

国际计算机视觉和模式识别大会(CVPR)一直是计算机视觉领域最重要的会议之一。受到新冠肺炎疫情影响,CVPR 2020 改为 6 月 14-19 日举行虚拟线上会议。本次大会共收录了来自全球的 1470 篇论文。华为视觉研究团队此次为业界贡献了 34 篇论文,其中包括 7 篇口头报告论文(注:华为视觉团队在 CVPR 2020 上发表 34 篇论文的完整列表,请参见文末附录)。
2020 年 3 月,田奇开始担任华为云人工智能领域首席科学家,主导华为云人工智能领域技术规划和提供技术支撑,并且代表华为公司正式发布《华为视觉计划》,着眼当前业界最为关心的三大基础问题,即如何从海量数据中挖掘有效信息、如何设计高效的视觉识别模型,以及如何表达并存储知识。《华为视觉计划》分为六大子计划:与数据相关的数据冰山计划、数据魔方计划;与模型相关的模型摸高计划、模型瘦身计划;以及与知识相关的万物预视计划、虚实合一计划。
华为视觉研究团队本次入围 CVPR2020 的 34 篇论文涵盖迁移学习、半监督学习、网络架构搜索、模型算子优化、知识蒸馏、对抗样本生成等领域。接下来,本文将从数据-模型-知识三大基础问题出发介绍华为 CVPR2020 的部分论文。
华为入选 CVPR 2020 的部分论文介绍
[数据挖掘] Cross-domain Detection via Graph-induced Prototype Alignment
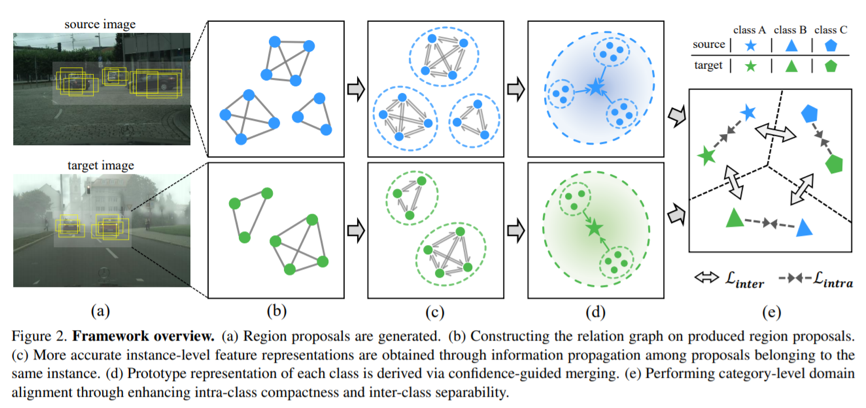
本文提出了一种跨域的学习方法,能够利用基于图匹配提升跨域迁移的效果。这本身是一个极具挑战性的问题,因为域间的分布差异会大大提升算法的难度。本方法的核心是构建一个两阶段的对齐算法:第一阶段(实例级)用于挖掘物体内部不同部件之间的相对关系,而第二阶段(类别级)用于挖掘不同物体之间的相对关系。整体算法被称为 Graph-induced Prototype Alignment(GPA),它能够与不同的物体检测框架相结合。在 Faster R-CNN 的基础上,算法在不同数据集间的迁移检测任务上,为基线算法提供了显著的性能提升。该算法已经开源:https://github.com/ChrisAllenMing/GPA-detection
[数据挖掘] Learning to Select Base Classes for Few-shot Classification
近年来,小样本学习越来越吸引研究人员的关注。人们提出了许多方法来进行从基类到新类的学习,但是很少有人研究怎样去进行基类的选择,或者是否不同的基类会导致学习到的模型具有不同的泛化能力。在这个工作中,我们提出一个简单但是有效的准则,相似比,来衡量小样本模型的泛化能力。我们把基类选择问题转化为相似比的子模函数优化问题。我们进一步通过对不同优化方法的上界进行理论分析,来寻找适合某一特定场景的优化方法。在 ImageNet, Caltech256 和 CUB-200-2011 等数据集上进行的大量实验验证了提出的方法在基类选择上的有效性。
[数据挖掘] Noise-aware Fully Webly Supervised Object Detection
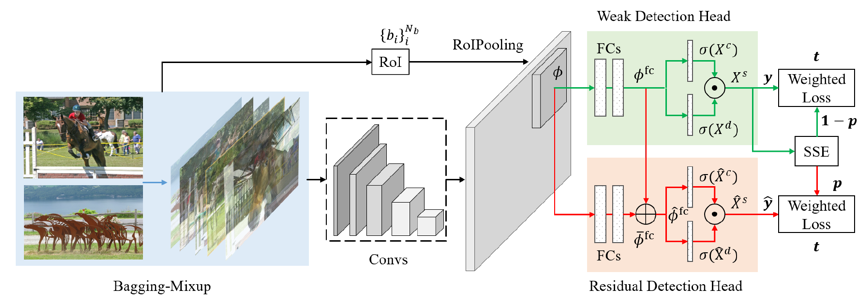
本文提出了一个新的训练物体检测器的方法,它仅需要网上图像级别的标签,而无需任何其它的监督信息。这是一项极具挑战的任务,因为网络上的图像级标签噪声极大,会导致训练出来的检测器性能很差。我们提出了一个端到端的框架,它能在训练检测器的同时减少有噪标签的负面影响,其中的结合弱监督检测的残差学习结构能将背景噪声分解并为干净数据建模。此外,我们提出的 Bagging-Mixup 学习方案可以抑制来自错误标注图像的噪声,同时保持训练数据的多样性。我们利用在照片共享网站的搜索获得的图像训练检测器,在流行的基准数据集上进行评估。大量的实验表明,我们的方法明显优于现有的方法。
[数据挖掘] Gradually Vanishing Bridge for Adversarial Domain Adaptation
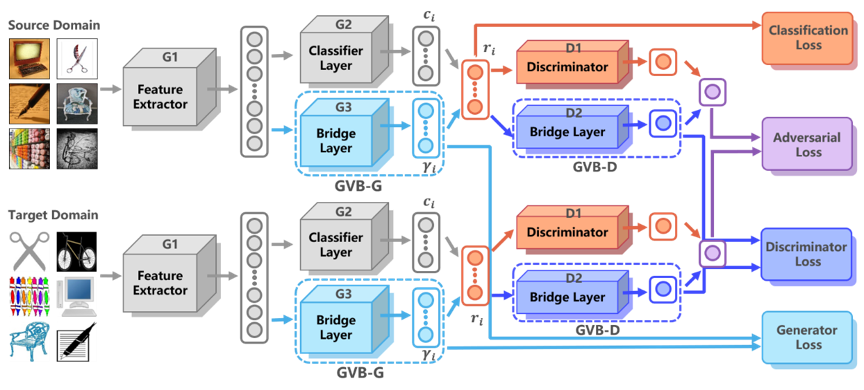
在无监督的领域适应中,丰富的领域特性给学习领域不变特征带来了巨大挑战。但是,在现有解决方案中,领域差异被直接最小化,在实际情况中难以实现较好的差异消除。一些方法通过对特征中对领域不变部分和领域专属部分进行显式建模来减轻难度,但是这种显式构造的方法在所构造的领域不变特征中容易残留领域专属特征。本文在生成器和鉴别器上都使用了减弱式桥梁(GVB)机制。在生成器上,GVB 不仅可以降低总体迁移难度,而且可以减少领域不变特征中残留的领域专属特征的影响。在鉴别器上,GVB 有助于增强鉴别能力,并平衡对抗训练过程。三个具有挑战性的数据集上的实验表明,GVB 方法优于强大的竞争对手,并且可以与其他领域适应的对抗方法实现很好地协作。这一项目已经开源:https://github.com/cuishuhao/GVB。
[模型优化] SP-NAS: Serial-to-Parallel Backbone Search for Object Detection
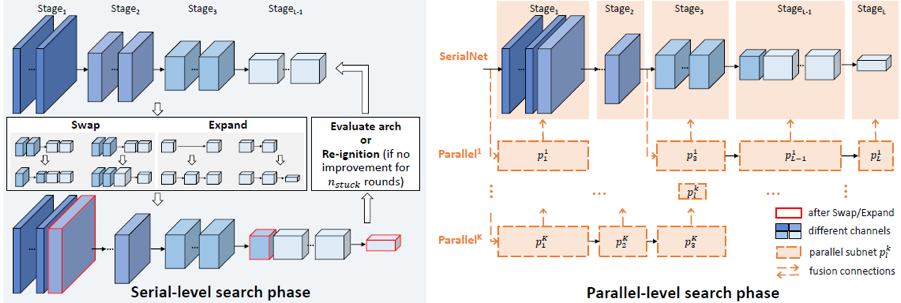
我们使用神经网络结构搜索自动设计针对于目标检测任务的主干网络,以弥合分类任务和检测任务之间的差距。我们提出了一个名为 SP-NAS 的两阶段搜索算法(串行到并行的搜索)。串行搜索阶段旨在通过“交换,扩展,重点火”的搜索算法在特征层次结构中找到具有最佳感受野比例和输出通道的串行序列;并行搜索阶段会自动搜索并将几个子结构以及先前生成的主干网络组装到一个更强大的并行结构的主干网络中。我们在多个检测数据集上可达到 SOTA 结果,在 ECP 的公开的行人检测排行榜上达到第一名的顶级性能(LAMR:0.055)。
[模型优化] Revisit Knowledge Distillation: A teacher-free Framework
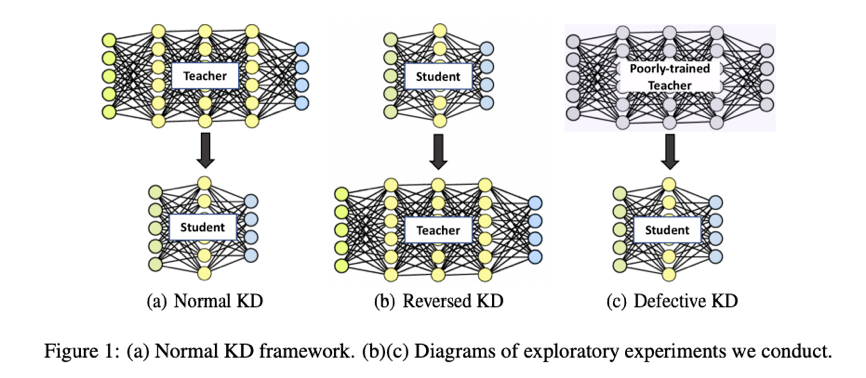
知识蒸馏(KD)的成功通常归因于由教师模型提供的类别之间相似性的信息。在这项工作中,我们观察到:1)除了教师可以提高学生的性能外,学生还可以通过逆转程序来提高教师性能; 2)未充分训练的教师网络仍然可以提高学生的水平。为了解释这些观察,我们提供了 KD 和标签平滑规则化之间关系的分析,证明 1)KD 是一种学习的标签平滑正则化,2)标签平滑正则化等价于利用虚拟教师模型来做 KD,并进一步提出了一种新颖的无教师知识蒸馏(Tf-KD)框架。在没有任何额外计算成本的情况下,该框架比公认的基线模型提高了 0.65%。代码位于 https://github.com/yuanli2333/Teacher-free-Knowledge-Distillation。
[模型优化] GhostNet: More Features from Cheap Operations
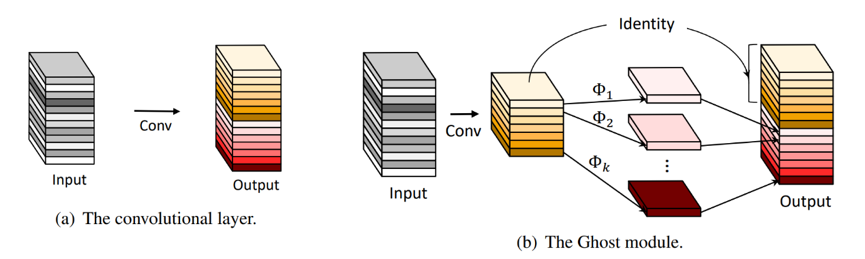
论文提出了一个全新的 Ghost 模块,旨在通过廉价操作生成更多的特征图。基于一组原始的特征图,作者应用一系列线性变换,以很小的代价生成许多能从原始特征发掘所需信息的“幻影”特征图(Ghost feature maps)。该 Ghost 模块即插即用,通过堆叠 Ghost 模块得出 Ghost bottleneck,进而搭建轻量级神经网络——GhostNet。在 ImageNet 分类任务,GhostNet 在相似计算量情况下 Top-1 正确率达 75.7%,显著高于 MobileNetV3 的 75.2%。相关代码已开源:https://github.com/huawei-noah/ghostnet
[模型优化] AdderNet: Do We Really Need Multiplications in Deep Learning?
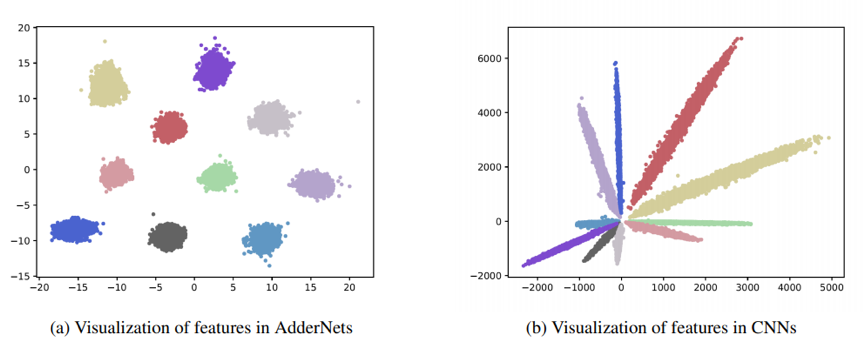
和乘法操作相比,加法操作对于计算机来说具有更少的计算代价。本论文提出了加法神经网络,通过将卷积中计算特征和卷积核的互相关替换为 L1 距离,卷积运算中的乘法可以被完全替换为更为轻量的加法计算。我们提出了针对加法神经网络特殊的反向传播和学习率调整技巧以提升加法神经网络的表达能力和准确率。实验表明,我们提出的加法神经网络可以使用 ResNet-50 网络在 ImageNet 数据集上达到 74.9%的 Top-1 准确率和 91.7%的 Top-5 准确率,并且在卷积计算中不包含任何的乘法。相关代码已开源:https://github.com/huawei-noah/addernet
[知识抽取] SketchyCOCO: Image Generation from Freehand Scene Sketches
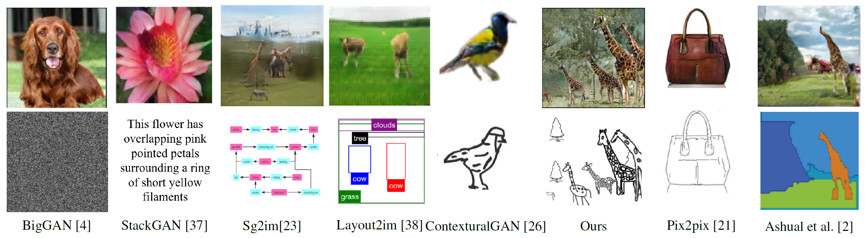
本文提出了首个从场景级手绘草图自动生成图像的方法。我们的模型允许通过手绘草图指定合成目标,从而实现可控的图像生成。本文的关键贡献在于设计了 EdgeGAN,它是一个属性矢量桥接的生成对抗网络,能够支持高质量的物体级别的图像内容生成,而无需使用徒手草图作为训练数据。我们建立了一个名为 SketchyCOCO 的大型数据集,用于评估所提出的解决方案。在物体级别和场景级别图像生成任务上,我们在 SketchyCOCO 上测试了我们的方法。 通过定量和定性的结果、视觉评估和消融实验,我们验证了该方法能够从各种手绘草图中生成逼真的复杂场景图像。
[知识抽取] Creating Something from Nothing: Unsupervised Knowledge Distillation for Cross-modal Hashing
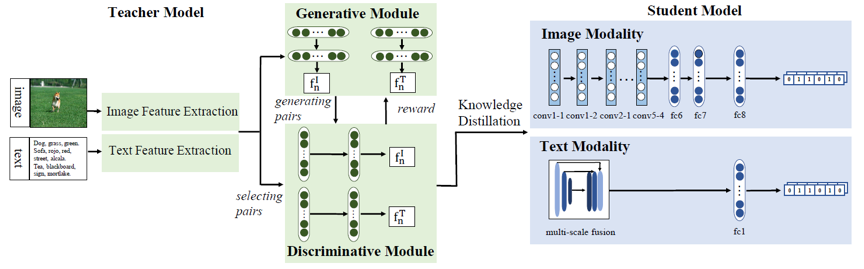
本文提出了一种利用“无中生有”的监督方式,用于跨模态哈希编码。现存的跨模态哈希编码分为有监督和无监督两类,前者通常精度更高,但依赖于图像级标注信息,以生成相似度矩阵。本方法创新性地提出,利用无监督的哈希方法产生图像特征,并利用图像特征计算相似度矩阵,从而绕开了对监督信号的需求,在不增加标注代价的情况下,提升了跨模态哈希编码的精度,超过了所有无监督的编码方法。本文还分析了图像特征和文本特征在相似度计算中的作用,并且讨论了这种方法在类似场景中的应用。
[知识抽取] Transformation GAN for Unsupervised Image Synthesis and Representation Learning
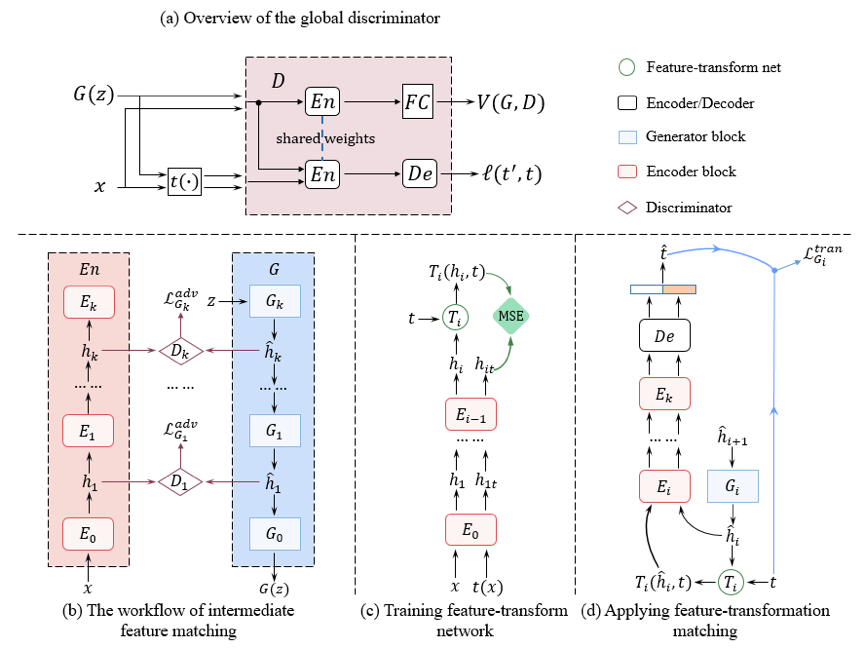
本文提出了一种新的自监督对抗生成网络模型,与现有的模型不同,新的模型既通过预测投影变换参数的自监督方式约束生成图片,又使用编码器提取到的特征来约束生成网络中间层的特征,从而更充分地利用自监督信息以提升性能。在新提出的模型中,我们使用中间特征匹配的方式约束生成网络的中间特征与自监督编码器的中间特征包含相似的语义信息。同时,我们提出了一种新的“特征-变换”匹配的约束,即:要求生成特征具有与自监督提取特征相似的“特征-变换”映射关系。上图显示了模型完整的训练过程:对于全局判别网络 D,我们训练 D 在分辨生成图片与真实图片的同时,能够预测出施加在真实图上的投影变换的参数;而在生成网络的训练中,我们首先通过对抗训练约束生成特征与自监督提取特征包含相似的语义信息。同时,我们训练 T 网络去近似真实图片变换前后所提取到的特征之间的映射关系,并约束生成特征具有相似的“特征-变换”映射关系。本文提出的方法在无监督图片生成的任务上获得了比有监督对比模型更好的性能(FID)。
[知识抽取] Unsupervised Model Personalization while Preserving Privacy and Scalability: An Open Problem
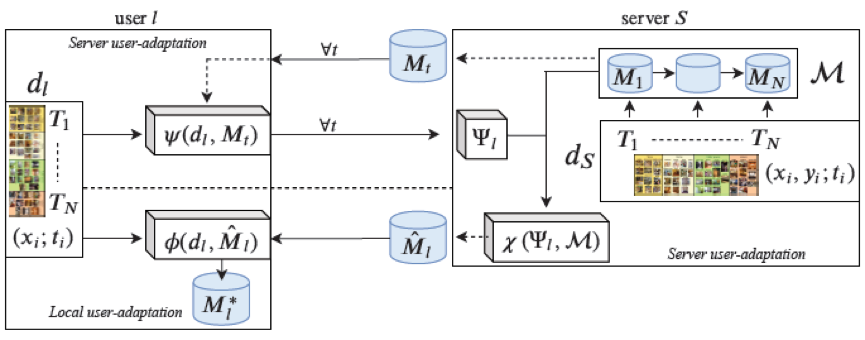
本工作研究无监督模型个性化的任务,可适应到连续演进以及无标签的用户数据。考虑服务器与许多资源受限的边缘设备进行交互的实际场景,它对规模化和数据隐私性有较高的要求。我们从持续学习的角度来看待这个问题,提出了对偶用户自适应框架。在服务器端增量式地学习多个专家模型,并在用户端以无监督方式根据用户先验对专家模型进行聚合;从领域自适应角度来进行局部用户自适应,通过调整批归一化使模型适应到用户数据进行自适应更新。大量的实验表明数据驱动的局部自适应具有良好表现,只需用户先验和模型而不需要用户原始数据也可进行模型局部自适应。
附录:
华为在 CVPR 2020 的完整论文列表(以下论文以作者姓氏排序)
[1] Francesca Babiloni, Marras Ioannis, Gregory Slabaugh, Stefanos Zafeiriou, TESA: Tensor Element Self-Attention via Matricization, CVPR 2020.
[2] Hanting Chen, Yunhe Wang, Chunjing Xu, Boxin Shi, Chao Xu, Qi Tian, Chang Xu, AdderNet: Do We Really Need Multiplications in Deep Learning? CVPR 2020 (Oral).
[3] Hanting Chen, Yunhe Wang, Han Su, Yehui Tang, Chunjing Xu, Boxin Shi, Chao Xu, Qi Tian, Chang Xu, Frequency Domain Compact 3D Convolutional Neural Networks, CVPR 2020.
[4] Hao Chen, Kunyang Sun, Zhi Tian, Chunhua Shen, Yongming Huang, Youliang Yan, BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation, CVPR 2020 (Oral).
[5] Shuhao Cui, Shuhui Wang, Junbao Zhuo, Liang Li, Qingming Huang, Qi Tian, Towards Discriminability and Diversity: Batch Nuclear-norm Maximization on Output under Label Insufficient Situations, CVPR 2020 (Oral).
[6] Shuhao Cui, Shuhui Wang, Junbao Zhuo, Chi Su, Qingming Huang, Qi Tian, Gradually Vanishing Bridge for Adversarial Domain Adaptation, CVPR 2020.
[7] Matthias De Lange, Xu Jia, Sarah Parisot, Ales Leonardis, Gregory Slabaugh, Tinne Tuytelaars, Unsupervised Model Personalization while Preserving Privacy and Scalability: An Open Problem, CVPR 2020.
[8] Chengying Gao, Qi Liu, Qi Xu, Limin Wang, Jianzhuang Liu, Changqing Zou, SketchyCOCO: Image Generation from Freehand Scene Sketches, CVPR 2020 (Oral).
[9] Guoqiang Gong, Xinghan Wang, Yadong Mu, Qi Tian, Learning Temporal Co-Attention Models for Unsupervised Video Action Localization, CVPR 2020 (Oral).
[10] Jianyuan Guo, Kai Han, Yunhe Wang, Chao Zhang, Zhaohui Yang, Han Wu, Xinghao Chen, Chang Xu, Hit-Detector: Hierarchical Trinity Architecture Search for Object Detection, CVPR 2020.
[11] Tianyu Guo, Chang Xu, Jiajun Huang, Yunhe Wang, Boxin Shi, Chao Xu, Dacheng Tao, On Positive-Unlabeled Classification in GAN, CVPR 2020.
[12] Kai Han, Yunhe Wang, Jianyuan Guo, Chunjing Xu, Qi Tian, Chang Xu, GhostNet: More Features from Cheap Operations, CVPR 2020.
[13] Daniel Hernandez-Juarez, Sarah Parisot, Benjamin Busam, Ales Leonardis, Gregory Slabaugh, Steven McDonagh, A Multi-Hypothesis Approach to Color Constancy, CVPR 2020.
[14] Hengtong Hu, Lingxi Xie, Richang Hong, Qi Tian, Creating Something from Nothing: Unsupervised Knowledge Distillation for Cross-Modal Hashing, CVPR 2020.
[15] Takashi Isobe, Xu Jia, Songjiang Li, Shanxin Yuan, Gregory Slabaugh, Chunjing Xu, Ya-Li Li, Shengjing Wang, Qi Tian, Video Super-resolution with Temporal Group Attention, CVPR 2020.
[16] Chenhan Jiang, Hang Xu, Wei Zhang, Xiaodan Liang, Zhenguo Li, SP-NAS: Serial-to-Parallel Backbone Search for Object Detection, CVPR 2020.
[17] Aoxue Li, Weiran Huang, Xu Lan, Jiashi Feng, Zhenguo Li, Liwei Wang, Boosting few-shot learning with adaptive margin loss, CVPR 2020.
[18] Yutian Lin, Lingxi Xie, Yu Wu, Chenggang Yan, Qi Tian, Unsupervised Person Re-identification via Softened Similarity Learning, CVPR 2020.
[19] Lin Liu, Xu Jia, Jianzhuang Liu, Qi Tian, Joint Demosaicing and Denoising with Self Guidance, CVPR 2020.
[20] Yuliang Liu, Hao Chen, Chunhua Shen, Tong He, Lianwen Jin, Liangwei Wang, ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network, CVPR 2020 (Oral).
[21] Sean Moran, Pierre Marza, Steven McDonagh, Sarah Parisot, Gregory Slabaugh, Deep Local Parametric Filters for Image Enhancement, CVPR 2020.
[22] Yucheng Shi, Yahong Han, Qi Tian, Polishing Decision-based Adversarial Noise with a Customized Sampling, CVPR 2020.
[23] Yehui Tang, Yunhe Wang, Yixing Xu, Hanting Chen, Chunjing Xu, Boxin Shi, Chao Xu, Qi Tian, Chang Xu, A Semi-Supervised Assessor of Neural Architectures, CVPR 2020.
[24] Jiayu Wang, Wengang Zhou, Guo-Jun Qi, Zhongqian Fu, Qi Tian, Houqiang Li, Transformation GAN for Unsupervised Image Synthesis and Representation Learning, CVPR 2020.
[25] Xinyu Wang, Yuliang Liu, Chunhua Shen, Chun Chet Ng, Canjie Luo, Lianwen Jin, Chee Seng Chan, Anton van den Hengel, Liangwei Wang, On the General Value of Evidence, and Bilingual Scene-Text Visual Question Answering, CVPR 2020.
[26] Jun Wei, Shuhui Wang, Zhe Wu, Chi Su, Qingming Huang, Qi Tian, Label Decoupling Framework for Salient Object Detection, CVPR 2020.
[27] Minghao Xu, Hang Wang, Bingbing Ni, Qi Tian, Wenjun Zhang, Cross-domain Detection via Graph-induced Prototype Alignment, CVPR 2020 (Oral).
[28] Jinrui Yang, Wei-Shi Zheng, Qize Yang, Yingcong Chen, Qi Tian, Spatial-Temporal Graph Convolutional Network for Video-based Person Re-identification, CVPR 2020.
[29] Zhaohui Yang, Yunhe Wang, Xinghao Chen, Boxin Shi, Chao Xu, Chunjing Xu, Qi Tian, Chang Xu, CARS: Continuous Evolution for Efficient Neural Architecture Search, CVPR 2020.
[30] Li Yuan, Francis E.H.Tay, Guilin Li, Tao Wang, Jiashi Feng, Revisit Knowledge Distillation: a Teacher-free Framework, CVPR 2020 (Oral).
[31] Li Yuan, Tao Wang, Xiaopeng Zhang, Francis Tay, Zequn Jie, Wei Liu, Jiashi Feng, Central Similarity Hashing for Efficient Image and Video Retrieval, CVPR 2020.
[32] Rufeng Zhang, Zhi Tian, Chunhua Shen, Mingyu You, Youliang Yan, Mask Encoding for Single Shot Instance Segmentation, CVPR 2020.
[33] Bolun Zheng, Shanxin Yuan, Gregory Slabaugh, Ales Leonardis, Image Demoireing with Learnable Bandpass Filters, CVPR 2020.
[34] Linjun Zhou, Peng Cui, Xu Jia, Shiqiang Yang, Qi Tian, Learning to Select Base Classes for Few-shot Classification, CVPR 2020.

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论