

2 月 12 日,才云市场团队奔赴上海,在阿拉小优总部 1 楼举办了“Kubernetes Meetup 中国 2017”第一场——上海站。继 2016 年 Kubernetes Meetup 四城联动之后,才云 2017 年的 Meetup 阵容更加强大,布道城市范围更广,为更多 Kubernetes 爱好者带去技术分享。
此次上海活动请来了:谷歌大脑资深工程师,拥有 12 年谷歌工作经验的陈智峰博士;小米科技基础架构工程师,主要负责深度学习平台的陈迪豪;才云首席大数据科学家郑泽宇以及才云新晋大将赵慧智。各路大神联袂出席为大家带来一场纯技术饕餮盛宴。本文将从活动整体情况以及现场参与人员来回顾此次活动。

嘉宾精彩演讲回顾
陈迪豪《深度学习模型应用与实践》
陈迪豪 现为小米科技基础架构工程师,主要负责深度学习平台的开发与维护。国内 TensorFlow 开源框架为数不多的 Contributor ,开发社区活跃贡献者。
此次 Meetup 会上,他介绍了 TensorFlow 深度学习模型的导出和预测,与大家分享了集成 Serving 服务的 Cloud Machine Learning 平台,实现通用的模型升级与分布式预测。

以下为演讲内容分享:
大家好,我是来自小米的陈迪豪,今天我给大家分享的就是《深度学习模型应用与实践》,我主要负责小米内部深度学习平台的开发,之前还做过一些分布式存储及一些基础工作。目前主要专注于 TF,K8S 社区,维护容器监控工具。
今天的议题主要包括这四部分:

TensorFlow 是一个数值计算的 library。目前主要用在深度学习上面,有 C++ 以及 Python 的接口。目前已经支持 CPU 以及 GPU 的训练,也支持分布式。
接下来是一个比较简单的 TensorFlow 应用。
第一步:准备训练数据。
第二步:定义一个 graph,就是 TF 里面的运行图
这是一个线性回归的模型,它只有两个参数,一个是斜率,一个是截距。
第三步,创建 Session 运行,通过运行几个 epoch。
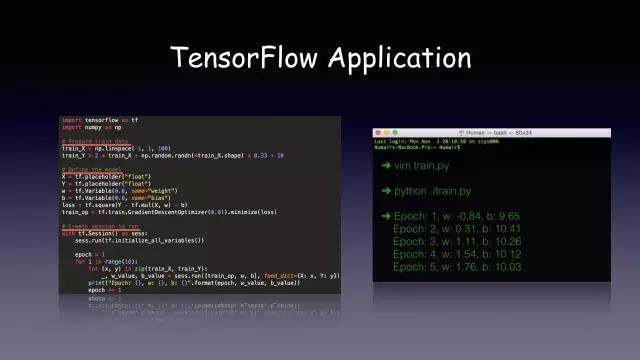

以上就是 TF 的一个应用。我们通过 TensorBoard 看到该应用的训练效果。下面是某个 TF 模型的 graph。
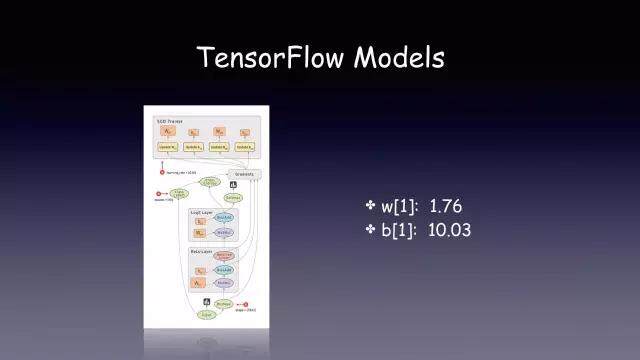
图左就是模型的 Graph,右边是通过训练得到的参数,这两部分组成了我们 TF 的模型。
有了这个模型,那么我们怎么去用?TF 里面一般有两种方法:Checkpoint(saver)和 Exporter。
我来介绍一下 checkpoint,它的用法很简单。先定一个 saver 的对象,然后在你想保存变量的时候,指定一个 checkpoint 的路径就可以了。在定义 saver 的时候,可以指定你需要保存的一些变量,如果没有指定的话,它就会把所有定义的模型变量写到文件里面。
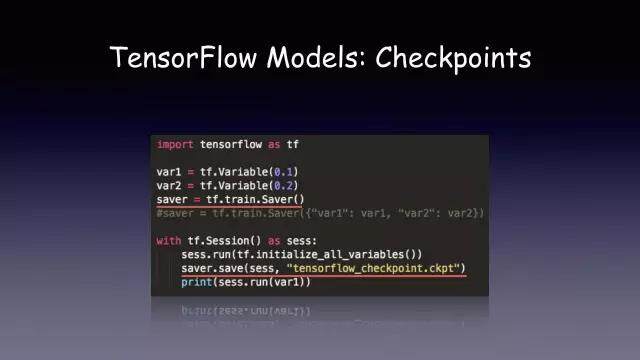
有了 checkpoint,接下来要怎么用呢?
一种方式是重新加载 checkpoint 文件后,把变量直接打印出来,实际上这个实践意义不是很大。另一种我们常用的方法就是,在我们训练的时候,先去检查我们的 checkpoint 文件,如果文件存在,我们就 restore 一下。这样的话,我们的代码就不需要在每次重新启动的时候再进行重新训练。如果你的应用 crash,下一次使用的时候可以从 checkpoint 文件那里进行恢复。这个其实也跟数据库里面的 checkpoint 是一样的。
但是这个 checkpoint 的问题就是,如果我们要去加载来启动一个 serving,我们需要自己去实现。因为在谷歌的 TF serving 里面,这个格式是不支持的,所以谷歌提供了另外一个库 Exporter。
Exporter 的功能就是提供导出能够被 TF serving 识别的 TF 模型。这个导出模型也会包含了模型的 graph 和模型训练得到的参数。用户在导出模型的时候就需要指定这个模型的输入和输出是什么。因为不同的模型(比如语音、图像)的输入输出是不一样的。这个可以由用户自定义。比如我指定了两个输入,和两个或者三个输出,然后调用 export 方法指定模型文件的路径和版本号。这个 input 和 output 是用户自定义的,后面我们在做一个通用的 serving,会再提到这个。
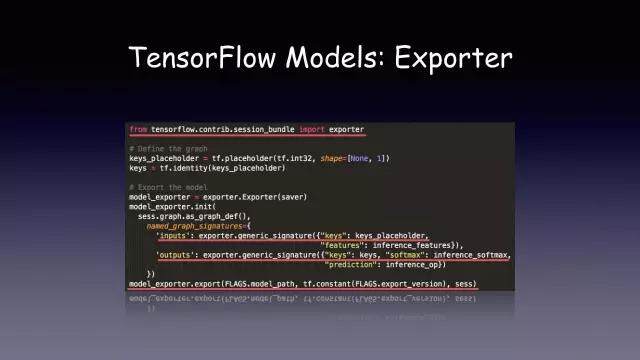
然后导出的文件是这样的,你可以看到你导出的版本号。该版本号下面有三个文件,这三个文件其实跟我们用 saver 保存的 checkpoint 文件内容是一样的。其中 export.meta 是 protobuf 文件,记录了模型的 graph 和参数。

以上就是我给大家演示的 TF 模型具体是什么(现场演示)。
如果大家用过 TF 的安卓 demo,可以发现,它实现的 APK 里面包含一个 Inception 模型,这个模型可以直接在网上下载,下载得到的就是一个 pb 文件,pb 文件里面就记录了 Inception 模型的 graph 和谷歌训练出来的模型参数。
这就是一个 TF 模型,那么怎么去把这个模型加载应用起来呢?
我们要实现一个 serving,要考虑下面三个问题:
1、如何加载这个模型;
2、执行 inference
3、我们提供怎样的 API

因为 TF 最初是用 Python 和 C++ 实现的,目前对加载模型支持最好的就是 Python 和 C++,最近它又加入了 Java 和 Golang 支持。而 inference 需要 CPU 或者 GPU。而对外暴露的 API 则可以选择 HTTP 或者 RPC。以上三个问题是我们自己去实现 Serving 要考虑的。
官方提供了一些例子和文档,我们可以自己去实现 Python 或者 C++ 的应用来加载 TensorFlow 模型。这两者没有谁更好之说,Python 实现的成本会低些,而 C++ 应用的效率可能就会高一点。

如果我们想要使用 CPU 或 GPU 来做 inference 的话,TF 本身 API 是支持的。需要我们在编译的时候,使用–config=cuda 这样的参数。
最后一点,就是关于 Serving 对外提供的 API,我们可以选择 HTTP 或者 RPC。HTTP API 会简单点,而 RPC API 的性能可能会高点。
在这里想给大家重点介绍的是,谷歌开源项目 TensorFlow Serving。该项目是使用 C++ 实现的。由于其自身是基于 TensorFlow API 的,于是 TensorFlow Serving 同时支持 CPU 和 GPU。而在对外暴露的 API 上,它提供的是一个性能比较高的 gRPC 的接口。然后大家可以在 github 上使用。
根据不同的应用场景,我们可以自己实现 Serving 服务,或者直接使用谷歌开源的 TensorFlow Serving。在我们内部,使用的是 TensorFlow Serving。
TensorFlow Serving 架构很简单,下面是官网截图。首先我们编写完 TF 的 Python 的应用后,通过之前介绍的 Exporter 导出训练的模型。然后我们便可以启动一个 Serving 服务来加载该模型,便可以通过 gRPC 接口来访问该 Serving 服务。

另外,TensorFlow Serving 提供了其他比较高级的功能,比如,它可以做 Batch,也可以做模型的 rolling update。那我们如何将 TensorFlow Serving 应用起来呢?这里有几种方法,我来给大家简单介绍一下。
第一种就是直接编译 TensorFlow Serving 项目,生成出来一个与平台相关的可执行文件。运行该可执行文件,指定一个 gRPC 服务端口,便可加载通过 Exporter 中导出文件的模型。
另一种方法就是,我们自己编译一个镜像,里面包含 TensorFlow Serving 和模型文件,然后直接通过该镜像来启动 Serving。
第三种就是我们内部用的比较多的,就是将 TF serving 集成到 Kubernetes 云平台中。
它可以加载任意的 TF 模型,不需要修改 TF seving,而且它对外提供的是一个,他的接口主要是由 Exporter 文件定义的。
第一个是 Model 文件。
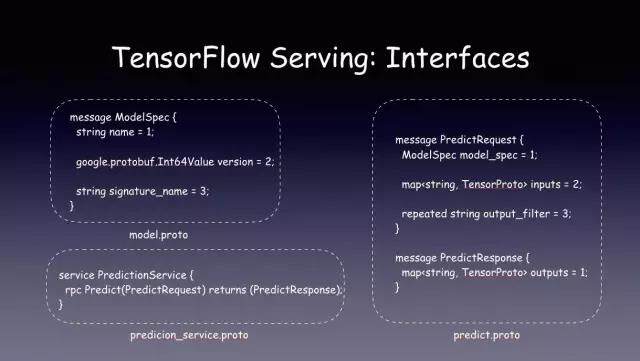
它定义了 protobuf 数据结构和 gRPC 通信接口。本质上是一个 string 和 TensorProto 的 Map,可以直接在 TF 应用的 Graph 中定义,告诉客户端模型的输入和输出格式是什么。
模型预测的 Tensor 本质上是一个多维数组的格式,通过使用 Map<string, TensorProto> 的数据结构,可以灵活定义各种各样模型结构,并且统一访问的 API,即使是图片也可以转成多维数组的格式,这样无论是图片分类、语音生成还是自然语言处理的模型都可以用这种方式定义。
最后就是 gRPC 接口的定义。
以上就是 TF serving 暴露给大家的接口。TF serving 的服务端是由谷歌实现的,客户端则是由自己去写。这个其实跟 TF 关系不是很大。它本质上是一个 gRPC 服务。
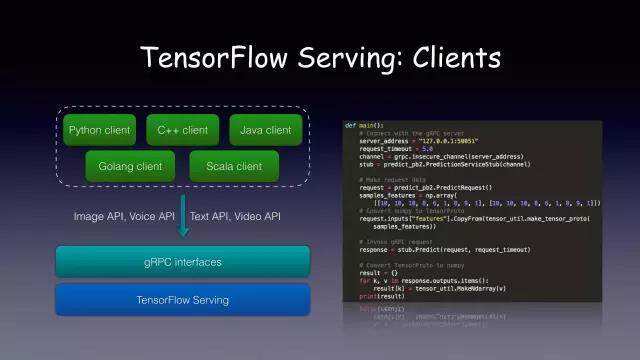
右边就是一个完整的 gRPC 客户端代码。大概只有二十几行,无论是图像分类,自然语言处理都可以通过统一的接口来访问,其中唯一不同的地方就是构建 Tensor 的这部分代码,可以用任意编程语言的多维数组来实现,是一个标准的 Protobuf 对象。
刚介绍的就是,TFserving 的服务。它本质上是一个 C++ 的应用,通过定义统一接口来为不同的 TF 服务。后面我会介绍小米内部真正在使用的机器学习服务。

云计算发展的历史大概是这样的:
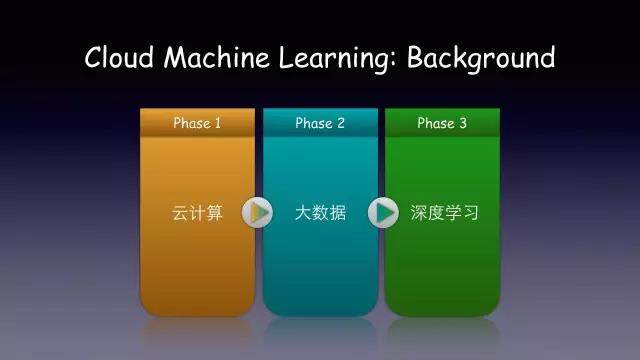
这是整个云计算发展的路线。我们称为 CBA,最开始我们有了分布式服务和云计算(Cloud computing),然后生成了大量数据(Big data),目前非常火热的大家都开始做人工智能(AI)和深度学习。但是大家可能会发现,现在做人工智能大多都直接使用 GPU 等物理资源,这和追求资源共享的云计算甚至是背道而驰的。
而目前主流的深度学习框架,无论是大家用的 TF,或者 Caffe,他们都是 library,没有解决分布式任务的调度和资源隔离问题,大部分应用也是运行在单机上的。我们认为。这可能是一种倒退,认为下一个阶段应该是云深度学习。我们需要一个云平台来解决我们深度学习框架本身的调度以及分布式计算。然后我们开发了 Cloud Machine Learning 平台。它大概的架构是这样的:
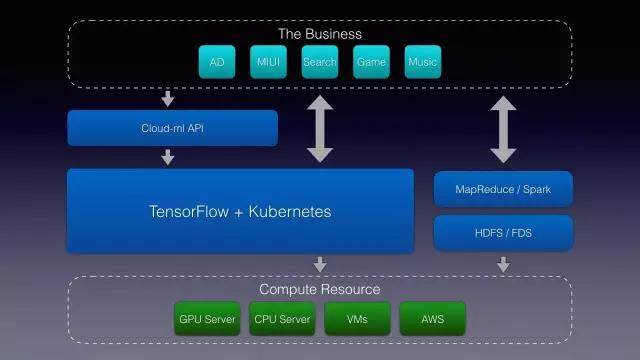
这是深度学习的一些应用代码。他不需要直接申请 GPU,或者 CPU 的计算资源,通过 API 提交,或者说我的 TF 模式已经提交好了。通过你的平台启动一个 TF serving 服务。通过中间的抽象来解决业务对云计算的需求。然后整个 Cloud Machine Learning 主要有三个功能,一是给用户提供了在线的 TF 开发环境,同样也支持 MXNet、Caffe、CNTK 等主流机器学习框架。第二部分,是用户直接提交到云端,然后在云端直接做运算,它支持 CPU 内存和 GPU。那样的话,GPU 计算的时候,就不需要独占资源,然后可以提高整个平台的资源利用率。然后通过 K8S 做资源调度。
第三部分,是我们提供一个模型部署。
最后给大家介绍下我们如何集成 TF serving。提供一个云端的模型。
下图是 Cloud Machine Learning 整个的使用流程:
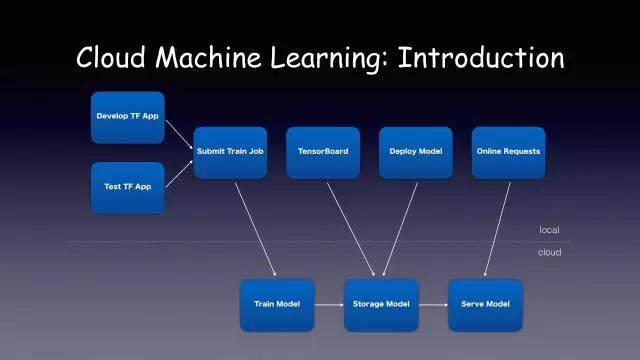
如上图所示:上面是 local 用户的本地开发环境,下面是我们本地的。
用户在本地编写 TF 的代码,然后再在本地进行测试。然后它测试代码没问题的话,它可以向云端指定一个 API,向云端申请机器给我来训练这个模型,然后云端训练完之后,会自动把模型转到我们的分布式存储里面。这时候用户可以用官方的 TF 工具去训练它的状态。如果模型的 metrics 效果不错,可以通过 API 服务来一键部署。现在用户只要写后端代码就可以了。
这个模型服务主要有两个功能,一个是用户直接通过 API 启动在线服务。这个服务内部是基于 TF serving 的,所以它提供的是一个 RPC 的接口。这样的业务可以使用 Golang,Java 或者 Python 去实行调用。
另一个就是一键应用的场景,它可以把这个模型导到 iOS 或者安卓达到手机端。在手机上做预测。
然后目前, 我们提供 Python,C++,Java 等,一些用户是通过 Spark,将它的应用提交到了 Spark 里面,当我运行数据处理的一部分之后,直接通过处理 executor 的接口去访问 TF 的模型,你无论是做 image 的模型,还是文本或者视图的 API,都是一样的。底层是基于 gRPC。
因为是通用的 protobuf 接口,大家在 Github 上可以找到各种语言实现的 gRPC 客户端。主要是 Python,二十几行代码,核心的部分就在于,用户需要将它预测的数据,无论你是图片,还是多维数组,生成一个的预测,下面是一个 Java 的,我节选了一部分。他们预测的一个数据。无论是多少,你都可以使用,然后用 gRPC Java 的 API 来生成。这是小米网 Golang 团队贡献的,使用 Golang 实现的 gRPC 客户端。

上面是参考 Google CloudML 服务,我们实现的通用的命令行客户端,可以直接读取 JSON 数据,然后生成 TensorProto 对象进行预测请求。
大家可以参考我在 Github 上开源的项目找到源代码,地址是 https://github.com/tobegit3hub/deep_recommend_system ,上面包含了模型的导出已经多种语言 gRPC 客户端的代码示例。

最后给大家介绍服务的实践。
首先是这个模型升级。大家都有这个需求,怎么把模型导出,训练数据可以不断地增加,我的模型需要定期去做升级。同时不需要停止我的预测服务。那么对于这个,TF Serving 它本身是支持这种功能的,就是你在导出的时候,指定导出的版本。它默认会有 30 秒的检查时间。当它检查到有新的版本文件的时候,会自动去加大新的模型,这样你预测以后会加载新的模型。然后我们的 Cloud Machine Learning 是兼容 TF serving 的,用户可以把你新导出的模型上传到我们的分布式存储里面,让 TF serving 自动去加载,或者是我们在训练脚本里面使用 export 去指定不同的版本。然后让它自动把模型上传,这样也可以实现 Rolling update。
然后就是怎么实现的问题。这是 Kubernetes 的基本架构。用户如果已经训练得到一个模型文件,需要启动一个 Serving 服务,这是可以请求 cloud-ml 服务的 RESTful API,我们通过获取用户请求的参数,知道模型的路径以及模型版本信息。我们会在后台生成一个 yaml 文件,里面会向 Kubernetes 提交一个 deployment,启动 TF serving。创建一个 service 文件,对外提供一个 IP 的端口。
其实我们不仅支持 TF,因为我们是去实现这种资源管理,支持 TF,mxnet 等十个深度学习框架。

这些深度学习框架我们都制作了对应的 Docker 镜像,用户需要把训练的应用代码提交到平台即可,可以指定需要特定的 TF 版本,或者直接指定 MXNet 基础镜像等,通过选择不同框架来启动对应的服务。
最后总结下,我们介绍了 TensorFlow 的模型格式以及通用的模型访问接口,使用开源的 TensorFlow Serving 可以加载任意的 TensorFlow 模型提供性能较高的 gRPC 接口,我们通过 Cloud Machine Learning 服务更进一步简化了模型服务的部署和使用。如果大家在使用 TensorFlow 模型以及 TensorFlow Serving 服务时有任何疑惑或者考虑也欢迎多多交流。
本文转载自才云 Caicloud 公众号。
原文链接:https://mp.weixin.qq.com/s/0IP0EWkUkr3zTMbXlQoXdg

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论