

我曾经访问过一个有“营业时间”的网站,它只在某些时间段才“开放”。我因此感到困惑,还有点沮丧。计算机可以运行一整天,为什么这个网站就不可以呢?可能我已经习惯了互联网那种令人难以置信的可用性保证。
然而,在互联网出现之前,全天候可用性的概念还“不成气候”。可用性虽然令人期待,但还没有到非要不可的程度。我们只在有需要时才使用电脑,它们不会为了一个极小可能出现的请求而等待。随着互联网的出现和发展,之前不太常见的本地凌晨 3 点请求变成了全球性的主要营业时间点,确保计算机能够处理这些请求就变得非常重要。
然而,很多系统只依靠一台计算机来处理这些请求——我们都知道,这样的故事不会有好的结局。为了保持正常运行,我们需要在多台计算机之间分配负载。然而,分布式计算有它的优势,也有它的不足:特别是同步和容忍系统内的部分故障。每一代工程师都在迭代这些解决方案,以满足他们那个时代的需求。
分布式是如何进入数据库领域的?这是个特别有意思的话题,因为相比计算机科学领域的其他问题,这个问题的发展要慢得多。当然,我们可以通过软件在本地数据库跟踪某些分布式计算的结果,但数据库本身的状态却是保存在单台机器上。为什么?因为跨机器复制状态是很难的。
在这篇文章中,我们将介绍分布式数据库如何处理系统内的部分故障,以及什么是高可用性。
使用现成的东西:主备
最开始,数据库运行在单台机器上,只有一个节点负责处理所有的读取和写入操作,没有所谓的“部分失败”这种事情。数据库要么在运行,要么被关闭。
对于互联网来说,单个数据库的故障涉及两个方面的问题。首先,计算机被全天候访问,因此停机时间会直接影响到用户。其次,计算机不停地运行,更有可能发生故障。最明显的解决方案是拥有多台可以处理请求的计算机,而这也就是分布式数据库故事的开端。
在单节点世界中,最自然的解决方案是让单个节点处理读写操作,同时将它的状态同步到辅助节点上——于是,主备(Active-Passive)复制机制就诞生了。
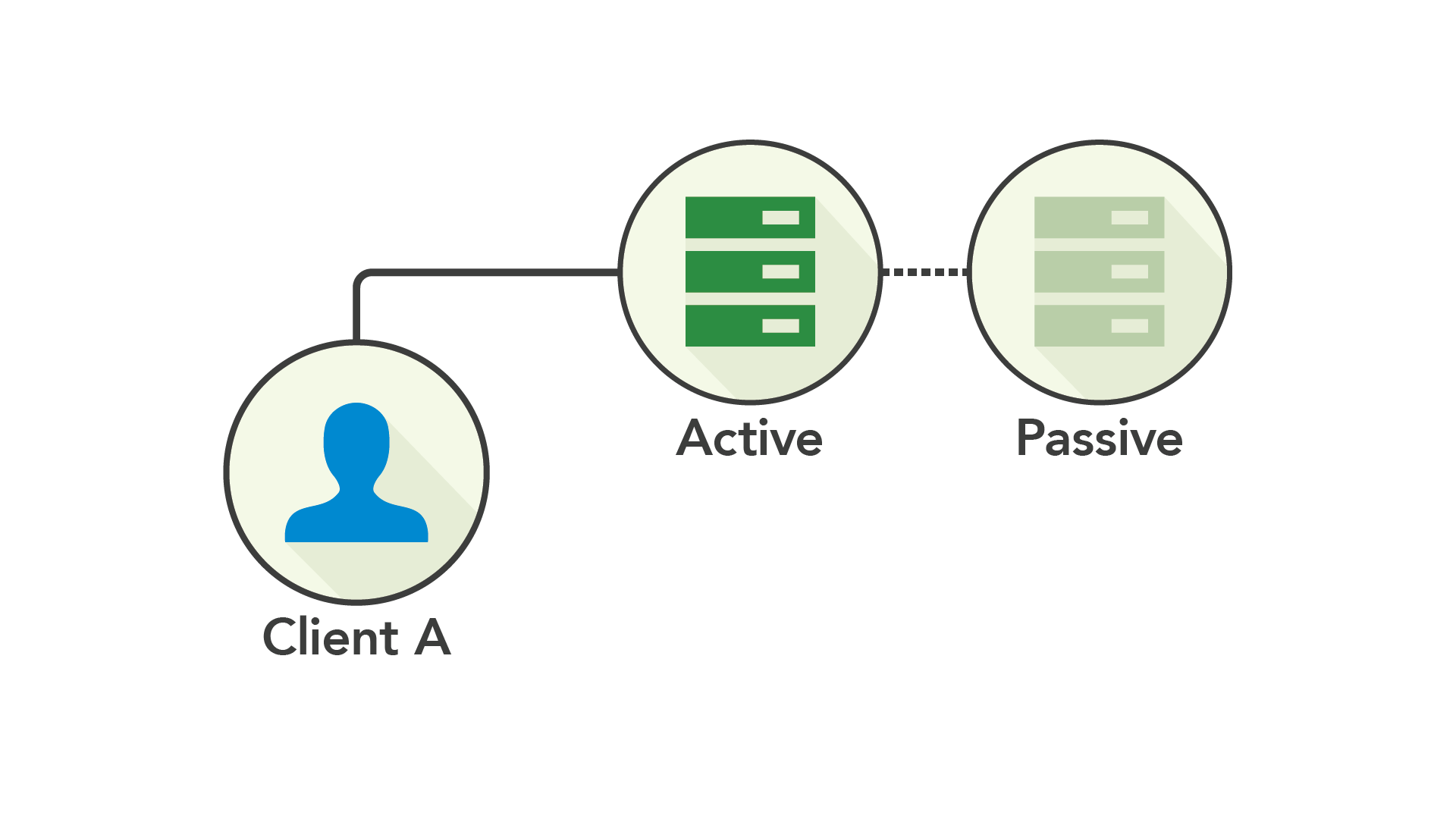
主备机制通过备份主节点来提高可用性——当主节点发生故障,将流量重定向到备用节点,并将其提升为新的主节点。无论何时,你都可以用新的备用节点替换掉宕机的主节点。
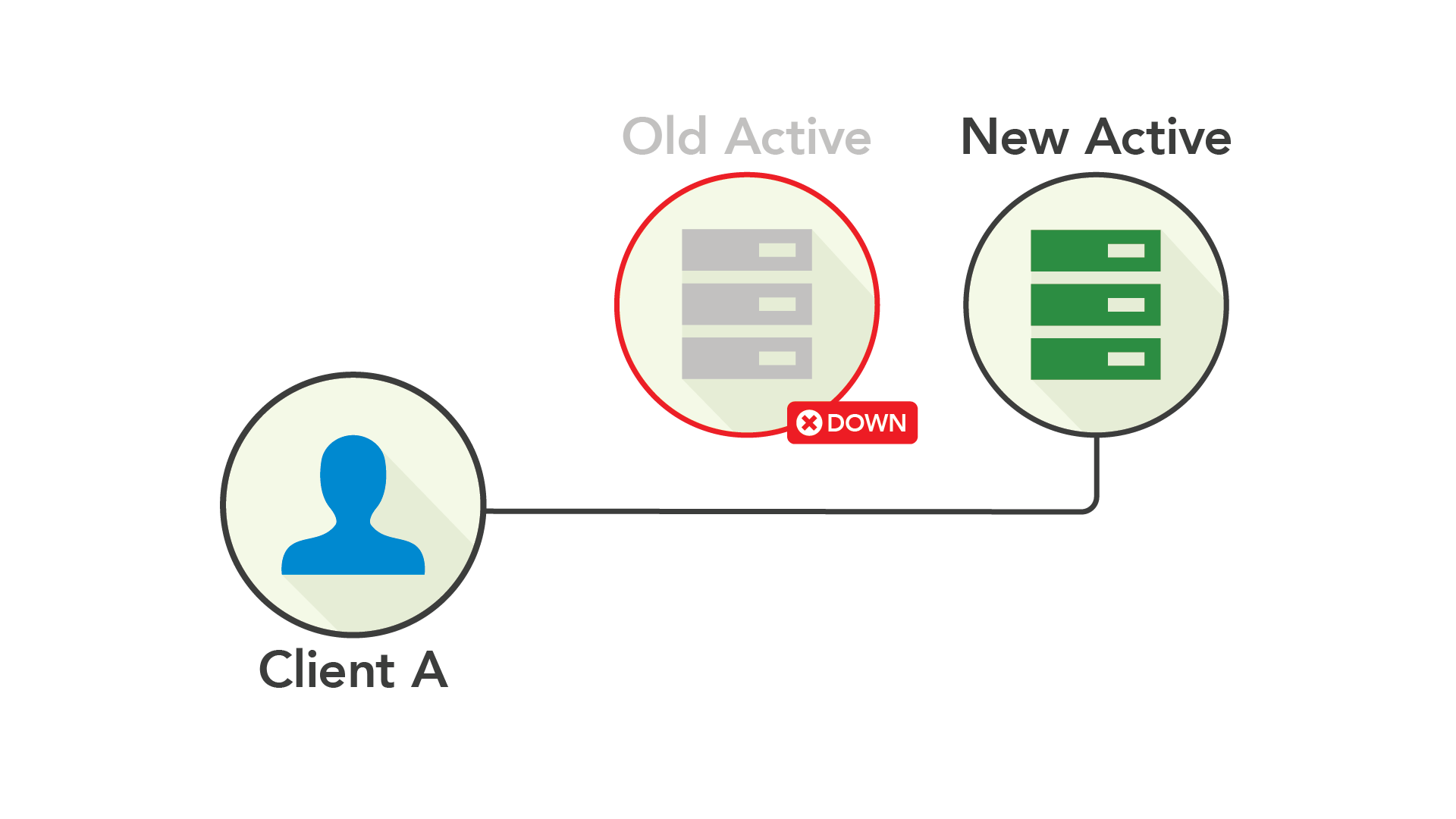
首先,从主节点到备用节点的复制是一个同步过程,也就是说,在备用节点做出确认之前,不会提交任何复制操作。但是,如果备用节点发生故障该怎么办?如果备用节点不可用,当整个系统挂掉时,这种机制就变得毫无意义——但在进行同步复制时,这种情况真的有可能发生。
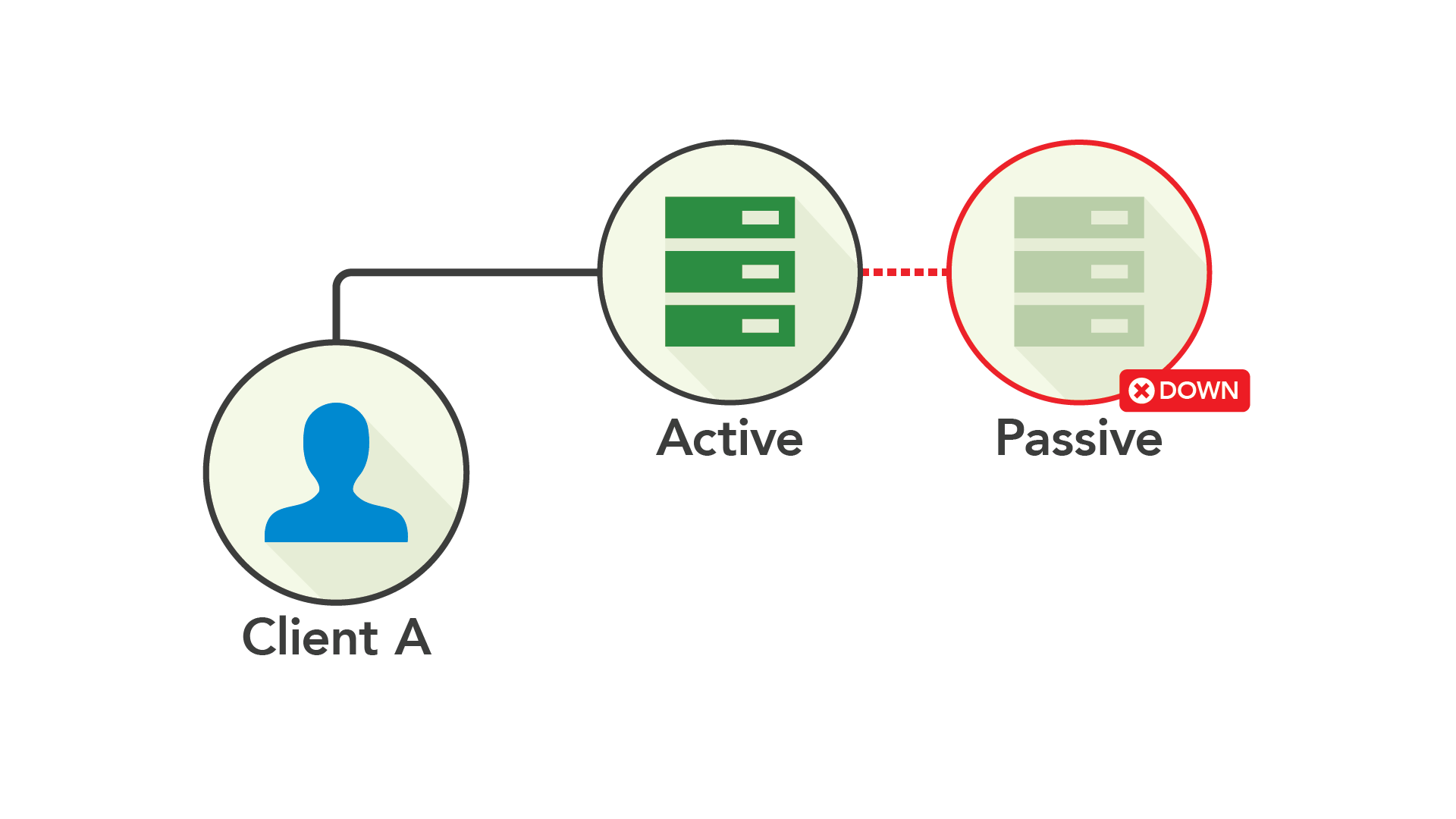
为了进一步提高可用性,可以异步复制数据。虽然架构看起来是一样的,但在主节点或备用节点发生故障时,都不会影响数据库的可用性。
虽然异步主备机制又向前迈进了一步,但仍然存在重大不足:
当主节点发生故障时,任何尚未复制到备用节点的数据都可能丢失——尽管客户端会认为数据已完全提交。
因为依靠单台机器处理流量,所以仍然受限于单台机器的最大可用资源。
追求 5 个 9:扩展到多台机器
随着互联网的快速发展,业务需求在规模和复杂性方面也有所增长。对于数据库而言,这意味着它们需要能够比单个节点处理更多的流量,提供“始终在线”的高可用性就成为一个必要的需求。
鉴于大量工程师拥有从事其他分布式技术的经验,很明显,数据库可以超越单节点的主备机制,在多台计算机之间分布数据库。
分片
同样,最简单的做法就是利用现有的东西,因此工程师通过分片将主备复制变成了更具可扩展性的方式。
你将集群的数据按照某个值(例如行数或主键中的唯一值)进行拆分,并将这些数据段分布在多个节点上,每个节点都有一个主备对。然后在集群前添加某种路由技术,将客户端定向到正确的节点上。
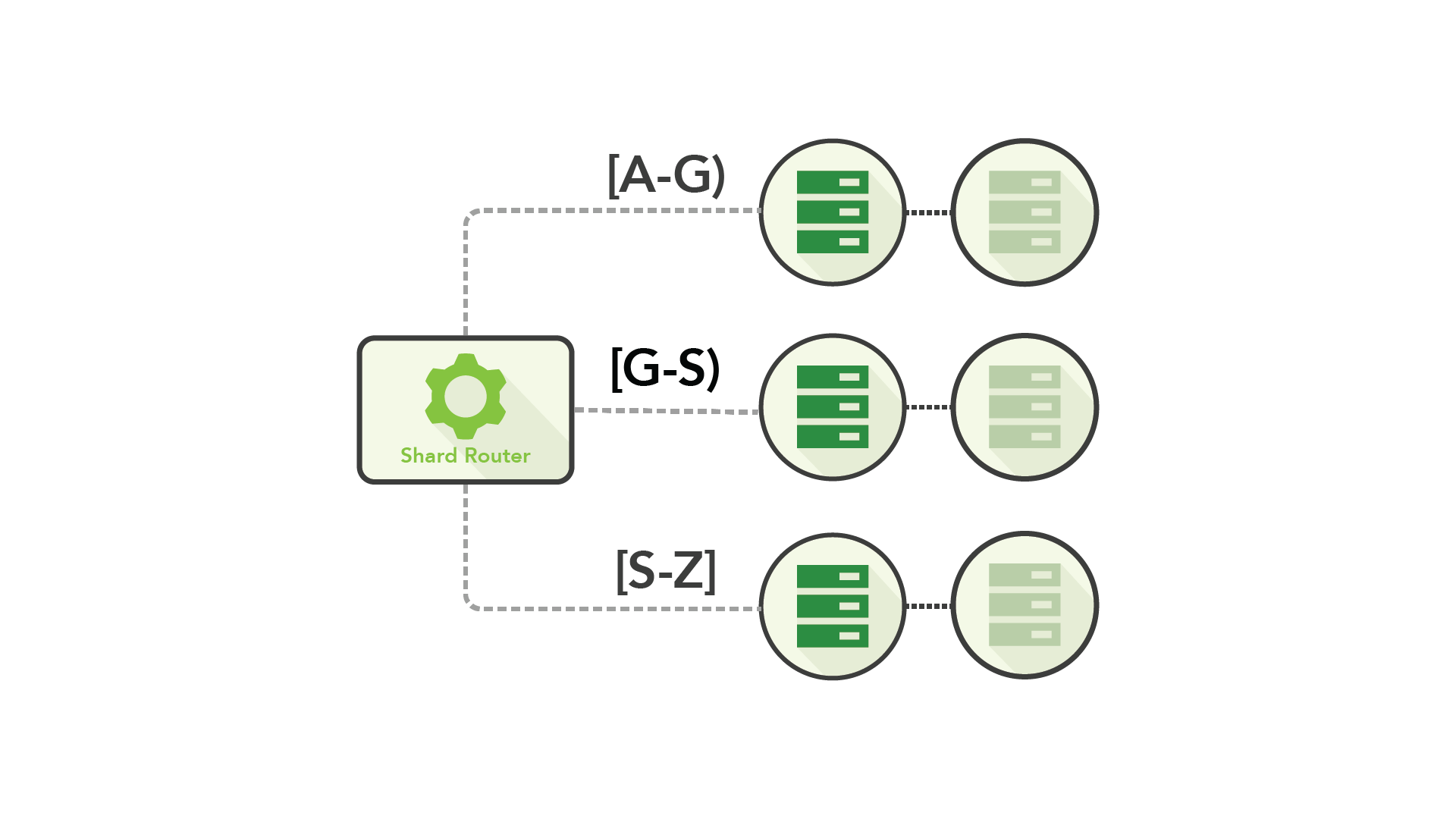
通过分片,你可以在多台计算机之间分配工作负载,提高吞吐量,并通过容忍更多的部分故障来获得更大的弹性。
尽管存在这些优势,但因为系统分片极其复杂,会给团队带来巨大的运营负担。管理分片的任务可能会变得非常繁重,以至于路由逻辑最终会逐步渗透到应用程序的业务逻辑中。更糟糕的是,如果你想要修改系统的分片方式(例如模式变更),通常会导致巨大的工作量。
单节点主备系统也提供了事务支持(即使不是强一致性)。不过,因为跨分片协调事务非常困难和复杂,以至于很多分片系统完全放弃了事务支持。
双活
鉴于分片数据库难以管理且功能不全,工程师们开始着手开发至少可以解决其中一个问题的系统。他们开发出来的仍然是不支持事务的系统,但更容易管理。随着对应用程序运行时间需求的增加,帮助团队满足其 SLA 是一个明智的决定。
这些系统背后的想法是每个节点可以包含集群的全部或部分数据,并负责处理读写操作。当一个节点接收到写入操作时,将变更传播到需要数据副本的所有节点。为了处理两个节点接收到相同键的情况,在提交之前,需要通过特殊算法来解决冲突。因为每个节点都是“活跃”的,因此这种模式被称为双活(Active-Active)。
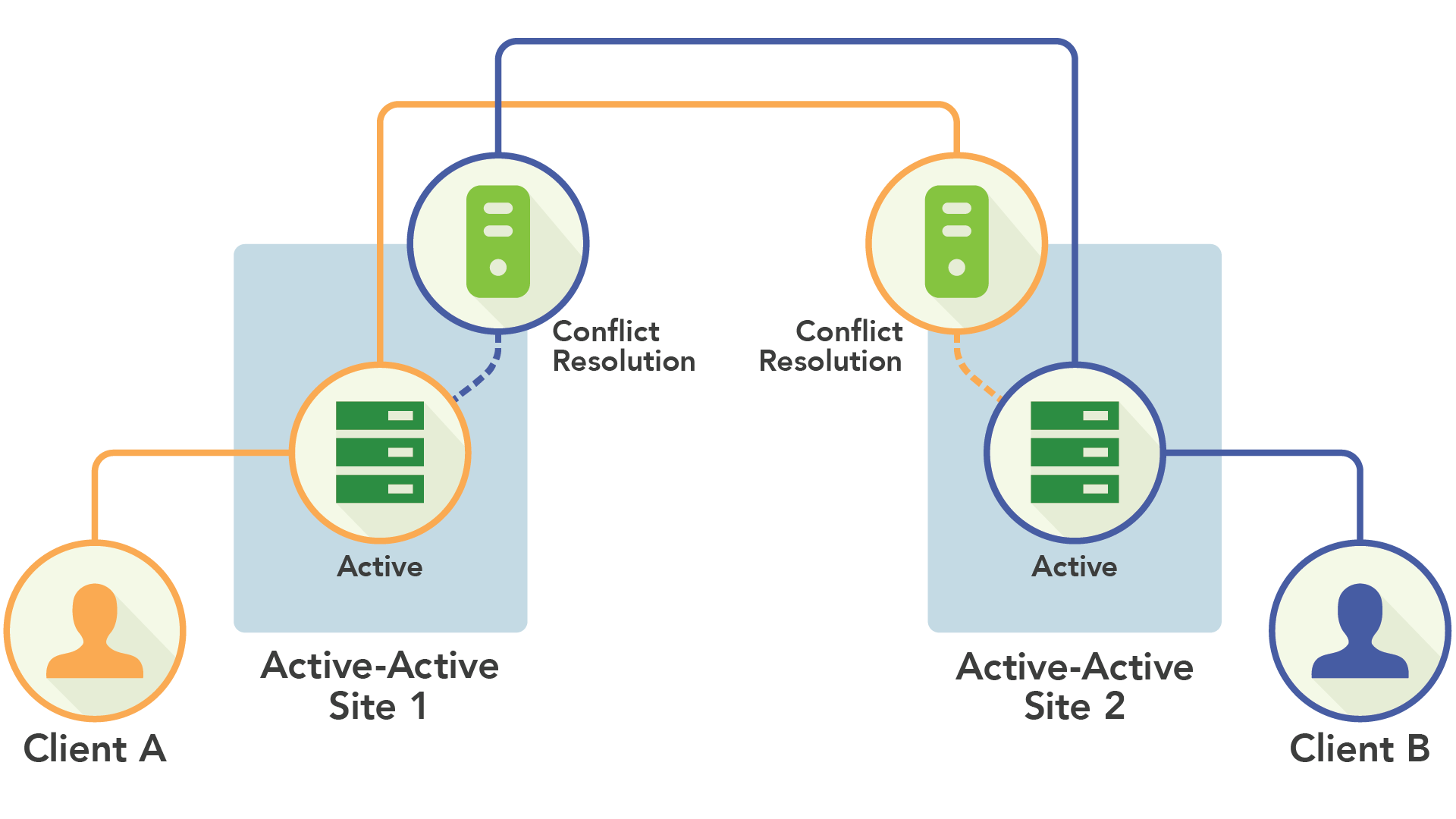
由于每个服务器都可以处理所有数据的读写操作,因此更容易通过算法进行分片,部署也更易于管理。
在可用性方面,双活的表现非常出色。如果一个节点发生故障,只需将客户端重定向到另一个节点上。只要数据的单个副本处于活动状态,就可以处理读写操作。
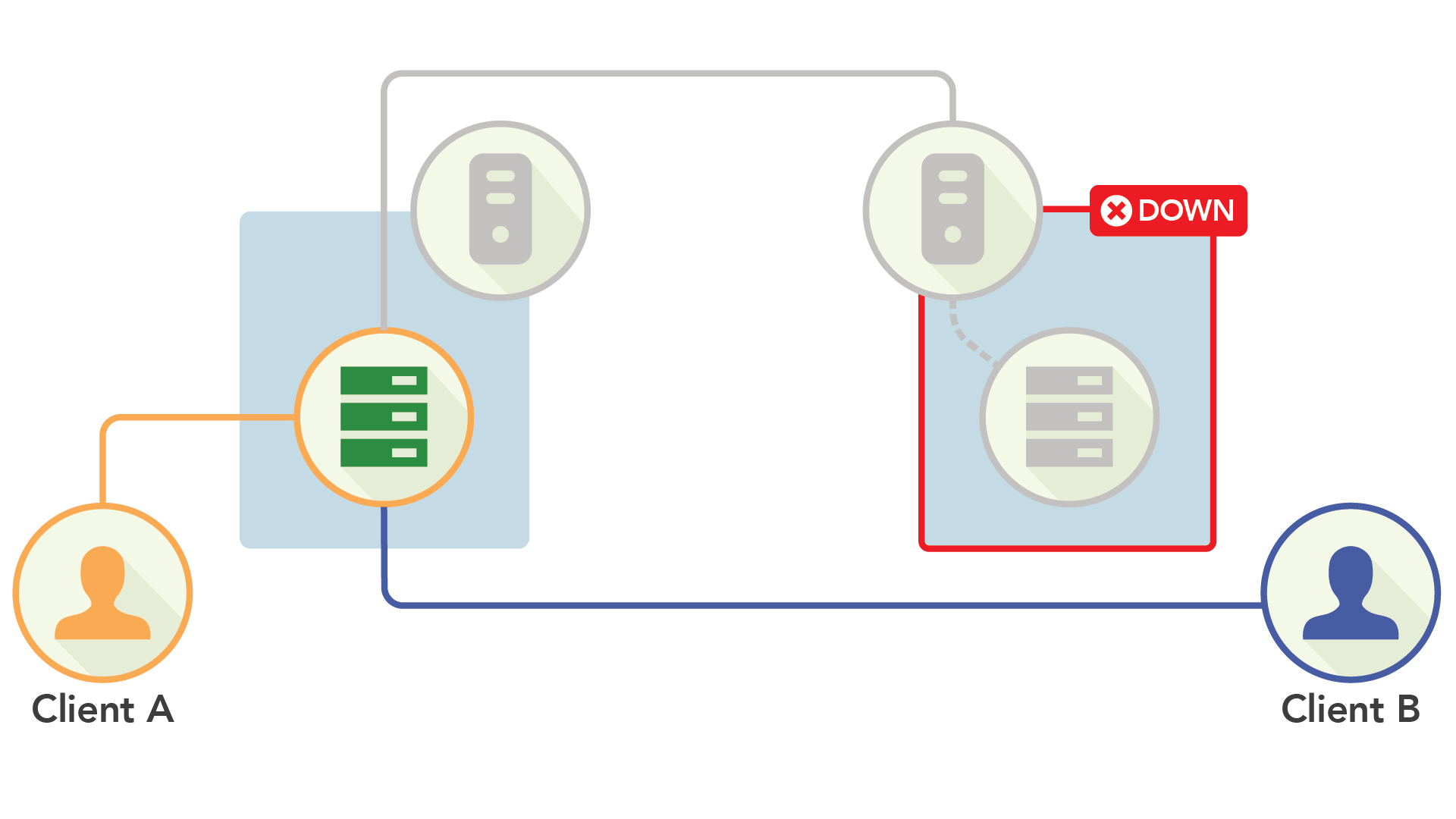
虽然这种方案具备很高的可用性,但在一致性方面存在不足。因为每个节点都可以处理键的写入,所以在处理数据时要保持数据完全同步变得非常困难。这种方法通常是通过冲突算法来调解节点之间的冲突,这些算法在处理不一致性问题时只会做出一些粗粒度的决策。
因为这个解决方案是在事后完成的,也就是在客户端已经收到响应之后——并且理论上已经基于响应执行了其他业务逻辑——所以双活复制很容易导致数据出现异常。
不过,考虑到运行时间问题,停机比潜在的数据异常成本更高,因此双活成了主要的复制类型。
大规模一致性:共识和多活可用性
虽然双活似乎解决了可用性问题,但却忽略了事务,这导致需要强一致性的系统找不到合适的解决方案。
例如,谷歌在它的广告系统中使用了庞大而复杂的 MySQL 分片系统,严重依赖 SQL 来查询数据库。这些查询通常依赖二级索引来提高性能,所以必须保持派生数据的完全一致性。
最后,系统规模变得越来越大,导致 MySQL 分片出现问题,他们的工程师开始思考如何解决这个问题,即如何拥有一个可以提供业务所需的强大一致性的大规模可扩展系统。双活缺乏事务支持,这意味着它不是一个好的选择,所以他们不得不去设计一些新的东西。他们最终得到的是一个基于共识复制的系统,它可以保证一致性,也可以提供高可用性。
在使用共识复制时,写入操作被传给一个节点,然后再复制到其他节点。一旦大多数节点已经确认写入,就可以提交写入操作。
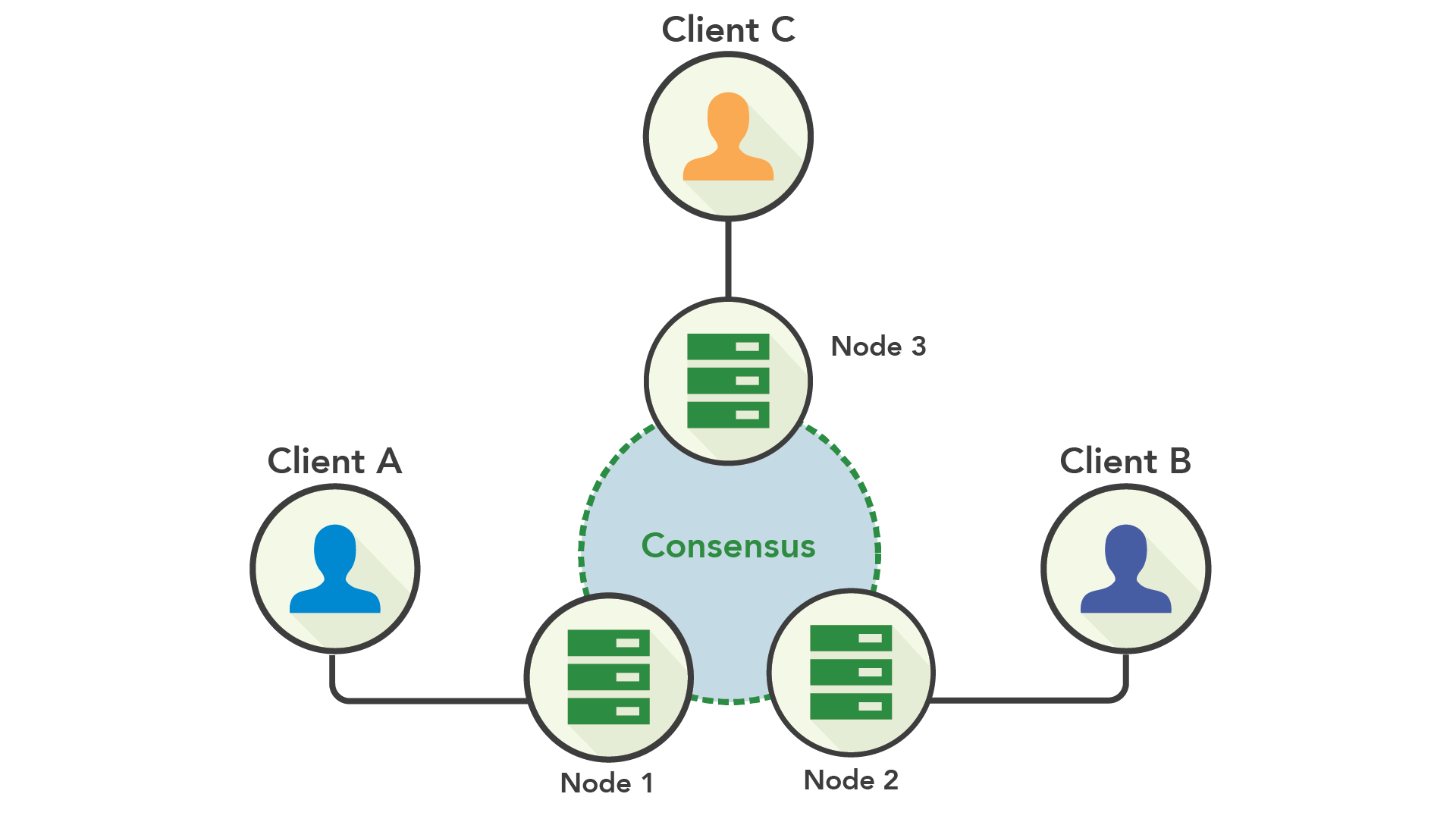
共识和高可用性
这里的关键是共识复制处于同步和异步复制之间的一个最佳位置:你需要一部分节点保持同步,至于是哪些节点就无关紧要。这意味着集群可以容忍少数节点宕机,而不会影响系统的可用性。
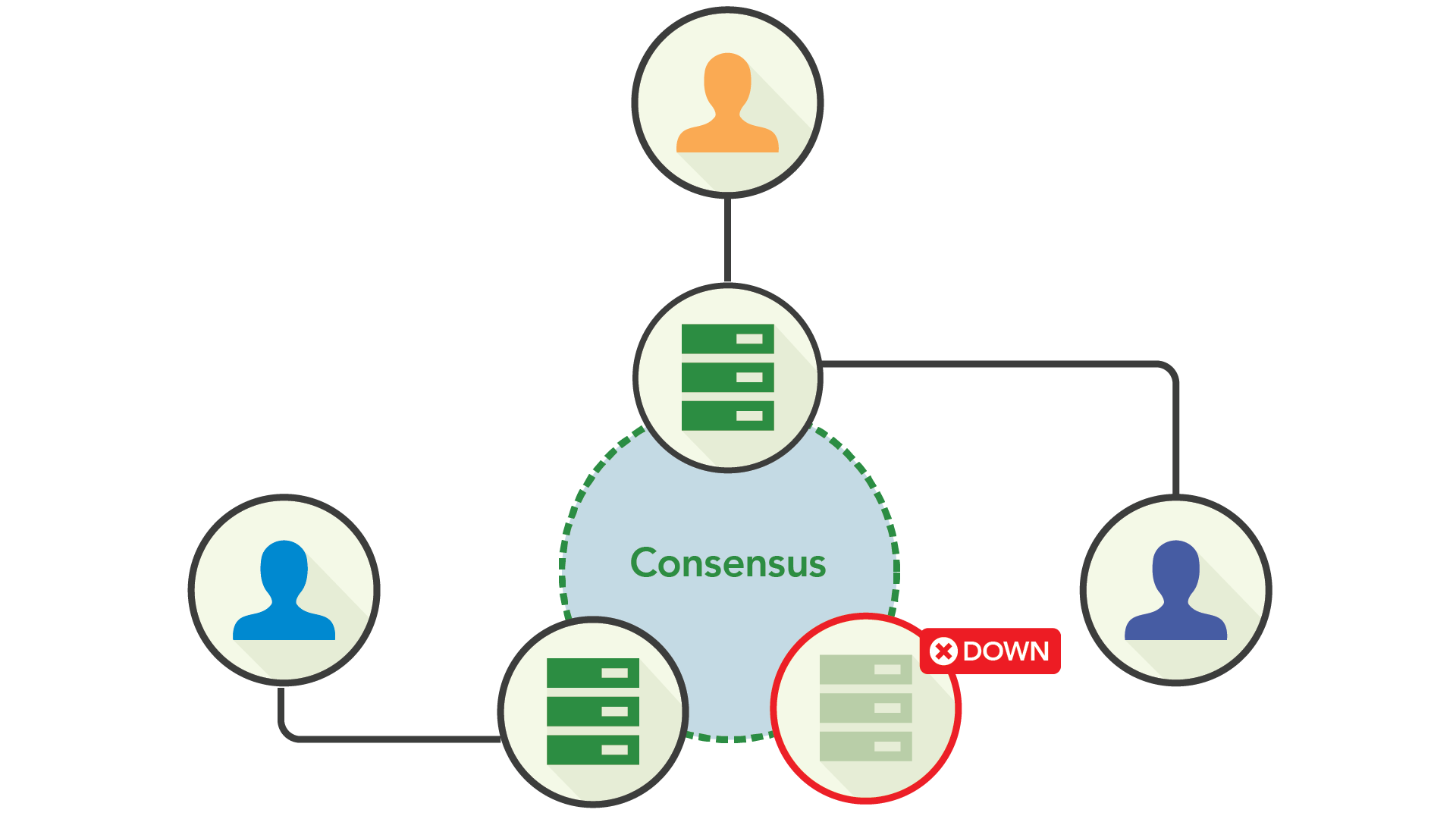
但是,共识的代价是它需要节点间进行通信以执行写入操作。虽然你可以采取一些措施来减少节点之间的延迟,例如将它们放在同一可用区域中,但这需要在可用性方面做出权衡。例如,如果所有节点都在同一个数据中心,它们彼此之间的通信速度很快,但是如果整个数据中心发生故障,那么可用性就不复存在。将节点扩展到多个数据中心可能会增加写入所需的延迟,但如果整个数据中心发生故障并不会影响应用程序,从而保证了可用性。
双活与多活
双活通过让集群中的任意节点处理读写操作并只在提交写入后才将数据变更传播到其他节点来实现可用性。
多活可用性允许任意节点提供读写操作,但确保大多数副本在写入操作上保持同步,并且只让最新的副本处理读取操作。
在可用性方面,双活只需要一个副本用于处理读取和写入操作,而多活需要大多数副本在线才能达成共识(这仍然允许系统内的部分失败)。
除了可用性,这些数据库在一致性方面存在差异。在大多数情况下,双活数据库接受写入操作,但不能保证客户端现在或将来某个时刻一定能够读取到写入的数据。多活数据库只在能够保证以后可以以一致的方式读取到数据的情况下才接受写入。
昨天、今天和明天
在过去的 30 年中,数据库复制和可用性已经取得了重大进展,现在甚至可以支持全球范围的部署,看起来好像永远不会出现故障。主备复制为这个领域奠定了重要的基础,但最终,我们需要更好的可用性和更大的规模。
从那时起,业界开发了两种主要的数据库范式:双活主要用于关注快速写入的应用程序,而多活主要用于关注一致性的应用程序。
让我们共同期待有一天能够利用量子纠缠并实现分布式状态管理的下一个范式。
英文原文:https://www.cockroachlabs.com/blog/brief-history-high-availability

暂无签名

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论