

如何在异构化、割裂化严重的大数据平台上解决数据孤岛的挑战,并支持丰富的 OLAP 分析能力和进阶分析功能,如可计算度量、多对多关系?背后的实现原理和技术难点是什么,以至于用户可以简单地通过 Excel 感受到极其平民化的多维分析体验?本次分享的主要内容包括:
大数据时代下的分析挑战
传统 OLAP 的局限
Kyligence 的解决方案
当中的一些挑战
效果展示
大数据时代下的分析挑战
1. 数据分析需求灵活多变
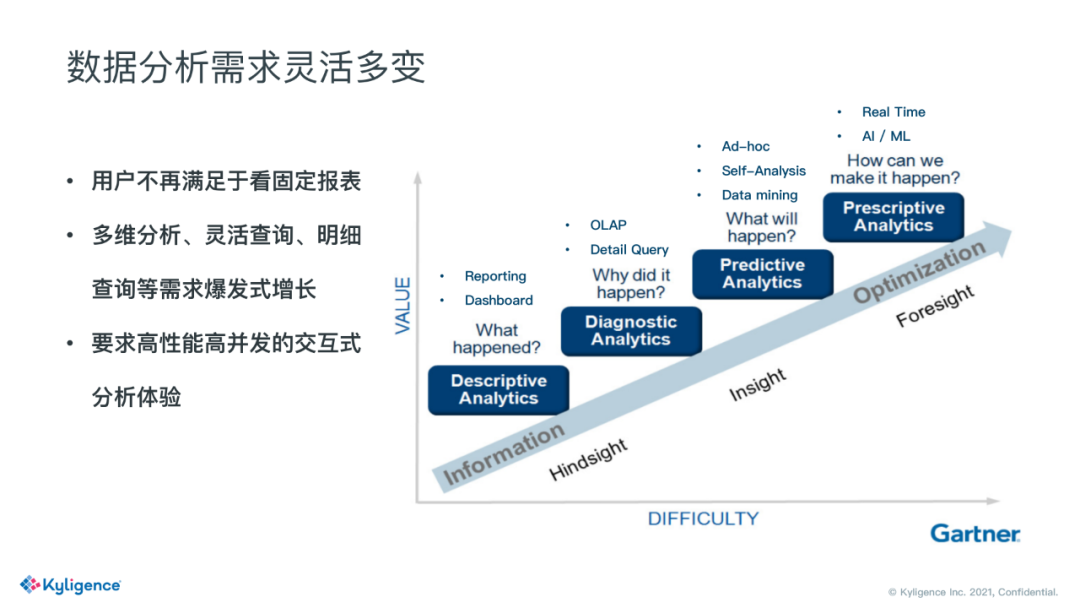
第一个挑战是目前用户分析的需求非常灵活多变。右边这张图是截取自 Gartner 的分析报告。这里描述了数据分析的四个阶段,第一阶段是描述性分析,主要描述发生了什么,一般是固定报表的形式。第二阶段是诊断性分析,来探究数据指标为什么高了还是低了,是哪部分高了,哪部分低了,这时候就需要使用到多维分析以及明细查询。第三个阶段是预测性分析,根据历史数据来预测接下来的走势。第四部分是规范性分析,为了促使指标最优,我们可以做些什么。
我们在实际的客户分析场景中发现,用户不再满足于看固定报表,他还需要分析这些数据,这些指标背后的成因。因此多维分析,灵活查询,明细查询这些需求就在爆发式的增长。同时他们在分析的过程中,希望能够高性能的进行交互式分析,而不是像以前可能执行一条 hive 语句后倒一杯咖啡,然后坐着等结果,这背后对数据分析平台的要求是很高的。
2. 数据孤岛带来割裂的分析体验
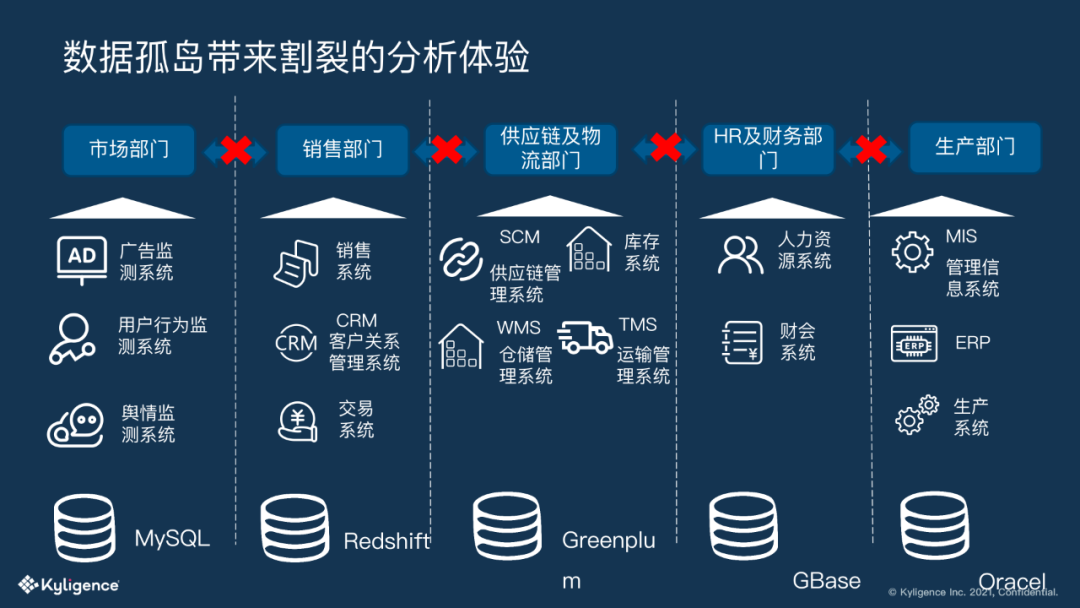
第二个挑战是数据孤岛带来割裂的分析体验。很多企业内部信息系统多各自为政,各系统之间缺乏整合,不同部门使用的数据存储不一样,数据规范也不一样。
各部门拥有各自信息系统的主导权,且局限于部门级别的信息决策,缺乏公司层面的统一的信息决策。
传统 OLAP 的局限
1. 传统 OLAP 的劣势
传统 OLAP 一定程度上能够解决刚才讲的部分问题,但是他们存在着一些局限性。

这些局限性有几个点:一个是数据量及维度数量的限制,传统 OLAP 一般使用的是 MOLAP 模式,在小数据量上,性能优势明显,但是在面对大型数据集时,可能会面临维度爆炸的问题。第二点是扩展的局限性,传统 OLAP 的拓展起来十分麻烦,有些 OLAP 数据库只能 scale up,这种情况就只能增加节点的内存和计算核心数量,但这个成本是极为昂贵的。另外一些 MPP 架构的 OLAP 数据库虽然能够 scale out,但是能够增加的节点数也比较有限,不像 hadoop 或者云上能够拓展到成千上万个节点。另外还有一些缺陷比如费用昂贵、高基维处理能力差,高并发下性能堪忧等等。
2. 理想的 OLAP 平台

讲了这么多传统 OLAP 的缺陷,那我们理想中的 OLAP 平台是什么样子呢?
首先是完善的 OLAP 能力,上钻下卷、高级分析功能,如可计算度量,多对多,时间智能等等。
同时支持 ANSI SQL 和 MDX ,能够与广泛的 BI 工具进行良好对接,尤其是 Excel,目前仍是广大分析师的重要选择。在此之上,如果能在海量数据上进行交互式分析,能够满足上千用户的高并发查询,以及面对数据激增的情况,能够很好的进行横向扩展。
那么如何做到这些呢?
Kyligence 的解决方案
1. Kyligence:分布式 OLAP 大数据分析引擎
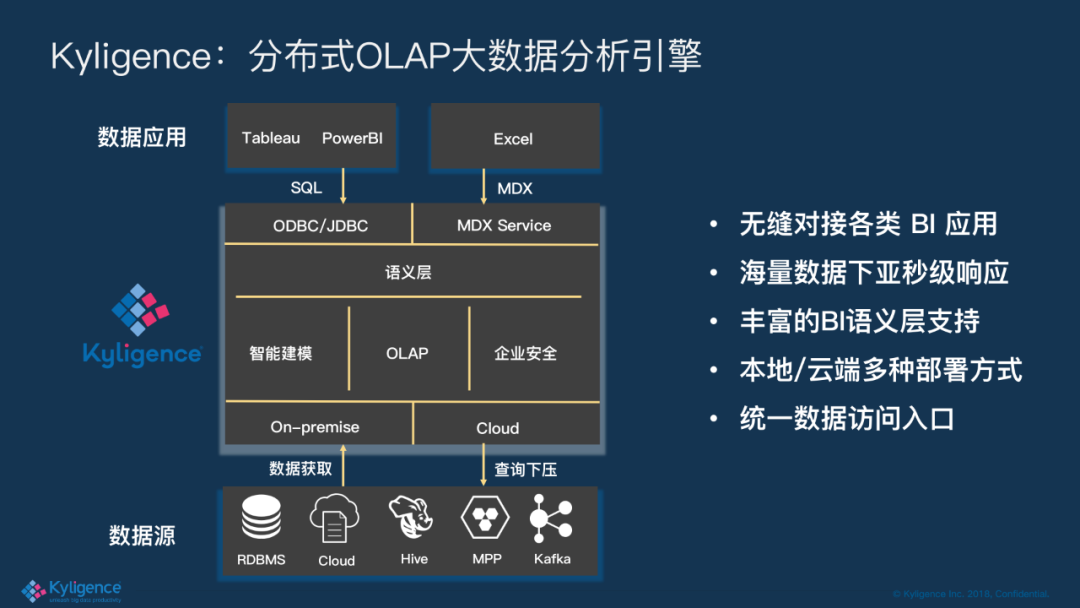
Kyligence 能够对接不同种类的数据源,支持云端及本地部署 hadoop,因此天然就是支持横向扩展的。另外 Kyligence 能够进行智能建模,智能加速查询,向外提供标准的 ODBC/JDBC/MDX 接口,能够对接广泛的 BI,而且最重要的是我们暴露语义是统一的。
让我们看一下 Kyligence 语义层中的一些功能:
① 灵活定义层级、指标
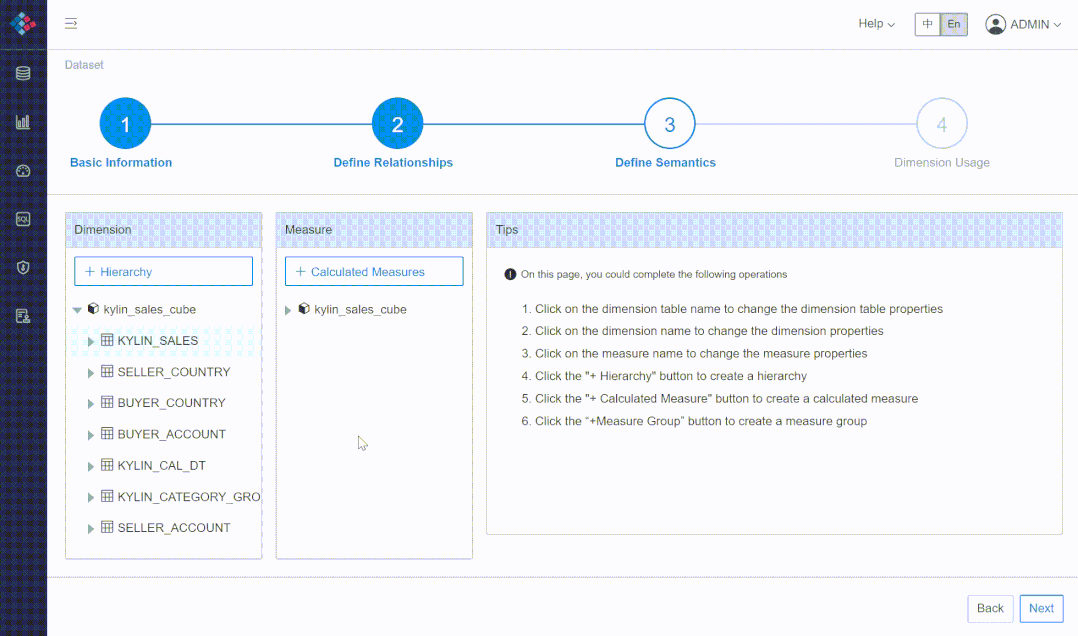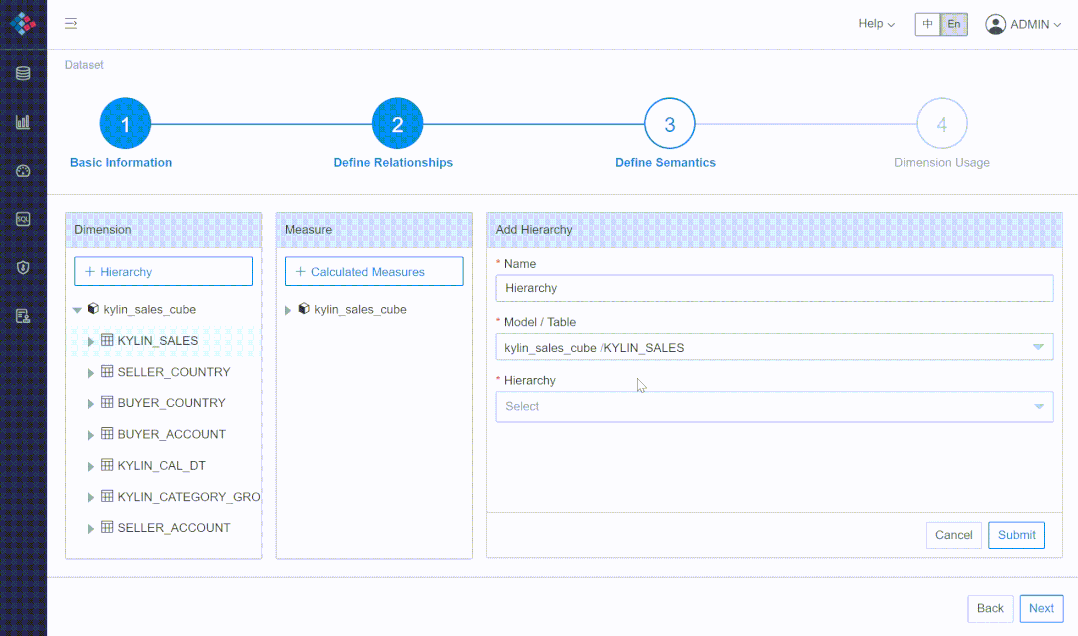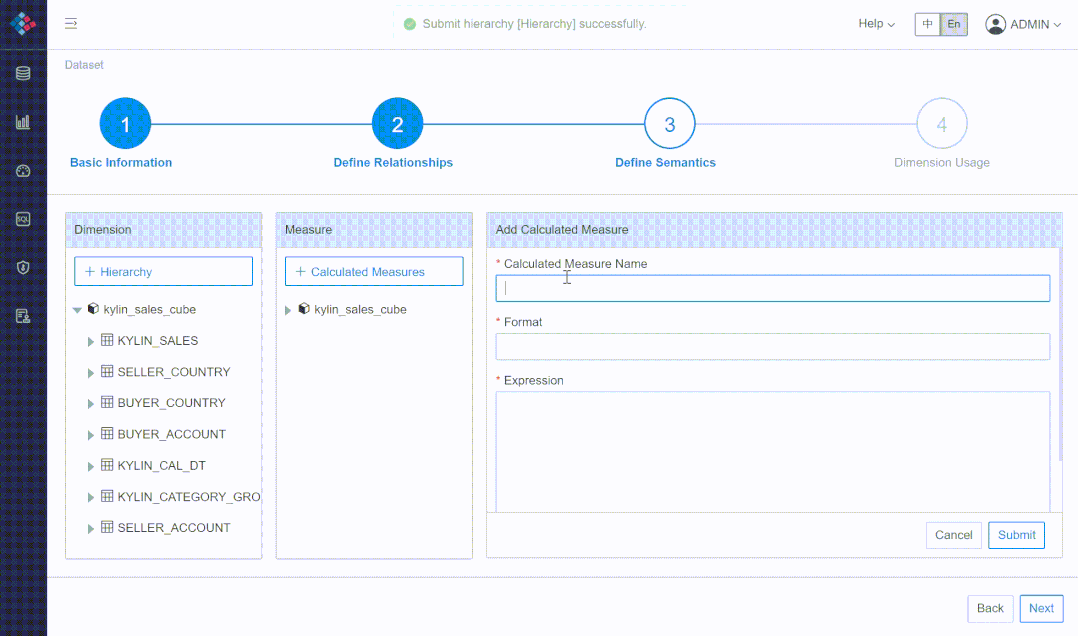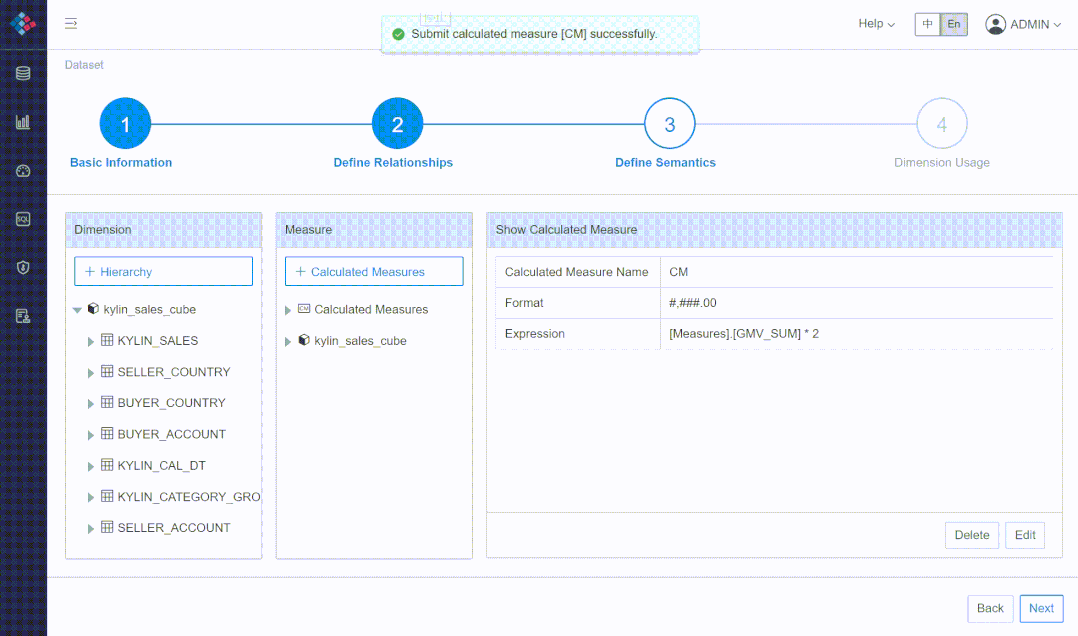
② 多对多、多事实表场景
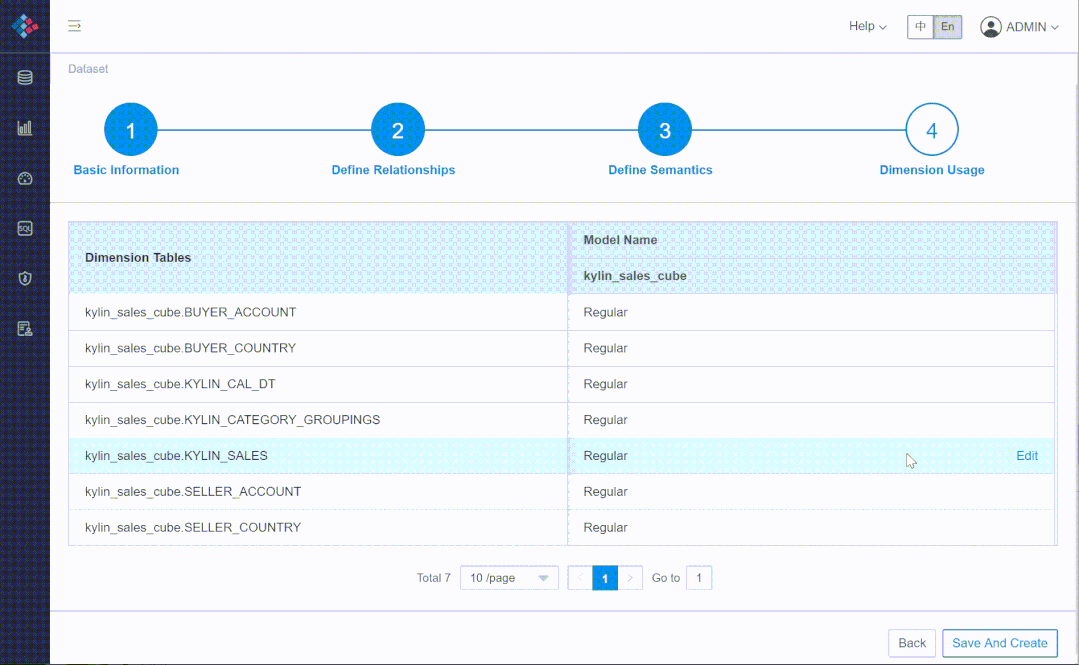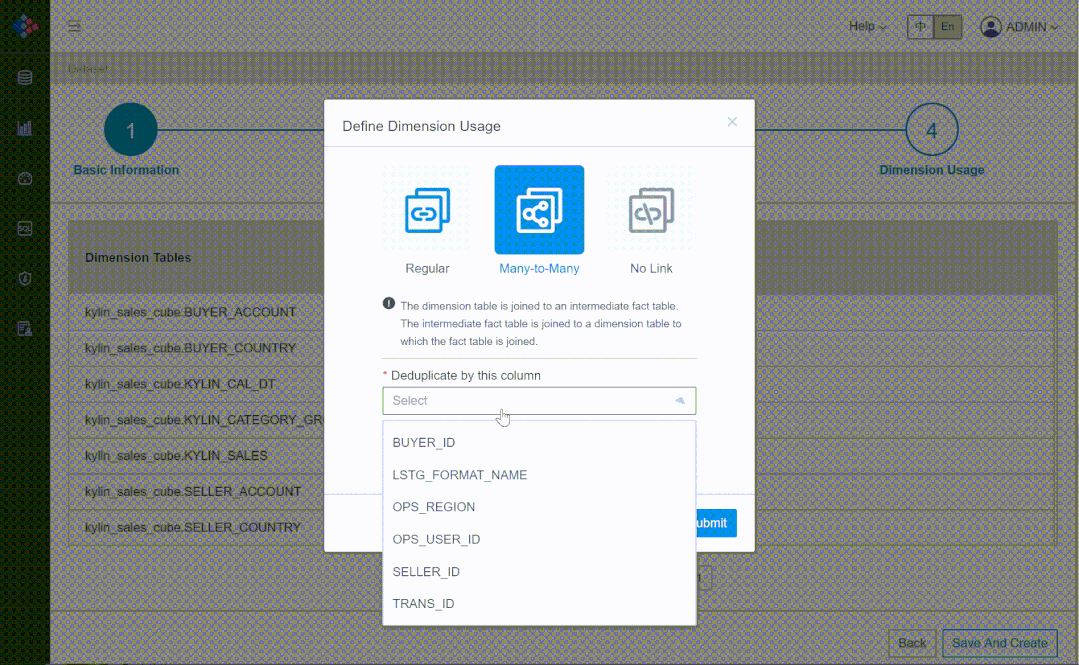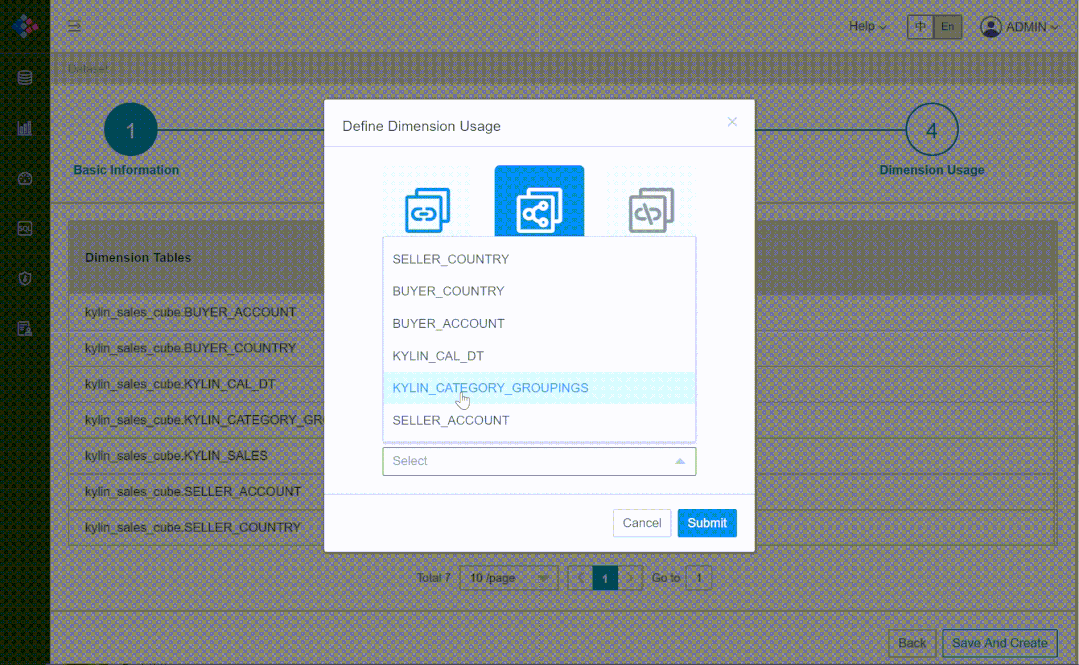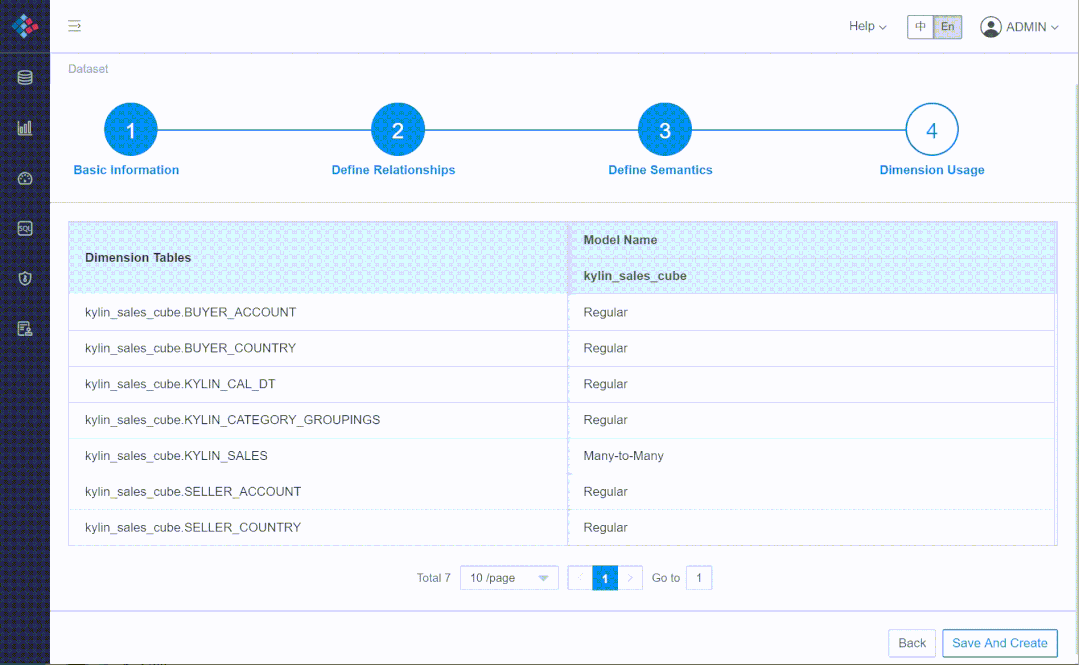
③ 支持标准 MDX 接口
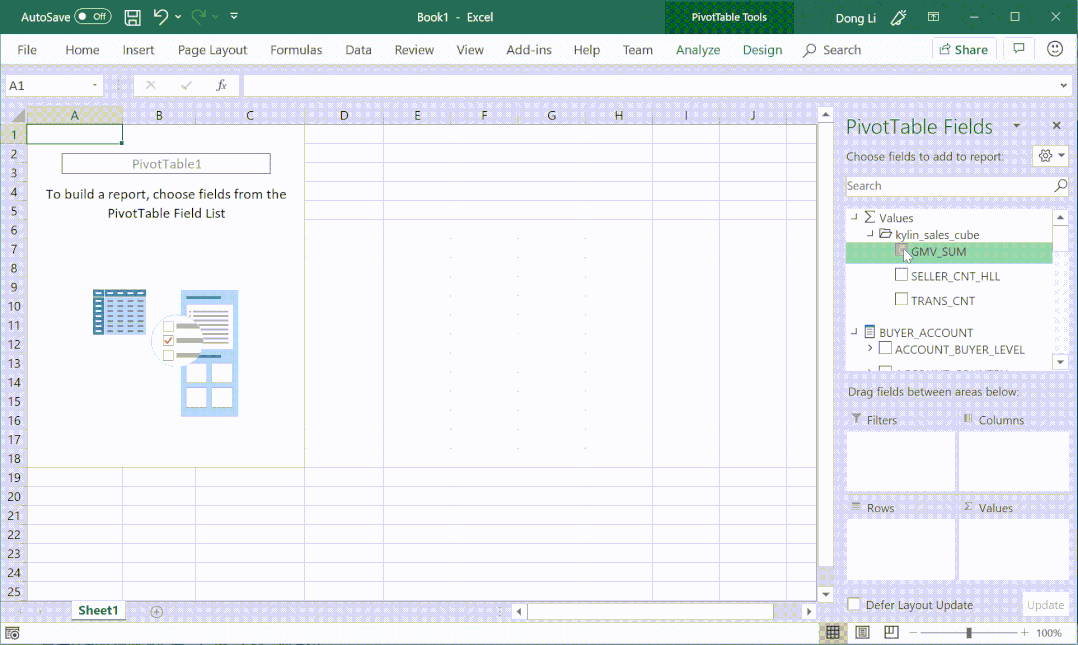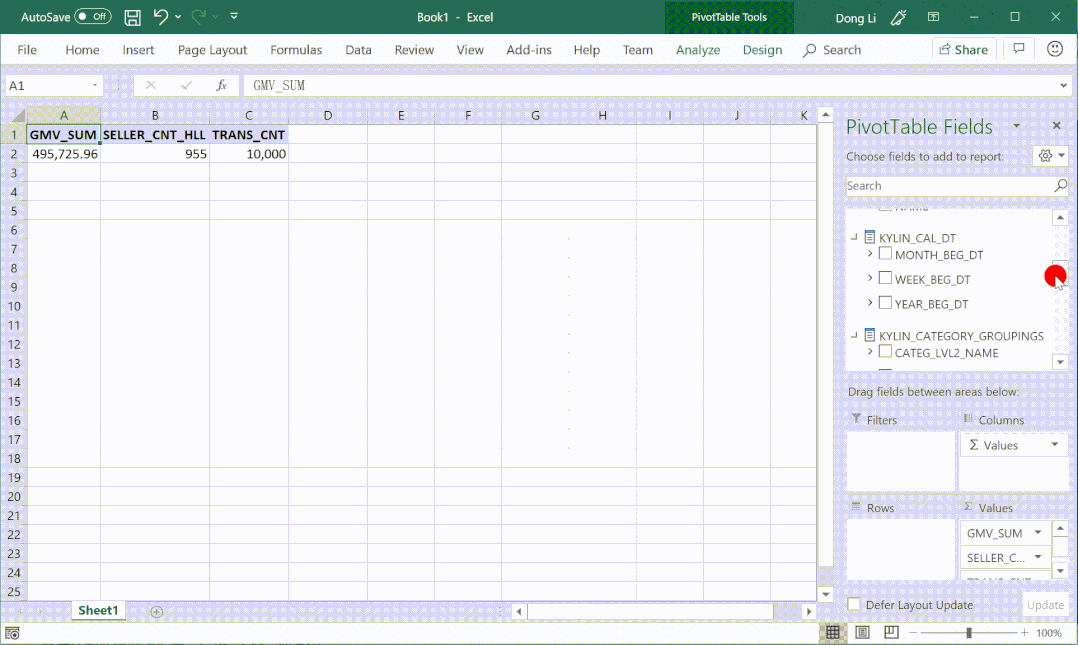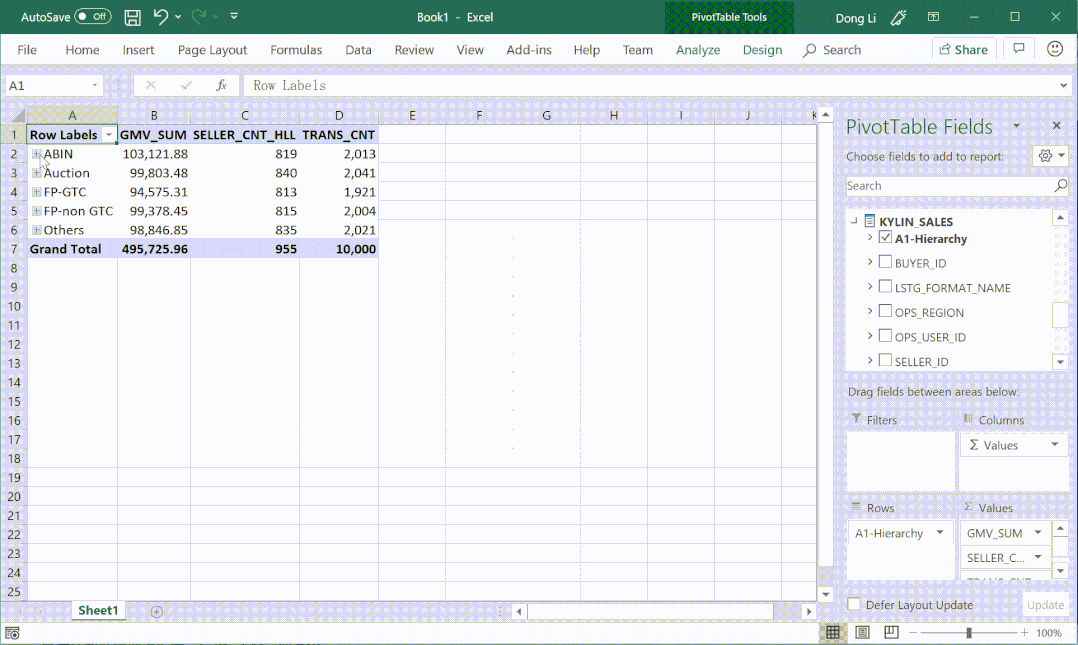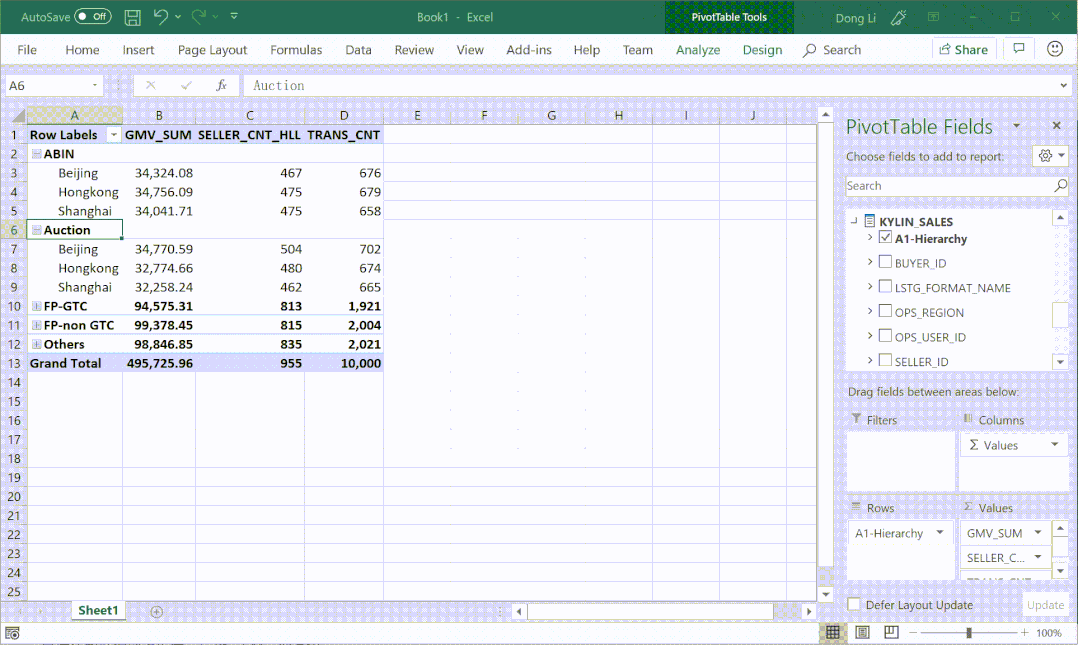
④ 支持时间智能指标
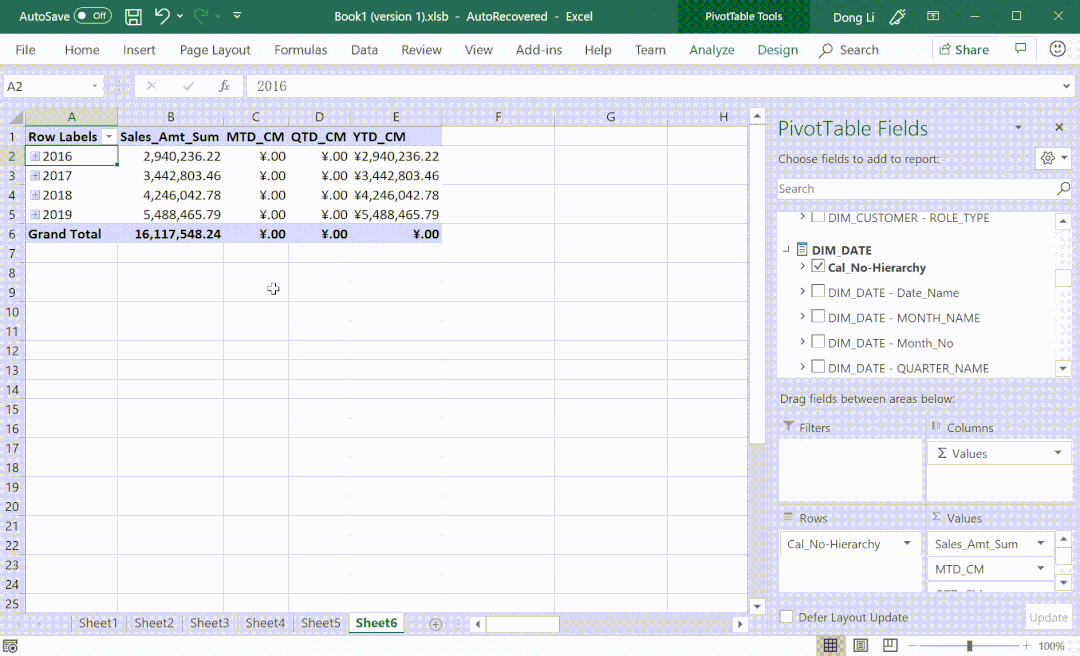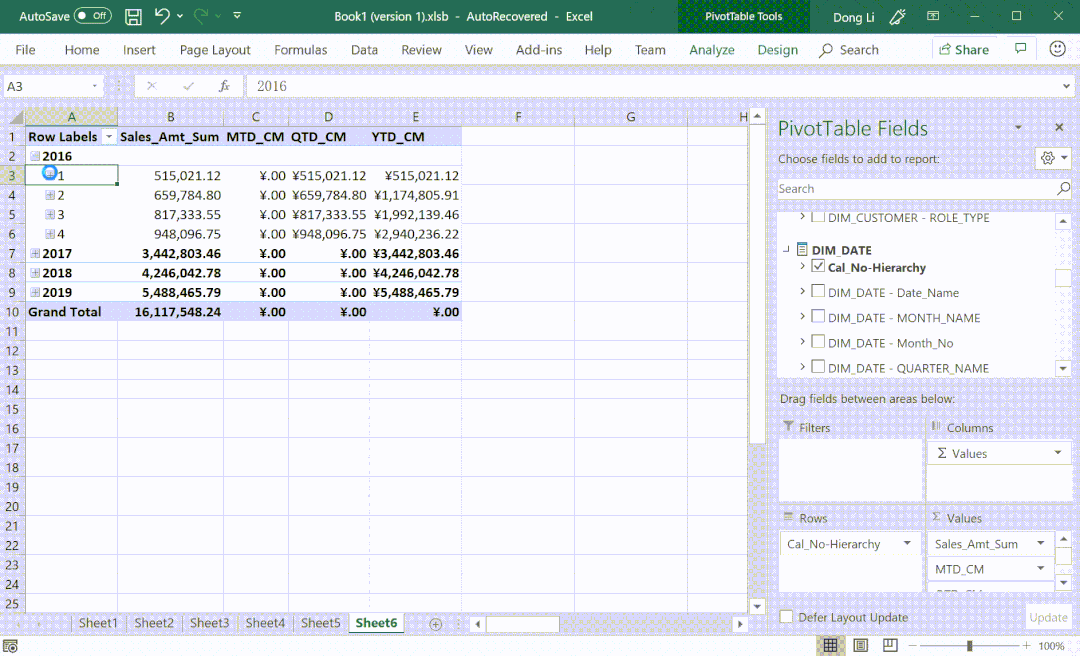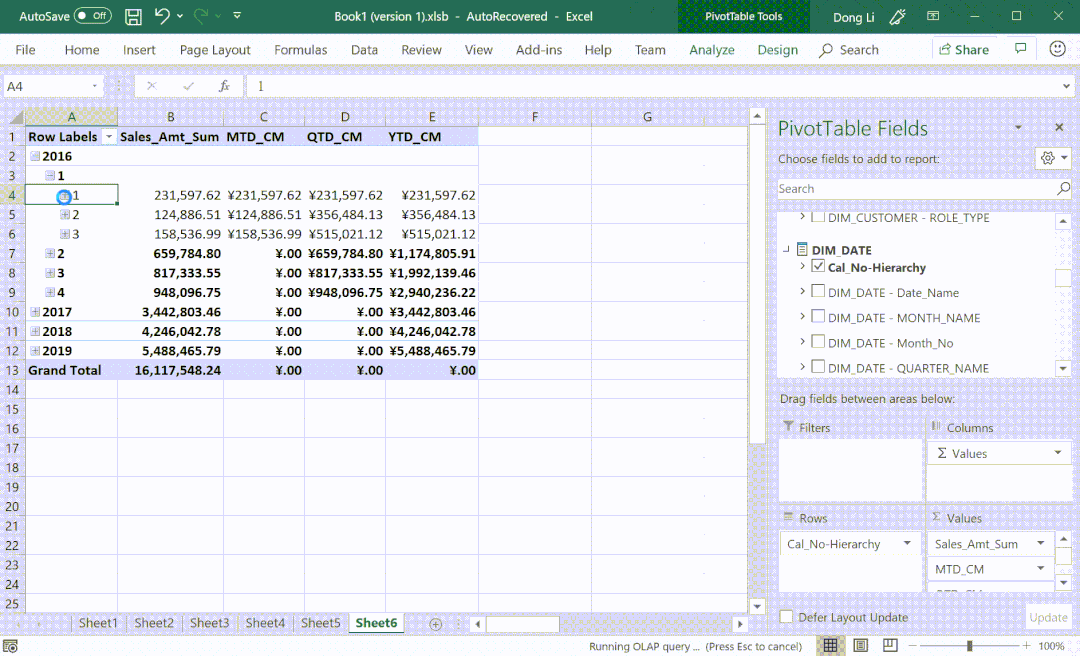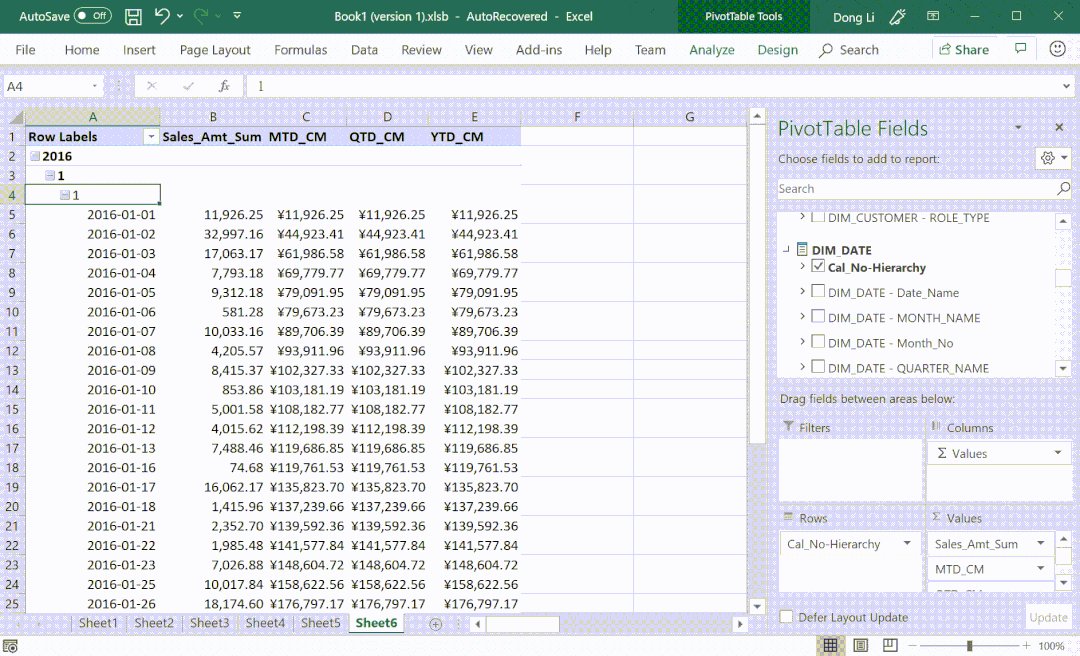
⑤ 支持多语言翻译
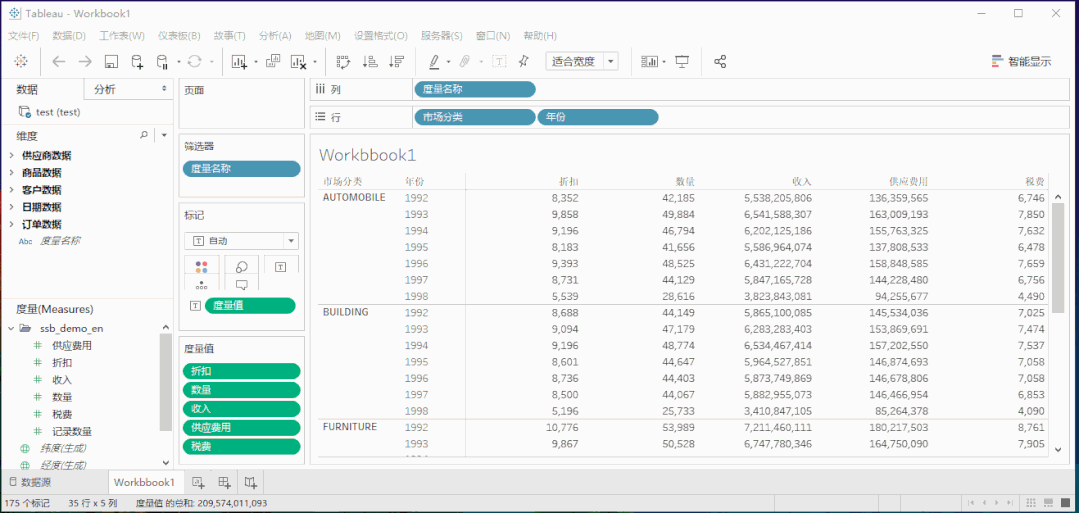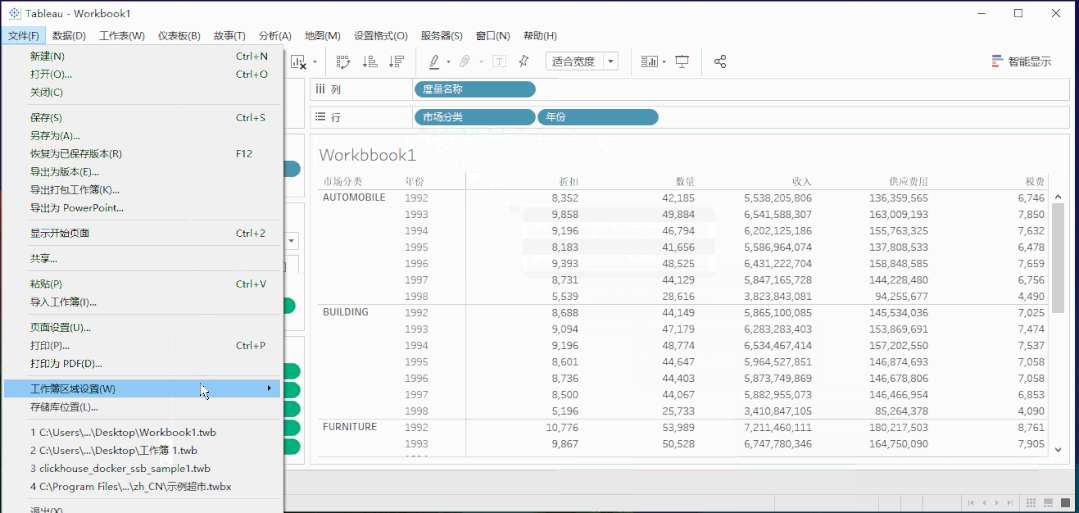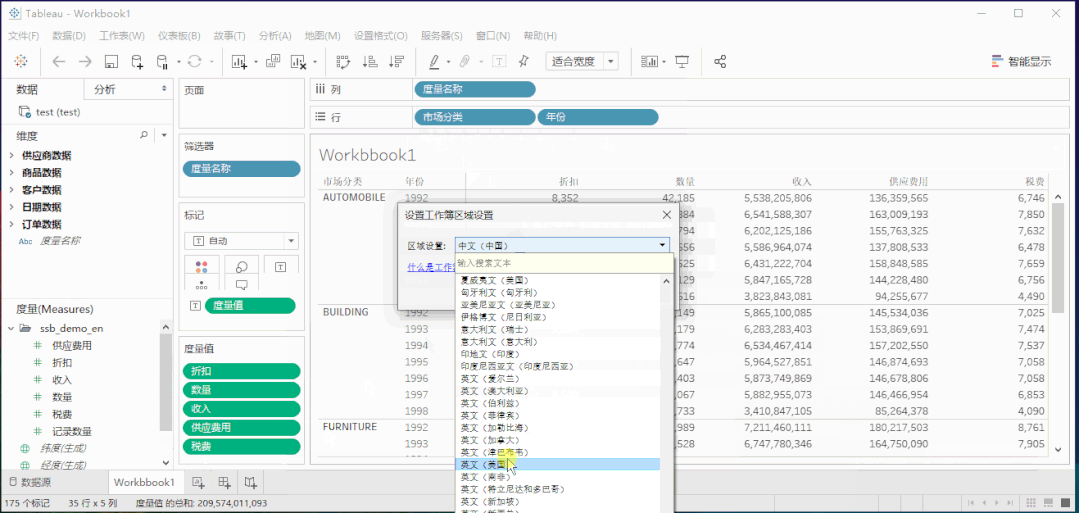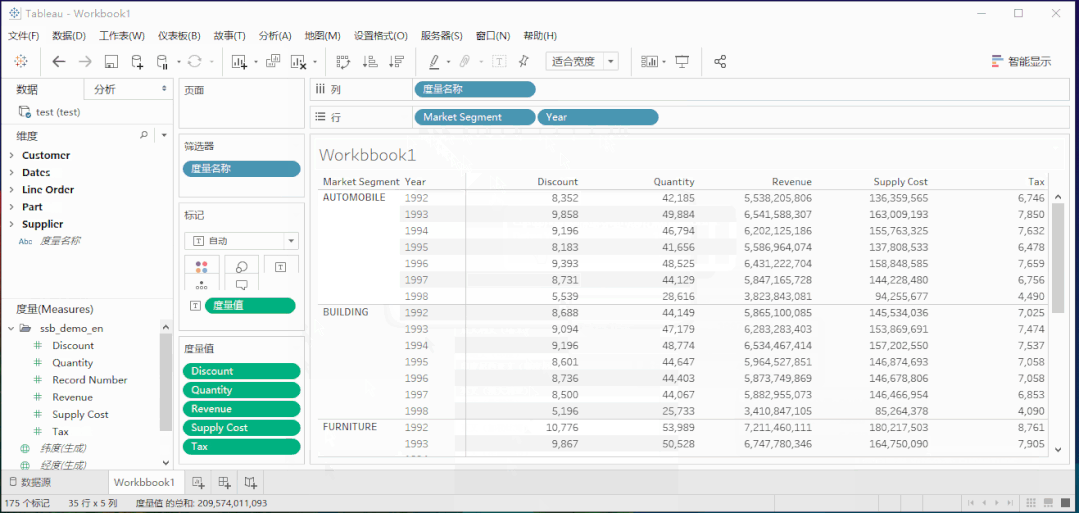
2. 强大的语义建模能力,助力业务场景分析
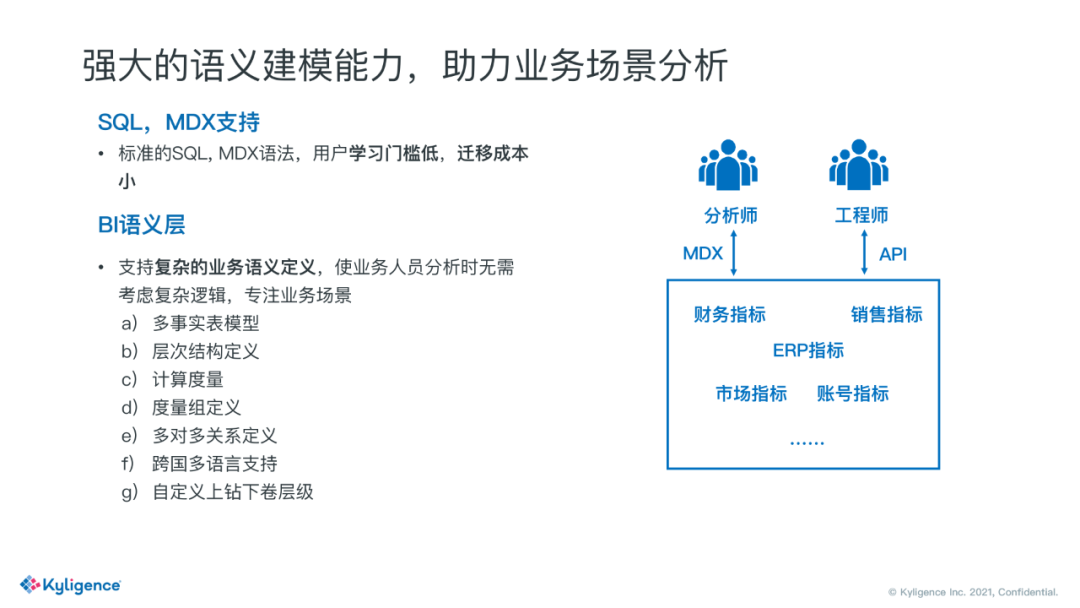
语义层帮忙屏蔽掉了底层的数据模型,意味着我的分析师不需要了解这些表结构,以及他们的关联关系。语义层暴露出来的概念都是维度度量、层级这种可直接拖拽的东西。一些复杂的技术逻辑也被屏蔽掉了,比如多事实表分析,多对多分析等等。
3. 统一的安全策略
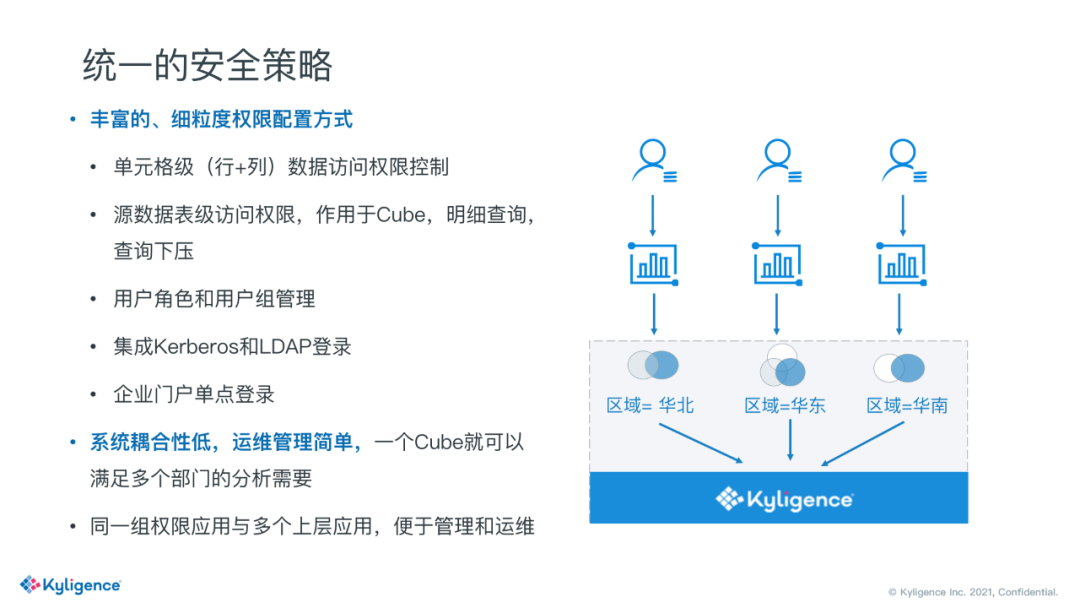
同时 Kyligence 也具备统一的安全策略,包括一些行列级权限,比方说不同部门的同事,只能看到不同地区的数据,华北的同事只能看到华北的数据,看不到华东的。
当中的一些挑战
1. 跨事实表分析
跨事实表分析是一个非常常见的分析场景,比如要分析不同年龄段年收入和年消费两者之间的关系,收入和消费就是两种完全不同类型的事实记录。
把两类指标放在一起进行分析,Excel 常用的做法是 vlookup,Tableau 的做法是数据融合(data blending), SSAS 的做法是星座模型。那在 Kyligence 是如何解决这个问题的呢?答案是模型整合。
2. 多对多分析
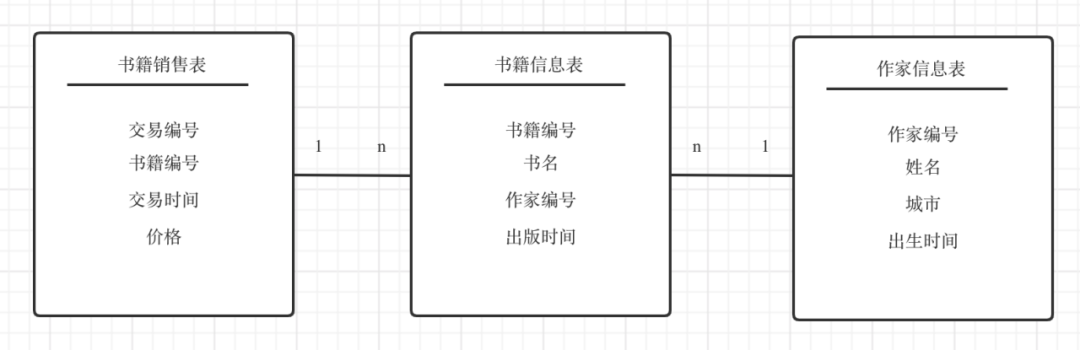
多对多分析在日常分析中经常见到,比如书籍和作者的关系,一本书可以有多个作者,一个作者也可以写多本书。如果要分析书籍销售额跟作者所在城市的关系,就会发现一本书的销售额在多个作家重复,导致在多个城市重复,但如果统计所有作家书籍的销售额时,又需要将这些重复的值去除,这就是典型的多对多场景。
3. 多对多典型处理方案
多对多典型处理方案:
在数据源层面将数据分摊,将度量值分摊到不同的维度值里。
模型打平后进行去重
基于键值进行关联查询
方案对比:
在数据源层面将数据分摊,容易操作,建立一个分摊数值后的 view 即可,缺陷是无法在各个维度用一个策略分摊,另外分摊后的只能保证某一维度汇总的值没有问题
模型打平后进行去重,缺陷是打平会导致数据重复,极易引起数据膨胀,且在线去重计算有一定性能问题。
基于键值进行关联查询,这个方案不需要将数据拉平,不用行行拿事实表主键来去重,直接利用 Cube 数据和维表数据 做关联即可得出结果。
4. 性能优化:MDX on Spark
Excel 数据查询使用的是 MDX 语言,是专门用来做多维分析的。传统的一些 MDX 查询引擎都是单机处理的,其中存在的问题是:
单机内存容量有限,一条大查询中间计算量可能非常庞大,一个指标计算依赖的数据可能达到上亿,这非常容易导致查询失败,且影响其他小查询的体验。
单机算力有上限,即使上述情况中超量的中间数据可以分批加载或采用落盘的方式来减轻内存的压力,但如此庞大的中间计算量仍会导致结果计算异常缓慢。
解决思路:
将 MDX 语法树转换成 Spark 执行计划,依靠 Spark 的分布式运算能力来解决单点问题。
本文转载自:DataFunTalk(ID:datafuntalk)

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论