

欢迎阅读新一期数据库内核杂谈。和所有催更的同学说一声抱歉,由于最近工作实在太忙了,拖更太久了。这一期内核杂谈,书接上文,接着聊NoisePage项目-自动驾驶数据库。这一期介绍的学术论文是 Query-based Workload Forecasting for Self-Driving Database Management Systems,发表在 SIGMOD-2018 年上(说个题外话,那一届 SIGMOD 在休斯顿开,我还去参加了,但当时没注意到这篇文章,光生病了。。。在会场宾馆躺了两天。。。那一届的 best paper 也是 Professor Pavlo 的学生的)。
Why? 为什么要做预测?
做学术研究最重要的一点就是,要讲清楚为什么要做这个研究,Why?预测 workloads,好处是显而易见的。这可以使数据库为将要来的 workloads 提前做好准备,无论是从资源角度(比如提前分配好计算资源)或者是具体的 workloads 的优化方面(比如,提前建立好索引,或者设置对应的优化器选项等等)。特别是对于云原生,存储计算分离的数据库系统来说,准确地预测 workloads,不仅可以未雨绸缪,为海量 workloads 来之前做好准备,也可以在休渔期,养精蓄锐,减少成本。
预测 workloads 的难点
介绍完了为什么,再来讨论一下这个问题的难点。这一点,文中并没有直接提及。但我觉得,这是一个很重要的问题。试想,如果实际生产情况中,workloads 非常有规律性,那还有必要花精力去预测 workloads 吗?这个问题就体现出了学术界和工业界的区别。在工业界,只有这是一个真实的问题,并且优先级很高,才会集中资源去解决它。
作为一个数据平台相关从业者,我可以比较负责任地说,大部分(比例可能在 80%-90%)的 workloads,都是非常有规律性的。因为绝大部分的 workloads 都是定时 ETL 任务。这些任务,每天,由定时器驱动(通常在凌晨),用来处理当天的数据。并且,当数据一旦进入一个稳定状态,每天处理的数据量,以及需要的计算资源,都是非常有规律性的。如此,直接使用昨天的历史数据来预测今天的 workloads,可能准确率已经能达到将近 80%-90%。数据平台只要集中精力来优化数据库,服务好这些大量,有规律性的 workloads,已经是一个很大的成功了。可能就不会花精力去预测并针对剩下的小部分长尾的 workloads。
文中并没有因为难点去展开,不过,倒是介绍了用来做实验的三类 workloads:
Admissions: 是一个大学网站的用例,学生提交申请,教授审核申请;
BusTracker:一个公交系统的 app,用来帮助找到最近的公交站的信息。。这和数据库。。有很大关系吗?感觉只有只读操作;
MOOC:是 CMU 的一个在线学习的网站应用。
我自己的理解是,用例可以调整一下。因为这些用例不太具备代表性,在数据量上也不会很大。这样,预测实验的说服力就降低了。这类研究,如果可以和互联网公司合作,结果应该会更有说服力。
下面,介绍本文使用的系统和方法。
QueryBot5000 简介
整个预测系统称为 QueryBot5000(以下简称 QB5),它可以作为一个独立应用部署,并接受数据库系统发来的查询语句。结合架构图,来看一下它如何工作。
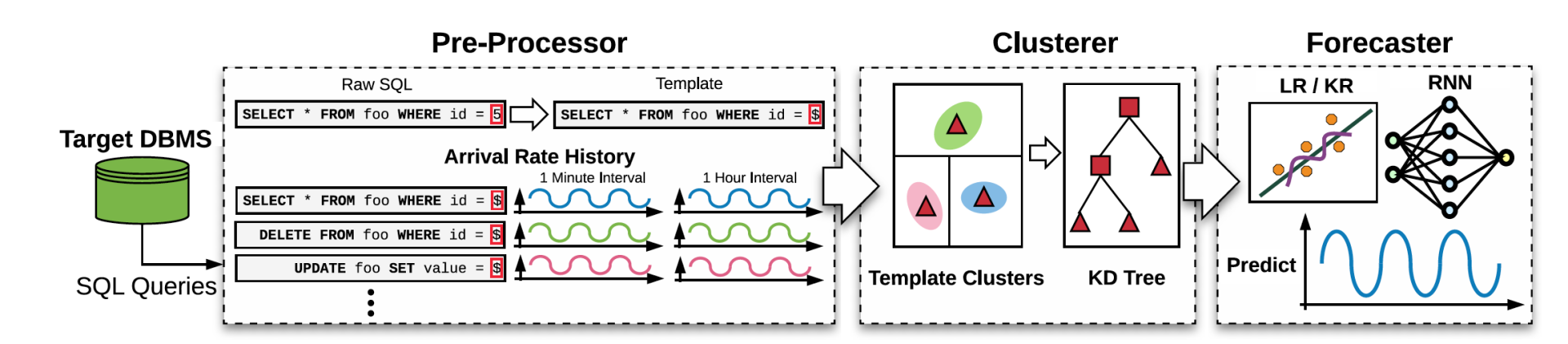
QB5 的工作流程分成三步:
1)Pre-Processor(预处理):对数据库发来的查询语句进行预处理来生成语句 template,例如把语句中的常数项替换成抽象符号(SELECT * FROM foo WHERE id = 5; ===> SELECT * FROM foo WHERE id = $;)。然后对于每个语句 template,系统会记录当前的查询时间。
2)Clusterer (聚类):即使经过了预处理,大量的语句 template 依然使得预测未来 pattern 计算量巨大。因此,为了进一步提高效率,QB5 通过聚类,将语义相似的 template,归并成组:通过使用在线的聚类算法来进一步合并查询时间 pattern 相仿的语句 template。
3)Forecaster (预测):QB5,通过训练预测模型,对大型的长 cluster(拥有很多语句的组)进行预测。预测结果形式是有多少这个组里的语句会在未来什么时候再次被提交查询。
在整个处理流程中,Pre-Processor 会在线实时把新的语句和查询时间记录到系统中,而 Clusterer 和 Forecaster 都是定期任务,读取最新的 template 和 cluster 信息来进行重新聚类和预测。接下来,依次介绍每个组件。
Pre-Processor(预处理)
预处理分为两个步骤:
1)将所有的常数项替换成标识符(比如 $)比如上面示例中的 filtering condition,除此之外,UPDATE 语句中对 column 的 SET 值,以及 INSERT 语句中的 value 值等。
2)对语句格式,做标准化处理。比如去掉多余的空格,括号,统一 syntax 大小写等。目的就是能够最大程度保证 template 的标准化。然后就是对每个 template 语句的查询时间做记录,记录格式其实是 tuple 形式,即(时间 interval, count)。这个 interval,是可调节的参数,可以是一个小时,也可以是一分钟。最后实验中有对应不同 interval 的比较。
跳出内容,我们来对于使用预处理后的语句 template 来作为查询语句的唯一标识符做一些讨论。这个方法的优点在于,实现简单,主要就是字符串处理。缺点是,由于是文本匹配,即使做了标准化,肯定还是会漏掉一些匹配结果(比如,对于一些特殊的语法糖处理不好)。有什么方法可以改进呢? 一个想法是,通过 parser,把语句变成语法树,再通过 binding 以及标准的 transformation 来变成 logical plan。Logical plan 相比于文本,肯定是标准化程度更高的表达形式。因为在这个阶段,语法糖已经被替换了,一些 transformation 应该会把语义相同,但 syntax 不同的查询语句都统一起来。因此,用 logical plan 来代表查询语句应该能达到更好的效果。文中也提到了一些其他 semantic equivalance 的研究,只是在本文中没有使用。
Clusterer (聚类)
聚类器的作用类似于二次预处理,将语句 template 的数量进一步压缩。文中也提到了原因,训练一个模型需要的时间和计算资源是有成本的(文中提到,训练一个模型需要 3 分多钟)。因此需要想办法进一步提升效率。聚类器会把类似的 template 进一步聚类成 group。它的做法就是,先定义并抽取出每个 template 的一些高纬的特征,然后根据特征向量来将类似的 template 聚成一类。
被提取的特征有三大类:物理执行层相关的,logical plan 相关的,以及语句的历史记录。物理执行层相关的特征包括数据库运行语句使用的资源情况,比如 CPU,内存,以及语句执行结果相关,比如读取了多少 tuple,最终结果集大小等。文中也提到了,数据库运行资源的使用和数据库实例以及当前状态相关。比如,相同的语句,运行在不同实例,或者是相同实例但当前 workloads 情况不同,都会产生不同的结果。因此,这些信息可能会有带来噪音。
Logical plan 的特征和上文提到的 pre-processing 的优化想法类似。比如,当前语句需要读取哪些表,哪些 column。有哪些 join pattern 等。文中也提到,这些特征的准确性也是有差异的。
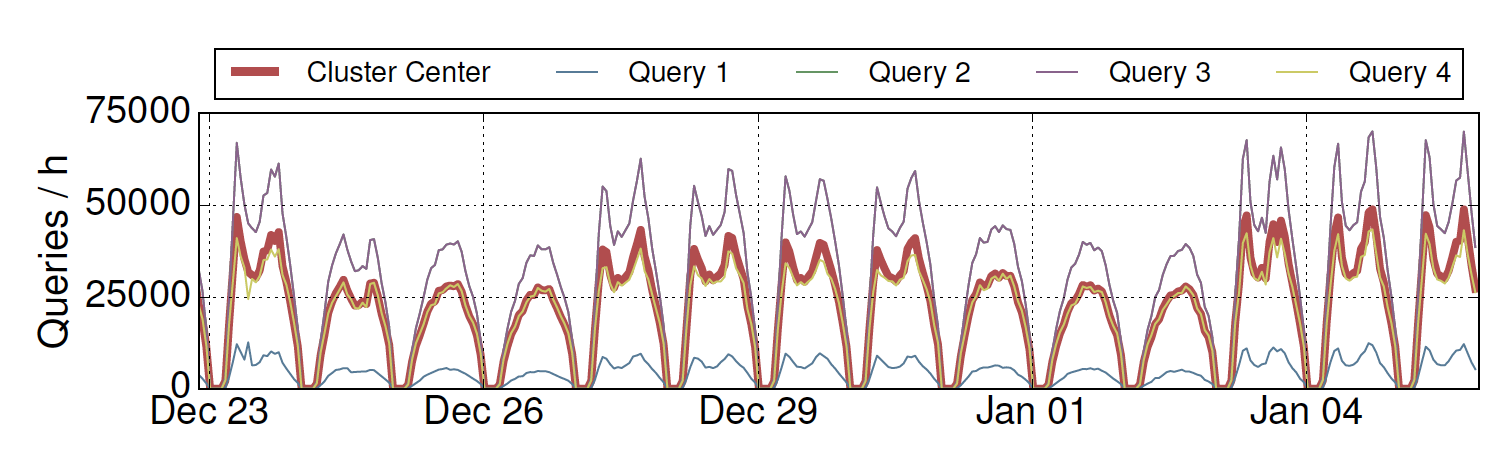
最后一类特征,也是本文研究的创新之一,就是引入了语句的历史记录(这类语句通常什么时候发生,发生的的时候会运行多少次等)来作为特征,比如下图显示了一些不同的语句拥有非常相似的历史记录,那它们就更可能被归为一类。
聚类算法:QB5 使用的聚类算法是 K-means 算法的一个变种,它的不同点在于算法不会被小聚类,或者聚类密度所影响:其中的改进是,在判断一个点是否属于某个聚类时,并不是去比较这个点和这个聚类中其他点的距离,而是比较这个点和聚类中心点(center of a cluster)的距离。
整个算法分成三个步骤:
1)对于一个新来的 template,算法会先计算出它和已有 cluster 的 similarity score,当 score 大于某个阈值后,会选择最大 score 的那个 cluster,并且将这个 template 加入到这个 cluster 中,并对 cluster 的 center 进行更新。如果没有任何 cluster 的 score 高于阈值,就会以当前模版生成一个新的 cluster。
2)更新完的 cluster 信息后,还需要对已经属于这个 cluster 的所有 template 重新和 center 进行比较,来判断是否需要移除已经不满足阈值的 template(然后再重新对 cluster 进行计算,并对移出的 template 重新找 cluster)。
3)QB5 也会对不同的 cluster 的 center point 进行比较,如果 similarity score 也超过阈值,就会对两个 cluster 进行合并。
下图给出了三个步骤的概括。
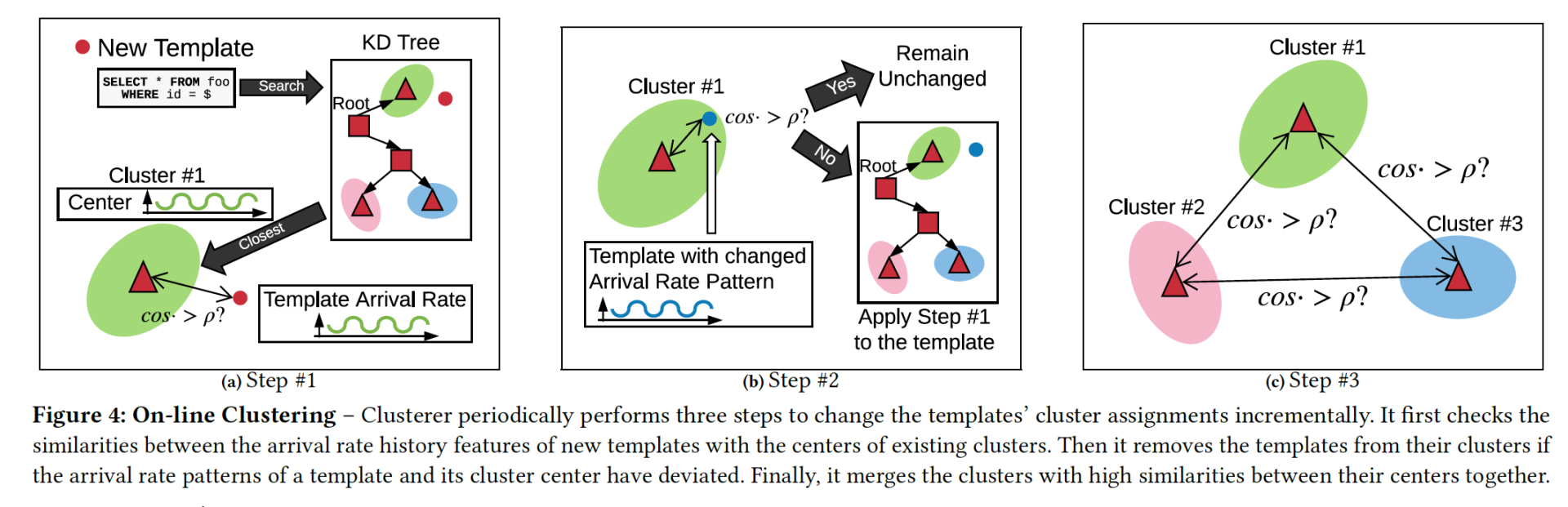
这是一个在线计算的聚类算法,根据新 template 的到来,不停地重复上述步骤,将 template 加入到 cluster 中,重新计算,直至收敛。
聚类剪枝:由于长尾效应,上述算法会产生很多小的 cluster,因此算法还会根据某个 cluster 中语句的频繁程度将它们排除在训练模型之外。
至此,我们得到了所有的 cluster,同时也记录了每个 cluster 中,语句流量的历史记录,文中使用的记录方式是每分钟多少语句。
Forecaster(预测模型)
最后一步就是通过预测模型来预测这个 cluster 的语句在未来的 pattern(以分钟粒度中语句的出现次数的形式)。

文中介绍了 6 种不同的预测模型,并从 3 个角度来分析它们的不同。结合上图来解释。
先介绍 3 个纬度:
Linear 代表算法的复杂度是否是线性相关于输入。
Memory 代表算法是否能将输入和当前模型的状态都储存在内存中(这样算法的效率就更高)。
Kernel 代表算法是否能使用 Kernel method(核函数,本人机器学习知识也是一知半解,只知道在 SVM 中有用到核函数,貌似是用来对数据进行不同纬度向量空间做映射的计算方法)。
然后文中也简单介绍了这些算法(其实我也不太懂):
1)Linear Regression(LR): 线性回归,可能大家都比较熟悉,模型相对简单,计算量也较小;
2)RNN:循环神经网络,这类神经网络比如 LSTM(长-短记忆模型)在自然语言处理上用的比较多;
3)KR:核函数回归?其他的一些算法文中也并没给出相信信息,估计是 RNN 的变种。
有了查询语句的样本,通过预处理和聚类对 workloads 进行归类,有了预测模型,下一步就是大量的实验了。文章剩下的内容都是针对多维度的实验的解读。有兴趣的同学可以去深入阅读一下。稍微看了一下,对于很有规律性的 workloads,预测是很准确的。但我依然认为,大部分的 workloads(特别是在大数据平台,生产环境中的),本身具有非常强的周期性,预测难度应该不高。
写在最后
虽然本文对于互联网大数据平台的直接影响不是特别大(可能,不能直接拿来主义去做成工业实践),但是数据平台智能化,特别是在云原生平台的基础上,是一个趋势。面对数据量越来越大,数据维度越来越多,业务逻辑越发复杂的挑战,如何利用人工智能来管理,适配,升级数据平台,未来有很多机会可以想象。
今天的内容就到这啦。一起学习了 NoisePage 中如何对未来 workloads 做预测的方法,通过预处理以及聚类来减少计算量,然后通过预测模型来预测未来属于某一个 cluster 中语句出现的 pattern。文中也系统系地比较了不同的预测模型对于不同 workloads 的预测结果。
感谢阅读这一期杂谈!2021 年的愿景之一是做更多对于技术和管理的输出,如果想要和我更多交流,欢迎关注我的知识星球:Dr.ZZZ 聊技术和管理。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 2 条评论