

本文来自“深度推荐系统”专栏,这个系列将介绍在深度学习的强力驱动下,给推荐系统工业界所带来的最前沿的变化。本文主要介绍一篇 ICCV 2019 Oral 上的论文[1],在 CNN 结构的启发下成功将 GCN 的可训练深度从 3/4 层拓展到了 56 层,大幅度提高了图卷积网络的性能,并开源了源代码。
摘要
卷积神经网络(CNN)在各种领域取得了令人瞩目的成果。他们的成功得益于能够训练非常深的 CNN 模型的巨大推动力。尽管取得了积极的成果,但 CNN 未能正确解决非欧几里德数据的问题。
为了克服这一挑战,利用图卷积网络(GCN)构建图来表示非欧几里德数据,并借用 CNN 的相关概念并应用它们来训练这些模型。GCN 显示出不错的结果,但由于梯度消失问题,它们仅限于非常浅的模型。因此,大多数最新型的 GCN 算法都不会超过 3 或 4 层。
作者提出了成功训练非常深层的 GCN 的新方法。他们借用 CNN 的概念,主要是 residual / dense connections(残差、密集连接) 和 dilated convolutions(膨胀卷积、扩张卷积、空洞卷积) ,使它们能够适应 GCN 架构。
residual / dense connections:解决由网络加深导致的梯度消失问题
dilated convolutions:解决由于 pooling 而导致的空间信息丢失,把卷积核膨胀了,增大了感受野,但没有增加参数数量
作者通过大量实验,展示了这些深层 GCN 框架的积极的效果。最后,使用这些新概念构建一个非常深的 56 层的 GCN,并展示它如何在点云语义分割任务中显著地提升了效果(相当于最先进的 3.7%mIoU|均交并比)。
背景介绍
GCN 网络在近几年发展迅猛。目前用于预测社交网络中的个体关系、提高推荐引擎的预测、有效分割大规模点云等领域。CNN 的成功的一个关键因素是能够设计和训练非常深层的网络模型。但是,现在还不清楚如何恰当地设计非常深层的 GCN 结构。
有一些研究工作研究了深度 GCN 的限制因素,堆叠多层图卷积会导致常见的梯度消失的问题。这意味着通过这些网络的反向传播会导致过度平滑(over-smoothing),最终导致顶点的特征收敛到相同的值。由于这些限制,大多数最先进的 GCN 不超过 4 层。
梯度消失在 CNNs 中并不是一个陌生的现象。它们也对此类网络的深度增长提出了限制。
ResNet 在追求非常深的 CNN 方面向前迈出了一大步,因为它引入了输入层和输出层之间的残差连接(residual connection。这些连接大大减轻了消失梯度问题。今天,ResNet 可以达到 152 层及以上。
DenseNet 提供了一个扩展,引入了 across layers。更多的层可能意味着由于 pooling 而导致更多的空间信息丢失。这一问题也通过 Dilated Convolutions(扩张/膨胀卷积)来解决。
这些关键概念的引入对 CNN 的发展产生了实质性的影响,相信如果能很好地适应 GCN,它们也会有类似的效果。
方法论
Residual Learning for GCNs
在最初的图形学习框架中,底层映射 H(以图形为输入并输出一个新的图形表示)是需要学习的。受 ResNet 启发,作者提出了一个图的残差学习框架,通过拟合另一个残差映射 F 来学习所需的底层映射 H 。在
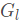
通过残差映射 F 变换了后,进行逐点加法得到
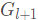
。残差映射 F 把一个图作为输入并为下一层输出一个残差图的表示
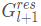
。在实验中,作者将这个残差模型称为 ResGCN。
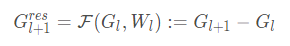
Dense Connections in GCNs
DenseNet 中提出了一种更有效的方法,通过密集的连接来改进信息流并重用层之间的特征。在 DenseNet 的启发下,文中采用了类似的思想到 GCN 中,以利用来自不同 GCN 层的信息流。也就是说,
包含了来自
以及之前的所有 GCN 层的转换。在实验中,作者称之为 DenseGCN。
Dilated Aggregation in GCNs
为了减轻由池化聚集操作造成的空间信息损失,扩展卷积(dilated convolutions)被提出作为一种对连续池化层的替代选择。为 dilation 扩大感受野的同时没有失去分辨率。作者认为 dilation 也有助于 GCN 的感受野。
因此,他们将扩张聚合(dilated aggregation)引入到 GCN 中。有许多可能的方法来构建一个扩张的邻居。他们在每一个 GCN 层后使用一个 Dilated k-NN 去寻找扩张邻居并构建了一个扩张图(Dilated Graph)。为了得到更好的推广,作者在实践中还使用了随机扩张(stochastic dilation)。
实验
论文中提出了 ResGCN 和 DenseGCN 来处理 GCN 的梯度消失问题。为了获得一个大的感受野,他们还定义了一个扩张的 GCN 图卷积(dilated graph convolution)。为了验证作者的框架,他们对大规模点云分割任务进行了大量的实验,并证明他们的方法显著提高了性能和效果。
作者设计了一个包含上述所有成分的深度 GCN 来研究它们的实用性。他们选择三维点云的语义分割作为一个应用,并在 Stanford Large-Scale 3D Indoor Spaces Dataset (S3DIS,斯坦福大规模三维室内空间数据集)上显示了结果,该数据集包含来自三个不同建筑的六个区域的三维点云。这个数据集在 6000 平方米的区域内总共包含 695878620 个点,并用 13 个语义类进行注释。
网络结构
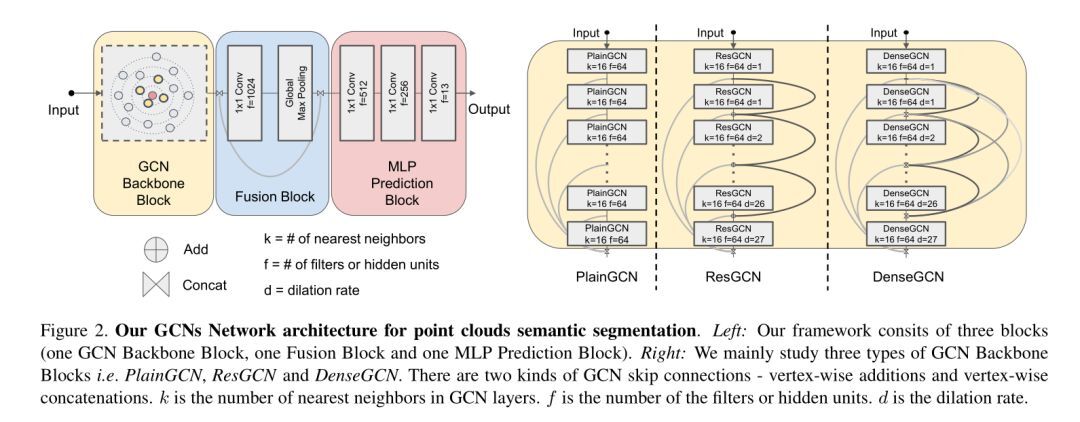
如下图所示,实验中的所有网络结构都有三个块(a GCN backbone block, a fusion block and an MLP prediction block)。GCN backbone block 是实验中唯一不同的部分。例如,PlainGCN 和 ResGCN 之间的唯一区别是,作者向 ResGCN 中的所有 GCN 层添加了 residual skip connections。PlainGCN 和 ResGCN 具有相同数量的参数。同样,DenseGCN 是通过在 PlainGCN 中添加稠密的图连接和 dynamic dilated k-NN 来构建的。
而 fusion block 和 MLP prediction block 保持一致,以便所有架构进行比较。fusion block 用于融合全局和多尺度局部特征。它将从每个 GCN 层的 GCN backbone block 中提取的顶点特征作为输入,并连接这些特征,然后将它们通过 1×1 卷积层和最大池化层。最大池化层将整个图的顶点特征聚合为全局特征向量。然后重复全局特征向量,并将其与所有先前 GCN 层的所有顶点特征连接起来,以融合全局和局部信息。
MLP prediction block 以融合特征作为输入,应用三个 MLP 层对各点进行分类预测。在实践中,MLP 层实现为 1×1 卷积层。
实验结果
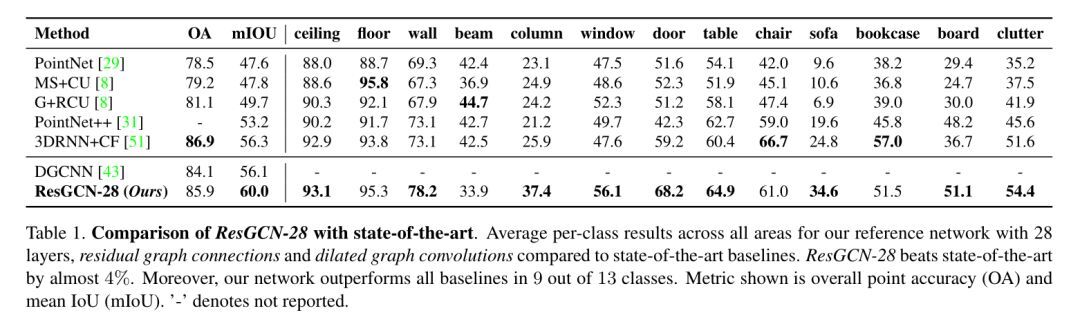
作者将重点放在残差图连接(residual graph connections)上进行分析,因为 ResGCN-28 更易于训练,速度更快。该网络包含了方法论章节中提出的想法,作者将此网络(ResGCN-28)与下表中的几个最新 baseline 进行了比较。实验结果表明:ResGCN-28 比最先进的高出近 4%,而且,文中的网络在 13 个类中有 9 个类超过了所有 baseline,显示的指标是总体精度(OA)和平均 IoU(MIoU)。
小结
作者研究了如何将已证实的有用概念(residual connections, dense connections 和 dilated convolutions)从 CNN 引入 GCN,并回答了以下问题:如何使 GCN 更深?
大量实验表明,在 GCN 中加入 skip connections,可以减轻训练难度,这是阻碍 GCN 进一步发展的主要问题。此外,dilated graph convolutions 有助于在不损失分辨率的情况下获得更大的感受野。即使只有少量的近邻,深度 GCN 也能在点云分割上获得较高的性能。尽管 ResGCN-56 只使用 8 个最近的邻居,而 ResGCN-28 使用 16 个邻居,但它在这项任务中的表现非常出色。
实验表明,能够在 80 个 epochs 内训练 151 层的 GCN;网络融合得很好,取得了与 ResGCN-28 和 ResGCN-56 相似的结果,但只有 3 个最近的邻居。由于计算上的限制,无法详细研究如此深入的体系结构,并将其留给将来的工作。
最后附上论文一作李国豪在知乎上的回答[2]:
目前常见的图卷积神经网络一般都是 3、4 层,我们关注的问题是图卷积神经网络 GCN/GNN 是否也能和一般的卷积神经网络 CNN 一样加深到 50+层而不会有 Vanishing Gradient 问题,我们提出了 ResGCNs,DenseGCNs 和 Dilated GCN,MRGCN 等结构,甚至能训练收敛 152 层 GCN,并在点云分割任务上取得了比较好的效果。
以及论文开源代码:
TensorFlow:https://github.com/lightaime/deep_gcns
PyTorch:https://github.com/lightaime/deep_gcns_torch
参考
1. Deep GCNs: Can GCNs Go as Deep as CNNs?
2. 论文原作者知乎楼层:https://www.zhihu.com/question/336194144/answer/761770679
本文授权转载自知乎专栏“深度推荐系统”。原文链接:https://zhuanlan.zhihu.com/p/86352650

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论