

近年来,随着深度学习的发展,文本转语音(TTS)受到了广泛的关注。基于神经网络的 TTS 模型(如 Tacotron 2、DeepVoice 3 和 Transformer TTS)在语音质量方面已经超过了传统的连续式统计参数方法。
本文最初发布于微软官方博客,由 InfoQ 中文站翻译并分享。
基于神经网络的 TTS 模型通常首先由文本输入自回归地生成梅尔谱图,然后使用声码器从梅尔谱图合成语音。(注:梅尔刻度是用来测量频率的,单位是赫兹,刻度是基于音高的比较。谱图是一种随时间变化的频率的可视化表示。)
由于梅尔谱图的长序列和自回归性质,这些模型面临几个挑战:
自回归梅尔谱图生成的推理速度较慢,因为梅尔谱图序列通常有数百或数千帧的长度。
合成语音通常不完整,单词会有跳过和重复,这是由于传播错误和基于 encoder-attention-decoder 框架的自回归生成中文本和语音之间的注意力对齐错误(attention alignments)造成的。
由于生成长度是由自回归生成自动确定的,所以语速和韵律(如断句)无法调整,缺乏可控性。
为了解决上述问题,来自微软和浙江大学的研究人员提出了 FastSpeech,这是一种新型的前馈网络,可以快速生成具有鲁棒性、可控性的高质量梅尔谱图。我们的研究论文《FastSpeech:一种快速、鲁棒、可控的TTS》已经被第三十三届神经信息处理系统会议(NeurIPS 2019)接受。FastSpeech 采用了一种独特的架构,与其他 TTS 模型相比,它的性能在许多方面都得到了提升。这些结论来自于我们对 FastSpeech 的实验,稍后我们将在这篇文章中详细介绍。
在 LJ 语音数据集以及其他语音和语言上的实验表明,FastSpeech 具有以下优点。简要概述如下:
快:FastSpeech 使梅尔谱图的生成速度提高了 270 倍,使语音生成速度提高了 38 倍。
鲁棒:FastSpeech 避免了错误传播和错误注意力对齐的问题,因此几乎消除了单词跳过和重复。
可控:FastSpeech 可以很好的调节和控制语速。
高质量:FastSpeech 实现了与以前的自回归模型(如 Tacotron 2 和 Transformer TTS)相当的语音质量。
解构支持 FastSpeech 的模型框架
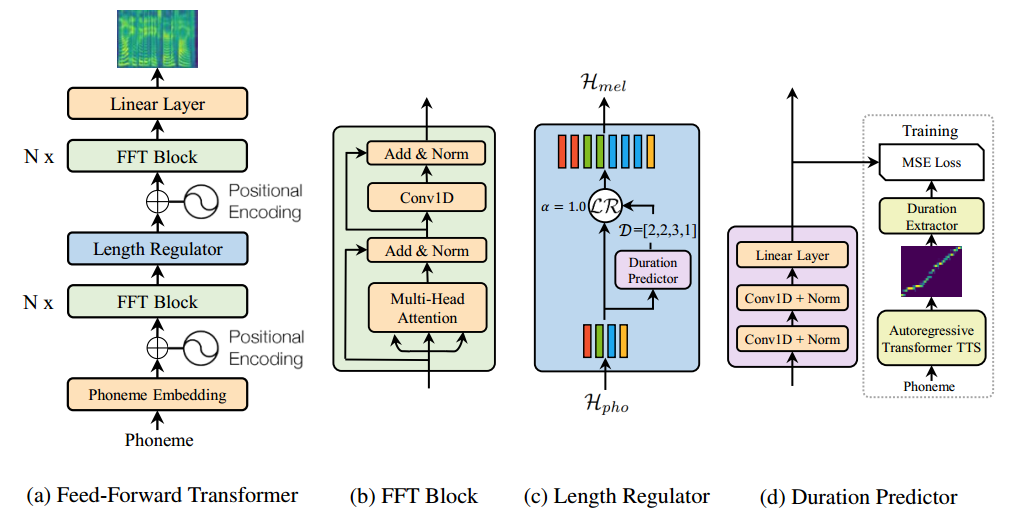
图 1:FastSpeech 的总体架构。(a)前馈转换器。(b)前馈转换器块。(c)长度调节器。(d)音长预测器。MSE 损失是预测时间和提取时间之间的损失,只存在于训练过程中。
前馈转换器
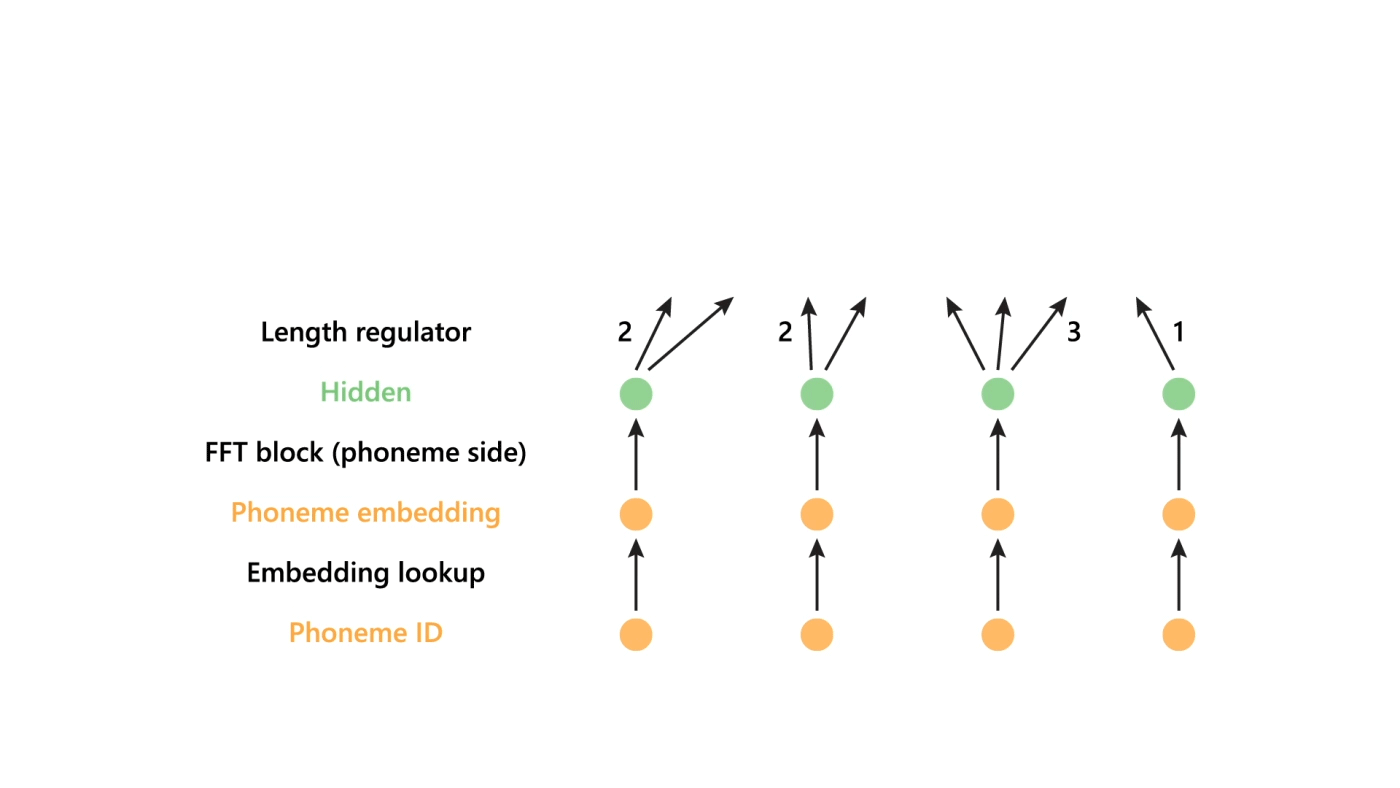
FastSpeech 采用了一种新颖的前馈转换器结构,抛弃了传统的 encoder-attention-decoder 框架,如图 1a 所示。前馈转换器的主要组成部分是前馈转换器块(FFT 块,如图 1b 所示),它由自注意力和 1 维卷积组成。FFT 块用于音素序列到梅尔谱图序列的转换,音素侧和梅尔谱图侧分别有 N 个堆叠块。与众不同的是,中间有一个长度调节器,用来弥补音素和梅尔谱图序列之间的长度不匹配。(注:音素是根据语音的自然属性划分出来的最小语音单位。)
长度调节器
模型的长度调节器如图 1c 所示。由于音素序列的长度小于梅尔谱图序列,一个音素对应几个梅尔谱图。对应一个音素的梅尔谱图的数量称为音长(phoneme duration)。长度调节器根据音素的持续时间扩展音素的隐藏序列,以匹配梅尔谱图序列的长度。我们可以通过按比例增加或减少音长来调整语速,也可以通过改变空白标记的时长来调整单词间的断句从而控制部分韵律。
音长预测器
音长预测器是长度调节器确定每个音素音长的关键。如图 1d 所示,时长预测器由两层 1 维卷积和一个预测音长的线性层组成。音长预测器位于音素侧的 FFT 块上,并通过均方根误差(MSE)损失函数与 FastSpeech 联合训练。在自回归教师模型中,音素时长的标签是从编码器和解码器之间的注意力对齐中提取的。详情请参阅论文。
FastSpeech 实验结果表明,TTS 能力得到了改善
为了验证 FastSpeech 的有效性,我们从语音质量、生成速度、鲁棒性和可控性几个方面对模型进行了评估。我们在 LJ 语音数据集上进行了实验,该数据集包含 13100 个英语音频片段和相应的转录文本,总时长约为 24 小时。我们将数据集随机分为三组:12500 个样本用于训练,300 个样本用于验证,300 个样本用于测试。FastSpeech 是在师生框架下训练的:教师是自回归 TTS 模型,用于序列级知识提取和时长提取,学生模型是 FastSpeech 模型。
语音质量
为了测量音频质量,我们对测试集进行了平均评价得分(MOS)评估。每个音频至少有 20 名测试者收听,这些测试者都是以英语为母语。我们将使用 FastSpeech 模型生成的音频样本的 MOS 与其他系统进行比较,其中包括:1)GT,基础真实音频;2) GT(Mel + WaveGlow),首先将基础真实音频转换为梅尔谱图,然后使用 WaveGlow 将梅尔谱图转换回音频;3)Tacotron 2 (Mel + WaveGlow);4)转换器 TTS (Mel + WaveGlow);5) Merlin (WORLD),一个流行的参数化 TTS 系统,使用 WORLD 作为声码器。结果如表 1 所示。可以看出,FastSpeech 的质量几乎与 Transformer TTS 模型和 Tacotron 2 的质量相当,感兴趣的话可以听一下我们Demo中的音频对比。

表 1:95%置信区间 MOS
推理速度
我们评估了 FastSpeech 的推理延迟,并将其与自回归转换器 TTS 模型进行了比较。从表 2 可以看出,FastSpeech 将梅尔谱图的生成速度提高了约 270 倍,将端到端的音频合成速度提高了约 38 倍。

表 2:95%置信区间的推理延迟比较。评估是在一个拥有 12 颗 Intel Xeon CPU、256GB 内存和 1 个 NVIDIA V100 GPU 的服务器上进行的。这两个系统生成的梅尔谱图的平均长度都在 560 左右。
鲁棒性
自回归模型中的编码-解码器注意力机制可能导致音素与梅尔谱图之间的注意力排列错误,进而导致单词重复和跳过的不稳定性。为了评估 FastSpeech 的鲁棒性,我们选择了 50 个对于 TTS 系统而言特别难的句子,错误统计如表 3 所示。可以看出 Transformer TTS 在这些困难的情况下并不健壮,错误率为 34%,而 FastSpeech 可以有效地消除单词重复和跳过,提高可理解性,这在我们的演示中也可以观察到。

表 3:FastSpeech 和 Transformer TTS 对于 50 个特别难的句子的鲁棒性比较。每句话中每一种单词错误最多计算一次。
长度控制
FastSpeech 可以通过长度调节器调节语速,速度从 0.5x 到 1.5x 不等,而且不会影响音质。你可以访问我们的页面来查看针对语速和断句的长度控制演示,其中包括 0.5x 到 1.5x 之间不同速度的录音。
消融实验
我们还研究了 FastSpeech 中各组件的重要性,包括 FFT 块中的一维卷积和序列级知识蒸馏。CMOS 评价如表 4 所示。可见,FFT 块中的一维卷积和序列级知识蒸馏对于保证 FastSpeech 的语音质量都是非常重要的。

我们还针对更多的语音和语言进行了实验,我们发现 FastSpeech 总是可以与自回归教师模型的语音质量相匹配,而且具有非常快的生成速度、鲁棒性和可控性。在未来的工作中,我们将优化 FastSpeech,并把它和并行声码器结合到一个单一的模型中,实现一个纯粹的端到端 TTS 解决方案。
原文链接:
FastSpeech: New text-to-speech model improves on speed, accuracy, and controllability

InfoQ主编

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论