

道路车辆功能安全的 ISO 26262 标准提供了一整套确保系统功能安全的要求,但机器学习(包括深度学习)方法自身的一些特点会影响安全或安全评估。
• 识别危险(Identifying hazards)。 机器学习的使用可能产生新的危险类型,这些并不是组件的故障(malfunctioning)带来的。特别是,人类与机器学习实施的高级功能之间复杂行为交互会产生危险的状况,应在系统设计中予以缓解。
• ML 使用水平。通过使用端到端方法,机器学习可在体系结构层面广泛使用,或者仅限于在组件级别使用。不过端到端(E2E)方法挑战了这样的假设,即复杂系统被定义成一个有自己的功能的、分层的的组件分解。
• 所需的软件技术。 ISO 26262 要求在软件开发生命周期的各个阶段使用许多特定技术。虽然其中一些仍然适用于机器学习组件而其他组件可以很容易地进行调整,但许多仍然特别偏向于使用命令式编程语言实现代码的假设。
• 非透明。所有类型的 ML 模型都包含编码的知识,但这种编码对人来说在某些类型中比其他类型更难以解释。例如,用于天气预报的贝叶斯网络更容易解释,因为节点是表示人类定义的概念的随机变量,例如“降水类型”,“温度”等。相比之下,神经网络模型被认为是不透明的。增加 ML 模型表达能力通常以牺牲透明度为代价。不透明是安全保障的障碍,因为评估员更难以建立模型按预期运行的信心。
• 错误率。 ML 模型通常不能完美地运行并且出现错误。因此,即使对于测试数据,ML 组件的“正确性”也很少实现,并且必须假定它周期性地出错。此外,虽然错误率的估计也是 ML 开发过程的任务,但只有其可靠性的统计保证。最后,即使误差的估计是准确的,也可能无法反映系统在有限输入集的误差率,要知道真实误差是基于无限样本集。在使用 ML 组件设计安全系统时必须考虑这些特性。
• 基于训练。用可能遇到的输入子集来训练基于监督和无监督学习的 ML 模型。因此,训练集必然是不完整的,并且不能保证甚至代表可能的输入空间。此外,可能通过捕获训练集附带的细节而不是一般输入的学习过程会出现过度拟合(overfitting)。 强化学习(RL)受到类似的限制,它通常仅在训练期间探索行为的子集。这种 ML 组件性能的不确定性是对安全的威胁。另一个因素是,即使训练集具有代表性,也不足以代表安全危机案例(safety-critical cases),因为这些案例在输入空间通常是较少的。
• 不稳定。通常使用局部优化算法训练更强大的 ML 模型(例如 NN),并且可能存在多个最优。因此,即使训练集保持不变,训练过程也可能产生不同的结果。但是,更改训练集也可能会改变最佳状态。一般说,不同的最优结构可能在架构上相距甚远,即使它们在性能上相似。这样,难以调试模型或重复使用已经安全评估的部分。
一种解决方案—贝叶斯深度学习(BDL)
在自动驾驶软件中,不存在隔离的单个组件。通过减少单个组件错误来提高安全性对于安全的 AV 软件是必要的 - 但还不够。即使每个组件独立地满足可接受的容错,误差的累积也会带来灾难性的后果。相反,了解错误如何通过组件流水线传播是至关重要的。例如,在图 1 中,感知组件 - 检测另一车辆的指示灯 - 影响预测组件如何预测车辆的运动,最终影响驾驶决策。由于流水线中上游(upstream)组件的分类错误会影响下游(downstream)组件,至少每个组件都应该传递下游其输出的局限性和不确定性。相应地,每个组件应该能够接受流水线上游组件的不确定性作为输入。此外,这些组件的不确定性必须以一种原则方式组合在一起,产生有意义的整个系统不确定性度量,并根据这些度量做出安全决策。
不确定性指知识有限的状态,这时候无法准确描述现有状态、未来结果或不止一种可能的结果。 由于它涉及深度学习和分类,不确定性还包括模糊性; 它是关于人类定义和概念的不确定性,而不是自然界的客观事实。
实际上存在不同类型的不确定性,我们需要了解不同应用所需的类型。这里将讨论两个最重要的类型 - 认知(epistemic)和任意(aleatoric)不确定性。
认知的不确定性反映了对哪个模型生成收集数据的无知(ignorance)。给定足够的数据可以解释这种不确定性,并且通常称为模型(model)不确定性。认知不确定性对于模型非常重要:
1、安全危急(safety critical)应用,因为需要来理解与训练数据不同的例子;
2、训练数据稀疏的小数据集。
观察认知不确定性的一种简单方法是用 25%的数据集训练一个模型,并用整个数据集训练第二个模型。仅在 25%数据集上训练的模型比在整个数据集上训练的模型具有更高的平均认知不确定性,因为它看到的例子更少。
对于数据无法解释的信息,任意不确定性解释了这种不确定性。例如,图像中的任意不确定性可归因于遮挡(因为相机无法穿过物体)或缺乏视觉特征或图像的过度曝光区域等。只要通过提高观察所有可解释变量(explanatory variables)的精度就能解释这些不确定性。对于以下情况,任意不确定性建模非常重要:
1、大数据情况,其中认知不确定性大多被解释;
2、实时应用,无需采用昂贵的蒙特卡罗采样(Monte Carlo sampling),因为可以将任意模型(aleatoric models)形成输入数据的确定性函数。
实际上可以将任意不确定性分为两个类别:
1、数据相关或异方差不确定性(Homoscedastic uncertainty)取决于输入数据并预测为模型输出;
2、任务相关或同方差不确定性(Homoscedastic uncertainty)不依赖于输入数据。它不是模型输出,而是一个对输入数据保持不变的常数并在不同任务之间变化。因此,它可以被描述为任务相关不确定性。
任意不确定性是输入数据的函数。因此,深度学习模型可以用修改的损失函数来学习预测任意不确定性。对于分类任务,贝叶斯深度学习模型有两个输出,即 softmax 值和输入方差,而不是仅预测 softmax 值。教模型预测任意方差是无监督学习的一个例子,因为该模型没有可供学习的方差标签。
可以通过改变损失函数来模拟异方差任意不确定性。由于这种不确定性是输入数据的函数,就可以学习从输入到模型输出的确定性映射来预测。对于回归任务,通常使用欧几里德/ L2 损失进行训练:损失= || y-ŷ|| 2。要学习异方差不确定性模型,可以用以下方法代替损失函数:
Loss = 0.5||y−ŷ ||2/σ2 + 0.5logσ2
同方差不确定性的损失函数类似。
对认知不确定性建模的一种方法是在测试时使用蒙特卡洛退出采样(dropout sampling),一种变分推理。注:退出是一种避免在简单网络中过拟合的技术,即模型无法从其训练数据到测试数据的泛化。在实践中,蒙特卡洛退出采样意味着模型包括退出并且模型测试时打开退出多次运行得到结果分布。然后,可以计算预测熵(预测分布的平均信息量)。
建模不确定性的原则方法是贝叶斯概率理论(事实上,一个理性的代理,其置信必须是贝叶斯方式)。贝叶斯方法使用概率来表示不确定性,并且用于每个单独组件表示其输出的主观置信度。然后,可以通过流水线向前传播这种置信度。为此,每个组件必须能够输入和输出概率分布(distribution)而不是仅仅数字(numbers)。组件输出到下游成为上游预测不确定性的函数,使决策层能够考虑上游错误分类的后果,并采取相应的行动。在该领域存在其他传达不确定性的方法,例如集合(ensembling)。但是,这些技术的不确定性不一定能以有意义的方式组合在一起(对于复杂的软件流水线而言)。此外,这些方法捕获的不确定性类型不一定适用于安全分析。传统的自动驾驶研究使用贝叶斯工具来捕捉不确定性。但是,此类系统向深度学习转变时带来了困难。深度学习系统如何捕捉不确定性?
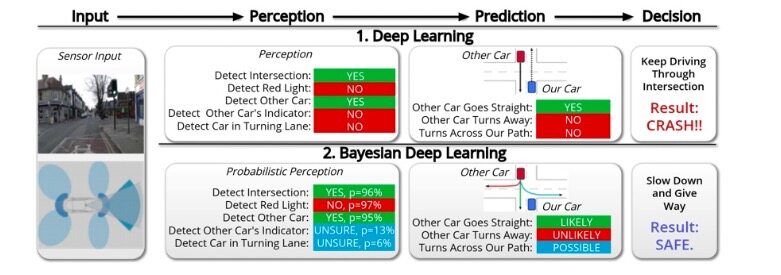
图 1 DL 和 BDL 的比较
虽然存在许多贝叶斯模型,但深度学习获得了细节和复杂关系的最佳感知性能。因此,贝叶斯深度学习(BDL)成为选择。贝叶斯统计(Bayesian statistics)是统计学领域的一种理论,其中关于世界真实状态的证据用置信程度(degrees of belief)来表达。贝叶斯统计学与实践中的深度学习相结合意味着在深度学习模型预测中加入不确定性。早在 1991 年就有了神经网络中引入不确定性的想法。简而言之,贝叶斯深度学习在典型神经网络模型中发现的每个权重和偏差参数上增加了先验分布(prior distribution)。过去,贝叶斯深度学习模型并不经常使用,因为它们需要更多参数进行优化,这会使模型难以使用。然而,最近贝叶斯深度学习变得越来越流行,并且正在开发新技术在模型中引入不确定性,同时参数量与传统模型相同。
图 1 是一个在整个流水线中不确定性传播但能防止灾难的示例,其中标准 DL 与 BDL 进行对比。在这种情况下,标准的 DL 艰难地做出预测,而 BDL 则输出概率预测来说明每个模型对世界的无知。这时候,自动驾驶车正在接近一个交叉路口,一个车辆迎面而来,其意图是转弯穿过我们自动驾驶车的道路。考虑到模型检测到另一辆车,但未能检测到它是在转弯车道还是否正在闪烁指示灯。通过深度学习,经模型架构传递硬分类的结果,系统无法预测到来的汽车可能会转向。相比之下,BDL 系统可能在迎面而来车辆的位置和指标出错,但它能够将其不确定性传播到下一层。在第二阶段,考虑到其他车辆存在的概率、指示灯和转弯车道的位置,预测组件可以计算迎面而来车辆阻碍自动驾驶车的概率。在第三阶段,决策部分对其他车辆预测的运动范围做出反应,产生完全不同的结果并避免碰撞。
图 2 和图 3 显示了一个场景理解系统这些不确定性的示例。图 2 是贝叶斯深度学习用于语义分割。通常,深度学习模型在不考虑不确定性的情况下(c)进行预测(b)。建议从每层估计不确定性(c)传递贝叶斯流水线。(b)显示语义分割,其中类单独着色。(c)显示不确定性,其中深蓝色以外的颜色表示像素更不确定。该模型对类边界、远距离和不熟悉的目标缺乏信心。

图 2 语义分割,图片源自黄浴的知乎
图 3 是贝叶斯深度学习用于立体视觉深度估计。此示例说明了立体视觉的常见故障情况,可观察到该算法错误地处理了红色汽车上的反射和透明窗口。重要的是,观察到 BDL 算法还预测了这种错误输出(b)的高不确定性(c)。

图 3 深度估计,图片源自黄浴的知乎
接下来讨论三个组件组成的架构流水线:感知层、预测层和决策层。
• 感知层
感知系统应解决三个重要的任务:估计周围场景的语义,理解几何形状,并估计车辆本身的位置。
先说语义。语义场景理解系统的作用是根据环境的外观对环境的类别和状态进行分类。视觉图像具有很高的信息量,但让算法去理解并不重要。语义分割是一项常见任务,它根据一组预定义的类标签对像素进行分割并对每个分割段进行分类。例如,给定视觉输入(图 2a),图像被分割成道路,路径,树木,天空和建筑物(图 2b)。大多数算法都会进行硬分类,但是使用贝叶斯深度学习的语义分割算法可以捕获不确定性。
再说几何。除了语义之外,感知系统还必须推断场景的几何形状。这对于确定障碍物和路面位置很重要。可以使用诸如超声波或激光雷达等距离传感器来解决该问题。然而,已经有监督和无监督深度学习的方法(见图 3)证明了视觉解决方案。
最后是定位。感知系统必须估计车辆的位置和运动。在不熟悉的环境中,这通常是 SLAM 的任务。有益的事是把车辆和全局地图,特别是某些场景特征(例如车道位置和到交叉路口的距离)校准。自动驾驶车必须推断所在的车道以及相对于前方十字路口的位置。这同样也有贝叶斯深度学习的计算机视觉方法。
但是感知中也存在其他问题,而不确定性在这些问题中起着核心作用。机器人专家长期以来一直在研究机器人感知的不确定性。对运动规划、滤波和跟踪等方面,几何特征的不确定性已经在考虑。另一种常见的用途是给定每个传感器的概率模型(似然函数)情况下,解决传感器融合问题。传感器融合结合了多个传感器输出,使用贝叶斯规则(Bayes rule)来构建一个比任何一个传感器都更有信心的场景视角。这种好处是一种结合所有可用信息、减少地图和定位(mapping & localization)错误的原则性方法。这种不同类型传感器组合的方式,特别是激光雷达、雷达、视觉和红外传感器,有助于克服其中任何一个传感器的物理限制。
感知组件通常放置在流水线的起始处,并且必须处理原始传感器输入。感知组件的输出应包括预测和不确定性,这对于输出更精确的目标检测(通过滤波和跟踪)和更准确的状态估计(通过改进的地图和定位)非常有用。不应在感知组件的输出处评估一个硬判决(hard decision)。相反,应该将不确定性明确地传播到预测层。大多数研究都没有考虑超出这点的不确定性,但它是后续预测和决策层的关键输入(见图 1)。例如,不确定性可以是来自感知系统输出分布的一组样本来传播。但是,这种方法在实时系统使用时受到限制。决定一个有效获得感知系统认知不确定性(epistemic uncertainty)的表示法,是一个悬而未决的问题。
• 预测层
尽管场景感知组件可以识别障碍物位置,但许多障碍物是动态因素,例如行人和车辆。场景预测有助于自动驾驶车估计代理的运动,以避免危险的情况,例如前方车辆可能突然制动,或行人可能进入车路。鉴于典型的激光雷达范围(~100m)和法定速度限制(~30m / s),预测通常不会提前超过~3.3s。
给定外部代理的行为模型,场景预测可以被构建为部分可观察的马尔可夫决策过程(POMDP,partially observable Markov decision process)。在没有模型的情况下,可以使用逆强化学习(IRL)。IRL 是从观察中推断另一个代理的潜在奖励函数的问题。然后,可以在决策层中使用推断的奖励函数来模拟人类驾驶的示例,比如,一种学徒学习(apprenticeship learning),或者仅仅是为了预测外部代理的动作。该方法学习一个奖励函数,给出特定场景的特征,旨在将其推广到新的场景。 IRL 的变体,如采用高斯过程的贝叶斯 IRL 、使用神经网络的深度 IRL,也是一样操作。最近引入概率深度方法,行人或车辆的概率输出预测容易可视化,这对于调试和可解释性是有利的。例如,状态占用(state occupancy)概率的热图可以使用。其他预测方法试图构建一个自回归模型,这个模型根据感知层给出的视觉片段预测未来的分割。这种方法在视觉上也是可以解释的,但由于缺乏几何知识,预测的不准确超过 0.5 秒。
然而,似乎尚未针对场景预测调查输入的不确定性。在目标存在和位置感知层输出的输入不确定性有利于复杂流水线中的预测。但实时地实现这一点非常困难。如果预测层的输出是占用概率(occupancy probabilities)图,每个被跟踪的对象的贡献则被存在概率加权,例如,与其位置的概率分布函数卷积。这是一个示例开放问题。
• 决策层
决策层通常包括路线规划(route planning)、运动规划和反馈控制组件来控制自动驾驶车。对于每个组成部分,贝叶斯决策理论是一种决定最大化给定效用函数(utility function)行为的原则方法。此外,贝叶斯决策理论提供了一种反馈机制,可以采取行动来减少代理的不确定性。此反馈用于在以后做出更明智的决策(例如,移动以获得更好的视图)。这依赖于在 POMDP 领域的工具。
决策部分的两个主要任务是路线规划和运动规划。
• 路线规划
该任务涉及根据道路网络先验图结构(graphical structure)的导航,用诸如 A *的算法解决最小成本路径问题。存在几种比 A *更适合大型网络的算法。对许多任务来说,路线规划是大多已解决的问题。
• 运动规划
给定要走的街道,运动规划(MP)根据自动驾驶传感器观察到的当前道路状况如交通灯状态、行人和车辆等进行导航。大多数 MP 方法都是基于采样的路径规划器或图搜索算法。经典路径规划考虑自动驾驶车的状态空间,分为 “自由空间”和“障碍” 二类。定位和制图的不确定性使这种自由障碍的区分模糊,这是一些基于采样的规划者所考虑的。
为了在动态不确定性下很好地规划运动,精确的概率动力学模型(probabilistic dynamics model)是至关重要的。虽然运动学模型适用于低惯性(low-inertia)无滑动(non-slip)情况,但需要更复杂的模型来模拟惯性,并且需要概率模型来模拟打滑(slip)。动力学不确定性建模尤其是在泥土或砾石道路上安全驾驶特别相关,其中滑动(slipping)是常见的并且应该是预期的。最近,BDL 动力学模型已被用于控制器的设计,应该会扩展到 MP。
端到端学习范式
端到端的学习范式,共同训练系统的所有组成部分,从感知、预测到决策结束。这是一个有吸引力的范例,因为它允许每个组件相对于期望的最终任务形成一个最佳的表示。或者,不提供终端任务的信号或知识情况下单独训练单个组件。例如,单独训练感知系统,可能会导致一种表示有利对自动驾驶车上方云彩的准确分割,而不是识别前方车辆。端到端训练使感知系统学习对最终任务最有用的场景。
但是,端到端训练信号需要大量数据。这是因为传感器输入到驱动命令的映射是复杂的。为了更快学习,在每个组件的任务中使用辅助损失(auxiliary losses)的模型约束法是有用的。在实践中,可能先训练单个组件(例如语义分割和预测等),然后采用具有辅助损失的端到端训练对它们微调。
对串行预测-决策流水线架构的批评来自于是假设外部世界演变独立于自动驾驶车的决策。然而,周围的行人和车辆肯定会根据自动驾驶车的决定来决定行动,反之亦然。例如,需要多智能体规划(multi-agent planning)的驾驶情况包括车道合并、四种停车标志、追尾碰撞避让、让路以及避免另一个盲点。这种多智能体规划可以将预测和决策组件耦合以共同预测外部世界状态和条件自动驾驶车的决策。这样的架构避免了今后关于未来外部场景状态的边际分布的决策(边际概率分布可以覆盖整个道路,具有不可忽略的占用概率)。总而言之,联合推理多智能体场景的方法是基于概率模型的强化学习,已经扩展到 BDL。
参考文献
R Salay et al. “An Analysis of ISO 26262: Using Machine Learning Safely in Automotive Software”,arXiv 1709.02435, 2017
Google WayMo Safety Report, “On the road to fully self-driving”, 2017
R McAllister et al.“Concrete Problems for Autonomous Vehicle Safety: Advantages of Bayesian Deep Learning”,IJCAI,2017
本文来源:
https://zhuanlan.zhihu.com/p/77028137
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论