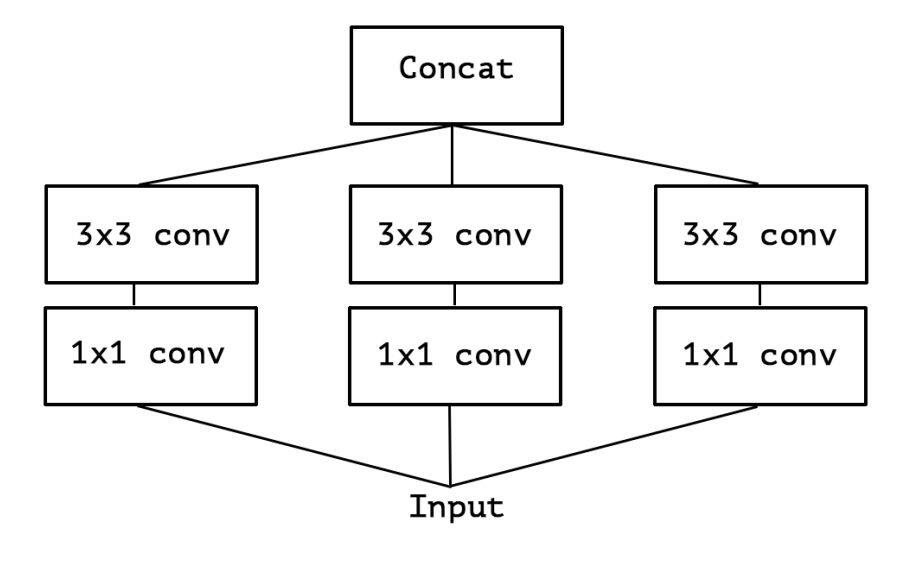
随着 Google 的 Inception 网络提出,这一个相对于 VGG 更加高效的网络也开始进化。到了 Inception V2 的时候,已经用上了上面的思想。

上面就是一个与 Inception Module 类似的模块,只是每一个通道完全一样,这就可以等价于通道分组了。
假如分组的个数与输入通道数相等,Inception 便成为了极致的 inception(extreme inception,简称 Xception[3])。
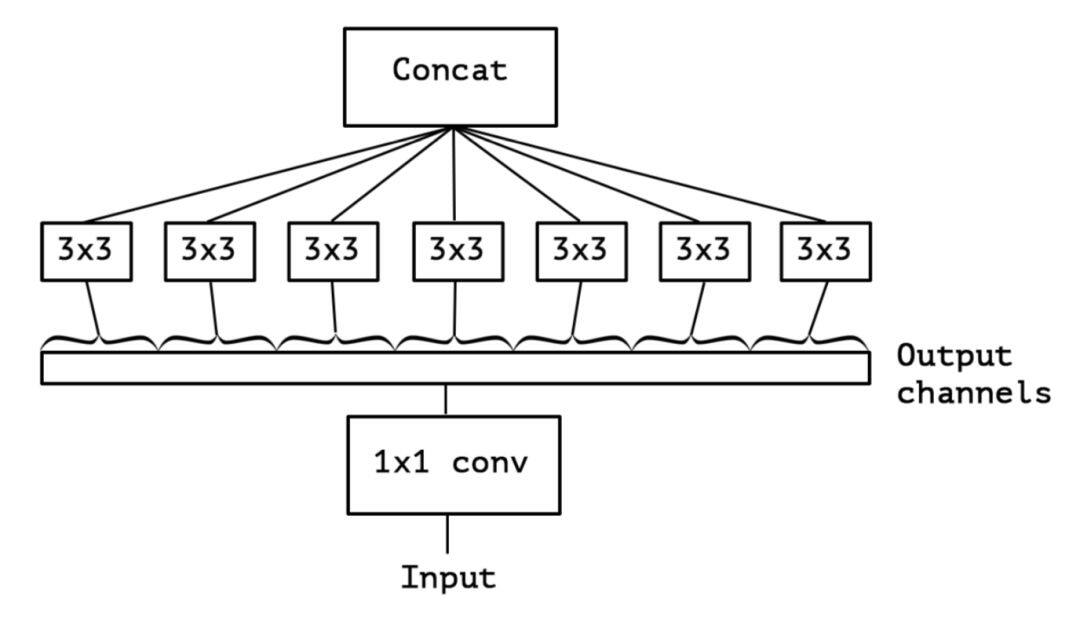
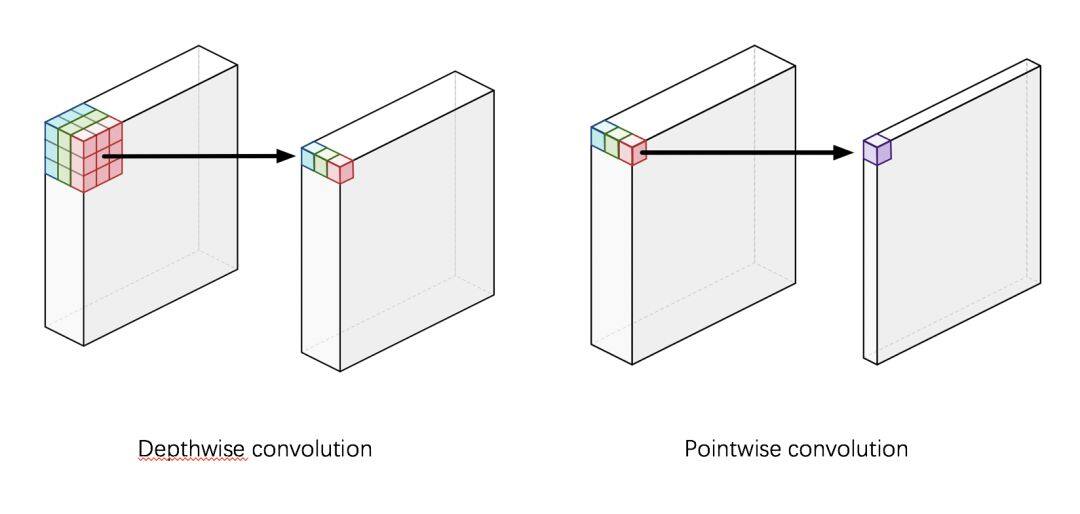
首先经过 1×1 卷积,然后通道分组进行卷积,这样的一个结构随 Tensorflow 的流行而流行,名为 Depthwise Separable Convolution。
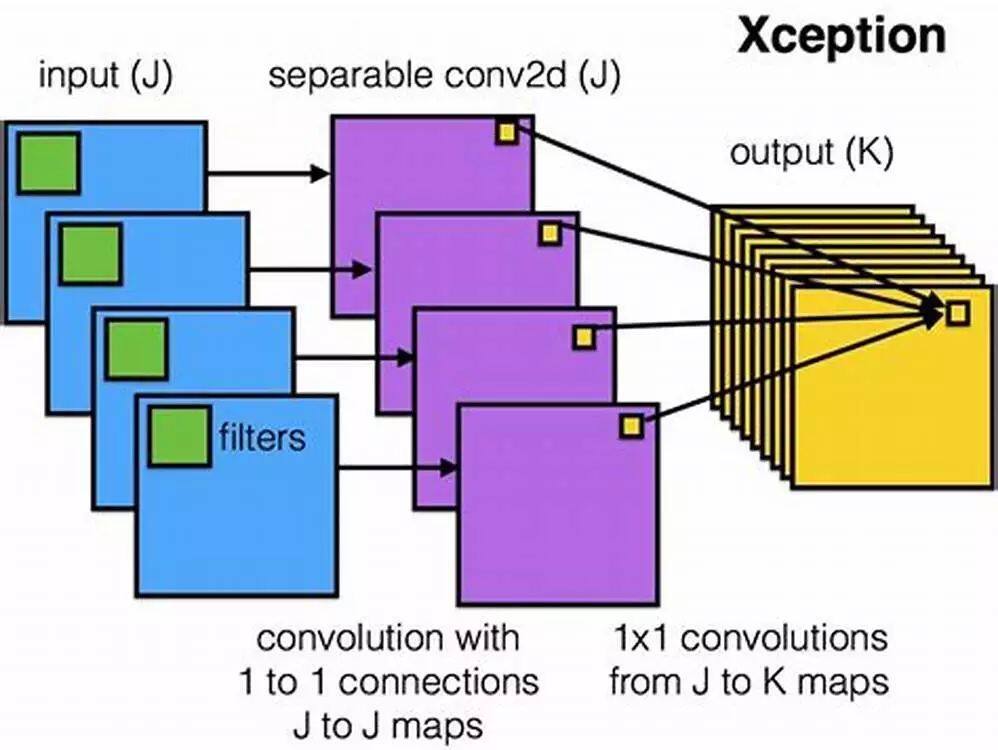
随后 Google 的研究人员提出了 MobileNets[4]结构,使用了 Depthwise Separable Convolution 模块进行堆叠,与 Xception 中的不同是 1×1 卷积放置在分组卷积之后。因为有许多这样的模块进行堆叠,所以两者其实是等价的。
画成二维图,示意图如下:
画成三维图,示意图如下:
使用 Netscope 可视化 MobileNet 的网络如下,当我们看到这个 28 层的网络,又经历了残差网络的洗礼后,顿时有种返璞归真的感觉。

2.3 分组卷积性能如何
令输入 blob 大小为 M×Dk×Dk,输出为 N×Dj×Dj,则标准卷积计算量为 M×Dk×Dk×N×Dj×Dj,而转换为 Depthwise 卷积加 Pointwise 卷积,Depthwise 卷积计算量为 M×Dk×Dk×Dj×Dj,Pointwise 卷积计算量为 M×N×Dj×Dj,计算量对比为:(M×Dk×Dk×Dj×Dj+M×N×Dj×Dj)/M×Dk×Dk×N×Dj×Dj= 1/N+1/(Dk×Dk),由于网络中大量地使用 3×3 的卷积核,当 N 比较大时,上面卷积计算量约为普通卷积的 1/9,从而降低了一个数量级的计算量。
性能上也没有让我们失望,在只有 VGG16 不到 1/32 的参数量和 1/27 的计算量的同时还能取得与之相当的性能。
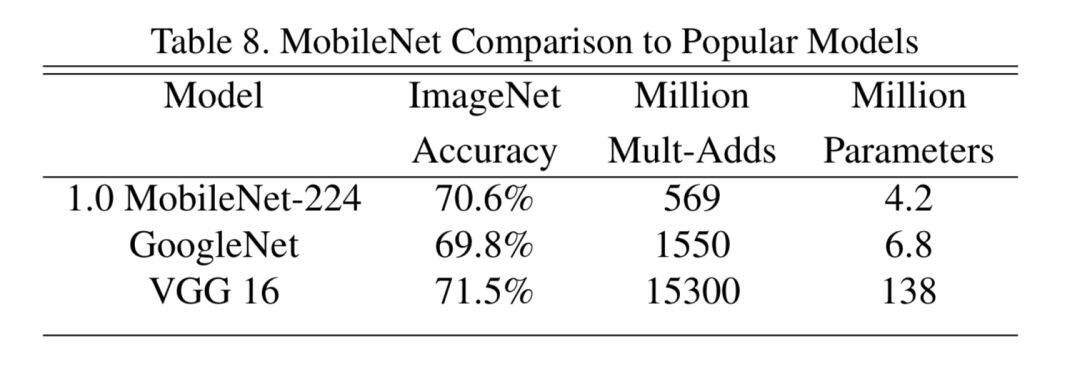
关于更多细节的解读和实验对比,此处就不再做介绍了,可以阅读以前的一篇文章。
2.4 分组卷积性能的进一步提升
对于 MobileNet 这样的网络结构,还可以从两个方向进行提升,第一个是增加分组的信息交流,第二个是更加智能的分组。
简单的分组使得不同通道之间没有交流,可能会导致信息的丢失,Shufflenet[5]重新增加了通道的信息交换。具体来说,对于上一层输出的通道,先做一个 Shuffle 操作,再分成几个组进入到下一层,示意图如下:
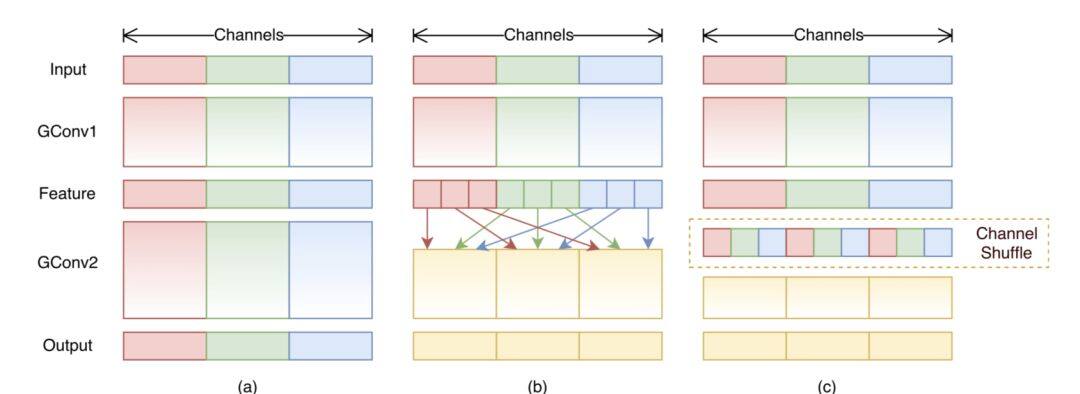
另一方面,MobileNet 的分组是固定,ShuffleNet 中的通道的打乱也是一个确定的映射,那是不是可以基于数据来学习到更加合适的分组呢?Condensenets[6]给出了确定的回答。
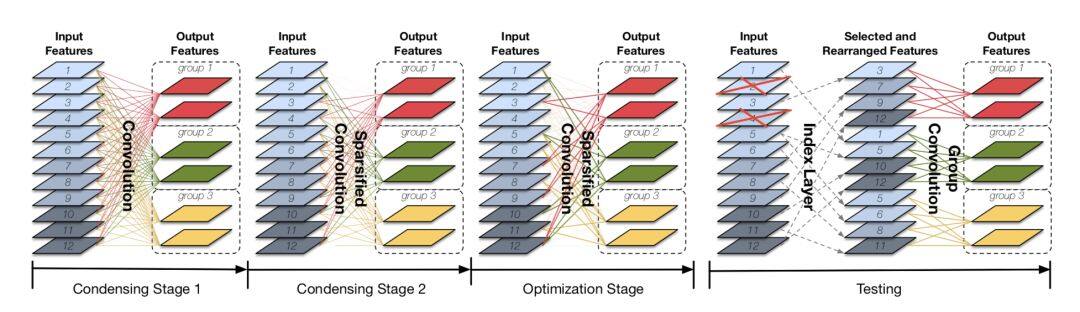
更多的解读,我们已经放在了知识星球中,感兴趣的可以关注。
分组卷积结构的发展
ResNet 虽然不是残差连接的发明者,但使得这一思想为众人痴狂。MobileNet 也不是分组卷积的发明者,但同样是它使分组的思想深入人心,原来这样的网络结构不仅不降低准确率,还能大幅度提升计算效率,尤其适合硬件并行。
自此,分组的思想被不断拓展研究,下面我们主要考虑分组的各个通道存在较大差异的研究。
3.1 多分辨率卷积核通道分组网络
这一类网络以 SqueezeNet[7]为代表,它以卷积层 conv1 开始,接着是 8 个 Fire modules,最后以卷积层 conv10 结束。
一个 fire module 的子结构下图,包含一个 squeeze 模块加上一个 expand 模块。Squeeze 模块使用 1×1 卷积进行通道降维,expand 模块使用 1×1 卷积和 3×3 卷积用于通道升维。
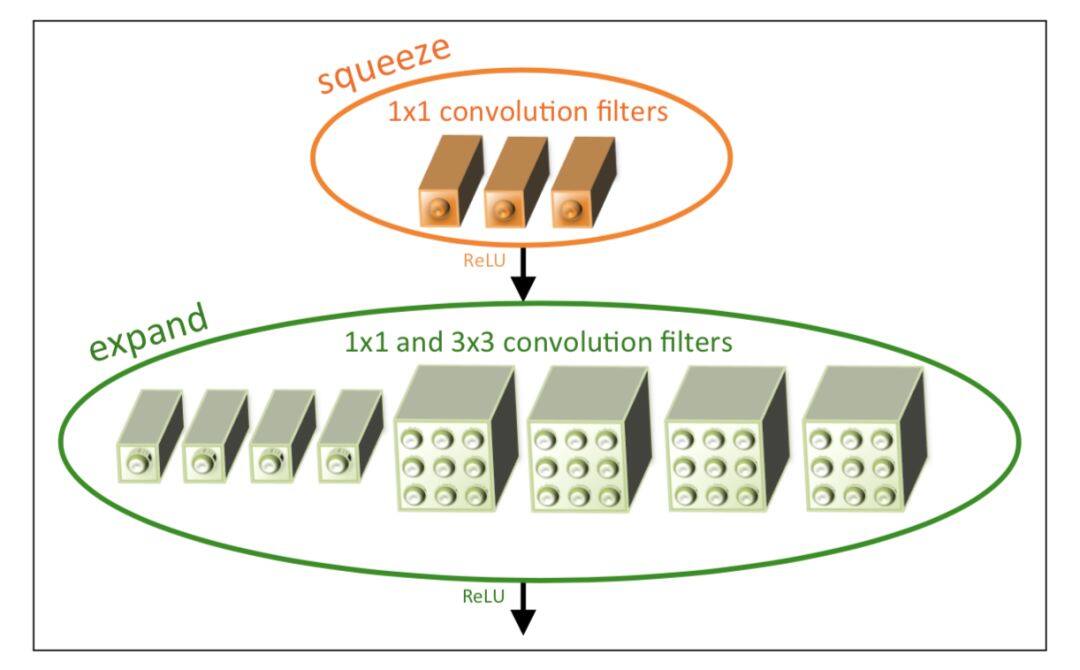
Squeezenet 的压缩比率是惊人的,只有 AlexNet 1/50 的参数量,能达到相当的性能。
3.2 多尺度通道分组网络
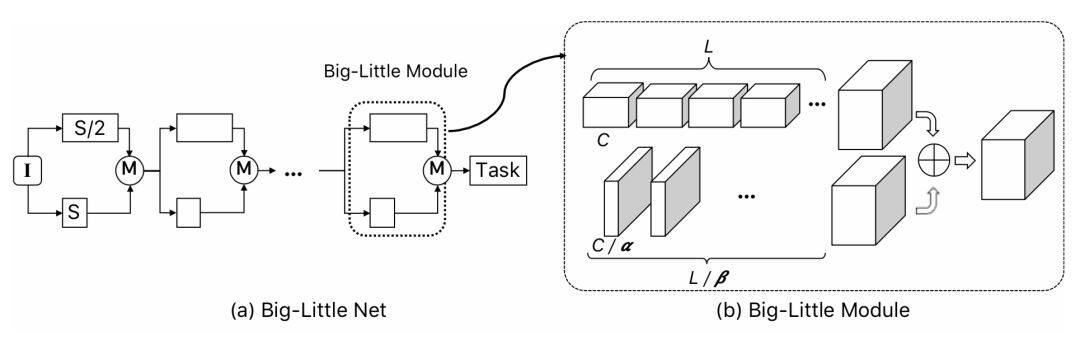
这一类结构采用不同的尺度对信息进行处理,对于分辨率大的分支,使用更少的卷积通道,对于分辨率小的分支,使用更多的卷积通道,以 Big-Little Net[8]为代表,K 个分支,尺度分别为 1/2^(K-1),如下图结构。
当然,如果两个通道在中间的计算过程中还存在信息的交流,则可以获得更高的性能,比如 Octave Convolution[9]。
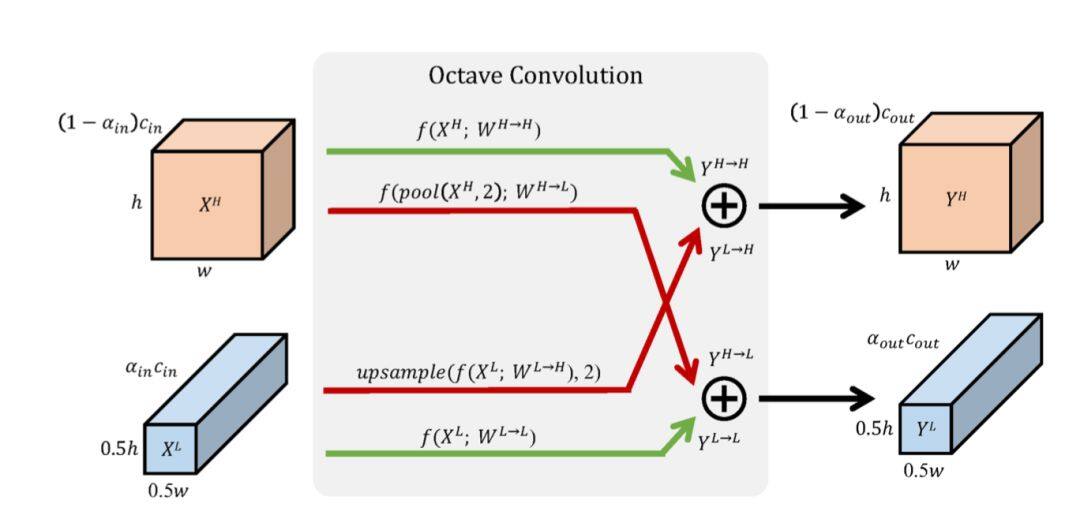
卷积核通过因子被分为了高分辨率和低分辨率两部分,低分辨率具有较多的通道,被称为低频分量。高分辨率具有较少的通道,被称为高频分量,两者各自学习,并且进行信息的融合。高分辨率通道通过池化与低分辨率通道融合,低分辨率通过上采样与高分辨率通道融合。最终在 22.2GFLOPS 的计算量下,ImageNet Top-1 的精度达到了 82.9%。
3.3 多精度通道分组网络
除了还分辨率和卷积核上做文章,还可以在计算精度上做文章,这一类结构以 DSConv[10]为代表,它将卷积核分为两部分,一部分是整数分量 VQK,一部分是分数分量 KDS,如下图:
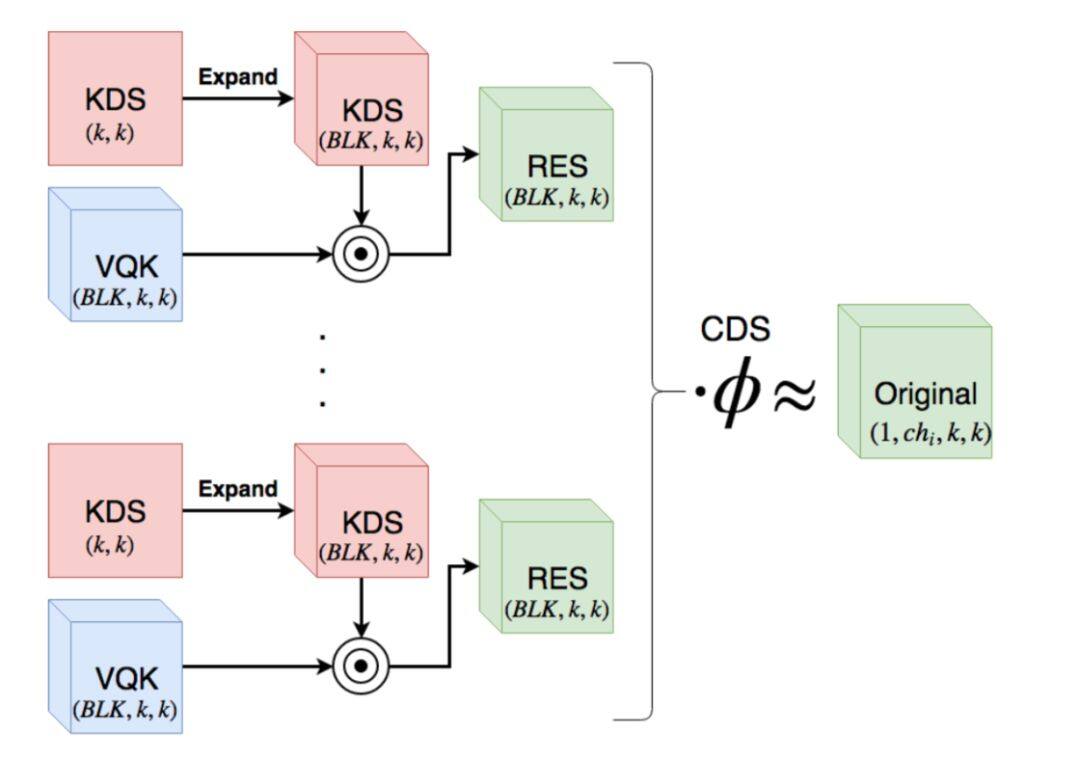
VQK(Variable Quantizes Kernel)只有整数值,不可训练,它的权重值从预训练模型中计算而来。KDS(kernel distribution shifter)是浮点数,包含一个 kernel 级别的偏移量,一个 channel 级别的偏移量。
这一个模型在 ResNet50 和 ResNet34,AlexNet,MobileNet 等基准模型上取得了 14x 参数量的压缩,10x 速度的提升。
除了上面这些思路外,还有很多可以做的空间,大家可以去多实验写论文填坑,有三就帮到这里了。
参考文献
[1] Jin J, Dundar A, Culurciello E. Flattened convolutional neural networks for feedforward acceleration[J]. arXiv preprint arXiv:1412.5474, 2014.
[2] Sifre L , Mallat, Stéphane. Rigid-Motion Scattering for Texture Classification[J]. Computer Science, 2014.
[3] Chollet F. Xception: Deep Learning with Depthwise Separable Convolutions[J]. computer vision and pattern recognition, 2017: 1800-1807.
[4] Howard A G, Zhu M, Chen B, et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications[J]. arXiv preprint arXiv:1704.04861, 2017.
[5] Zhang X, Zhou X, Lin M, et al. Shufflenet: An extremely efficient convolutional neural network for mobile devices[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 6848-6856.
[6] Huang G, Liu S, Van der Maaten L, et al. Condensenet: An efficient densenet using learned group convolutions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 2752-2761.
[7] Iandola F N, Han S, Moskewicz M W, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size[J]. arXiv preprint arXiv:1602.07360, 2016.
[8] Chen C F, Fan Q, Mallinar N, et al. Big-little net: An efficient multi-scale feature representation for visual and speech recognition[J]. arXiv preprint arXiv:1807.03848, 2018.
[9] Chen Y, Fang H, Xu B, et al. Drop an octave: Reducing spatial redundancy in convolutional neural networks with octave convolution[J]. arXiv preprint arXiv:1904.05049, 2019.
[10] Gennari M, Fawcett R, Prisacariu V A. DSConv: Efficient Convolution Operator[J]. arXiv preprint arXiv:1901.01928, 2019.
作者介绍
言有三,公众号《有三 AI》作者,致力于为读者提供 AI 各个领域所需的系统性的专业知识。
原文链接
本文源自言有三的知乎,链接:
https://zhuanlan.zhihu.com/p/69449808

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论