

目前,很多网站为了反爬都会采取各种各样的策略,比较简单粗暴的一种做法就是图片验证码,随着爬虫技术与反爬技术的演变,目前验证码也越来越复杂,比较高端的如Google的I‘m not a robot,极验等等。这些新的反爬方式大多都基于用户行为分析用户点击前的鼠标轨迹来判断是访问者是程序还是人。
基于图像处理的图片验证码识别
这篇文章介绍的是破解一般“传统”的图片验证码的步骤。上面提到的极验(目前应用比较广)也已经可以被破解,知乎上有相关的专栏,这里就不重复了。
即便是传统的图片验证码,也是有难度区分的(图一是我母校研究生院官网上的验证码,基本形同虚设;图二则是某网站的会员登录时的验证码增加了一些干扰信息,字符也有所粘连),但是破解的流程大致是一样的。

图 1

图 2
识别步骤
获取样本
从目标网站获取了 5000 个验证码图片到本地,作为样本。因为后期需要进行监督学习样本量要足够大。
样本去噪
✎ 先二值化图片
这一步是为了增强图片的对比度,利于后期图片图像处理,代码如下:
效果如下:
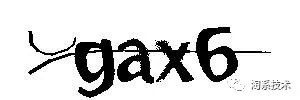
✎ 图片去噪
该案例中就是去除两条干扰线,常规的去噪算法有很多(洪水法等等),这里根据图片的特点采用了两种去噪算法,一种是自己根据图片的特征实现的算法,另一种是“八值法”。去噪后的效果如下,可以看到去除了大部分的干扰线(剩下的根据字宽可以直接过滤掉),但是部分字符也变细了,所以这一步的去噪阀值需要不断调整,在去噪的基础上要尽量保持原图的完整和可读性。
代码如下:
效果如下:
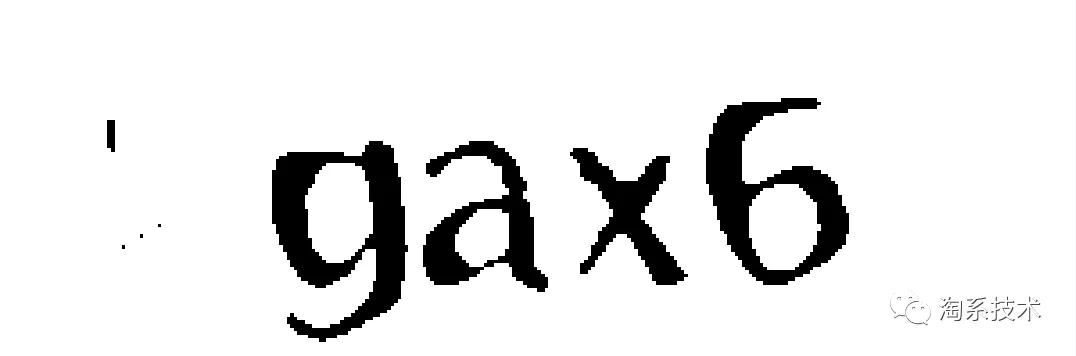
图片切割
图片切割有很多算法如投影法、CFS 以及滴水法等。投影法适用于字符垂直方向上没有粘连和重合的情况,CFS 能够很好的切割垂直方向有粘连但是没有粘连的字符,水滴法可以分割粘连字符。目前采用的 CFS 切割法。切割效果如下图,对于非粘连字符,效果很不错。CFS 联通域切割的实现算法主要用的是图的广度/深度遍历,代码如下:
效果如下:

提取 feature 并训练特征模型
✎ 提取 feature
每个字符用了 40 个样本(每个字符都切成了 60×60)进行打标签,如果效果不好后续可以增加样本量(由于 M 大多数粘连严重,所以切出来的 M 很少,没有达到 40 个,直接导致后面 M 的识别结果也很不好)。

✎ 训练模型
这里采用了 libsvm 来训练模型,从个样本中预留了 1/10 个作为检验集,accuracy 达到 95%。
识别效果
先手动挑选了“乍一看”粘连不是很严重的 30 个样本,进行训练,结果如下,在 80%左右。

总结和优化方向
1、目前整个识别流程已经走通,验证码识别服务也初具对外服务的能力;
2、虽然目前对于整体验证码的识别效果不是很好,但是,验证码服务拼的是识别率,比如说一个验证码需要识别,我在对其进行预处理和切割之后发现字符粘连效果不好,则完全可以抛弃,这并不影响识别率。换句话讲我只是别切出来是四个字符的验证码即可(如果遇到一个网站每个图片的粘连都比较严重,这条路就走不通了);
3、优化方向有两个:
(1)优化切割字符的算法,目前的机器学习算法在图片切割比较好的情况下识别率是非常高的,因此目前这类验证码的切割是整个过程中的难点,对于该案例可以采用波斯平滑后通过垂直投影图找到极值点作为水滴法的起点是一个思路;
(2)增加样本量,目前是 40 个识别率已经可以接受,如果增加训练集的 Size 识别率应该会有所提升。
基于神经网络的图片验证码识别
上文提到的识别方式效果严重依赖于图像切割的效果。对于一些粘连严重的验证码,需要花很大的精力来进行去噪和分割,即使这样,效果也不一定会达到令人满意的程度。
基于 CNN 来进行验证码识别的优势在与整体识别,字符的粘连对于识别效果的影响不是特别大。

图一
识别过程
以图一验证码为例,在本次识别中,构建了一个 4 层(一开始是 3 层,效果并不好)隐层的深度神经网络,网络结构如下(示意图中每一层的图片看起来虽然没有区别但是每一层的 size 是有区别的,重点看下标):
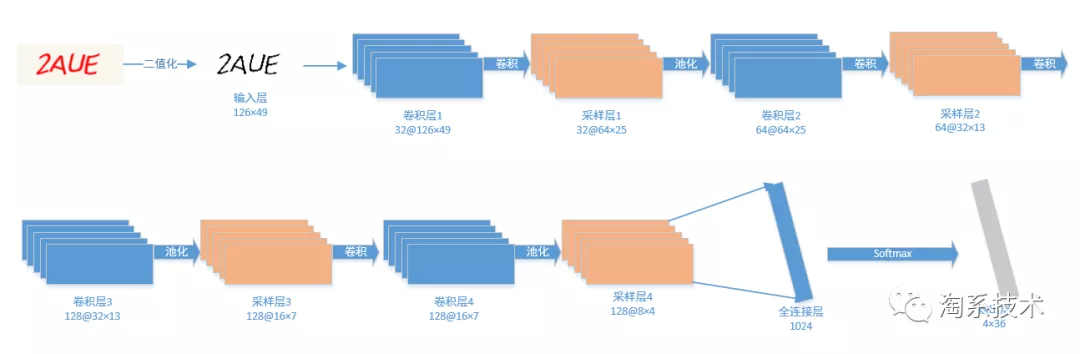
参数如下:
卷积核大小为 5×5(zero padding),Pooling 采用 max pooling(block 为 2×2),激活函数为 ReLU,学习率(LR)为 0.001,在训练集识别率达到 99%的时候输出模型。
训练过程优化的过程包括:
一开始使用三层卷积网络,效果并不理想,随后调整成了四层卷积层,效果有所提升;
训练集样本量的提高;
学习率的降低;
使用 Google 的 Tensorflow 机器学习框架进行训练。涉及到公司政策,代码就不上传了,网上可以搜到一些类似的。
识别效果
识别效果如下,左图是学习样本量为 3500 的时候识别率,右图是样本量为 4500(人工打码约 8 小时)的时候识别率:
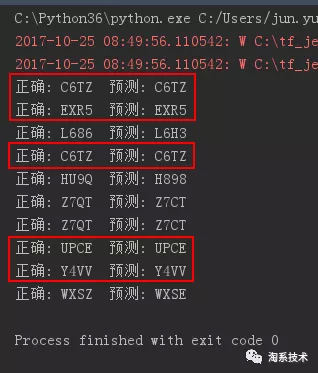
CNN:训练集样本量为 3500 时
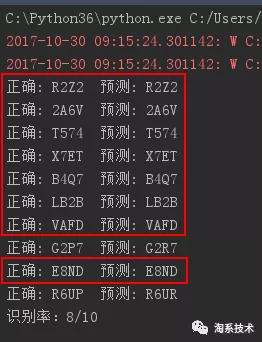
CNN:训练集样本量为 4500 时
对比一下用 libsvm 来识别的情况,左图是单个字符样本量为 40 张的时候识别情况,右图为单个字符样本量为 100 的时候的样本量(识别结果为 xxxx 的表示切割字符失败):
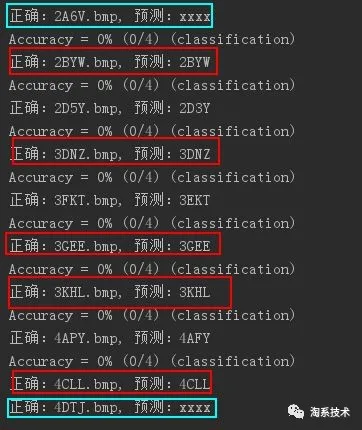
切割+SVM:每个字符样本为 40 时
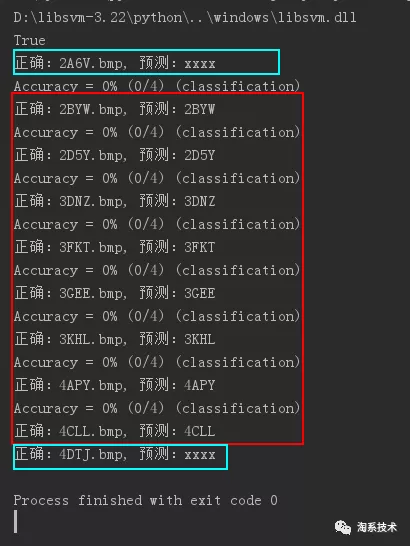
切割+SVM:每个字符样本为 100 时
存在的问题
整个过程遇到的问题主要包括两个方面:
中四层网络的训练明显要比三层收敛的更慢,MBP只能用CPU跑,正常4层网络要输出一个可用的模型(训练集识别率达到99%)需要1-2天;
样本集对于学习至关重要,目前没有较好的对样本进行打标记的方式,只能人工打码(人工智能之人工),4500的样本量我打了4个晚上。并且人工打码会有很多不确定因素,在本例中,后期发现很多7和T都打错了,势必会对最后的识别效果有所影响;
将来的优化方向包括:
增加训练集;
调低LR学习率;
调低keep_prob的值;
增加卷积层;
总结
验证码识别哪怕模型的识别率只有 20%也是可用的,识别错了换一个就可以,但是在整个爬虫和反爬的过程中,主动权往往掌握在反爬的这一边,切换验证码的成本比破解一个类型的验证码的成本要低太多,更何况验证码只是众多反爬手段之一,也正是如此爬虫和反爬才会显得格外的有意思。
和其他互联网攻防技术一样,这篇文章只是验证码识别技术探讨,旨在为设计验证码防爬提供思路,并不鼓励读者带着炫技或其他目的去破解验证码,疯狂爬取别人的网站。任何技术本身都是中立的,be a reasonable crawler。
本文转载自公众号淘系技术(ID:AlibabaMTT)。
原文链接:

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...









评论 1 条评论