

深度学习出来以后,大家发现它和以前机器学习的算法运行系统不一样,这就有了 GPU 的“辉煌岁月”:)。大神 Jeff Dean 也曾为此抓狂过的,这才有了 Tensorflow。
自动驾驶的深度学习任务也很大,建立强大的深度学习平台是非常必要的。
1 “Demystifying Parallel and Distributed Deep Learning: An In-Depth Concurrency Analysis”, 9, 2018
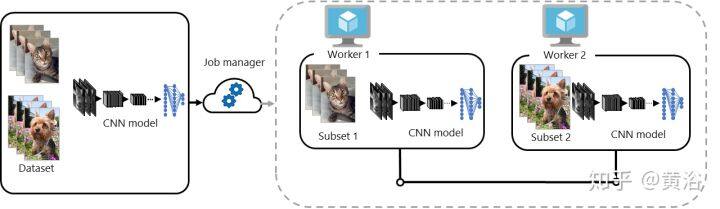
深度学习的训练很费时间,这个在一开始热的时候就了解。当时一般个体研发人员会寻找硬件加速卡,这也是当时 Nvidia GPU 大受欢迎的原因。但作为云计算和大数据领航者的谷歌,自然会考虑如何在云平台上完成深度学习的训练。
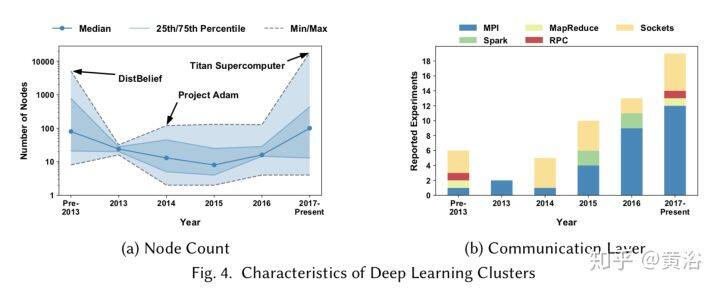
当时谷歌开发的系统是 DistBelief,但性能还是不理想,主要原因在于以往在云平台上运行的多是数据密集型(data intensive)应用程序,而不是计算密集型(compute intensive);但深度学习不管是推理还是训练,都同时具有这两种特性,而后者显然造成了分配到各个计算节点的任务之间耦合相关度高,通讯开销过大。即使如此,DistBelief 仍然有可圈可点的贡献,比如参数服务器(parameter server)的采用,异步的随机梯度下降(A-SGD)算法,还有数据并行加模型并行的策略等。
事实上,一个机器学习,特别是深度学习的分布式实现,是统计准确性(泛化)和硬件效率(利用率)的折衷。互联网最重要的指标是延迟、带宽和消息速率。不同网络技术性能不同,专用 HPC 互连网络可以在所有三个指标中实现更高的性能。
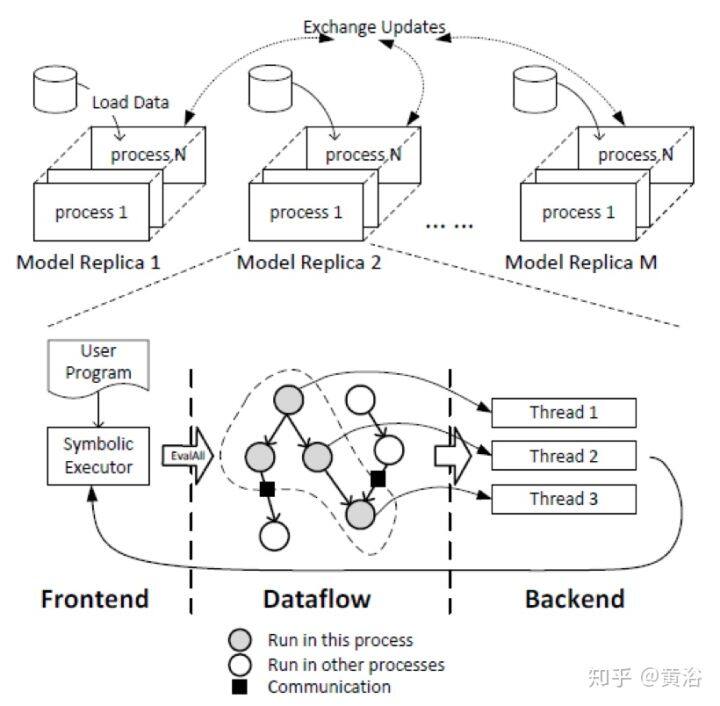
计算机每个计算作业可以建模为有向无环图(DAG)。DAG 的顶点是计算,边是数据依赖(或数据流)。这种计算并行性可以通过两个主要参数来表征:图的工作 W,其对应于顶点的总数,以及图的深度 D,任何最长路径上的顶点的数量。这两个参数表征并行系统的计算复杂性。

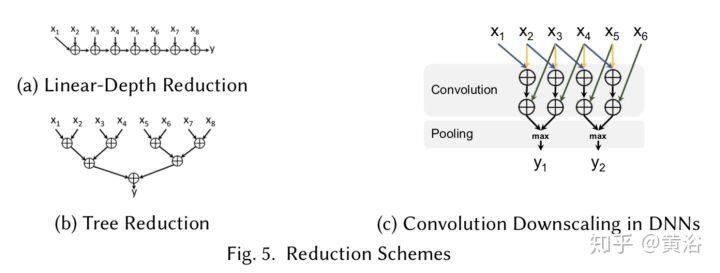
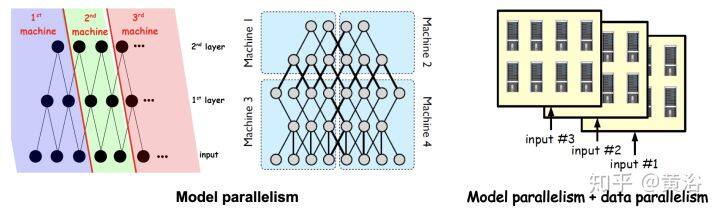
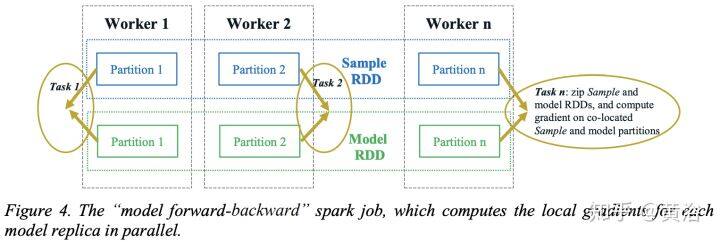
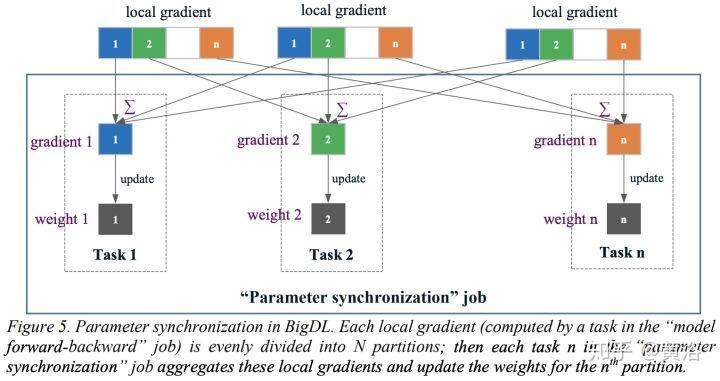
神经网络中的高平均并行度不仅可以用于有效地计算操作单元,而且可以在不同维度同时评估整个网络。由于使用微型批处理(minibatch)、层宽度和网络深度等,可以在并行处理器同时划分前向评估和后向传播成不同模式,即按输入样本划分的数据并行(data parallelism)模式,按网络结构划分的模型并行(model parallelism)模式,以及按层划分的流水线(layer pipelining)模式,如图所示。
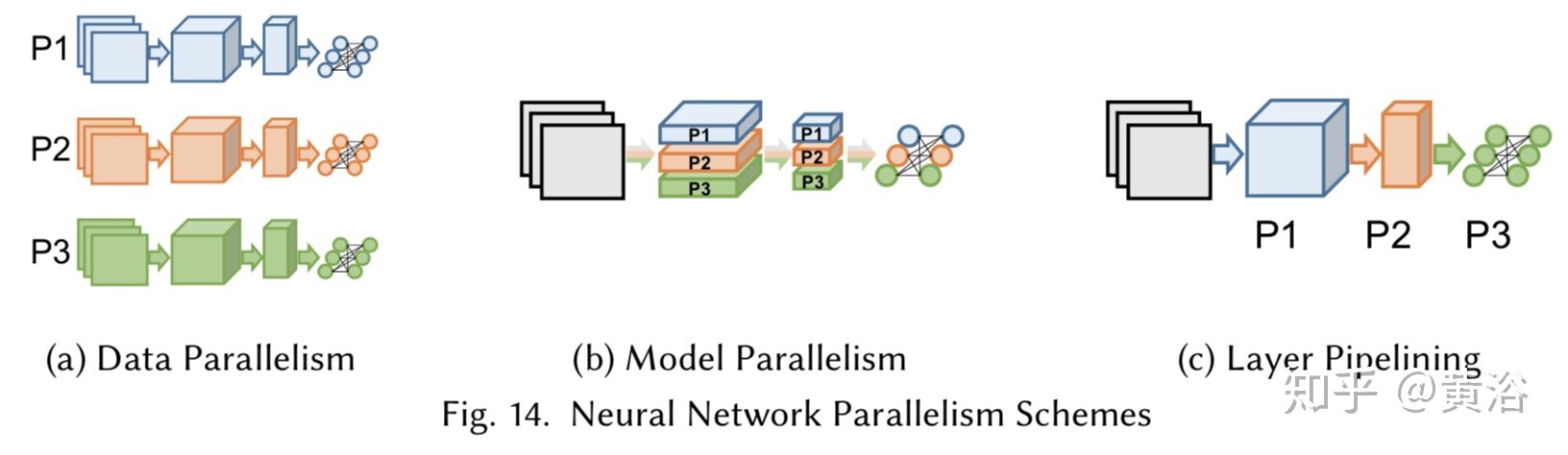
· 数据并行
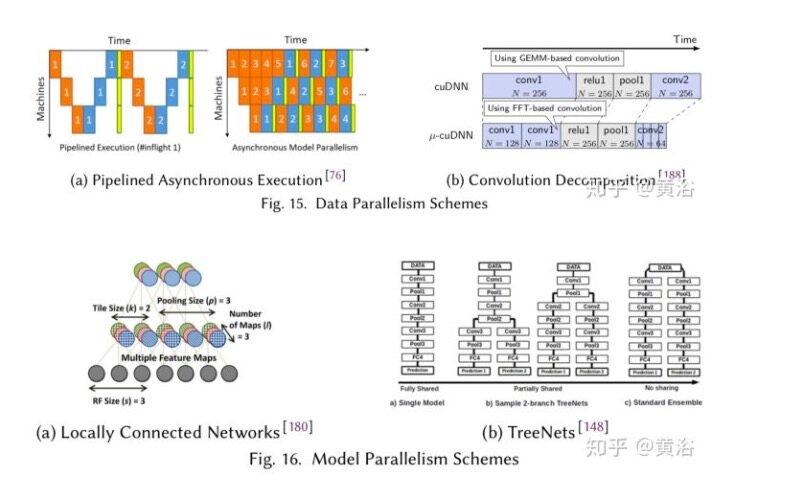
在 minibatch SGD 中,数据以 N 个样本为增量进行处理。并行化的直接方法是将小批量样本的工作划分为多个计算资源(核心或设备),最初称为模式并行,因为输入样本称为模式,其实就是数据并行。
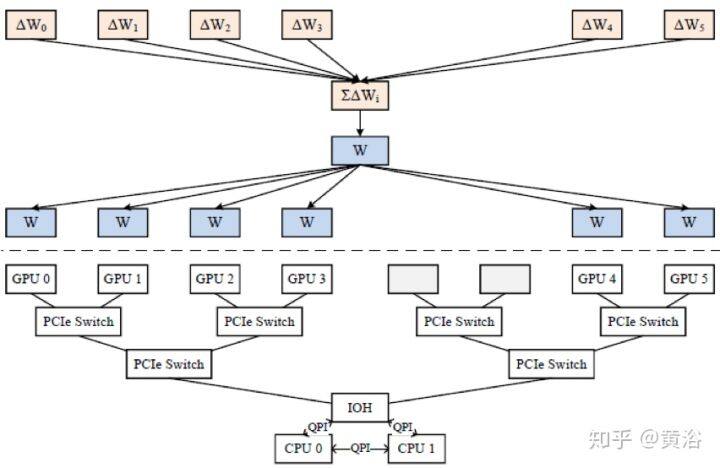
数据并行性的扩展性自然由小批量(minibatch)尺寸定义。除了批量归一化(BN)之外,一般运算符对单个样本进行一次操作,所以前向评估和反向传播几乎完全独立。然而,在权重更新阶段,必须对分区的结果求平均以获得相对整个最小批处理(minibatch)的梯度,可能导致 AllReduce 操作。 此外,这种方法让所有参与设备必须能访问所有网络参数,就是说,们应该复制。
· 模型并行
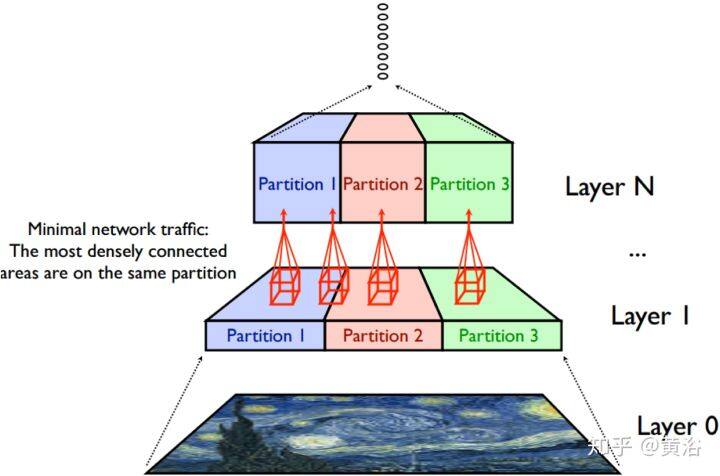
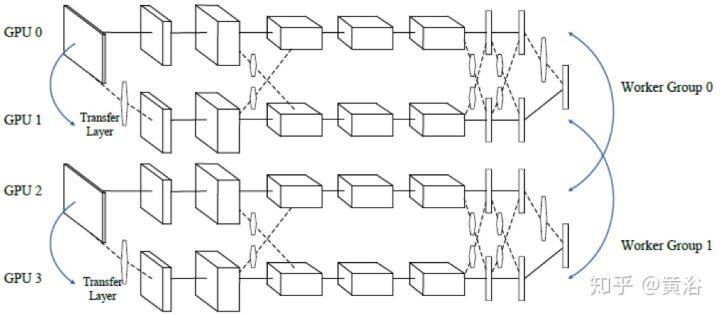
模型并行,也称为网络并行,该策略根据每层中的神经元划分工作。在这种情况下,样本小批量被复制到所有处理器,并且神经网络的不同部分在不同的处理器上计算,这样可以节省存储器,但是在每个层之后引起额外的通信开销。
为了降低完全连接层(FCL)中的通信成本,可以将冗余计算引入神经网络。特别是划分 NN 时,使每个处理器负责两倍的神经元(具有重叠),这样计算更多但通信更少。
卷积层(CL)的模型并行性可能不太有效地缩放,这取决于输入维度。如果样本按功能(通道)在处理器之间进行划分,则每个卷积都需要对所有处理器输出求和(根据分解产生 AllReduce 或 AllGather 操作)。利用空间维度的并行性可以为某些输入尺寸加速,因为周边交换(halo exchange)操作可以在前向和后向传递中和其他计算重叠。为了减轻周边交换问题,卷积滤波器可以通过 TCN(Tiled Connected Networks)和 LCN(Locally-Connected Networks)进行分解,其中前者可以部分地权重共享,而 LCN 则不然。不幸的是,权重共享是 CNN 的重要组成部分,有助于减少内存占用并改善泛化,因此标准卷积运算符的使用频率高于 LCN。
· 分层流水线
在深度学习中,流水线操作可以指重叠计算,即在某层和其下一层之间(当数据准备好),或者根据深度划分神经网络,将层分配给特定的处理器。流水线可以被视为数据并行的一种形式,因为元素(样本)通过网络并行处理;但也作为模型并行性,因为流水线长度由神经网络结构决定。
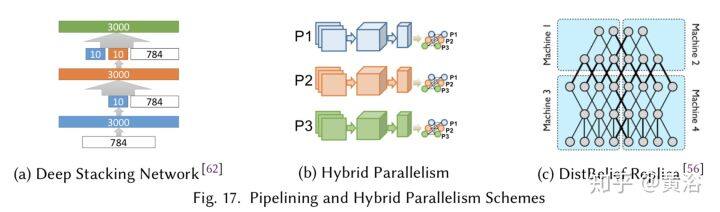
第一种流水线形式可用于重叠前向评估、反向传播和权重更新,通过减少处理器空闲时间来提高利用率。在更精细的粒度中,网络架构可以围绕重叠层计算的原则设计,如深度堆叠网络(Deep Stacking Networks,DSN)。在 DSN 中,每个步骤计算不同的完全连接层(FCL),但先前的结果都连接到层输入。由于宽松的数据依赖性,每个层能部分地并行计算。
· 混合并行
谷歌的 DistBelief 分布式系统结合了三种并行策略。在实现中,同时训练多个模型副本,其中每个副本用不同样本训练(数据并行)。在每个副本根据同一层的神经元(模型并行性)和不同层(流水线)划分任务。 微软的 Adams project 延伸了 DistBelief 的思想并展示了相同类型的并行性,但是流水线仅限于同一节点上的 CPU 核。
在分布式环境中,可能存在多个独立运行的训练代理实例,必须修改整个算法。对深度学习的分布式实现方案可以定义在三个轴上:模型一致性(model consistency),参数分布(parameter distribution)和训练分布(training distribution)。
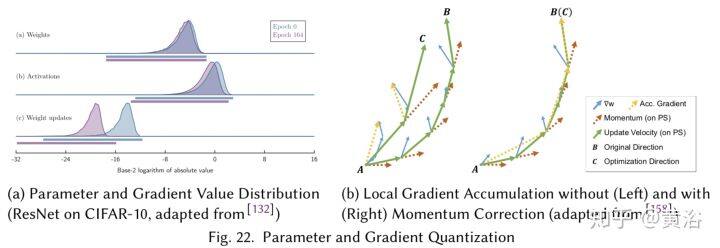
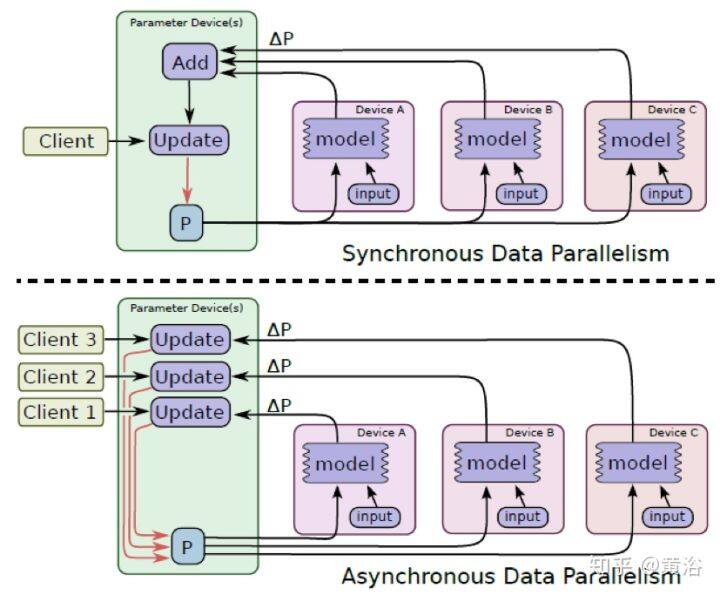
为了支持分布式数据并行的训练,需要在参数存储区读写参数,其方式可以是中心化(centralized)或去中心化(decentralized)的。这是一个系统性开销,会阻碍运行训练的扩展性。
如果训练中每个分布计算单元都能得到最新参数,这种训练算法叫模型一致性方法(consistent model methods)。当放松同步的限制条件,则训练得到的是一个不一致的模型,比如 Yahoo 提出的分布式 SGD 算法 Hogwild,允许训练代理随意读取参数和更新梯度,覆盖现有进展。
Hogwild 已被证明可以收敛稀疏学习(sparse learning)问题,其中更新仅修改参数的子集,可用于一般的凸优化和非凸优化问题。
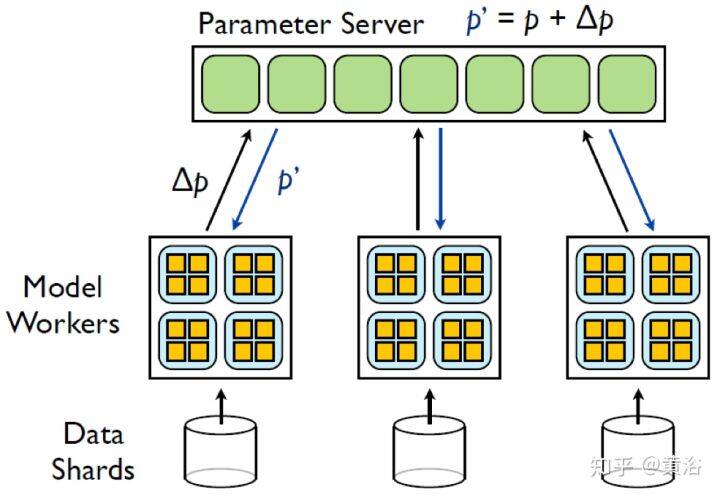
深度学习训练选择中心化还是去中心化网络架构,取决于多种因素,包括网络拓扑、带宽、通信延迟、参数更新频率和所需的容错。中心化网络架构通常包括参数服务器(parameter server,PS)基础设施,可包括一个或多个专用节点;而分散式架构将依赖 AllReduce 在节点之间传递参数更新。通信之后 PS 执行中心化参数更新,而去中心化架构的参数更新由每个节点分别计算,并且每个节点会创建自己的优化器。

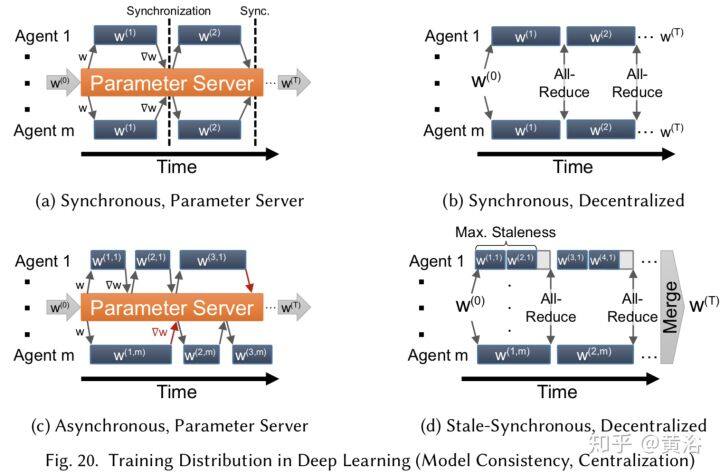
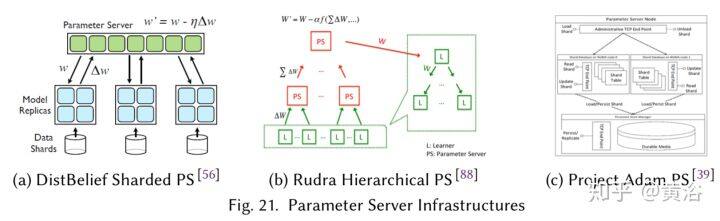
训练分布方案的权衡通过全局更新的通信成本建模。虽然 AllReduce 操作对不同大小的消息和节点都可以有效地实现,可是 PS 方案要求每个训练代理和 PS 节点之间有发/收信息的来往。因此,并非使用所有路由,而且就通信而言,这种操作等同于 AllReduce 运行 Reduce-then-Broadcasting。另一方面,PS 有一个训练的“全局图”,可以对一个位置的梯度做平均,并启用训练代理的异步运行方式。这样,在 PS 上执行一些计算可允许节点传递更少的信息,并且在训练期间动态启动(spin-up)和移除节点以增加容错性。
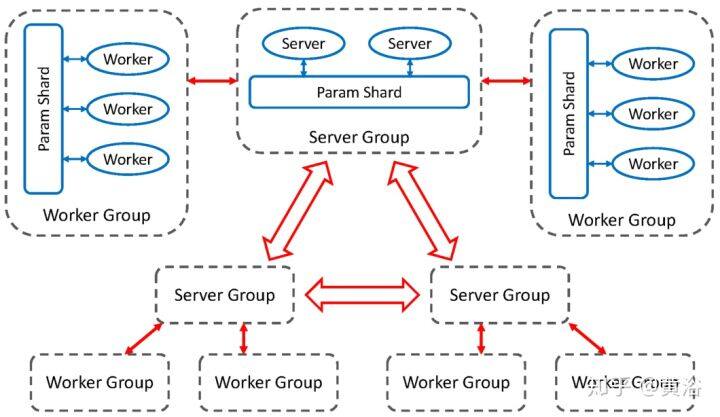
PS 的基础结构是一个抽象概念,不一定由一个物理服务器表示。谷歌 DistBelief 系统提出了一种分片参数服务器(Sharded PS),将参数所有权分到多个节点,每个节点包含其中一部分。结合模型并行性和分层流水线两种模式,减轻了 PS 的一些拥塞,其中“模型复制品”(训练代理)的每个部分传输其梯度并从不同的接收其权重。Rudra 的分层参数服务器(Hierarchical PS)为训练代理分配 PS“叶子”,从特定的训练代理组传播权重和梯度到全局参数存储区,这样进一步减轻了资源竞争问题。
在去中心化方案设置中,可以使用异步训练实现负载平衡。但是,参数交换不能使用 AllReduce 操作,会导致全局同步。不一致去中心化的参数更新方法是使用固定通信图,采用基于邻居的梯度/参数交换方式。另一种方法是 Gossip 算法,每个节点与固定数量的随机节点通信(大约为 3)。由于分布式深度学习不需要强一致性,因此该方法在 SGD 取得一定的成功,收敛和速度更快。
“Using Distributed TensorFlow with Cloud ML Engine and Cloud Datalab”
3 “Distributed training of deep learning models on Azure”
4 Peer-to-Peer Framework
5 DistBelief: Distributed Deep Nets at Google
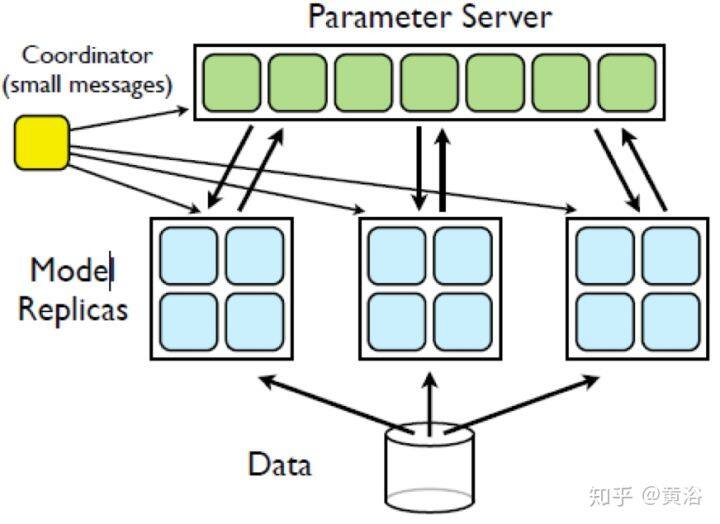
6 Project Adam @MSR
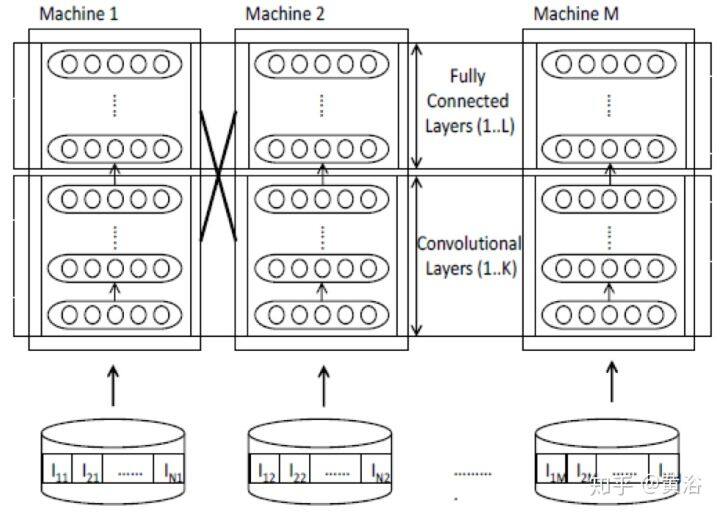
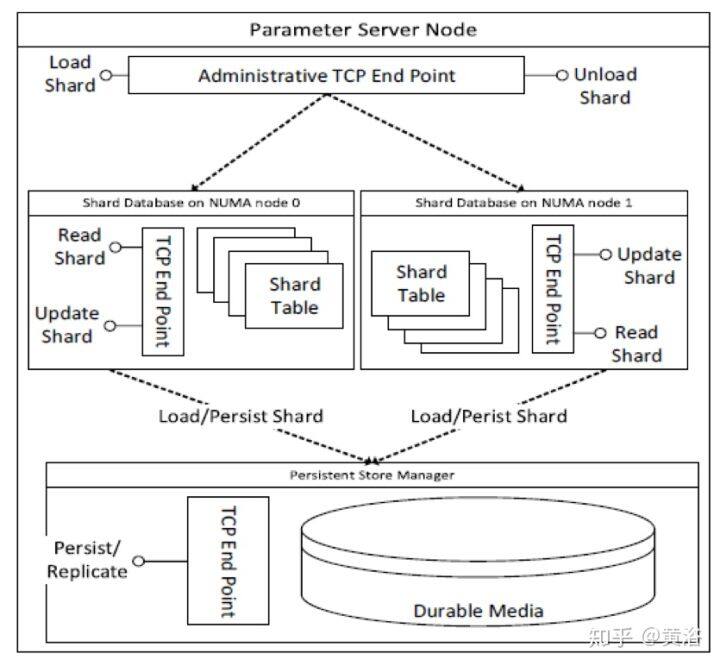
7 Petuum: Iterative-Convergent Distributed ML
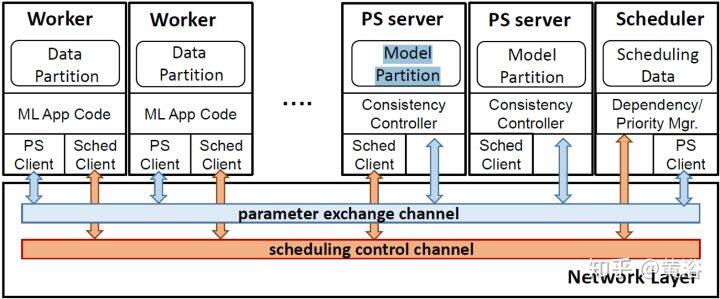
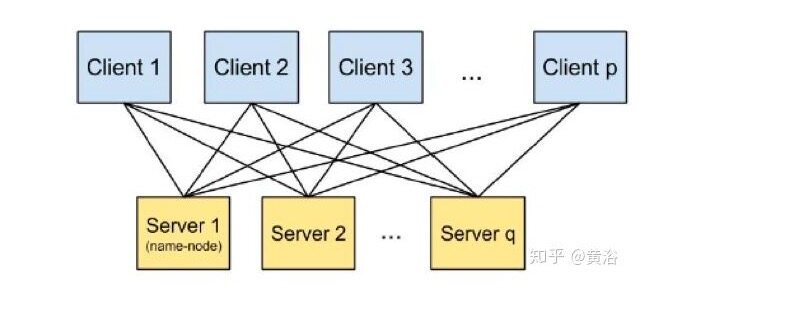
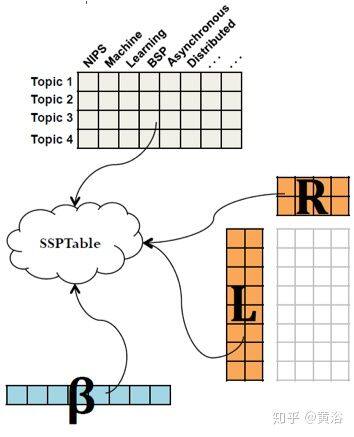
8 SINGA: A Distributed Deep Learning Platform
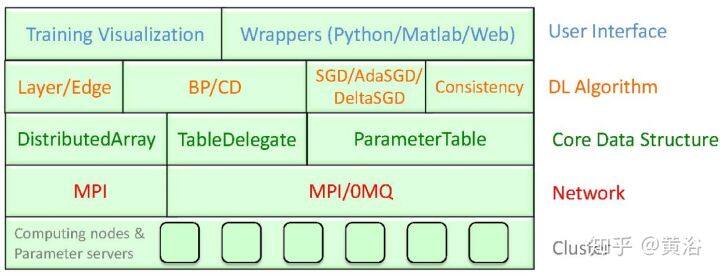
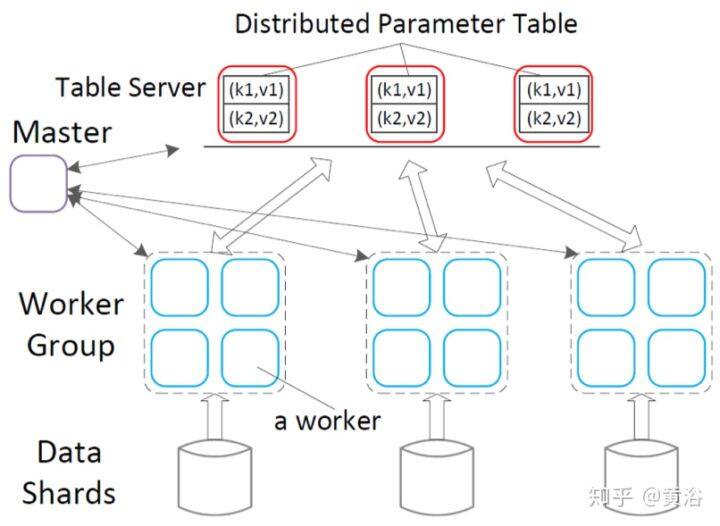
9 Minerva: A Scalable and Highly Efficient Training Platform
10 Mariana: Deep Learning Platform at Tencent
11 MXNET: Distributed Deep Learning
12 TensorFlow: Large-Scale Heterogeneous Distributed ML
张量流(TensorFlow)是谷歌在 DistBelief 基础上研发的第二代深度学习系统。张量(Tensor)意思是 N 维数组,流(Flow)指基于数据流图(data flow graph)的计算。TensorFlow 使复杂的数据结构在深度学习网络中分析和处理,可被用于语音识别或图像识别等多项领域。
TensorFlow 提供丰富的深度学习相关的 API,支持 Python 和 C/C++接口;支持 Linux 平台,Windows 平台,Mac 平台,甚至手机移动设备等各种平台;提供了可视化分析工具 Tensorboard,方便分析和调整模型。
TensorFlow 的系统架构有设备层(Device layer)和通信层(Networking layer)、数据操作层、图计算层、API 接口层和应用层,前三个是核心层。
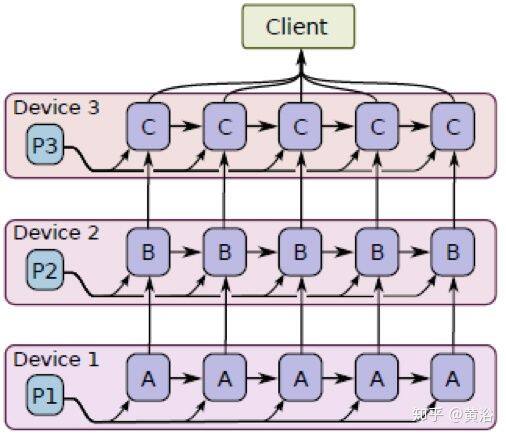
第一层是设备和通信层,负责网络通信和设备管理。设备管理可以实现 TensorFlow 设备异构的特性,支持 CPU、GPU、Mobile 等不同设备。网络通信依赖 gRPC 通信协议实现不同设备间的数据传输和更新。第二层是张量的 OpKernels 实现。依赖网络通信和设备内存分配,它们以张量为对象实现各种 TensorFlow 操作或计算。第三层是图计算层(Graph),包括本地和分布式两种计算流图的实现。图计算模块有图的创建、编译、优化和执行等部分,图中每个节点都是 OpKernels 类型表示。第四层是 API 接口层。Tensor C API 是 TensorFlow 功能模块接口封装,便于调用。第五层则是应用层。不同编程语言通过 API 接口调用 TensorFlow 核心功能,在应用层实现各种相关应用。
计算机编程模式可分为命令式(imperative style)和符号式(symbolic style)。命令式编程容易理解和调试,只是命令语句基本没有优化。符号式编程有较多的嵌入和优化,不容易理解和调试,但运行速度有提升。Torch 是典型的命令式风格,caffe、theano、mxnet 和 Tensorflow 都使用了符号式编程。
符号式编程将计算过程抽象为计算流图,所有输入、运算和输出的节点均符号化处理。计算流图建立输入节点到输出节点的传递闭包,完成数值计算和数据流动。这个过程可以进行优化,以数据流(data flow)方式完成,节省内存空间,计算速度快,但不适合程序调试。
Tensorflow 的计算流图如同数据流一样,数据流向表示计算过程。数据流图可以很好的表达计算过程,Tensorflow 中引入控制流扩展其表达能力。
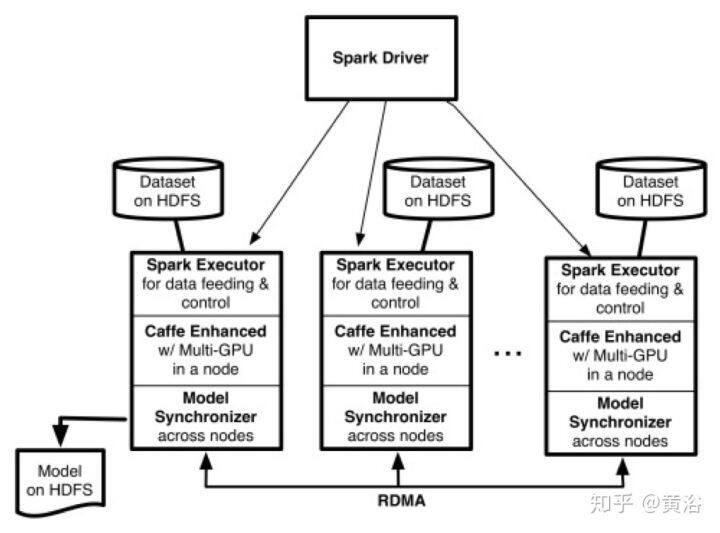
13 Caffe on Spark at Yahoo
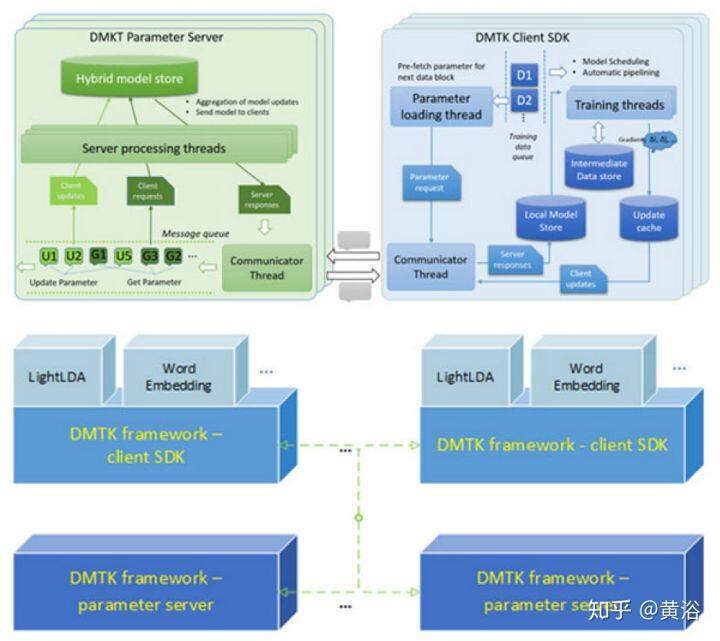
14 DMTK: Distributed Machine Learning Toolkit @ MSR
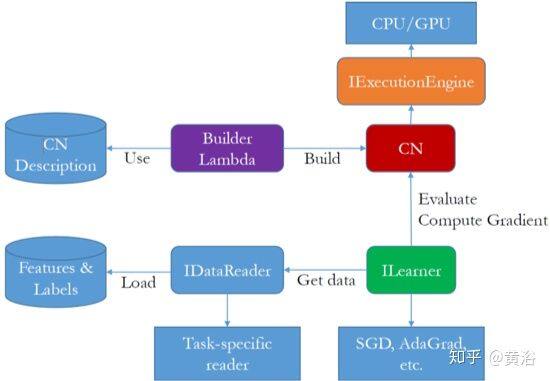
15 Computational Network Toolkit (CNTK) at MSR
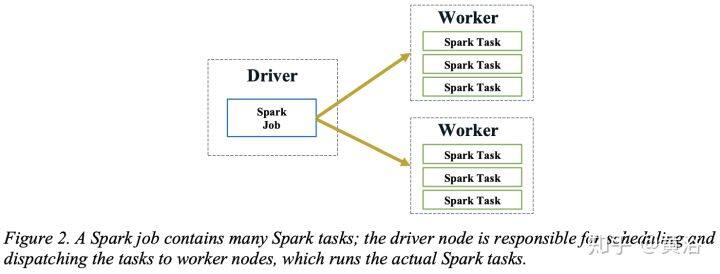
16 BigDL: A Distributed Deep Learning Framework for Big Data
作者介绍
黄浴,奇点汽车美研中心总裁和自动驾驶首席科学家,上海大学兼职教授。曾在百度美研自动驾驶组、英特尔公司总部、三星美研数字媒体研究中心、华为美研媒体网络实验室,和法国汤姆逊多媒体公司普林斯顿研究所等工作。发表国际期刊和会议论文 30 余篇,申请 30 余个专利,其中 13 个获批准。
原文链接
注:本文源自黄浴的知乎:https://zhuanlan.zhihu.com/p/58806183

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论