

核心要点
Saga 能够实现长时间运行的、分布式的业务事务,这样的事务会跨多个微服务执行一组操作,实现一致的全有或全无的语义。
为了实现解耦,微服务之间的通信最好按照异步的方式来进行,比如借助 Apache Kafka 使用分布式的提交日志。
发件箱模式为服务作者提供了一种解决方案,能够让他们在本地数据库执行写入,同时通过 Apache Kafka 发送消息,避免依赖不安全的“双重写入(dual writes)”。
Debezium 是一个分布式的开源数据变更捕获平台,为使用发件箱模式的编排式 Saga 流提供了健壮和灵活的基础。
在转向微服务的时候,我们意识到的第一件事情就是单个服务都不是孤立存在的。尽管我们的目标是创建松耦合、独立的服务,它们之间的交互要越少越好,但是很可能某个服务需要另外一个服务所持有的数据集,或者多个服务需要协同行动才能达成业务领域中一致的操作结果。
借助变更数据捕获实现的发件箱模式是解决微服务之间数据交换问题的一种行之有效的方式,这种模式能够避免对多种资源(如数据库和消息代理)的不安全的“双重写入”,从而能够实现最终一致的数据交换,在这个过程中不依赖所有参与者的同步可用性,也不需要复杂的协议,如 XA(由The Open Group定义的广泛用于分布式事务处理标准)。
在本文中,我会探讨如何进一步使用发件箱模式,也就是将其用于实现 Saga,即可能会跨多个微服务的长时间运行的事务。常见的例子就是预订由多个部分组成的行程:要么所有的航班和住宿都预订成功,要么全部取消预订。Saga 将这样一个整体的业务事务分割成一系列的本地数据库事务,这些事务会在相关的服务中执行。
Saga 入门
为了在出现失败的情况下“回滚”整体的业务事务,Saga 依赖于补偿事务的理念:每个在此之前已经应用过的本地事务必须要能通过运行另外一个事务来进行“撤销”,该事务会取消掉之前已经完成的变更。
Saga 并不是什么新鲜的概念:早在 1987 年,Hector Garcia-Molina 和 Kenneth Salem 在他们的 SIGMOD Sagas论文中就首次讨论了这个理念。但是,在业界不断向微服务架构演进的背景下,Saga 作为一种由相关服务中的本地事务作为支撑的方案越来越受欢迎,比如目前正在活跃开发中的长时间运行的操作的MicroProfile规范,这些问题通常不能使用ACID语义来解决。
为了让阐述更加具体,我们考虑一个电子商务业务的样例,它由三个服务组成:订单、消费者和支付。当新的购买订单提交到订单服务时,就会执行如下的流程,其中包含了其他的两个服务:
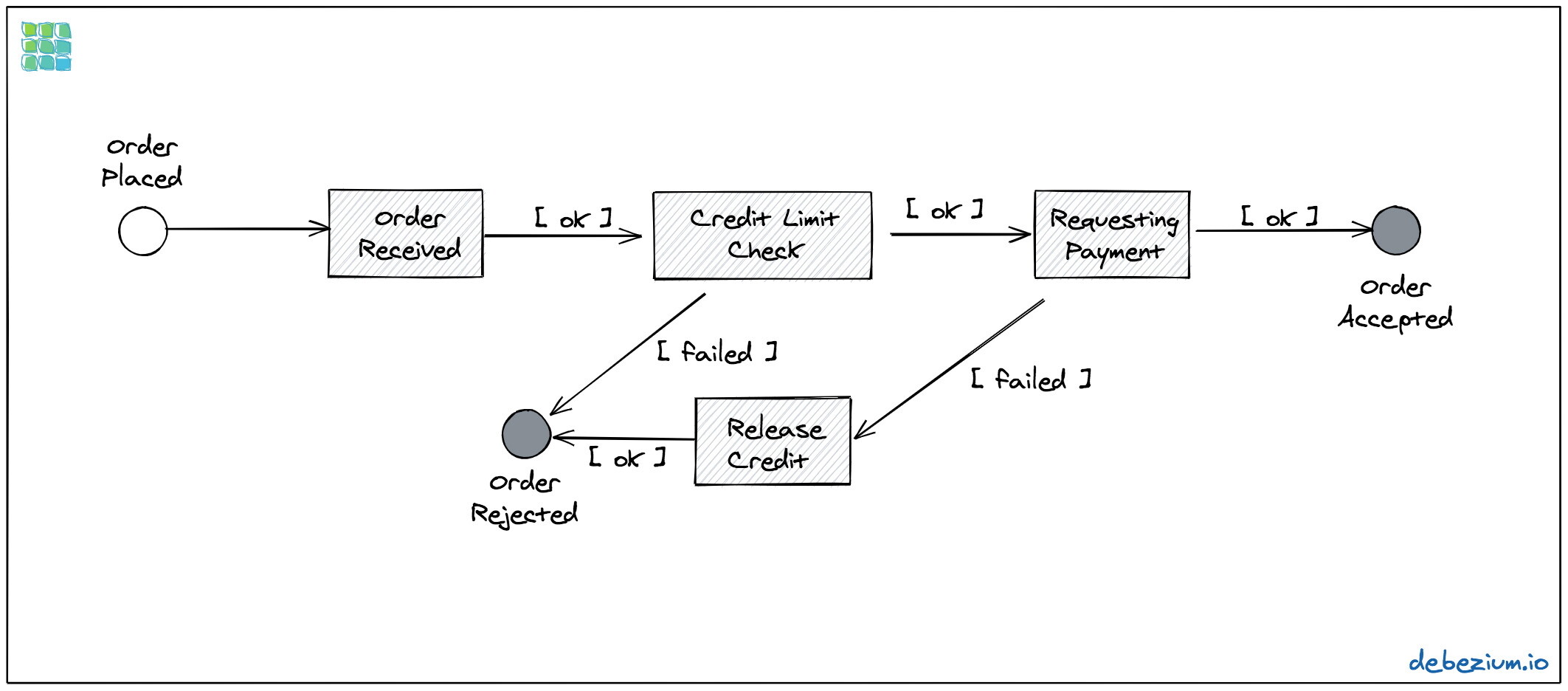
图 1:订单状态的转换
首先,我们需要通过消费者服务来检查传入的订单是否匹配消费者的信用额度(因为我们不希望用户的待处理订单超过某个阈值)。如果消费者的信用限额是 500 美元,新进来的订单是 300 美元,那么这个订单就符合当前的限额,剩余的额度就会变成 200 美元。如果随后又有一个 259 美元的订单,那么它就会被相应的拒绝,因为它超过了当前消费者开放的信用额度。
如果信用额度检查成功的话,那么就需要通过支付服务申请对订单进行付款。如果信用额度检查和支付请求都成功的话,订单将会转移至Accepted状态,这样就可以对该订单开始进行交付了(这一步骤不在我们这里所讨论的过程之中)。
但是,如果信用额度检查失败的话,订单会立即转移至Rejected状态。如果这个步骤成功了,但是后续的支付请求失败了,在将订单转移至Rejected状态之前,需要将在前面步骤中分配的信用额度释放掉。
可选的实现方案
在实现分布式 Saga 的时候,有两种通用的方式,即协同式(choreography)和编排式(orchestration)。在协同式 Saga 中,每个参与其中的服务都会在它执行完本地事务之后发送一条消息给下一个服务。而在编排式 Saga 中,会有一个协调服务,它会逐个调用参与其中的每个服务。
这两种方式都有其优点和缺点(请参见 Chris Richardson 的博客文章以及 Yves do Régo 的文章以了解更详细的讨论)。就我个人而言,我更加喜欢编排式,因为它定义了一个中心点(编排器,或者称为“Saga 执行协调器”,简称 SEC),通过它我们能够查询得到特定 Saga 的当前状态。它能够避免各个参与者之间点到点的通信(编排者除外),而且还允许在流程中添加额外的中间步骤,这个过程中并不需要调整每个参与者。
在深入实现这个 Saga 流程之前,我们有必要花点时间讨论一下 Saga 所提供的事务语义。我们首先看一下 Saga 如何满足事务的四个经典 ACID 属性,这是 Theo Härder 和 Andreas Reuter(基于 Jim Gray 早前的工作成果)在他们的基础论文Principles of Transaction-Oriented Database Recovery中所定义的:
原子性(Atomicity)✅:该模式能够确保所有的服务要么应用本地事务,要么在出现故障的时候,所有已执行的本地事务都能得到补偿,所以不会产生任何有效的数据变化。
一致性(Consistency)✅:在成功执行组成 Saga 的所有事务之后,所有的本地约束都能确保得到满足,从而使整个系统从一个一致状态转换到另外一个一致的状态。
隔离性(Isolation)❌:尽管 Saga 有最终失败的可能性,这会导致所有之前已经执行的事务被补偿,但是鉴于在 Saga 的运行过程中,本地事务已经进行了提交,所以它们的变更已经对其他并发事务可见了,换句话说,从整个 Saga 的角度来看,隔离级别可以类比成”读取未提交的数据(read uncommitted)“。
持久性(Durability)✅:一旦 Saga 的本地事务得到提交,它们的变更就会持久化,并且会持久性保存,比如能够经历服务的故障或重启。
从服务消费者角度来看,例如某个用户通过订单服务提交了一个购买订单,系统最终是一致的,也就是说,根据不同的参与其中的服务的逻辑,要耗费一定的时间购买订单才能处于正确的状态。
至于参与其中的服务之间的通信,它可以是同步进行的,如通过 HTTP 或gRPC,也可以异步进行,比如通过消息代理或分布式日志,如Apache Kafka。只要有可能,我们就应该优先使用异步的方式进行服务间的通信,因为它将发送服务与消费服务的可用性进行了解绑。正如我们在下一节所看到的,借助变更数据捕获,即便是 Kafka 本身的可用性都不再是什么问题。
回顾发件箱模式
那么,发件箱模式和变更数据捕获(由Debezium提供)是如何将这一切组织在一起的呢?如前文所述,Saga 协调器最好通过请求和答复消息通道与相关服务进行异步的通信。Apache Kafka 是实现这种通道的一个非常流行的可选方案。但是,编排器(以及每个参与其中的服务)还需要将事务应用到其特定的数据库中,从而执行整个 Saga 流中属于它们的那一部分。
虽然简单地执行某个数据库事务,并且稍后发送一条对应的消息到 Kafka 是一种非常诱人的做法,但是这并不是一个好主意。这两个动作横跨数据库和 Kafka,因此并不会在同一个事务中完成。我们迟早会遇到不一致状态的问题,比如数据库事务已经提交了,但是写入到 Kafka 的过程失败了。但是,好朋友是不会让自己的朋友进行双重写入的,发件箱模式提供了一个非常优雅的方式来解决这个问题:
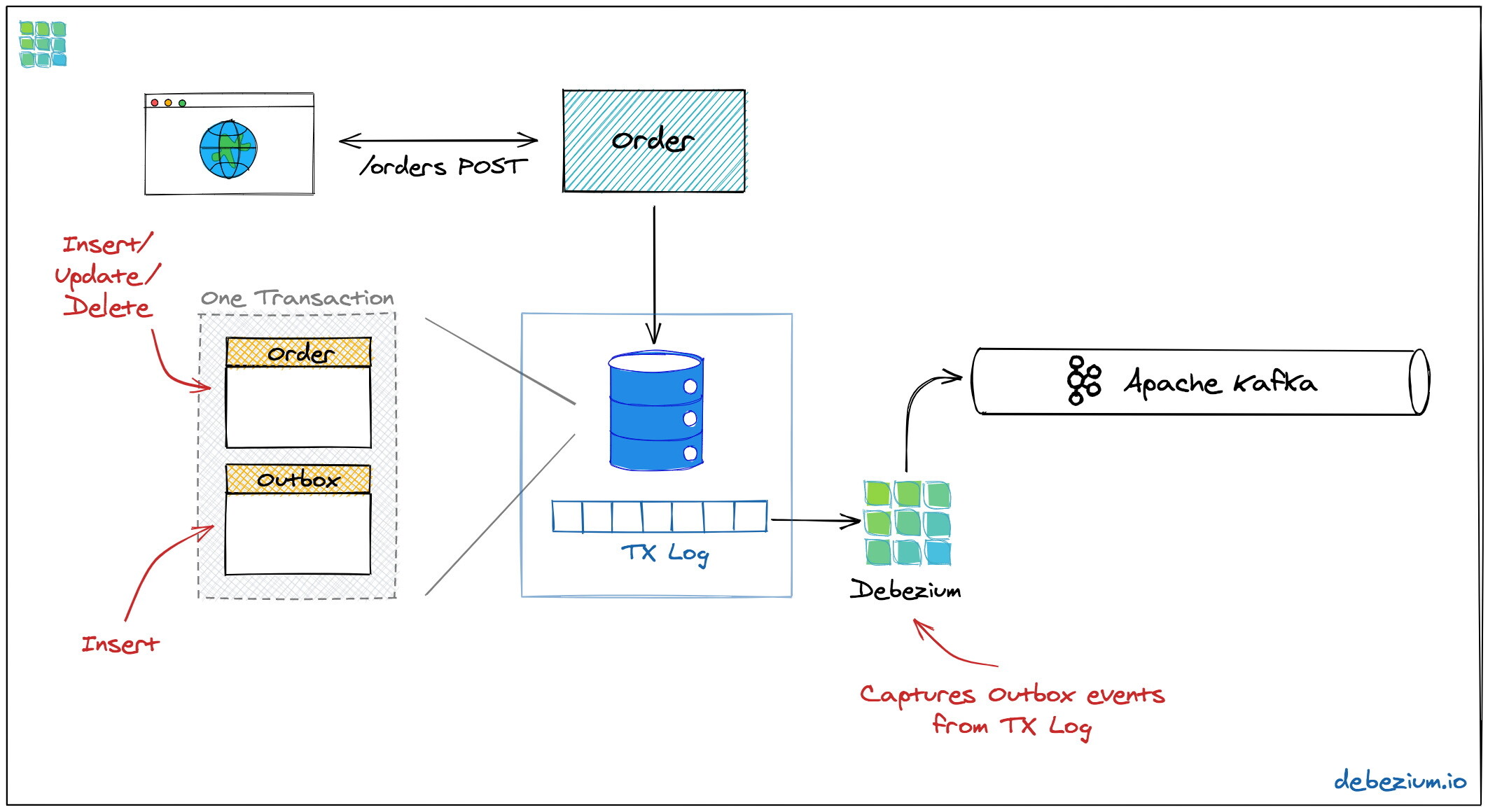
图 2:安全地更新数据库并通过发件箱模式发送消息到 Kafka
我们不会在更新数据之后直接发送消息,而是让服务基于同一个事务执行正常的更新并将消息插入到数据库中一个特定的发件箱表中。因为这个操作是在同一个数据库事务中完成的,我们会有两种结果,要么服务模型的变更会得到持久化并且消息能够安全地保存到发件箱表中,要么这两个都不会得到执行。事务写入到数据库的事务日志之后,Debezium 数据变更捕获进程就会从这里得到发件箱的消息,并将其发送至 Apache Kafka。
这是通过使用“至少执行一次(at-least-once)”的语义实现的:在特定的环境下,相同的发件箱消息可能会多次发送到 Kafka 中。为了让消费者探测到并忽略重复的消息,每条消息应该有一个唯一的 id。例如,这可以是一个 UUID,也可以是一个单调递增的序列,这是与每个消息生产者密切相关的,这个 id 应该通过 Kafka 消息的头信息进行传播。
通过发件箱模式实现 Saga
工具箱中的发件箱模式准备就绪之后,接下来的事情就更清楚了。订单服务将作为 Saga 协调者,在接收到下单的请求之后(通常会通过 REST API 实现),它会通过更新本地状态(包括持久化订单模型和 Saga 执行日志)来触发整个流程,并依次发送消息给其他两个参与其中服务。
这两个服务对通过 Kafka 接收到的消息做出反应,执行本地事务来更新它们的数据状态并且通过它们自己的发件箱表向协调者发送一个答复消息。整个解决方案看起来如下所示:
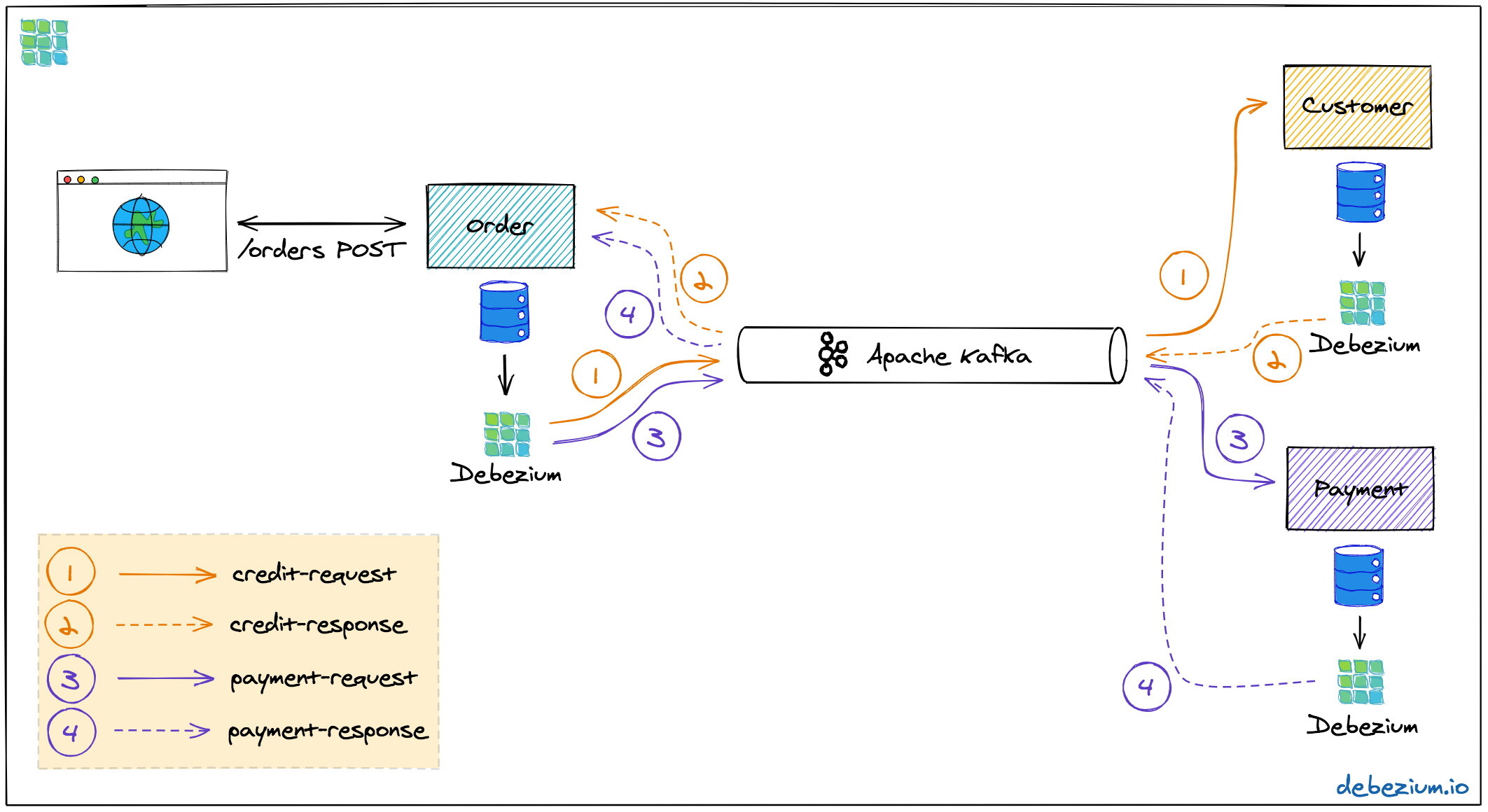
图 3:使用发件箱模式的 Saga 编排
在 Debezium 的 GitHub样例仓库中,你可以看到这个架构的完整概念验证(proof-of-concept,PoC)实现。该架构的主要组成部分如下所示:
三个服务,分别是订单(用来管理购买订单并作为 Saga 协调者)、消费者(用来管理消费者的信用限制)和支付(用来处理信用卡支付),每个服务都有自己的数据库(Postgres)。
Apache Kafka 作为消息传输的骨架
Debezium 运行在 Kafka Connect 之上,它会订阅这三个不同数据库的变更,并通过 Debezium 的发件箱事件路由(outbox event routing)组件将它们发送至对应的 Kafka 主题。
这三个服务是使用Quarkus实现的,这是一个构建云原生微服务的技术栈,构建出来的应用可以运行在 JVM 上,也可以编译成原生二进制(通过 GraalVM 实现)。当然,这个模式也可以通过其他的技术栈或语言来实现,只要它们提供消费来自 Kafka 消息并且写入数据库的能力即可。另外,组合不同的实现技术也是可行的。
这里涉及到四个 Kafka 主题:信用审批消息的请求和响应主题以及支付消息的请求和响应主题。在 Saga 执行成功的情况下,恰好会有四条消息会被进行交换。如果其中的某一个步骤失败的话,就需要一个补偿事务了,在每个步骤都会有额外的请求和响应消息对来进行补偿。
确保顺序
为了达到扩展的目的,Kafka 主题可以组织到多个分区中。
只有在一个分区内部,才能确保消费者接收到消息的顺序与生产者发送消息的顺序完全一致。默认情况下,具有相同 key 的所有消息都会发送到相同的分区中,所以 Saga 的唯一 id 是 Kafka 消息 key 的自然选择。通过这种方式,同一个 Saga 实例的消息就能保证以正确的顺序进行处理。
如果我们有多个 Saga 实例,它们用于 Saga 消息交换的主题出现在了不同的分区中,那么它们可以并行处理。
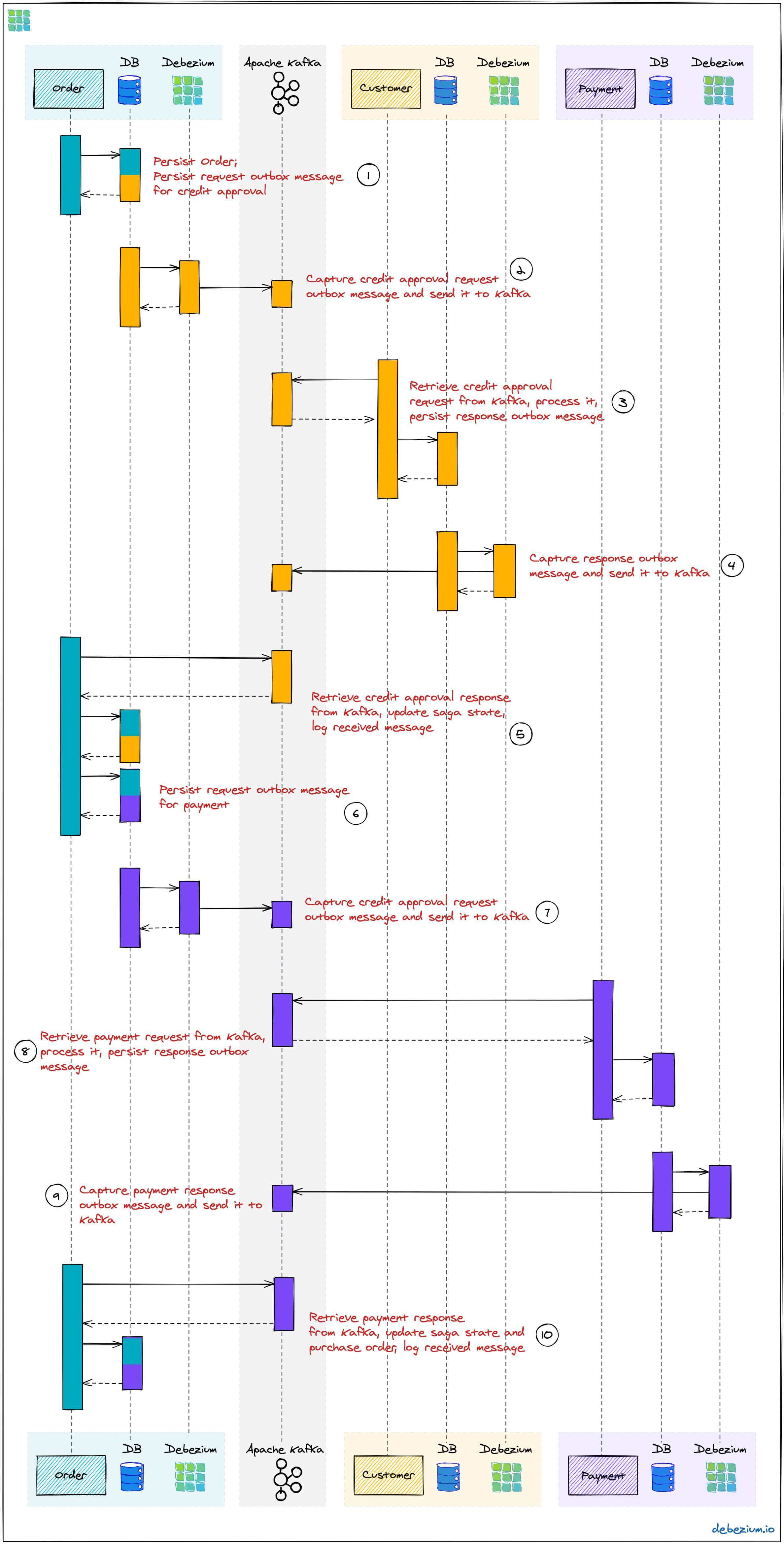
图 4:成功 Saga 流的执行序列
每个服务都通过自己数据库中的发件箱表发送消息。在这里,这些消息由 Debezium 捕获并发送至 Kafka,最终由接收消息的服务进行消费。在发送和消息的时候,订单服务作为编排者也会将 Saga 的进度持久化到本地状态表中(后文详解)。另外,所有的参与者会将它们所消费的消息的 id 记录到一个 journal 表中,从而标识后续可能会出现的重复。
那么,我们现在考虑一下,如果流中的某个步骤失败了会怎么样?假设支付步骤因为消费者的信用卡已经过期而失败了。在这种情况下,在前面消费者服务中已经预留的信用卡额度需要再次进行释放。为了实现这一点,订单服务会向消费者服务发送一个补偿请求。将这个过程放大一点(就像前面介绍 Debezium 和 Kafka 详情那样),那么消息交换将会如下所示:
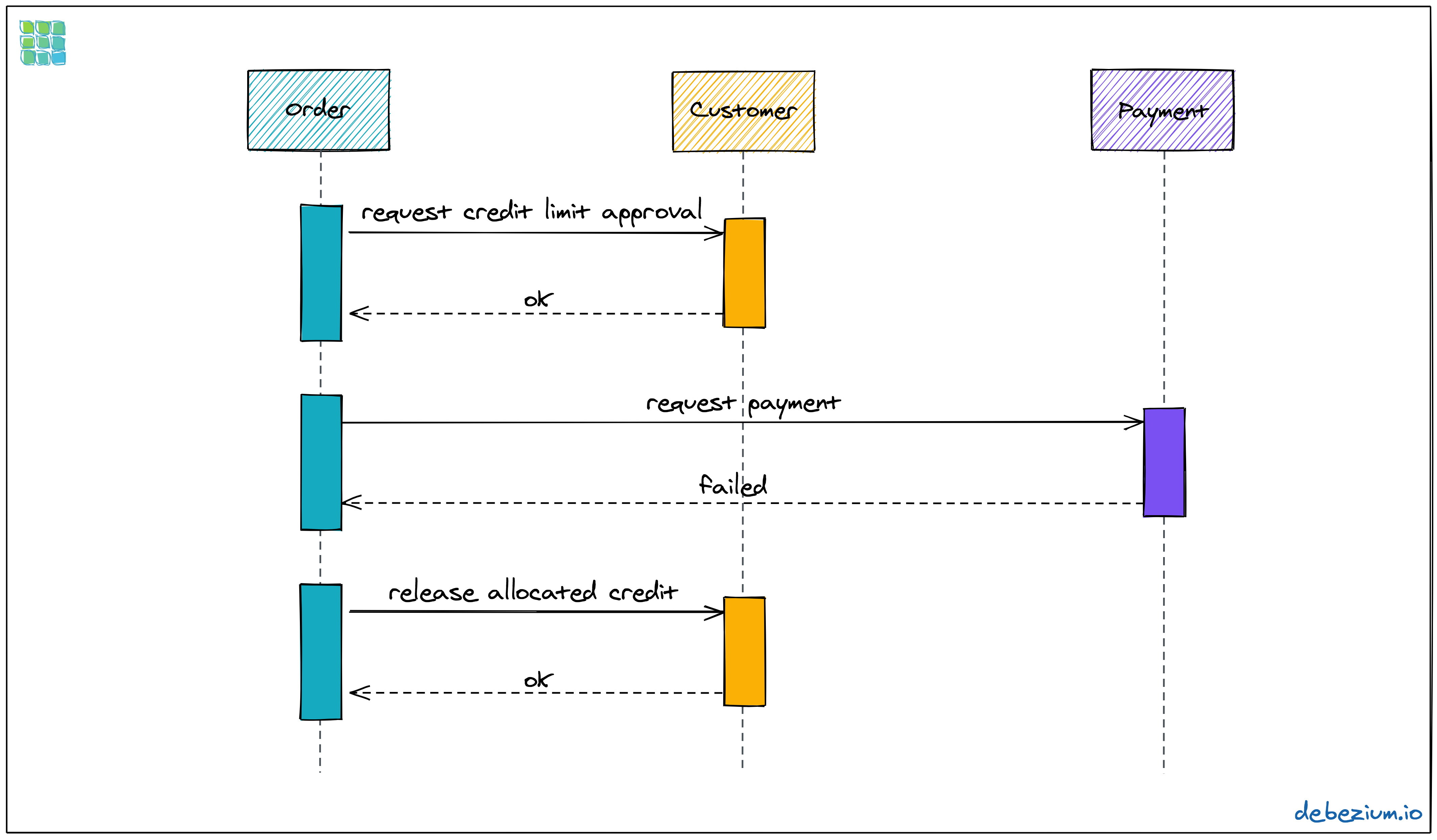
图 5:带有补偿的 Saga 流的执行序列
讨论完服务之间的消息流之后,接下来我们深入订单服务的一些实现细节。概念验证实现以简单状态机的形式提供了一个通用的 Saga 编排器以及针对订单场景的 Saga 实现,在后文中我们会对其进行深入讨论。订单服务实现的”框架“部分在sagastate表中跟踪了 Saga 执行的当前状态,其模式如下所示:

图 6:Saga 状态表的模式
这个表满足了 Saga 日志的要求。它的每个列如下所示:
id:给定 Saga 实例的唯一标识符,代表创建一个特定的购买订单。currentStep:Saga 当前所处的步骤,如“credit-approval”或“payment”。payload:与特定 Saga 实例相关联的任意的数据结构,例如,在 Saga 生命周期中,包含相对应的购买订单的 id 和其他有用的信息;尽管在样例实现中我们使用 JSON 作为载荷的格式,但是也可以考虑使用其他的格式,比如Apache Avro,并将载荷的模式存放到模式注册表中。status:Saga 当前的状态,可以是STARTED、SUCCEEDED、ABORTING或ABORTED其中之一。stepState:字符串化之后的 JSON 结构,描述了每个步骤的状态,比如"{"credit-approval":"SUCCEEDED","payment":"STARTED"}"type:Saga 命名化的类型,比如“order-placement”,用来区分系统中所支持的不同类型的 Saga。version:一个基于乐观锁的版本,用来探测和拒绝对一个 Saga 实例的并发更新(在这种情况下,需要重试那些触发失败更新的消息,从 Saga 日志中重新加载当前的状态)
当订单服务发送请求到消费者和支付服务并通过 Kafka 接收到它们的答复时,Saga 状态就会更新到这个表中。通过搭建 Debezium connector 来跟踪sagastate表,我们可以很好地检查 Kafka 中 Saga 的执行进度。
如下展示了一个支付失败的购买订单的状态转换,首先订单传入,“credit-approval”步骤启动:
此时,一条“credit-approval”请求消息也会持久化到发件箱表中。消息发送到 Kafka 之后,消费者服务将会处理它并发送一条答复消息。订单服务会更新 Saga 状态并开始支付步骤:
消息会再次通过发件箱表进行发送,不过现在是“payment”请求。如果这个步骤失败了,支付系统会发送一个答复消息作为响应,并表明发生了什么情况。这也就意味着“credit-approval”步骤需要通过消费者系统进行补偿:
这个步骤完成后,Saga 会进入最后的状态,也就是ABORTED:
你可以按照样例中 README 文件中的说明自行尝试一下,在这里你可以找到创建订单成功和失败的请求。这里还包含如何检查 Kafka 主题中交换消息的指南,这些消息都来自不同服务的发件箱表。
现在,我们看一下这个用例的部分具体实现。Saga 流是在订单服务中启动的,其 REST 端点实现如下所示:
持久化传入的购买订单
为传入的订单开启下单的 Saga 流
SagaMananger.begin()会在sagastate表中创建一条新的记录,通过OrderPlacementSaga实现获取第一个发件箱事件并将其持久化到发件箱表中。OrderPlacementSaga类要实现 Saga 流中与该用例相关的所有具体的组成部分,包括:
用来执行 Saga 流中某个组成部分的发件箱事件
用来补偿 Saga 流中某个组成部分的发件箱事件
事件处理器,用来处理来自其他 Saga 参与者的答复消息
OrderPlacementSaga实现太长了,并不适合在这里全部展示(你可以在GitHub上查阅它的完整代码),但是这里我们展示了一些核心的组成部分:
1️⃣ Saga 步骤的 id,便于执行
2️⃣ 返回给定的步骤要发布的发件箱消息
3️⃣ 返回补偿步骤要发布的发件箱消息
4️⃣ 针对“payment”答复消息的事件处理器,它会更新购买订单的状态以及 Saga 的状态(通过 onStepEvent()回调实现),根据不同的状态,它可能会完成 Saga,也可能会通过应用所有的补偿消息启动它的回滚过程。
5️⃣ 针对“credit approval”答复消息的事件处理器
6️⃣ 基于当前的 Saga 状态,更新购买订单的状态
消费者服务和支付服务并没有什么新鲜的内容,所以简洁起见,我们在这里就略过它们了。你可以在这里和这里查阅它们的完整代码。
如果事情出错会怎样
在实现像 Saga 这样的分布式交互模式时,一个关键的组成部分就是了解它们在出现故障时的表现,并确保在不可预见的情况下,也能实现(最终)一致性。
注意,Saga 步骤的负面输出(比如,支付服务因为无效的信用卡而拒绝支付)并不算是这里所说的故障场景,因为我们明确预期参与者可能无法执行整体流程中属于它们的那一部分,从而会导致对应的补偿本地事务会被执行。这意味着,这种通用的参与者执行故障不得引发本地数据库事务的回滚,因为否则的话,就不会有答复消息通过发件箱发送给编排者了。
记住了这一点,我们就来讨论一些可能的故障场景:
Kafka 消息的事件处理器抛出了异常
本地数据库事务被回滚了,而消息消费者没有向 Kafka 代理确认(acknowledge)它能够处理消息。因为代理没有接收到消息已经得到处理的确认信息,所以在一定的时间之后,它就会重复性地重发该消息,直到得到确认为止。我们应该有监控措施来探测这种场景,因为在消息得到处理之前,Saga 流不会继续进行处理。
Debezium connector 在发送发件箱消息给 Kafka 之后就崩溃了,此时还没有在源数据库事务日志中提交偏移(offset)。
重启 connector 之后,它将会继续从上次提交日志偏移的地方在发件箱表中读取消息,这有可能造成有些发件箱事件会发送两次,这也就是为何要求所有参与者都是幂等的,就像前面的例子中通过使用唯一的消息 id 来实现的那样,消费者还能通过 journal 表跟踪成功处理过的消息。
Kafka 没有运行或者无法访问,例如由于网络分割所致。
Debezium connector 能够在 Kafka 再次可用时恢复它们的工作,但是在此之前,Saga 流自然无法进行处理。
消息已经得到了处理,但是向 Kafka 确认的时候失败了。
这条消息会再次传递给消费者服务,而在消费者服务的 journal 表中会找到该消息的 id,因此会作为重复消息被忽略掉。
并行处理多个 Saga 步骤时,对 Saga 状态表的并发更新
虽然我们已经讨论了编排者如何通过依次触发参与服务形成顺序化的流程,但是我们也应该设想一下并行处理多个步骤的 Saga 实现。在这种情况下,并发到达的答复信息可能会竞争更新 Saga 的状态表。这种场景会通过该表上的乐观锁探测到,会导致事件处理器试图去提交更新给一条已经过时的 Saga 状态版本,从而出现失败、回滚和重试。
我们可以讨论更多的情况,但是总体设计的语义是最终一致的系统,能够保证至少执行一次。
额外的福利:分布式跟踪
在设计分布式系统之间的事件流时,运维上的洞察力对于确保一切正确和高效运行至关重要。分布式跟踪提供了这样的洞察力:它会收集每个系统的跟踪信息,这些系统会贡献这样的交互信息,并且允许对调用流进行检查,例如以 Web UI 的形式,这使得它成为了故障分析和调试的宝贵工具。
Debezium 的发件箱通过与OpenTracing(对OpenTelemetry 的支持已经在路线图上了)规范的紧密结合解决了这个问题。通过Jaeger这样的工具,只需要一些配置,就能收集订单、消费者和支付服务的跟踪信息,并将它们展现为端到端的跟踪结果。
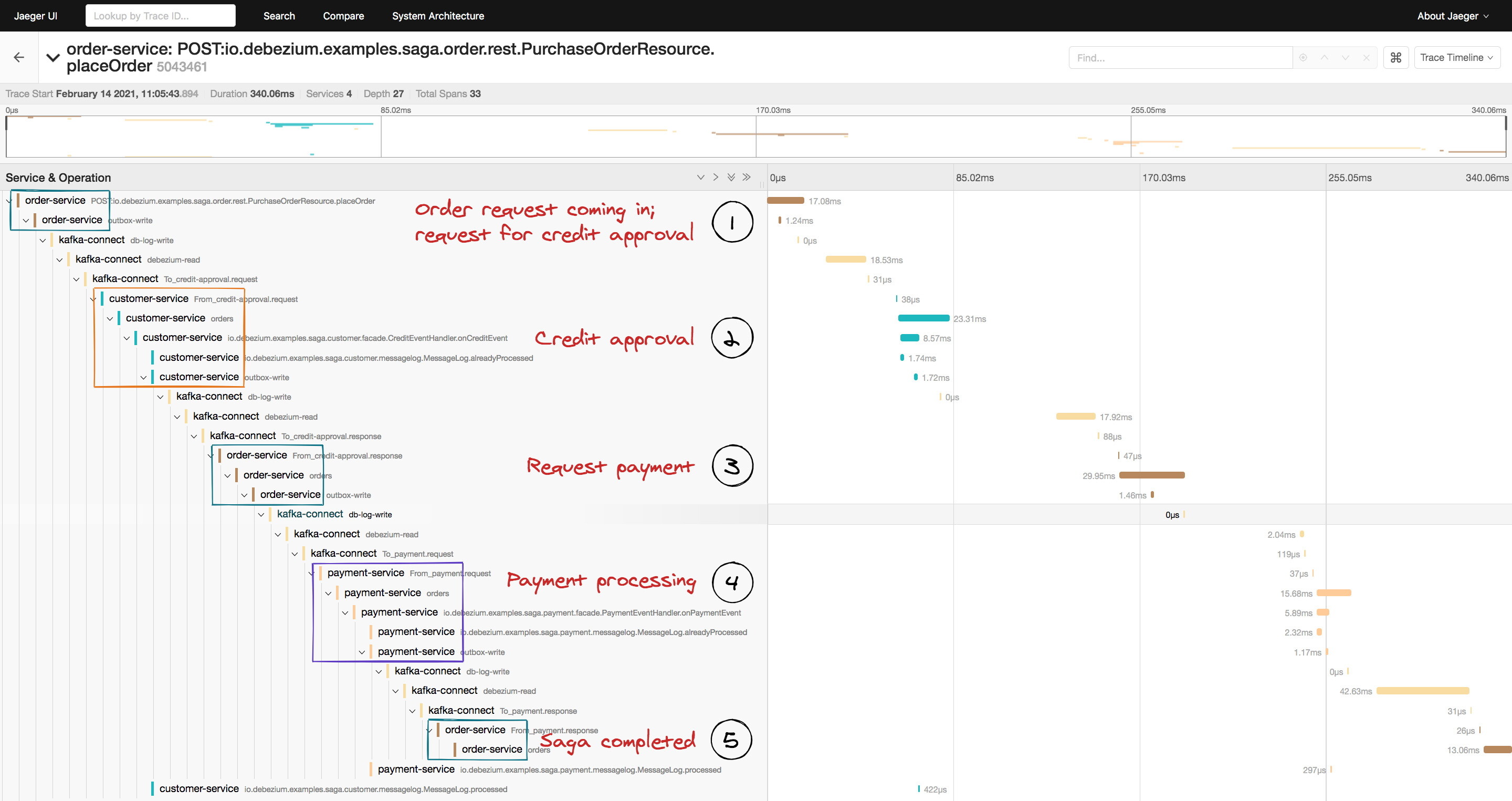
图 7:Saga 流上的 Jaeger UI
Jaeger 中的可视化很好地为我们展示了 Saga 流是如何通过订单服务中的传入 REST 请求(1)触发的,发件箱消息发送给消费者服务(2)并传送回订单服务(3),随后另外一条消息发送给支付服务(4)并最终再次发送回订单服务(5)。
借助跟踪功能,我们能够很容易地识别未完成的流(例如,因为某个参与服务的事件处理器未能成功处理某条消息)和性能瓶颈(例如,某个事件处理器需要一个不合理的时间才能完成 Saga 流中属于自己的那一部分)。
总结与展望
Saga 模式为实现长时间运行的”业务事务“提供了一个强大而灵活的解决方案,这需要多个独立的服务就应用还是放弃一组数据变更达成一致。
借助 CDC、Debezium 和 Apache Kafka 实现的发送者模式,Saga 编排者能够与所有参与服务的可用性解耦。单个参与服务的临时中断不会影响整体的 Saga 流:组件恢复之后,Saga 将会从之前中断的地方继续进行。
当然,我们应该期望服务之间是互相分割的,尽可能减少与远程服务之间互动的需求。例如,把信用额度的逻辑转移到订单服务本身之中,避免与消费者服务的协同,这可能也是一个可选方案。但是,根据业务的需要,这种跨多个服务的交互可能是难以避免的,特别是涉及到集成遗留系统,或者系统不在我们的控制之中。
在实现像 Saga 这样的复杂模式时,准确理解它们的约束和语义是至关重要的。在我们建议的解决方案背景中,有两件事需要注意,那就是固有的最终一致性以及总体业务事务的有限隔离级别。例如,因为一个订单给消费者分配了部分信用额度可能会导致同时提交的另外一个订单被拒绝,而第一个订单最终却可能并没有真正完成。
本文讨论的样例项目基于 CDC 和发件箱模式提供了一个概念验证级别的 Saga 编排实现,它被组织成了两部分:
一个通用的“框架”组件,它以简单状态机的形式提供了 Saga 编排的逻辑,同时提供了 Saga 执行日志。
我们所讨论的下订单的具体实现(上文所示的
OrderPlacementSaga类以及相关的 REST 端点等)。
更进一步的话,我们可能会将前一部分提取成一个可重用的组件,比如通过现有的 Debezium Quarkus 扩展实现。如果你对此感兴趣的话,可以通过 Debezium 的邮件列表联系我们。一个可能增加的功能是并发执行多个 Saga 步骤的方法。这是否合理是一个商业决定,但从技术角度来看,支持它并不难。在这种情况下,更新 Saga 状态时的竞争可能会成为一个关键问题,
分散-聚集Saga的优化一文讨论了在这方面可能的解决方案。如果能有一个设施来监控和识别那些在一段时间后还没有完成的 Saga,也是很有意思的。
我们所提议的实现提供了一种可靠执行业务的方式,能够在跨多个服务时实现”全有或全无“的语义。对于有更复杂需求的用例,比如带有条件逻辑的流程,那么就可以了解一下现有的工作流引擎和业务处理自动化工具,比如Kogito。另一项值得关注的技术是针对长时间运行的活动(long-running activities,LRA)的MicroProfile规范,该规范目前正在开发中。MicroProfile 社区也在讨论与Debezium这样的事务性发件箱实现的整合。
非常感谢Hans-Peter Grahsl、Bob Roldan、Mark Little和Thomas Betts在写这篇文章时提供的大量反馈!
查看英文原文:Saga Orchestration for Microservices Using the Outbox Pattern
作者介绍:
Gunnar Morling 是一名软件工程师,热情的开源爱好者。他正在领导Debezium项目,这是一个用于变更数据捕获(CDC)的工具。他是一名 Java Champion,是Bean Validation 2.0(JSR 380)的规范负责人,并创立了多个开源项目,如Layrry、Deptective和MapStruct。在加入 Red Hat 之前,Gunnar 广泛在物流和零售行业从事 Java EE 相关的项目。他的工作地点在德国汉堡。你可以通过推特联系到他:@gunnarmorling。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论