

过去几年,人工智能产业无论是算法实现、海量数据获取和存储还是计算能力的体现都离不开目前唯一的物理基础——芯片。可以说,“无芯片不 AI”,能否开发出具有超高运算能力、符合市场需求的芯片,已成为人工智能领域可持续发展的重要因素。 年终在即,AI前线小组盘点了2019年国内外主流科技公司在AI芯片方面的进展,有些公司因为2019年没有发布新的AI芯片而未计入本次统计,统计维度分为主要特点、芯片参数和应用场景三部分,如有疏漏,欢迎各位留言。
芯片类型
在正式盘点之前,我们先来了解下芯片类型、芯片架构以及主要的应用场景(注:如果仅对盘点数据感兴趣,可以直接跳转到文章后半部分)。
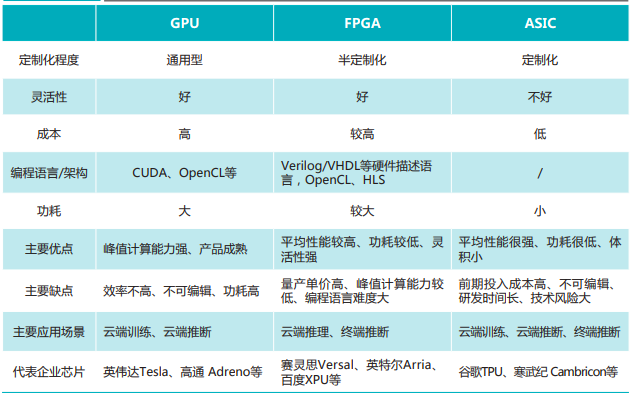
从芯片技术类型来看,AI 芯片主要可以分为 GPU(图形处理器)、FPGA(现场可编程门阵列)、ASIC(专用集成电路) 、类脑芯片四大类。
其中,GPU 和 FPGA 因为具有较为成熟的技术,已经占据了市场上的大部分份额,目前由英伟达、英特尔、AMD、赛灵思等公司所主导;ASIC 的发展也不容小觑,虽然前期的投入成本较高,但因为平均性能强、功耗低等特点,ASIC 深受各大云厂商的喜爱(如谷歌的 TPU、华为的昇腾、阿里的含光等)。类脑芯片与这些 AI 芯片相比则有些特殊,它颠覆了传统的冯·诺依曼架构,以模拟人脑神经元结构为主,比如 IBM 的 TrueNorth 芯片、清华大学的天机芯等。
天机芯:清华大学开发的全球首款异构融合类脑芯片,今年7月31日刊登在Nature杂志封面上。该芯片采用 28 nm工艺制成,整个芯片尺寸为3.8 X 3.8mm^2 ,由156个计算单元(Fcore)组成,包含约40000个神经元和1000万个突触。它能够把人工通用智能的两个主要研究方向,即基于计算机科学和基于神经科学这两种方法,集成到一个平台,可以同时支持机器学习算法和现有类脑计算算法。
(来源:中国AI芯片产业发展白皮书)
芯片架构
芯片架构,或者称其为指令集架构更为精确,它是计算机体系结构中与程序设计有关的部分,包含了基本数据类型、指令集、寄存器、寻址模式、存储体系等。谈及指令集架构,X86、ARM、RISC-V 是必不可少的部分,其中 X86 占据 PC 端市场、ARM 占据移动端市场、RISC-V 则主要是在 IoT 市场中应用。
IoT 市场是人工智能技术的主要落地应用场景,所以对于初创 AI 芯片公司来讲,开源的 RISC-V 指令集架构往往是一个重要选项。另外,RISC-V 指令集架构还具有灵活性、可扩展性的特点,基于该架构设计的 AI 芯片,往往在固定的 AI 应用场景中,可以达到较为理想的能源利用和运算效率。
除此之外,AI 芯片领域的指令集架构,并不像 PC 端的 X86 架构和移动端的 ARM 架构一样,哪怕是有 RISC-V 架构在前,AI 芯片指令集架构也未形成统一形式,各大公司也都有自研的 AI 芯片指令集架构,就比如:华为昇腾系列芯片采用的自研 CISC 指令集架构、寒武纪思元系列芯片采用的 MLUv02 指令集架构、地平线旭日、征程系列芯片采用的 BPU 架构、深鉴科技的自研 DPU 指令集架构······
应用场景
按照部署位置,AI 芯片可以分为云端部署和终端部署两种。其中云端部署的 AI 芯片大部分是指用于数据中心的 AI 训练芯片和 AI 推理芯片,终端部署的 AI 芯片则大部分是指用于移动终端、自动驾驶、智能家居等边缘终端应用场景的 AI 推理芯片。虽然由于算力的限制,终端位置并不适合用于 AI 模型的训练,但其碎片化的特点,反而使得终端推理市场的前景一片广阔。
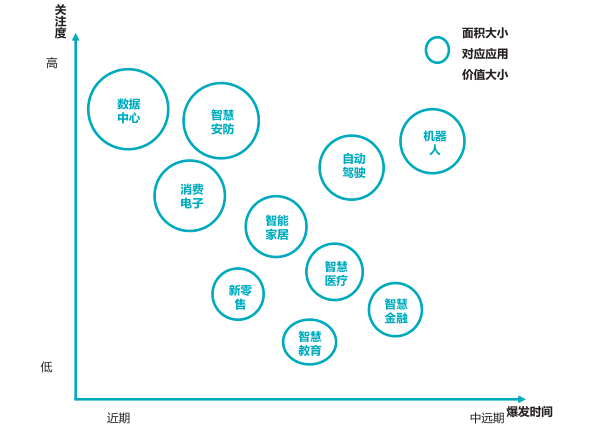
AI 芯片应用价值领域分布(来源:中国AI芯片产业发展白皮书)
数据中心(云端)
数据中心,或者说是云端训练用 AI 芯片的市场主要是以英伟达的 GPU 为主,专用芯片 ASIC 为辅。相对于 ASIC 的“专用”局限性,目前包括全球排名前四(AWS、GCP、Microsoft Azure、阿里云)的公共云中,英伟达 GPU 的市场份额占到了 97%以上。
尽管当前的 AI 训练任务相关的解决方案有 3 种,英伟达的GPU+CUDA计算平台,第三方异构计算平台OpenCL + AMD GPU 或 OpenCL + 英特尔/Xilinx FPGA,谷歌的TPU+ Cloud TPU平台。但从市场份额、生态完善程度、性价比等方面比较来讲,大多数企业和开发者选择了英伟达的 GPU。
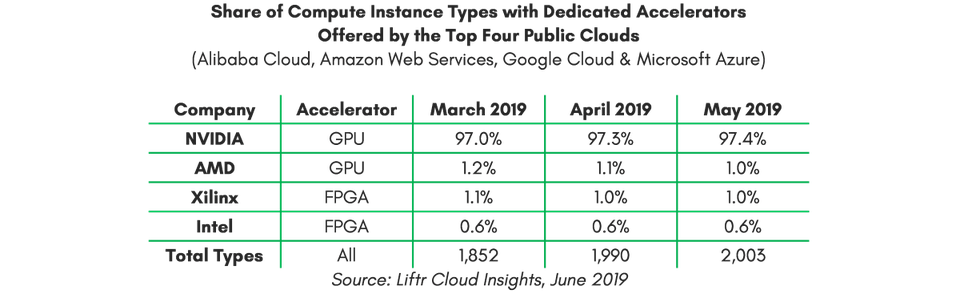
具体 AI 芯片份额
随着各大公司对云端战略的不断加码,又有谷歌 TPU 成功案例的引导,各大云厂商也开始不断推出自己的云端用 AI 芯片。比如亚马逊近期发布的云端推理用 Inferentia 芯片、华为推出的云端训练用昇腾系列芯片、阿里平头哥推出的云端推理用含光 800 等。事实上,云端推理用 AI 芯片市场是一种百家争鸣的局面,像百度、微软、Facebook、英特尔等巨头企业都有不同程度的涉及,只不过采用的技术类型并不统一而已。
移动终端
随着全球智能手机出货量趋于平稳,各智能手机厂商开始将 AI 性能作为竞争的重要因素之一,而搭载性能更佳的 AI 芯片则变成了智能手机厂商实现差异化竞争的标准手段。
华为海思推出的麒麟 970 是全球第一款集成专用神经网络处理单元(NPU)的 SoC 芯片,随后苹果发布的 A 系列芯片、高通的骁龙系列芯片也都集成有 AI 技术,从此 AI 芯片也就成为了智能手机的一种标准配置,并逐渐进入到普及阶段。
另外,在移动端,如智能手环、VR/AR 眼镜等可穿戴设备都将是 AI 芯片的潜在市场。换句话说,AI 芯片凭借在图像、语音方面的快速处理能力,将会为人们带来一种全新的人机交互方式,而就目前而言,像谷歌、苹果、华为、小米等诸多公司都已经不同程度的进军到了可穿戴设备市场,所以,移动终端中的 AI 芯片,也将会因此置于一个非常重要的位置。
智慧安防
人工智能技术在智慧安防中的应用尤为广泛,尤其是在平安城市、智慧城市等大方向建设的推动下,国内的安防行业不断扩大。而在智能安防系统中,AI 芯片是不可或缺的存在,对此,一大批 AI 芯片厂商涌入,其中既有寒武纪、地平线等 AI 芯片创企,也有传统安防芯片霸主华为海思的强势入局。
就解决方案而言,智慧安防有两种思路,一种是智能前置,另一种是智能后置,相对应的,在安防中 AI 芯片的部署也可以分为前置和后置,简单来说,就是利用云端推理和终端推理两种不同的推理方式,以实现智能分析、图像信号处理等作用。
不过出于对成本的考虑,现阶段的安防 AI 芯片多为终端推理用 AI 芯片,相关的安防芯片厂商,会将 AI 模块集成于摄像机 SoC 的芯片中,以达成 AI 技术集成的目的。然而,尽管云端推理的成本较高,安防领域的 AI 芯片也正在向着“云边结合”的方向发展,毕竟终端存在着诸如算力不足、算法要求高、运维难度大等缺点。
自动驾驶
对自动驾驶行业而言,芯片同样重要,除了搭建自动驾驶系统,其硬件基础车轨级 AI 芯片也是不容忽视的。换句话说,全栈系统开发和车规 AI 芯片开发是两个行业层面的工作,而目前的车规级 AI 芯片还处在从嵌入式 GPU 到 FPGA、ASIC 的转变阶段。
过去两年,自动驾驶企业主要是通过嵌入式 GPU 搭建自动驾驶系统,而一些有实力的企业会采用嵌入式 GPU+FPGA 的深度优化方案,未来的自动驾驶芯片则有可能慢慢向 FPGA+ASIC 的方向过渡。总之,自动驾驶技术的发展,和 AI 芯片的发展是密不可分的。
今年 8 月,地平线在世界人工智能大会上发布了中国首款车规级 AI 芯片征程2.0,搭配地平线自研的 Matrix 自动驾驶计算平台,可以提供 192 TOPS 的算力。除此之外,今年 4 月份,特斯拉也首次公开了他们的全自动驾驶(FSD)芯片,7 月份,马斯克在推特表示,将会对购买了全自动驾驶功能的用户免费更换 FSD 芯片;而对于自动驾驶领头羊——谷歌 Waymo,其应用了英伟达和英特尔的 FPGA 芯片。
2019 年国内 AI 芯片主要玩家盘点
阿里巴巴
1、玄铁 910
主要特点:玄铁910基于RISC-V开源架构开发,核心针对高性能计算,是一款IP core,是一款处理器,也可以理解为是SoC里的CPU。
芯片参数:单位性能7.1 Coremark/MHz,主频在12nm工艺下达到2.5GHz。性能在Core Mark跑分数据中达到7.0,超过第二名40%以上,主频功耗仅为0.2瓦。玄铁910采用3发射8执行的复杂乱序执行架构,是公开的RISC-V处理器中首个实现每周期2条内存访问的处理器,对RISC-V指令的系统性增强扩展到50+条指令。
应用场景:玄铁910用于设计制造高性能端上芯片,应用于5G、人工智能以及自动驾驶等领域。
2、含光 800
主要特点:含光800是一款云端推理用AI芯片,可以用于数据中心、边缘服务器和大型端上。
芯片参数:含光800采用台积电12nm制作工艺,在业界标准的 ResNet-50 测试中,推理性能达到 78563 IPS,比目前业界最好的 AI 芯片性能高 4 倍;能效比 500 IPS/W,是第二名的 3.3 倍。
应用场景:主要用于云端视觉处理场景,含光800已开始应用在阿里巴巴内部核心业务中。拍立淘商品库每天新增10亿商品图片,使用传统GPU算力识别需要1小时,使用含光800后可缩减至5分钟。在杭州城市大脑的业务测试中,1 颗含光 800 的算力相当于 10 颗 GPU。
华为
1、麒麟****990 5G
主要特点:麒麟990 5G据报道是业界首款商用的5G SoC,也是目前晶体管数最多、功能最完整、复杂度最高的5G SoC,是首个采用达芬奇架构NPU的旗舰芯片,也是华为昇腾系列芯片在端侧的应用。
芯片参数:麒麟 990 5G 采用7nm+ EUV 工艺制程,首次将 5G Modem 集成到 SoC 上,板级面积相比业界其他方案小 36%,采用两个大核+两个中核+四个小核的CPU 架构,支持超过 300 个算子,90% 的视觉计算神经网络,性能表现比同类产品要强 8 倍之多。麒麟 990 5G 也对GPU进行了升级,升级到 16 核 GPU Mali-G76。与骁龙 855 相比,图形性能提高 6%,能效高 20%。与前一代相比,视频优化处理能力有了很大提升,ISP吞吐率提升15%,能效提升15%,照片降噪30%,视频降噪20%。
应用场景:华为今年发布的年度旗舰5G手机Mate 30系列已经搭载该芯片。
2、昇腾 910
主要特点:昇腾 910是目前已发布的单芯片计算密度最大的 AI 芯片。
芯片参数:昇腾 910 是目前为止计算密度最大的单芯片,最大功耗为 350W,半精度为(FP 16)256 Tera FLOPS,比英伟达 V100 的 125 Tera FLOPS 还要高出近 1 倍。若集齐 1024 个昇腾 910,将会出现迄今为止全球最大的 AI 计算集群,性能也将达到 256 个 P,不管多复杂的模型都能轻松训练。在算力方面,昇腾 910 完全达到设计规格,即:半精度 (FP16) 算力达到 256 Tera-FLOPS,整数精度 (INT8) 算力达到 512 Tera-OPS,重要的是,达到规格算力所需功耗仅 310W,明显低于设计规格的 350W。
应用场景:华为已经把昇腾 910 用于实际 AI 训练任务,比如在典型的 ResNet50 网络的训练中,昇腾 910 与 MindSpore 配合,与现有主流训练单卡配合 TensorFlow 相比,显示出接近两倍的性能提升。
3、昇腾 310
主要特点:昇腾 310是目前面向计算场景最强算力的 AI SoC。
芯片参数:昇腾310采用华为自研达芬奇架构,使用了华为自研的高效灵活CISC指令集,每个AI核心可以在1个周期内完成4096次MAC计算,集成了张量、矢量、标量等多种运算单元,支持多种混合精度计算,支持训练及推理两种场景的数据精度运算。统一架构可以适配多种场景,功耗范围从几十毫瓦到几百瓦,弹性多核堆叠,可在多种场景下提供最优能耗比。
应用场景:基于昇腾 310 的 MDC 和很多国内外主流车企在园区巴士、新能源车、自动驾驶等场景已经深入合作。基于昇腾 310,华为云提供了图像分析类服务、OCR 服务、视频智能分析服务等云服务。基于昇腾 310 的 Atlas 系列板卡、服务器,与数十家伙伴在智慧交通、智慧电力等数十个行业落地行业解决方案。
百度
昆仑系列芯片
主要特点:昆仑系列芯片基于 XPU 架构设计,包括训练用昆仑818-300和推理用昆仑818-100两种 AI 芯片。2018年7月,昆仑芯片在百度开发者大会上首次曝光,当时号称业内设计算力最高的AI芯片。
芯片参数:昆仑芯片采用三星 14nm 制作工艺,支持PCIe 4.0 x8,并提供 512 GBps 的内存带宽,能够在 150 W的功率下实现 260 TOPS 的处理能力;它支持针对自然语言处理的预训练模型 Ernie,推理速度比传统 GPU/FPGA 加速模型快 3 倍。
应用场景:该款芯片将主要用于云计算和边缘计算,预计在2020年初实现量产。
燧原科技
邃思 DTU
主要特点:邃思 DTU 基于通用 AI 处理器的设计,具备一定的可编程性,是一款云端训练用AI芯片。
芯片参数:燧思 DTU 采用 12nm FinFET 制作工艺,集成有 141 亿个晶体管,具备 16Gbps 的 PCIe 4.0 接口和 25Gbps 的 ESL 高速互联;支持 CNN、RNN、LSTM、BERT 等网络模型以及 FP32、FP16、BF16、Int8、Int16、Int32 等数据类型,最大功耗为200W。
应用场景:搭载邃思DTU的加速板卡云燧 T10 已经可以实现量产,预计 2020 年第一季度上市。据了解,目前燧原科技已经与腾讯针对通用人工智能应用场景的项目开展了密切的合作。
寒武纪
1、思元 220
主要特点:思元220基于寒武纪自研架构MLUv02设计,是一款专门用于边缘计算应用场景的AI加速产品。
芯片参数:思元220集成有4核 ARM CORTEX A55、LPDDR4x内存以及丰富的外围接口。用户既可以使用思元220作为AI加速协处理器,也可以使用其实现SoC方案。思元220的整体功耗小于15W ,算力可达16TOPS(INT8)。
应用场景:可用于智慧工厂、智慧零售、无人机、智能机器人等诸多应用场景。
2、思元 270
主要特点:思元 270 基于寒武纪自研架构MLUv02设计,是一款云端推理用AI芯片。
芯片参数:思元 270 采用台积电 16nm 制作工艺,性能是上一代 MLU100 的 4 倍,算力达到 128TOPS(INT8);同时兼容INT4和INT16运算,理论峰值分别达到256TOPS和64TOPS;支持浮点运算和混合精度运算。功耗70W~150W。
应用场景:思元 270 支持视觉、语音、自然语言处理以及传统机器学习等多种人工智能应用,可应用于推荐引擎、NLP、智能视频分析等多种场景。
地平线
1、征程 2.0
主要特点:征程2.0基于地平线自研架构BPU2.0设计,是中国首款车规级AI芯片(用于自动驾驶)。
芯片参数:征程 2.0 可提供超过 4 TOPS的等效算力,典型功耗2W,满足AEC-Q100标准,每TOPS算力可以处理的帧数是同等算力GPU的10倍以上,识别精度超过99%,延迟少于100毫秒,多任务模式下可以同时执行超过60个分类任务,每秒钟识别目标数可超过2000个。
应用场景:目前,征程2.0芯片已实现量产,将主要应用于自动驾驶领域。据了解,地平线已经获得了五个国家市场客户的前装定点项目。
2、旭日 2.0
主要特点:旭日2.0基于地平线自研架构BPU2.0设计,属于终端推理用AI芯片。
芯片参数:旭日2.0分类模型 MobileNet V2 的运行速度超过每秒 700 张图片,检测模型 Yolo V3 的运行速度超过每秒 40 张图片,能够达到甚至超过业内标称 4TOPS 算力的 AI 芯片;最大输入分辨率为4K@30fps;支持主流外部接口;功耗为 2W。
应用场景:旭日2.0在边缘端即可实现全视频结构化能力,可以完成 10-30 万人前端识别、密集人群时空属性行为分析、以及多种非机动车/机动车检测分类。适用于AIoT领域。
思必驰
TH1520
主要特点:TH1520 是一款聚焦于语音应用场景下的 AI 专用芯片。
芯片参数:TH1520 进行了算法硬件优化,基于双 DSP 架构,内部集成 codec 编解码器以及大容量的内置存储单元,同时,TH1520 采用了 AI 指令集扩展和算法硬件加速的方式,使其相较于传统通用芯片具有 10X 以上的效率提升。此外,TH1520 在架构上具有算力及存储资源的灵活性,支持未来算法的升级和扩展。兼具低功耗及实用性,采用多级唤醒模式,内置低功耗 IP,使其在 always-on 监听阶段的功耗低至毫瓦级,典型工作场景功耗仅需几十毫瓦,极端场景峰值功耗不超过百毫瓦。该芯片支持单麦、双麦、线性 4 麦、环形 4 麦、环形 6 麦等全系列麦克风阵列,同时支持 USB/SPI/UART/I2S/I2C/GPIO 等应用接口和多种格式的参考音,能在各类 IOT 产品中灵活部署应用。
应用场景:主要面向智能家居、智能终端、车载、手机、可穿戴设备等各类终端设备。
依图科技
依图芯片 questcore(求索)
主要特点:据介绍,这是全球首款深度学习云端定制SoC芯片,已经实现量产。
芯片参数:依图芯片questcore(求索)基于拥有自主知识产权的ManyCore架构,基于领域专用架构(Domain Specific Architecture,DSA)理念。作为云端服务器芯片,它可以独立运行,不依赖Intel x86 CPU。虽说是为了服务器芯片而生,questcore既支持云端,也支持边缘。在实际的云端应用场景,依图questcore最高能提供每秒15 TOPS的视觉推理性能,最大功耗仅20W,比一个普通的电灯泡还小。集成度高,能高效适配各类深度学习算法,模型兼容性好,可扩展性高,支持TensorFlow、PyTorch等各类深度学习框架,无缝接入现有生态。
应用场景:专为计算机视觉应用而生,针对视觉领域的不同运算进行加速,适用于人脸识别、车辆检测、视频结构化分析、行人再识别等多种视觉推理任务。
瑞芯微电子
RK3399Pro
主要特点:RK3399Pro还内置了性能高达3.0Tops、融合了瑞芯微Rockchip在机器视觉、语音处理、深度学习等领域的多年经验打造的NPU,让典型深度神经网络Inception V3、ResNet34、VGG16等模型在其上的运行效果表现出众,性能大幅提升。
芯片参数:RK3399Pro采用专有AI硬件设计,NPU运算性能高达3.0Tops,高性能与低功耗指标均大幅领先:相较同类NPU芯片性能领先150%;相较GPU作为AI运算单元的大型芯片方案,功耗不到其所需的1%。RK3399Pro的NPU支持8bit与16bit运算,能够兼容各类AI软件框架。现有AI接口支持OpenVX及TensorFlowLite/AndroidNN API,AI软件工具支持对Caffe/TensorFlow模型的导入及映射、优化。RK3399Pro这颗AI芯片采用双核Cortex-A72+四核Cortex-A53的big.LITTLE大小核CPU架构,芯片在整体性能、功耗方面具技术领先性。同时,芯片还集成了四核的ARM高端GPU Mali-T860,进一步提升了芯片在图形处理方面的能力。
应用场景:主要应用于智能驾驶、图像识别、安防监控、无人机、语音识别等各AI应用领域。
紫光展锐
虎贲 T710
主要特点:虎贲 T710是一个高性能 AI 边缘计算平台。
芯片参数:虎贲 T710 采用 8 核 CPU 架构,其中 4 颗为 2.0GHz 的 Arm Cortex-A75,4 颗为 1.8GHz 的 Arm Cortex-A55;并搭载工作频率为 800MHz 的 IMG PowerVR GM 9446 图形处理器(GPU)。除了架构和算力,该芯片能效大于等于2.5TOPS/W,超过业界平均水平 30%;支持多种 AI 训练框架, 如 TensorFlow、TensorFlow Lite、Caffe 等;支持多种 AI 模型量化方式,包括 INT4、INT8、INT16 和 FP16 等;支持 Android NN,并且提供紫光展锐自研 SDK,使第三方应用程序更高效部署 AI 功能。整合了如 4K@30fps 编解码,802.11AC,BT 5.0 等强大的多媒体能力和先进的无线通信能力。
应用场景:为各类 AI 应用提供高效能、低功耗的技术基础。
2019 年国际 AI 芯片主要玩家盘点
英特尔
NNP-T 和 NNP-I
主要特点:NNP系列芯片主要用于数据中心,NNP-T属于云端训练用AI芯片,NNP-I则属于云端推理用AI芯片。
芯片参数:NNP-T 代号 Spring Crest,采用了台积电的 16nm 制作工艺,集成有 270 亿个晶体管,支持 TensorFlow、PaddlePaddle、PyTorch 框架,同时也支持 C++深度学习软件库和编译器 nGraph。NNP-T的工作频率是 1.1GHz,风冷条件下功率配置为 150W 到 250W。NNP-I 代号 Spring Hill,采用了 10nm 的制作工艺,它在 ResNet50 的效率可达 4.8TOPs/W,功率范围在 10W 到 50W 之间。
应用场景:据英特尔称,NNP-I 已经被 Facebook 采用;NNP-T 也与百度达成了合作。NNP系列芯片将主要应用于数据中心。
英伟达
Orin 芯片
主要特点:Orin是一款用于自动驾驶的系统级AI芯片,集成有170亿个晶体管,并且达到了ISO 26262 ASIL-D等系统安全标准。
芯片参数:Orin系统级芯片集成了英伟达新一代GPU架构和Arm Hercules CPU内核以及全新深度学习和计算机视觉加速器,每秒可运行200万亿次计算,几乎是英伟达上一代Xavier系统级芯片性能的7倍。
应用场景:英伟达发布的全新的软件定义自动驾驶平台 DRIVE AGX Orin,内置了全新的Orin系统级芯片。
亚马逊
Inferentia 芯片
主要特点: Inferentia 是一款专用于机器学习推理的ASIC 芯片,它具有大容量片上内存,可用于缓存大型模型,而无需将它们存储到芯片以外。
芯片参数:Inferentia 芯片支持 FP16、BF16 和 INT8 数据类型,算力达128 TOPS。还支持 TensorFlow、Apache MXNet 和 PyTorch 深度学习框架以及使用 ONNX 格式的模型。与EC4上的常规英伟达 G4实例相比,借助Inferentia,AWS可提供更低的延迟和三倍的吞吐量,且每次推理成本降低40%。
应用场景:Inferentia 芯片将主要用于云端推理任务。
赛灵思
Virtex UltraScale+ VU19P
主要特点:这是一款FPGA芯片,考虑到芯片设计背后需要更大容量的FPGA实现高效仿真和功能验证,因此也出现在了本次的盘点名单中。
芯片参数:VU19P FPGA 采用台积电 16nm 工艺制造(上代为 20nm),基于 ARM 架构,集成了 16 个 Cortex-A9 CPU 核心、893.8 万个系统逻辑单元、2072 个用户 I/O 接口、224Mb(28MB)内存,DDR4 内存带宽最高 1.5Tbps(192GB/s),80 个 28G 收发器带宽最高 4.5Tbps(576GB/s),支持 PCIe 3.0 x16、PCIe 4.0 x8、CCIX。
应用场景:主要面向最顶级 ASIC、SoC 芯片的仿真和原型设计,以及测试、测量、计算、网络、航空、国防等应用领域,支持各种复杂的新兴算法,包括人工智能、机器学习、视频处理、传感器融合等。
苹果
A13 仿生芯片
主要特点:宣称具备智能手机有史以来最好的机器学习性能
芯片参数:该款芯片包含 85 亿个晶体管,同时配备有 6 个 CPU 核心:两个运行主频为 2.66 GHz 的高性能核心(称为 Lightning)与四个高能效核心(称为 Thunder)。另外,其还拥有一块四核图形处理器,一个 LTE 调制解调器,一款苹果自主设计的图像处理器,外加一套每秒可运行超过 5 万亿次运算的八核机器智能神经引擎。这款新的芯片体积更小、智能度更高、性能更强,同时又通过某种神奇的方式获得了低于上代方案的功耗水平。事实上,其能效较去年的 A12 芯片提高了约 30%,这也成为新一代 iPhone 实现 5 个小时电池续航提升的重要基础之一。
应用场景:iPhone

InfoQ高级编辑

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论