

自从 1994 年日本的工程师原昌宏发明二维码以来,微信于 2011 年引进二维码,并很快认定了二维码便是手机上的入口。说不清是二维码成就了微信,还是微信成就了二维码,但是到今天,中国的二维码的使用量已经超过了日本,可以说是移动互联网时代大放异彩。据 2020 年微信大会数据,因为二维码带动的码上经济规模就达到了 8.58 万亿,有超过 5kw 中小商户使用二维码。
房产交易是一个典型的重线下产业互联网市场,由于文化的不同而带来了不同人兴趣的不同,而同一个小区的房子也有非常大的差异,所以如何进行房客匹配是一个非常关键的问题。基础设施的建设可以构筑出客户和经纪人完成交易的全链路平台,而效率的提升可以帮助用户更快速获取自己满意的房子,而这一切在买房上学和市场火热的时候,变得更加突出和重要。
贝壳所进行的二维码营销,就是一条“以房找客”之路。凭借数十万庞大的线下经纪军团,完成数百万线上用户的触达,通过朋友圈二维码营销,将优质房源和目标客户连接在一起,铺设了新的高质量获客渠道。
从房源、客源、场景、类型再加上灰度标签多个维度来说,生成二维码的差异非常之大,我们很难通过全量预生成的方式,提前将业务所需的二维码准备好。特别是在推送 push 的情况下,数量非常庞大,瞬间峰值足以对服务器造成沉重一击。所以,对码上营销来说,二维码的生成成为技术上的关键点。
在强大的需求背景下,我们接手了贝壳找房小程序的二维码生成服务,志在高质量完成新房、二手、租房、海外等业务不断膨胀的生成需求,然而中间并不顺利,老服务不断暴露出来新问题,亟待解决。我们在中间进行了一系列的思考,在这里跟大家进行交流。
架构演化过程
参数过长问题
我们知道,URL 的完整信息可以包含在二维码中;长度越长,二维码就会越密集。当出现类似图片压缩,造成展示精度不够时,就影响了二维码的扫描使用。在一些小的海报和线下展示位就非常不便。
一般可以采用 URL 压缩的方式,先通过短链服务,将长 URL 置换为短 URL,扫码打开之后,前端支持 302 的情况下,就可以直接跳到最终 URL 上。短 URL 服务一般都具有很高的并发能力,所以不会成为性能的瓶颈。所以该问题很容易解决。
但是这里引入了一个新的问题,由于短链服务域名往往承接了非常多不同业务,一些业务常常在微信侧并不合规。曾经笔者就遇到过因为微信封杀 url.cn,导致我方业务牵连受损的情况。

如果企业内部有短链服务,则可以适当降低风险。笔者也遇到了因为租赁页面违规,导致贝壳小程序发版无法过审的问题。混用不止,风险永远都存在。但不可能每个业务都自建一个短链服务,短链服务也很难对每一个 URL 的业务进行了解,并及时拒绝有风险的业务方的接入。
另外一种做法是:
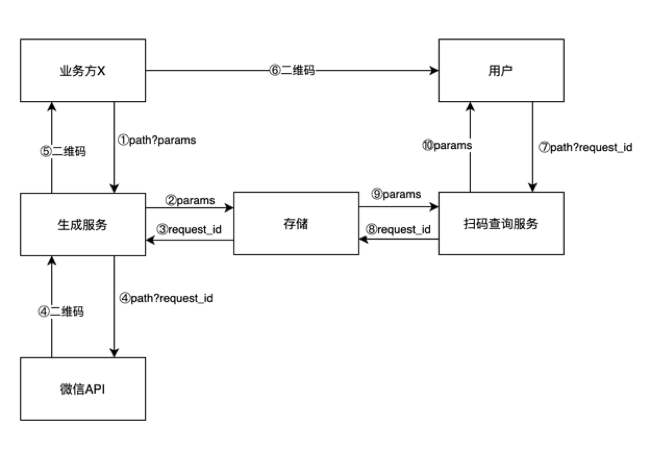
将 URL 的参数部分以 request_id 的形式,进行单独存储;在扫码时,前端先通过查询接口获取 request_id 的参数部分,然后再根据详细参数请求数据和渲染页面,这样就变向实现了二维码的 URL 压缩。不过害处可能是:
前端多了一次扫码查询请求,增加了页面打开的等待时间
二维码是按个人+房源等信息来区分的,特别分散,复用度不高
扫码用户不多,缓存又容易过期淘汰,命中率低
增加了后台存储工作,生成二维码延迟升高,分享体验下降
如果缓存有抖动,有击穿数据库的风险
所以,如果单纯实现成这样,其实并不完善。
并发量问题
大家知道,微信二维码生成方式有:

10w 个二维码显然满足不了贝壳经纪人对不同房源的分享诉求,所以我们只能选择类型三。微信说没有总量限制,但按每分钟 5000,其实隐含了每天最多 720w 个二维码。一般不用关心总量,只需要关注峰值。如果峰值超出,则实际只能当成失败处理。
微信建议量级过大走预生成,但是怎么预生成呢?
二维码信息=经纪人 ID+房源 ID+业务类型+……
贝壳平台拥有数量庞大的经纪人团队,每天接触到想要分享的房源更多,而分享的场景类型也有差异化,所以每分钟 5000 个很快就达到了瓶颈,在周末高峰期已经捉襟见肘。
(1)不可能要求经纪人提前生成二维码保存再使用
经纪人本身对平台提供的码上营销就有学习成本,更不用说操作成本这么高。房源成交随时都在发生,已经成交的房子的二维码失去了营销价值,也是一种浪费。
(2)机器生成很难命中需求
不同的经纪人能够关注到的房子不同,很难通过机器为经纪人提前生成,就算是只针对热门房源,也命中率很低。如果要通过距离、热度等因素来计算,则陷入了一个更大的问题里面。
(3)热门营销活动,针对性预生成
如果是营销活动,一般是有准备的,可以具体的知道需要分享的页面、推送的目标经纪人群体,那么属于有限提前生成,看起来是技术上可行的。这里的问题在于:
开发成本
贝壳分为新房、二手、租赁、海外等业务,还有横向的品质、好房等项目,每个团队都去预生成,会导致营销活动开发成本很高。
时间成本
如果开发一套通用的预生成机制,提前几个小时就开始生成二维码,一个是不一定赶得上业务方的需求上线时间点,二是不一定有这么多资源给你预生成,因为实时生成的量级也很大,留给预生成的额度本来就不多了。
并发压力
如果同时在准备的营销活动比较多,则更加抢手,最后还会因为要预生成而造成比实际峰值更大的峰值。
浪费严重
营销活动的实际参与情况,并不是那么乐观,浪费依然很严重。
动态绑定的预生成方式
思路分析
前面的思路里面,一个比较典型的现象是,白天作业高峰不够用,晚上又无法合理的利用资源。如果我们能够积累一批二维码,可以用于任何业务场景,则能够达到削峰填谷的作用,问题自然迎刃而解。
这就类似于你的旧信用卡到期了,不能换号,只能等厂家制作,完了才能快递给你,等待周期长。而对于新申请开户来说,银行提前制作了大量的有号银行卡,在你申请时,直接任选一张,跟你的身份证绑定就可以了,等待周期短。
核心设计
现在让我们重新看一下前文提到的 request_id 的流程图。
通过分析发现,要生成二维码,只需要 path 和 request_id 即可。而 path 对于每个业务方来说,是相对集中的,目前统计有 30 种。而 request_id 可以走分布式唯一 ID 生成算法,构造一批,这样就可以满足生成二维码的必要条件。等业务方来请求新二维码的时候,就随机取一个已有 request_id 分配,并和 params 完成后期绑定就可以了。扫码过程保持查询 request_id 的过程不变。
由此,二维码的囤积方式,分为三种:
夜间生成,白天复用
工作日生成,周末高峰期复用
白天捡漏
只要囤积的二维码足够多,那么高峰期的分配就不是问题。我们针对白天捡漏算法进行了针对性的详细设计,后续有机会再分享。
性能分析
由于预生成二维码之后,可以完成两项重操作:
上传到 cdn,获取持久的二维码 URL
数据库生成记录,进行落地
所以到实际绑定时,只需要将绑定关系存储到分布式缓存系统(如 redis),则扫码时则可以直接命中缓存,扫码和分配都会比较快。为了防止 redis 过期,可以加上回写逻辑。将绑定关系计入日志流水,或者发送到消息队列,异步任务批量入库,性能也会比较高。
而预生成的二维码可以放入 kafka 等高性能的消息队列,需要时取出即可。只要在 kafka 中放入足够多的二维码,应对高峰期的 20 分钟过量需求,是完全不成问题的。
所以整体流程改造下来,比实时生成,无论是速度还是并发能力,都能够提升非常多。瓶颈从微信接口并发能力,转移到内部服务器的数量,和 kafka 队列积累的二维码总量大小上来。
页面多样性问题
以上方案中,还存在一个问题:path 的管理成本。
-path 随着业务方迭代,会不断申请,需要持续维护
按 path 维度预生成,很难预估下一分钟的需求量级
某个 path 如果下线,则对应 topic 下资源全部作废
Kafka 的 auto.create.topics.enable 开关如果被 DBA 关闭,那么新增一个 path 需要手动提单才能创建新 topic
所以固定一个 topic 的方式则比较好用,而 kafka 性能可以通过增加 partition 数量的方式来进行快速的扩容,所以并发能力不是问题。
如何做呢?我们的选择是前端开发一个中间页,将原本的 path 信息也放入 params 参数中,所有的预生成二维码都是用中间页的固定 path,这样就不用担心浪费问题,可以进行海量预生成累积了。
性能方面,并未增加更多的接口调用,所以无妨。
有区别的差异是:
前端如果能尽早知道最终的 path,则可以尽早展示骨架图。实际上,替换为 loading 效果,在产品上也可以接受,所以差异不大。
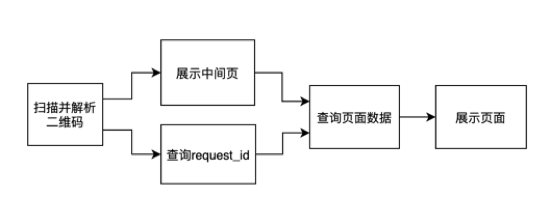
很难使用微信的扫码数据预拉取功能
微信能够在小程序冷启动的时候通过微信后台提前向第三方服务器拉取业务数据,当代码包加载完时可以更快地渲染页面,减少用户等待时间,从而提升小程序的打开速度。
由于前面增加了一个公共的扫码查询接口,再跳转各个业务方时,很难通过一个固定接口来知道新房、二手、租赁等业务方的各个页面都需要什么具体的数据。
总结
通过以上的逐步分析和方案思考和实践,我们最终完成了一个转交项目,二维码服务的高并发改造,并支持以很低的成本进行维护。中间也有谈到一些利弊的思考,以及我们的选择。如果你有更好的思路,请不吝赐教。如有勘误,请大力斧正。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 6 条评论