
AAAI 2018 大会将至,蚂蚁金服在本次大会上也有多篇论文被录取。上周,我们和大家介绍了《AAAI 2018 论文 | 蚂蚁金服公开最新基于笔画的中文词向量算法》这篇论文(点进链接即可阅读),这是蚂蚁金服人工智能部与新加坡科技大学一项最新的合作成果:cw2vec——基于汉字笔画信息的中文词向量算法研究,受到了大家的欢迎。
本篇文章我们分享的是蚂蚁在 AAAI 2018 大会上的另外一篇论文,Privacy Preserving Point-of-interestRecommendation Using Decentralized Matrix Factorization,本文探讨了用去中心化的方式来在做用户兴趣推荐的同时保护好用户隐私,还能同时解决原有中心化的计算方式带来的资源浪费问题。一起来看看吧!如果你有什么问题和想法,请欢迎在文末的评论区与蚂蚁金服的技术同学进行互动!

论文下载链接 https:// docs.google. com/viewer?a=v&pid=sites&srcid=ZGVmYXVsdGRvbWFpbnxjY2Nob21lcGFnZXxneDoxMGM0OGFkMGM4ZTA2MzY(请将网址复制至浏览器中打开或直接点击阅读原文即可查看。)
随着基于地理位置的社交网络(如共享单车)的发展,兴趣点的推荐(Point-of-interest,如推荐酒店,餐厅,加油站,以下简称 POI)也变的越来越流行。矩阵分解(潜在因子模型)是兴趣点推荐中非常重要的一类方法。在训练阶段,它通过用户对物品已有的交互信息(如点击,评分,评论,上下文等)学习用户和物品的潜在向量;在预测阶段,通过用户和物品的潜在向量的相似度匹配来做推荐。
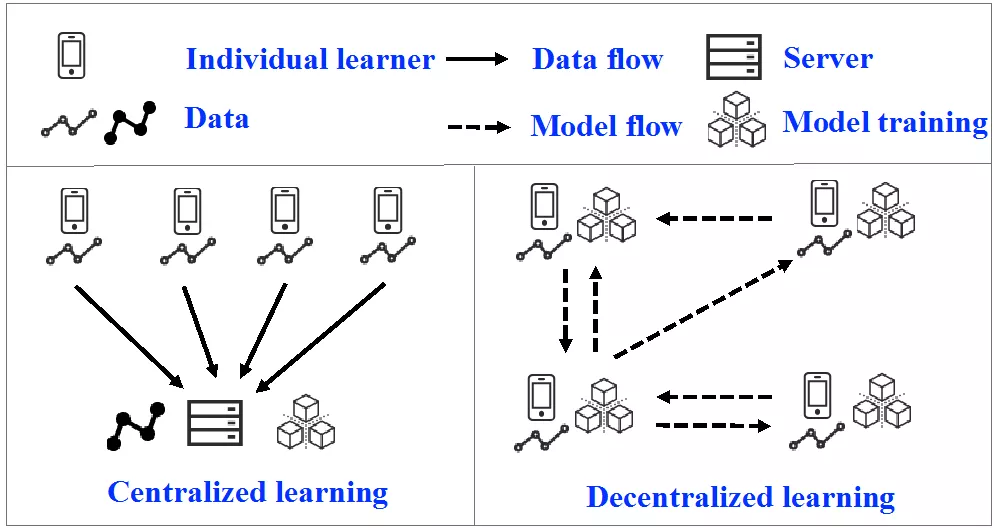
图 1 集中式训练与去中心化式训练的对比
现有的兴趣点推荐系统,都属于集中式(centralized)训练的方法,如图 1 左所示。也就是说,传统的矩阵分解技术,首先构建该推荐系统的人(或平台),要获取用户对物品行为(如购买,点击,评分等行为)数据,然后利用这些数据来构建一个矩阵分解推荐系统。这样做有两个弊端:
(1)耗费存储计算资源。一方面,所有用户对物品的行为历史数据,都要集中式的存储在某个服务端,因此浪费存储资源。另一方面,在训练矩阵分解模型时,需要在服务端机器上训练,模型的训练速度受限于服务端机器数量,因此浪费了计算资源。
(2)不能保护用户隐私数据。因为用户对物品的行为历史,都被该服务端获取了,假设该服务端不会主动泄露用户隐私,那也存在会被黑客攻击,从而导致用户隐私泄露的事情发生。
为解决这两个问题,我们提出了一种用户隐私保护的去中心化式的矩阵分解方法,如图 1 右所示。简单而言,用户的数据存在在自己的个人设备上,如手机和 pad,不向服务端上传,这样解决了集中式训练造成的存储资源浪费。另一方面,模型的训练,也都在用户端完成,用户之间通过交互非原始数据信息来完成模型的协同训练。这样的去中心化式的训练方法可视为分布式算法,每个用户都是一个计算节点,因为可以解决集中式训练造成的计算资源浪费。
模型介绍
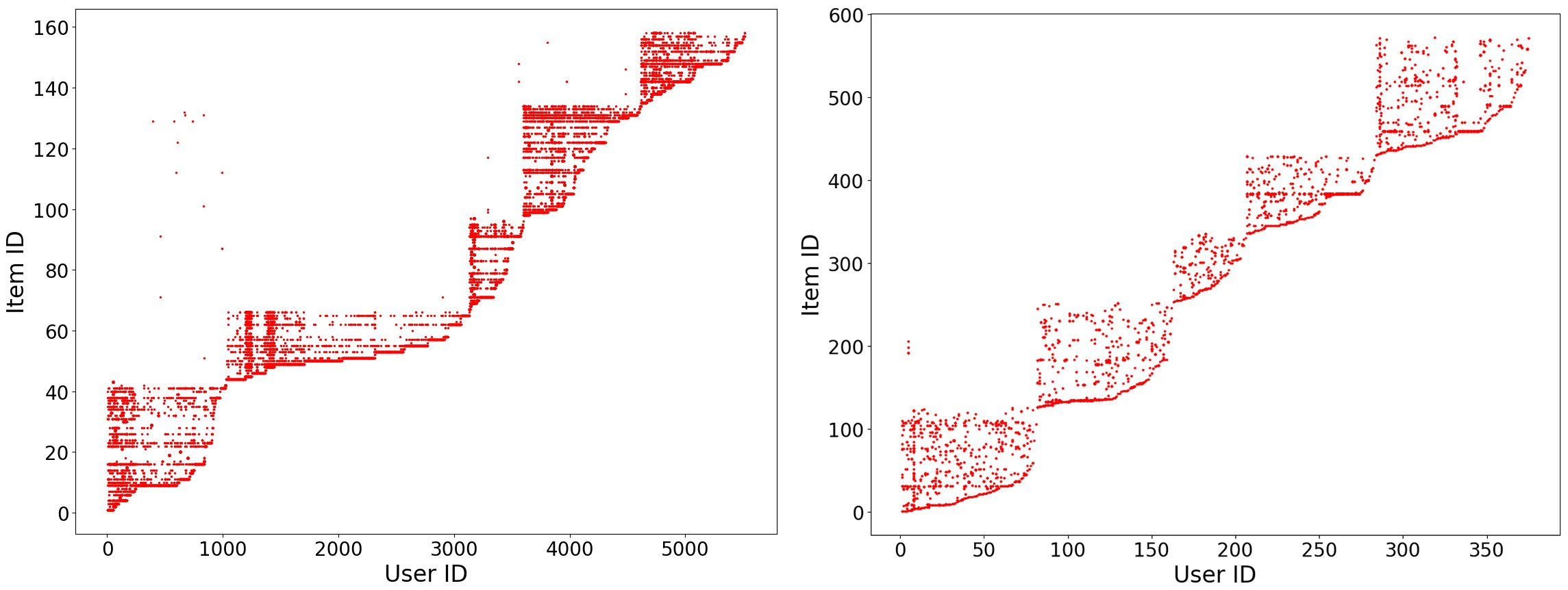
图 2 Foursquare 及 Alipay 数据分析
1. 问题定义
对于去中心化的推荐而言,每个用户对 POI 的行为数据(如 check-in),都保存在用户自己的设备上,如手机和 pad,不向服务端上传。我们提出的去中心化的推荐,可以应用于多种已知的潜在向量模型中,如矩阵分解[1]和 pair-wise 的排序方法[2]中。以去中心化的矩阵分解方法为例,每个用户自己需要保存的信息有:
a. 其自己对每个 POI 的原始交互信息
b. 其自身的用户潜在向量
c. 每个 POI 的共享(common, global)潜在向量
d. 该用户自己对 POI 的个性化(personal, local)向量
去中心化的推荐与传统集中式训练的推荐方法的核心思想相似,即用户之间协同完成模型的训练。那么,很自然的可以想到,去中心化式的推荐方法面临以下两个挑战:
C1: 每个用户应当与哪些用户做信息交互,以学习模型;
C2: 用户之间应当交互哪些信息,以达到不泄露个人数据但能协同训练模型的目的。
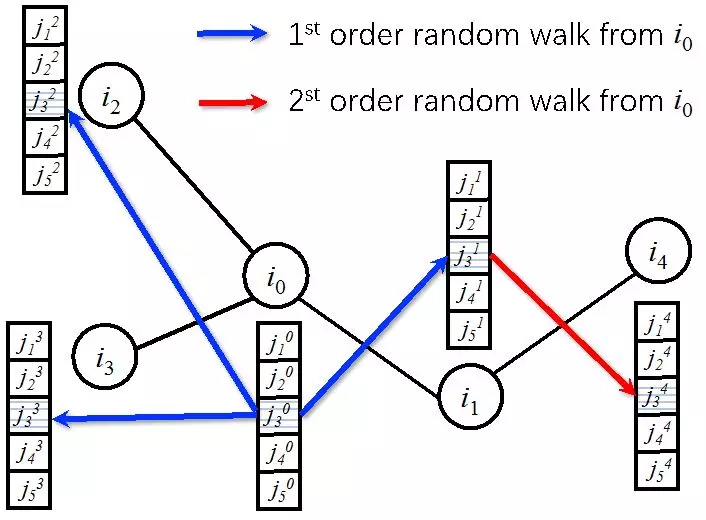
图 3 基于 Random Walk 的用户信息交互
1. C1 的解决方案
为回答第一个问题,我们首先对真实 POI 数据做了分析,如图 2 所示。从图 2 我们可以发现,在 POI 场景中,绝大多数用户具有地理位置的聚集性。因此,用户可以通过与地理位置相近的其他用户交换信息来学习模型。我们首先使用用户地理位置信息构建用户邻接图,然后提出使用 Random Walk 在用户邻接图上做信息交互,如图 3 所示。其中,i 表示用户,j 表示 POI,当用户 i0 对 POI j3 产生了一个动作时(如 check-in),用户 i0 会将其学到的关于 j3 的信息传递给其一阶或多阶邻居。至于是何种信息,下文会有介绍。同时,我们可以通过指定 Random Walk 的最大跳数来限制用户之间信息交互频率,以减小通信和计算开销。
2. C2 的解决方案
已有研究[1]已经证明,去中心化式的训练过程中,单独的学习者之间通过交换梯度可以实现模型的收敛。在去中心化式的矩阵分解场景下,我们提出用户之间通过交换 POI 的共享潜在向量梯度来完成用户之间的协同训练。即,当一个用户对某 POI 有行为时,该用户的潜在向量以及该 POI 的共享及个性化潜在向量都会通过梯度进行更新,与此同时,该用户将该 POI 共享潜在向量的梯度发送给其邻居,这些邻居拿到该 POI 共享潜在向量的梯度之后,得知与其相关的用户已经对该 POI 进行了一定的反馈。因此,存在这些邻居处的该 POI 共享潜在向量也会得到相应更新,以此来完成模型的协同训练。
实验结果及分析
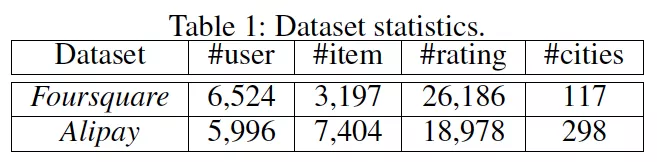
我们的实验在两个数据集上完成,一个是学术界公开数据集(Foursquare),另一个则是支付宝内真实的数据集(Alipay),两个数据集信息如表 1 所示。
在真实的推荐场景下,推荐物品 top 准确性至关重要,因此,我们选择 top 的准确率(P@k)和召回率(R@k)作为评价指标。同时,我们选择了传统集中式的矩阵分解方法(MF)和集中式的 pairwise 优化方法(BPR)作为对比方法外。此外,我们还对比了我们在模型(DMF)在用户设备上只保留 POI 共享(common, global)潜在向量(GDMF),及只保留 POI 的个性化(personal, local)向量(LDMF)时,我们模型的效果。对比结果见表 2 和表 3。
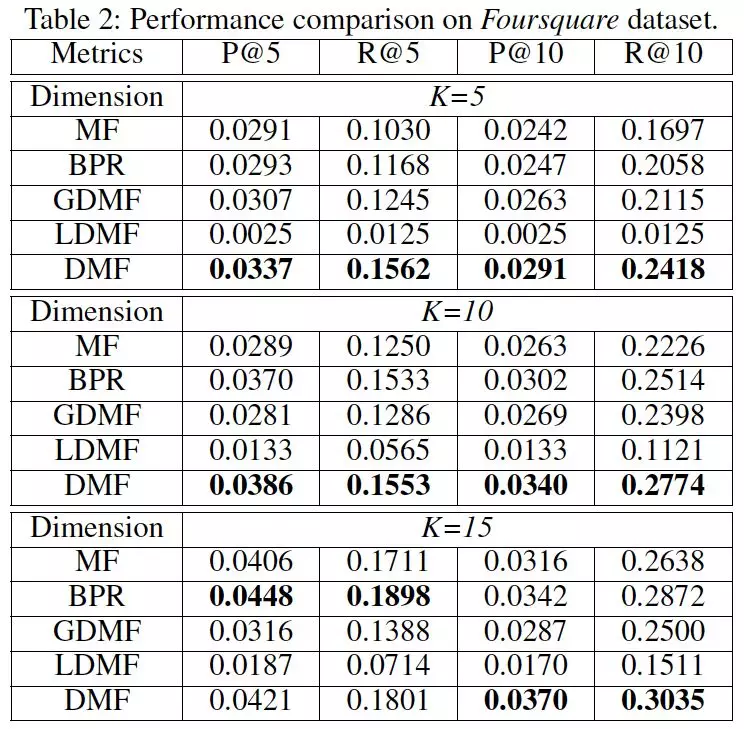
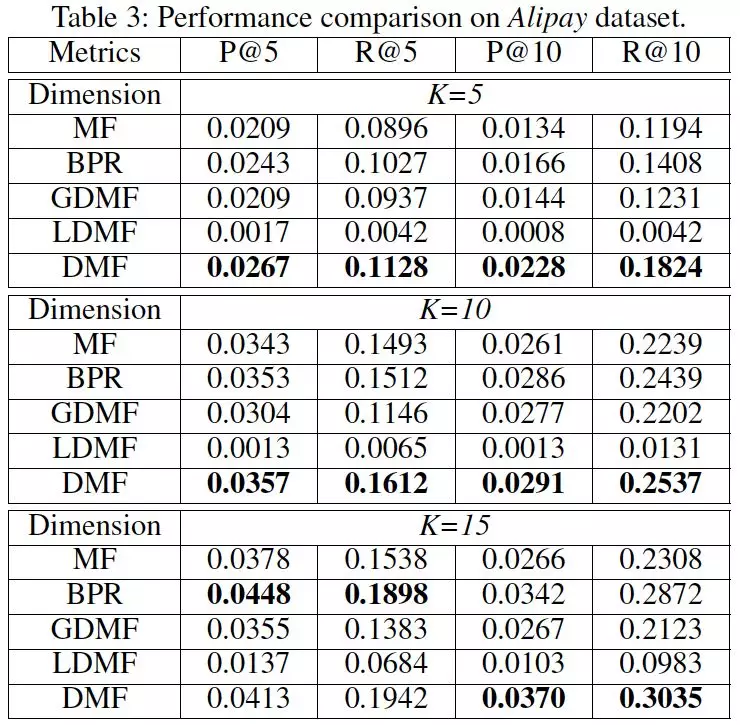
从对比结果中我们可以看出,我们所提出的去中心化的矩阵分解方法,效果不仅可以优于集中式的矩阵分解方法,而且可以优于大多数情况下 pairwise 的优化方法;同时也可以看出去掉用户之间的协同作用之后(LDMF),模型效果得到大幅度下降,这也表明了用户协同训练的重要性。此外,图 4 显示了我们模型在两个数据集上 train 和 test 上的 loss,可以看出,模型随着迭代次数的增加,在 train 和 test 上都能很好的收敛。

图 4 模型 train 和 test loss 随着迭代次数的变化
总结
随着个人,企业及政府对用户隐私保护重视程度的提高,很多数据都由用户或单位自己保管。因此,如何在保证他们各自都保留自己数据的前提下,协同训练并共同获得推荐成果成为一个发展趋势。除传统的数据加密方法外,该论文所提出的去中心化式的推荐方法成为了基于用户数据隐私保护的另一类推荐方法。
现在的方法中,所有的潜在向量都是以实数向量的形式进行存储,在数据量极大时,用户设备的存储及计算资源将会限制模型的扩展性。因此,我们会把模型的压缩作为未来工作。
本文转载自公众号蚂蚁金服科技(ID:Ant-Techfin)。
原文链接:
https://mp.weixin.qq.com/s/JrUQupsoKqpwfd4bnYfwFA

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论