

剑桥大学研究人员推出了强化学习框架 RLgraph(GitHub repo),该框架将逻辑组件组合从深度学习后端和分布式执行中分离开来,为强化学习带来了对内部和外部状态、输入、设备及数据流的严格管理。
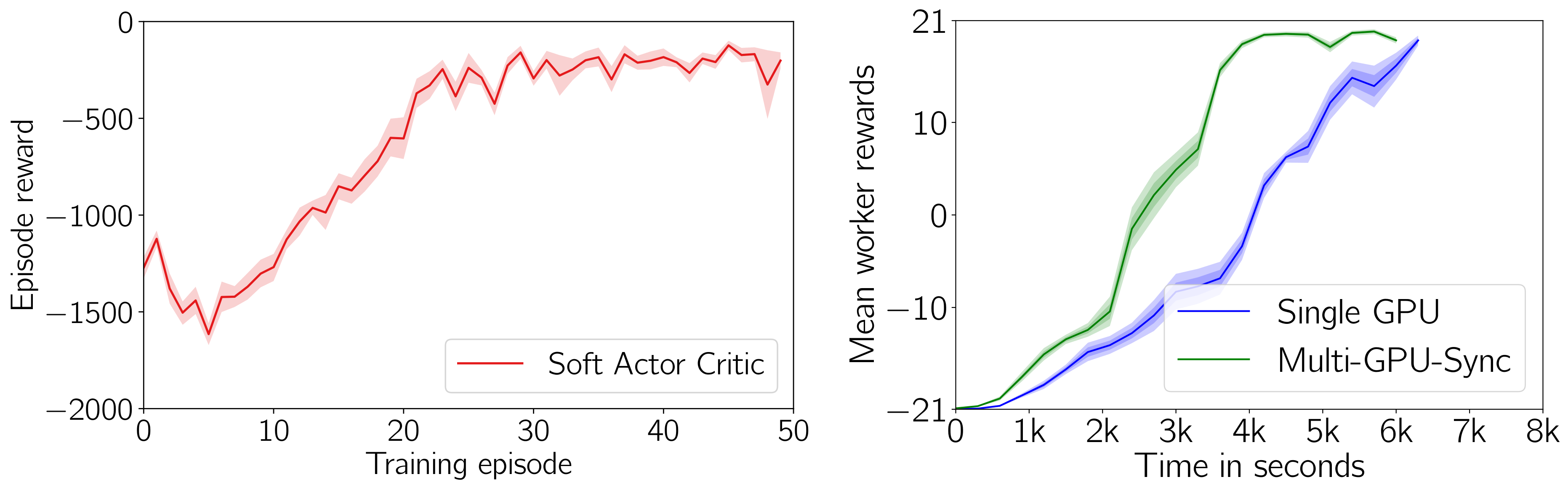
左侧:在 Pendulum-v0(10 个种子)上的 Soft Actor Critic。右侧:在 Pong-v0(10 个种子)上的多 GPU Ape-X。
开发人员使用 RLgraph 把高级组件以与空间无关的方式组合并定义输入空间。然后,RLgraph 构建与后端无关的组件图,该图可以转化为 TensorFlow 计算图,或通过 PyTorch(1.0 以上版本)以运行模式定义的方式执行。
以这种方式生成的智能体可以嵌入到其他应用程序(如第三方库 numpy 等)进行本地训练,或使用分布式 TensorFlow、Ray 和 Horovod 等框架作为后端。RLgraph 实现了目前许多流行算法的变体,如 SAC(感谢贡献者)、IMPALA、APE-X、PPO 等等。
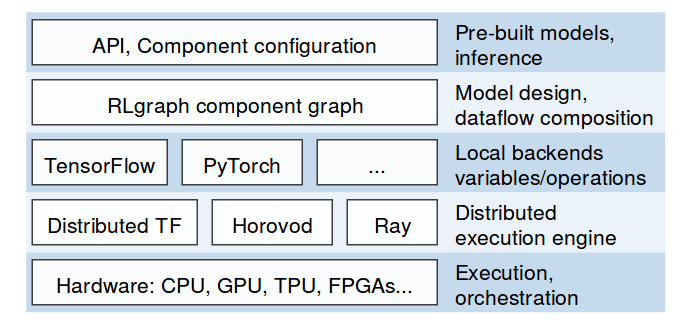
以上算法现有的实现难以解决原型、跨后端的重用性及可扩展执行之间的紧张关系。与之相比,RLgraph 实现的版本具有很多优势:
每个组件可以作为独立的图进行构建和测试,能够系统地测试复杂算法的子图,大大加快了调试和原型设计。组件可以被视为 Sonnet 风格对象,但包含 API 和设备管理、构建系统、变量创建和计算逻辑的分离。
后端和与空间无关的高级逻辑有助于更快地探索新设计。
可扩展性:RLgraph 代理可以任意执行,如:在 Ray 上使用我们的 Ray 执行包 、使用分布式 TensorFlow 来探索端到端图、或使用任意选择的分布机制。
维护:扩展现有框架常常意味着,不是复制大量代码就是把新的学习启发式内容不透明地堆到单个实现中。这两者都不可取。在 RLgraph 中,启发式算法是第一类公民,它们是分开构建和测试的。
总体而言,RLgraph 的目标是,在强制严格接口和严格构建系统及探索新设计之间进行必要的平衡。具体而言,RLgraph 框架适用于需要在各种各样的上下文部署中执行其研究的用户。该框架还具有简单的即插即用的高级 API(见下文)。
架构
用户通过非常类似于 TensorForce 的前端代理 API(该 API 我们中有些人也在创建或使用)与 RLgraph 代理进行交互。在内部,代理依赖图执行器,这些执行器服务于针对组件图的请求并管理特定于后端的执行语义。例如,TensorFlowExecutor 处理会话、设备、摘要、占位符、分析、分布式 TF 服务器和时间线。PyTorch 执行器反过来处理默认张量类型、设备或外部插件(如 Horovod)。
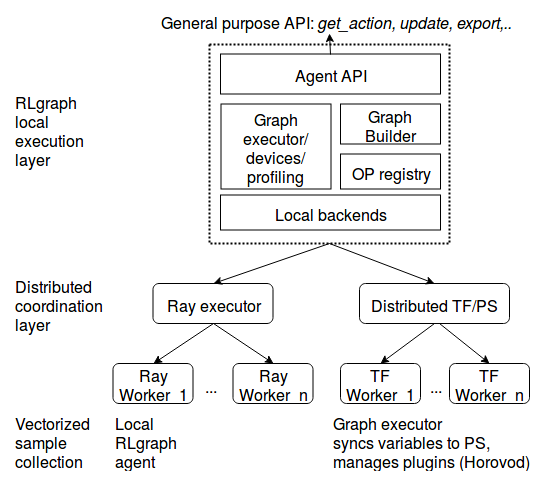
可以在外部引擎上(如,使用 RLgraph 的 RayExectuors)执行代理,或像任何其他应用程序中的对象一样使用代理。
API 示例
大多数应用用户都可以依赖复杂的高级别 API。下面我们将展示如何在本地或分布式上下文中无缝配置和执行代理。
完整的示例脚本和配置文件可以在存储库中找到。
组件
在 RLgraph 中,一切都是一个个的组件。代理通过根组件实现算法,而根组件包含各种子组件,如内存、神经网络、损失函数或优化器。组件通过 API 函数彼此交互,这些 API 函数在组件之间隐含地创建数据流。也就是说,使用 TensorFlow 后端,RLgraph 通过把 API 调用拼接在一起并在构建过程中跟踪它们,以创建端到端的静态图。例如,下图是一个用来更新策略网络的简单 API 方法:

API 方法装饰器将 API 函数包装起来,以创建端到端的数据流。RLgraph 会管理每个组件的会话、变量/内部状态、设备、范围、占位符、嵌套、时间和批处理以及其传入传出的数据流。
我们可以从空间构建组件并与其交互,而无需手动创建张量、输入占位符等等:
RLgraph 将张量空间和逻辑组件分开,使我们能够重用组件,而无需再次手动处理不兼容的形状。请注意,上述代码如何没有包含任何特定于框架的概念,只定义了来自一组空间的输入数据流。在 RLgraph 中,启发式算法(通常对 RL 的性能有很大的影响)不是事后才想到的,而是第一类公民,是单独或用其它组件集成测试过的。例如,策略(Policy)组件包含神经网络、动作适配器(以及相应的层次和分布)子组件,所有这些都是单独测试的。
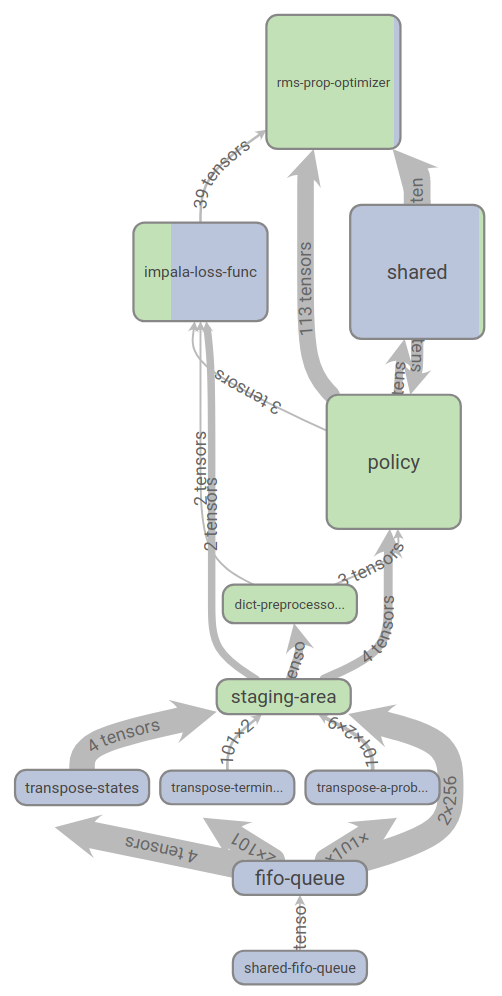
使用 RLgraph 和标准实施工作流的核心区别在于,每个组件都是完全明确指定的:它的设备和计算范围及内部状态(如变量共享)是明确分配的,这免除了令开发人员头痛的嵌套上下文管理的问题。因此,RLgraph 可以创建优雅的 TensorBoard 可视化,比如下图中我们实现的 IMPALA:
资源和贡献者征集
RLgraph 目前处于 alpha 阶段,正用于一些研究试点。我们欢迎贡献者和反馈。由于 RLgraph 雄心勃勃地覆盖了多个框架和后端,因此,在所有方面都有很多工作要做(我们特别欢迎更多 PyTorch 专家的加入)。
在接下来的几个月,我们将继续构建实用程序(TF 2.0 注意事项;后端代码分离,尤其是查看固定问题;其他 Ray 执行程序等等)和实现更多算法。请自由创建讨论改进的问题。
代码:用 RLgraph 构建应用程序入门:https://github.com/rlgraph/rlgraph
文档:请从readthedocs下载相应的文档
论文:请阅读我们的论文以了解更多关于 RLgraph 的设计。
阅读英文原文:RLgraph: Robust, incrementally testable reinforcement learning

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论