

当前主流的 3D 目标检测方法,很大程度上受 2D 检测器的影响。为了利用 2D 检测器,研究人员通常将 3D 点云转换为规则的网格(体素网格或鸟瞰图像),或者依靠 2D 图像检测器来提取 3D 边界框。很少有研究尝试直接探测点云中的物体。何恺明团队在 ICCV2019 发表的论文《基于深度霍夫投票的 3D 目标检测》(Deep Hough Voting for 3D Object Detection in Point Clouds)中,回归第一原则,为点云数据构建尽可能通用的 3D 检测方法。本文是 AI 前线第 91 篇论文导读,我们将为大家详细解读本论文的技术要点。
由于数据的稀疏性,直接从场景点预测边界框参数时面临着一个重大挑战:3D 对象的质心可能远离任何表面点,因此很难用一个步骤准确地回归。为了解决这一问题,作者提出了一种基于深度点集网络和霍夫投票的端到端 3D 目标检测网络 VoteNet。该模型设计简单、模型尺寸紧凑,而且效率高。在 ScanNet 和 SUN RGB-D 两个大型数据集上取得了最先进的 3D 检测精度。VoteNet 通过使用纯几何信息而不依赖彩色图像,取得了比以前的方法更好的结果。论文已被 ICCV 2019 收录,且论文代码已在 GitHub 开源。
介绍
3D 目标检测的目的是定位和识别 3D 场景中的对象。具体地说,在这项工作中,作者的目的是从点云数据中估计定向的 3D 边界框以及对象的语义类别。
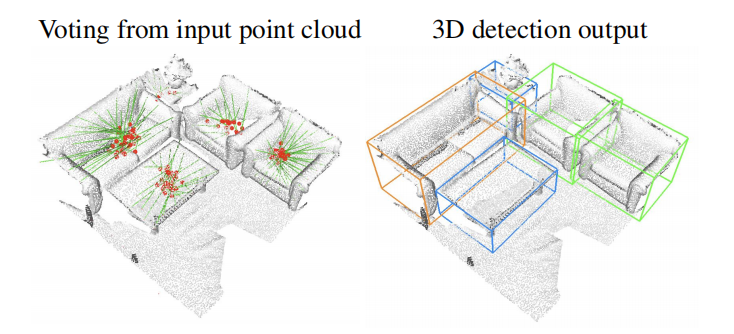
图 1:使用深度霍夫投票进行点云中的 3D 目标检测
通过端到端的可微架构,在深度学习的背景下重新定制了霍夫投票,称之为 VoteNet。
在 SUN RGB-D 和 ScanNet 两个数据集上实现了最先进的 3D 目标检测性能。
深入分析了投票在点云 3D 目标检测中的重要性。
深度霍夫投票(Deep Hough Voting)
传统的霍夫投票 2D 检测器包括离线和在线两个步骤。首先,给定一组带有标注的对象边界框的图像,用图像块(或其特征)及其到相应目标中心的偏移量之间的映射关系构建一个 codebook。在推理时,从图像中选择兴趣点以提取周围的图像块。然后将这些图像块与 codebook 中的图像块进行比较,以检索偏移量并计算投票。由于目标的图像块倾向于一致投票,因此将在目标中心附近形成集群。最后,通过追溯集群投票到生成的图像块来检索目标边界。
这种方法非常适合点云数据 3D 目标检测的问题。首先,基于投票的检测比区域候选网络(RPN)更适合于稀疏集。其次,它基于自下而上的原理,积累少量的局部信息以形成可靠的检测。
然而,由于传统的霍夫投票是由多个独立的模块组成的,如何将其集成到点云网络仍然是一个开放的研究课题。为此,作者建议对流程的不同成分进行以下调整。
兴趣点(Interest points)由深度神经网络来描述和选择,而不是依赖手工提取的特征。
投票(Vote)生成是由网络学习的,而不使用 codebook。利用更大的感受野,可以减少投票的模糊,使投票更有效。此外,还可以使用特征向量对投票位置进行增强,从而实现更好的聚合。
投票聚合(Vote aggregation)是通过可训练参数的点云处理层实现的。利用投票功能,网络可以过滤掉低质量的投票,并生成改进的候选区域(proposals)。
目标候选(object proposal)的形式为:位置、维度、方向,甚至语义类别,都可以直接从聚合特征中生成,从而减少了追溯投票来源的需要。
下面的内容将介绍如何将上述的所有成分组合成端到端的网络 VoteNet。
VoteNet 结构
图 2 给出了端到端检测网络 VoteNet 的结构。整个网络可以分为两部分:一部分处理现有的点来生成投票;另一部分处理虚拟点——投票——来提出和分类目标。
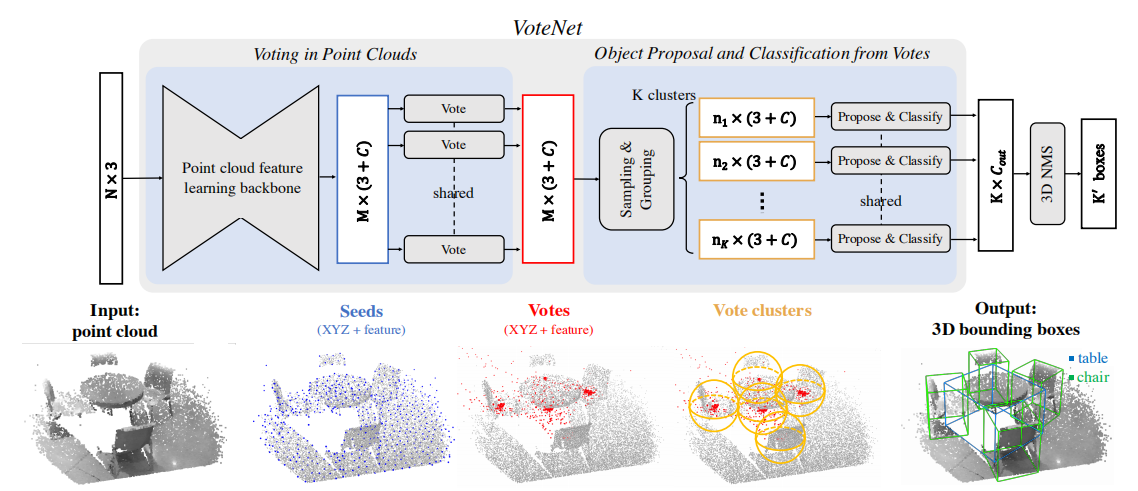
图 2:用于点云中 3D 目标检测的 VoteNet 结构。给定一个包含 N 个点和 XYZ 坐标的输入点云,一个主干网络(使用 PoingNet++实现),对这些点进行采样和学习深度特征,并输出 M 个点的子集。这些点的子集被视为种子点。每个种子通过投票模块独立地生成一个投票。然后将投票分组为集群,并由 proposal 模块处理,生成最终的 proposal。经过分类得到的 proposal 经过 NMS(非极大值抑制),即为最终的 3D 边界框。
从点云数据中学习投票
给定一个大小为 N×3 的输入点云,N 个点中的每个点都有一个 3D 坐标,目标是生成 M 个投票,其中每个投票都有一个 3D 坐标和一个高维特征向量。主要有两个步骤:通过主干网络学习点云特征和从种子点学习霍夫投票。
点云特征学习。生成一个准确投票需要几何推理和上下文信息。作者利用最近提出的深度网络在点云上进行点特征学习。作者采用了 PointNet++作为主干网络。主干网络有多个集抽象层和跳跃连接的特征传播(上采样)层,这些层输出的是输入点的子集,包含 XYZ 坐标和一个 C 维特征向量。结果为 M 个种子点,维度为 3+C。每个种子点生成一个投票。
深度网络霍夫投票。传统的霍夫投票是通过在预先计算的 codebook 中查找决定的,作者使用一个基于深度网络的投票模块生成投票,不仅效率更高,而且更准确,因为它是与剩下的步骤一起训练的。
给定一组种子点{si},si=[xi;fi];xi 表示三维坐标,fi 表示 C 维特征矢量,一个共享的投票模块从每个种子中独立地生成投票。具体来说,投票模块是通过多层感知器(MLP)网络实现的。MLP 输入种子特征 fi,输出欧几里得空间偏移量Δxi 和特征偏移量Δfi,那么从种子生成的投票 vi=[yi;gi],其中 yi=xi+Δxi,gi=fi+Δfi。
预测的 3D 偏移量Δxi 由回归损失监督:
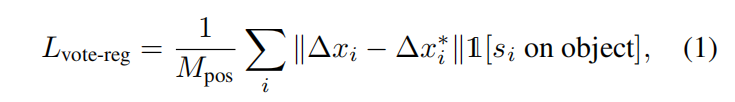
其中 1[si on object]表示种子点 si 是否在目标表面上,Mpos 是目标表面上种子的总数。Δxi *是从种子位置 xi 到它所属物体的边界框中心的真实偏移量。
从投票中得到目标的 proposal 和分类
通过抽样和分组对投票聚类。作者选择了一种简单的策略对投票聚类,即根据空间邻近度进行统一采样和分组。具体地说,从一组投票{vi=[yi;gi]}中,作者基于{yi}进行最远点采样,得到包含 K 个投票的子集{vik}。然后通过找到每个 vik 3D 位置的近邻投票来形成 K 个聚类:
从投票聚类中得到 proposal 和分类。由于投票聚类本质上是一组高维点,因此可以利用一个通用的点集学习网络来聚合投票,以生成目标 proposal。作者采用共享的 PointNet。给定一个投票聚类 C={wi},其中 wi=[zi;hi],zi 为投票位置,hi 为投票特征,聚类中心为 wj。为了利用局部投票几何,将投票位置转换成局部标准化坐标系。然后对于聚类 C 的目标 proposal p©就可以通过把集合输入一个类似 PointNet 的模块得到:
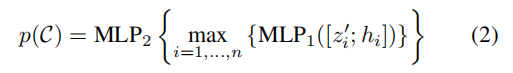
其中,来自每个聚类的投票由 MLP1 独立处理,然后按通道最大池化为单特征向量,并传递到 MLP2,在那里,来自不同投票的信息进一步组合。作者将 proposal p 表示为一个多维向量,包括目标性得分、边界框参数和语义分类得分。
损失函数。Proposal 和分类阶段的损失函数包括目标性、边界框估计和语义分类损失。
对于目标性分数,监督信息为投票与真实目标中心更近(0.3 米以内)或远离任何中心(0.6 米以上)。作者将这些投票产生的 proposal 分别视为积极 proposal 和消极 proposal。对于其他 proposal 的对象性预测不进行惩罚。对象性是通过交叉熵损失来监督的,该交叉熵损失由一个 batch 中不被忽略的 proposal 的数量进行归一化。对于积极的 proposal,将根据最近的真实边界框进一步监督边界框估计和语义类预测。具体来说,作者将边界框损失与中心回归、航向角估计和边界框尺寸估计分开。对于语义分类,使用标准的交叉熵损失。
实验结果
作者首先在两个大型 3D 室内目标检测基准上,将基于霍夫投票的检测器与之前最先进的方法进行比较。然后,作者提供了分析实验来了解投票的重要性、不同的投票聚合方法的效果,并展示了该方法在紧凑性和效率方面的优势。最后,作者展示了检测器的定性结果。
与 SOTA 方法进行比较
####数据集
SUN RGB-D 是一个单视图 RGB-D 数据集,用于 3D 场景理解。包含 5K 的 RGB-D 训练图像,包含 37 个类别的标注框。作者使用提供的相机参数将深度图像转换为点云数据。
ScanNetV2 是一个注释丰富的室内场景 3D 重建网格数据集。包含从数百个不同房间收集的 1.2K 训练样本,并用语义和实例分割对 18 个目标类别进行标注。与 SUN RGB-D 相比,ScanNetV2 中的场景更完整,平均覆盖的区域更大,目标更多。作者从重建的网格中抽取顶点作为输入点云。
####方法比较

表 1:SUN RGB-D val 数据集上的 3D 目标检测结果。评价标准为 3D IoU 阈值为 0.25 的平均精度。
表 2:ScanNetV2 val 数据集上的 3D 目标检测结果。
表 1 表明,当类别为训练样本最多的“椅子”时,VoteNet 比以前的最优方法提高了 11AP。表 2 表明,仅采用几何输入时,VoteNet 显著优于基于 3D CNN 的 3D-SIS 方法,超过了 33AP。
分析实验
####投票好还是不投票好呢?
作者采用了一个简单的基线网络,称之为 BoxNet,它直接从采样的场景点提出候选框,而不需要投票。BoxNet 与 VoteNet 具有相同的主干,但它不是投票,而是直接从种子点生成框。表 3 显示,在 SUN RGB-D 和 ScanNet 上,相比 BoxNet,投票机制的网络性能分别提高了 5 mAP 和 13 mAP。

表 3:VoteNet 和 no-vote 基线的比较

图 3:投票有助于增加检测上下文。由种子点(BoxNet),或投票(VoteNet)在图中用蓝色显示。随着投票有效地增加了上下文,VoteNet 能够更密集的覆盖场景,因此增加了准确检测的可能性。
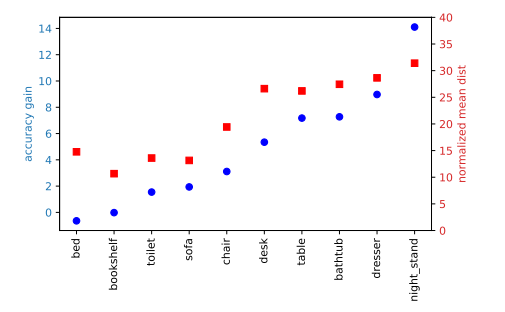
图 4:当目标点远离目标中心的情况下,投票更有帮助。
####投票聚合的效果
投票聚合是 VoteNet 的一个重要组成部分,因为它允许投票之间的沟通。因此,分析不同的聚合方案对性能的影响是非常有用的。
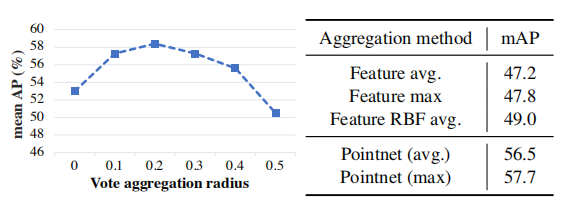
图 5:投票聚合分析
图 5(右)表明,由于存在杂乱投票(即来自非目标种子的投票),使用学习的 PointNet 和最大池化进行投票聚合比手动聚合局部区域中的投票特征能获得更好的结果。图 5(左)给出了投票聚合半径对检测的影响。随着聚和半径的增加,VoteNet 的效果会不断提高,在 0.2 半径处达到峰值。当半径过大时,引入了更多的杂乱投票,导致性能下降。
####模型大小和速度
VoteNet 利用了点云的稀疏性,避免在空的空间搜索。与以前的最佳方法相比,该模型比 F-PointNet 小 4 倍,在速度上比 3D-SIS 快 20 倍。
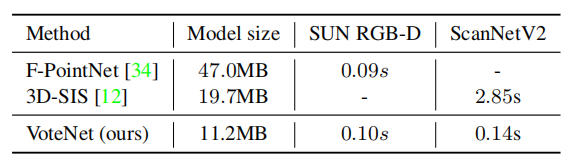
表 4:模型尺寸和处理时间。
定性结果和讨论
图 6 和图 7 分别给出了 VoteNet 在 ScanNet 和 SUN RGB-D 场景上检测结果的几个代表性示例。如图所示,场景是非常多样化的,并具有多种挑战,包括杂乱、扫描伪影等。尽管存在这些挑战,VoteNet 仍然显示出相当强大的结果。
例如,图 6 展示了 VoteNet 在顶部场景中正确地检测到绝大多数椅子。该方法能够很好地区分左下角场景中连起来的的沙发椅和沙发,并预测出了右下角场景中那张不完整的、杂乱的桌子的完整边界框。
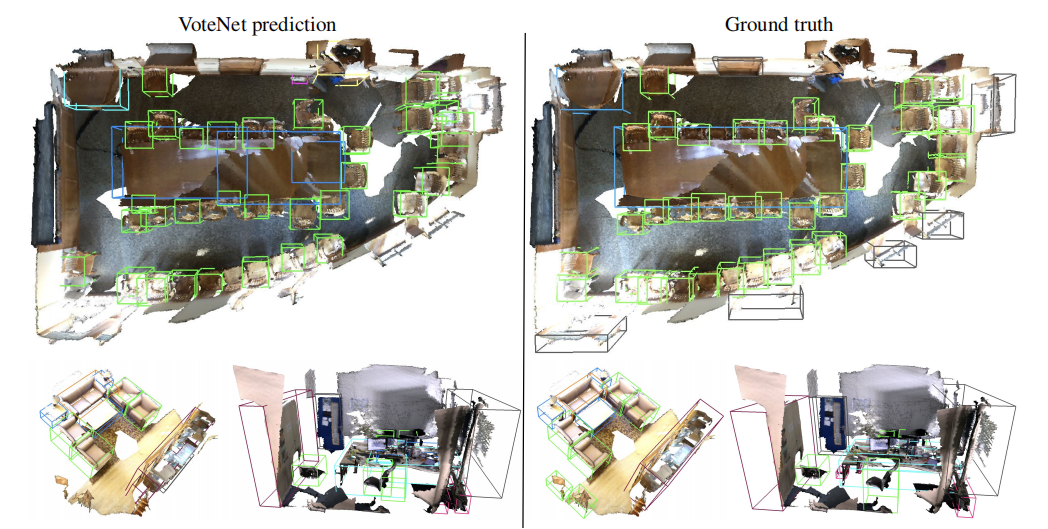
图 6:ScanNetV2 数据集 3D 目标检测结果。
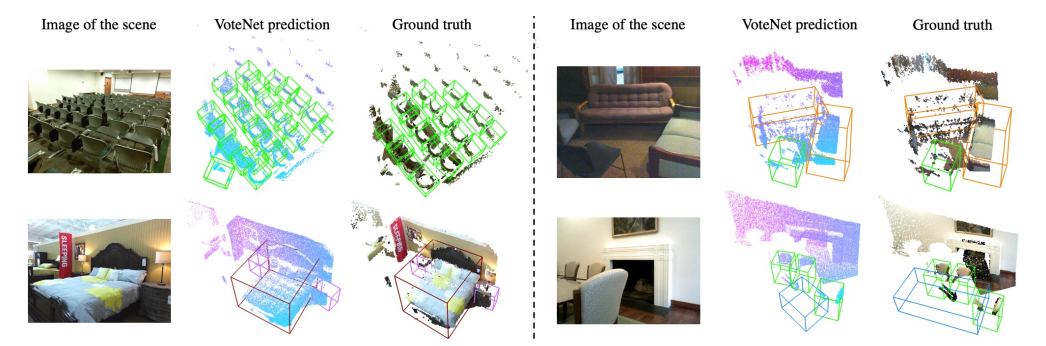
图 7 SUN RGB-D 数据集 3D 目标检测结果。
结论
在这项工作中,作者提出了 VoteNet:一个简单但强大的 3D 目标检测模型,其灵感来自于霍夫投票。该网络学习直接从点云向目标中心投票,并学习通过其特征和局部几何信息聚合投票,以生成高质量的目标 proposal。该模型仅使用 3D 点云,与之前使用深度和彩色图像的方法相比,有了显著的改进。在未来的工作中,作者将探索如何将 RGB 图像纳入这个检测框架,并在下游应用(如 3D 实例分割)中汇总利用该检测器。作者表示霍夫投票和深度学习的协同作用可以推广到更多的应用领域,如 6D 姿态估计、基于模板的检测等,并期待在这方面看到更多的研究。
论文原文:
Deep Hough Voting for 3D Object Detection in Point Clouds
论文代码:https://github.com/facebookresearch/votenet

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论 1 条评论