
在人工智能的世界里,正在发生一场翻天覆地的变化,随着 ChatGPT、Sora 的横空出世,我们正在从深度学习时代转向生成式人工智能时代,而在这场巨变中,芯片成为了科技巨头们的必争之地。
近日,硅谷一家初创企业以一款独特的芯片产品攻占各大科技媒体板块头条。该公司正以一种与过往不同的方式推动这场人工智能革命。该公司名为Groq,是一家人工智能解决方案公司。
据多家外媒报道,Groq 刚刚推出了 alpha 预览版的推理引擎,该引擎使用其定制的语言处理单元 (LPU) 芯片架构。这款推理引擎主打一个“快”字,每秒能输出 500 个 token。相比之下,Chat GPT-3.5 每秒生成速度为 40 个 token。
“Groq 那疾如闪电的演示开始疯传,让人们第一次意识到当前版本的 ChatGPT、Gemini 甚至是 Grok 看起来是多么笨拙和迟缓。”有网友感叹道。
“你必须尝试的疯狂技术!” HyperWriteAI CEO Matt Shumer 在 X 上极力称赞 Groq:“以 500 tok/s 的速度运行 Mixtral 8x7B-32k,答案几乎是即时的。开辟新的用例,并彻底改变现有用例的用户体验可能性。”
根据 Shumer 发布在 X 上的演示,Groq 能够瞬间给出包含数百个单词的事实性答案,并提供逻辑链上的消息来源。
在另一段演示中,Groq 公司创始人兼 CEO Jonathon Ross 还邀请 CNN 主持人以实时对话的方式,跟跨越半个地球的 AI 聊天机器人来了场电视直播交流。虽然之前的 ChatGPT、Gemini 等其他聊天机器人也都带来令人印象深刻的表现,但 Groq 单凭速度一项就倾倒了众生。正所谓“天下武功,唯快不破”,速度往往是决定技术成果能否实际应用的关键。
在 Groq 的第一个公开基准测试中,Meta AI 的 Llama 2 70B 在 Groq LPU™ 推理引擎上运行,其输出令牌吞吐量快了 18 倍,优于所有其他基于云的推理提供商。
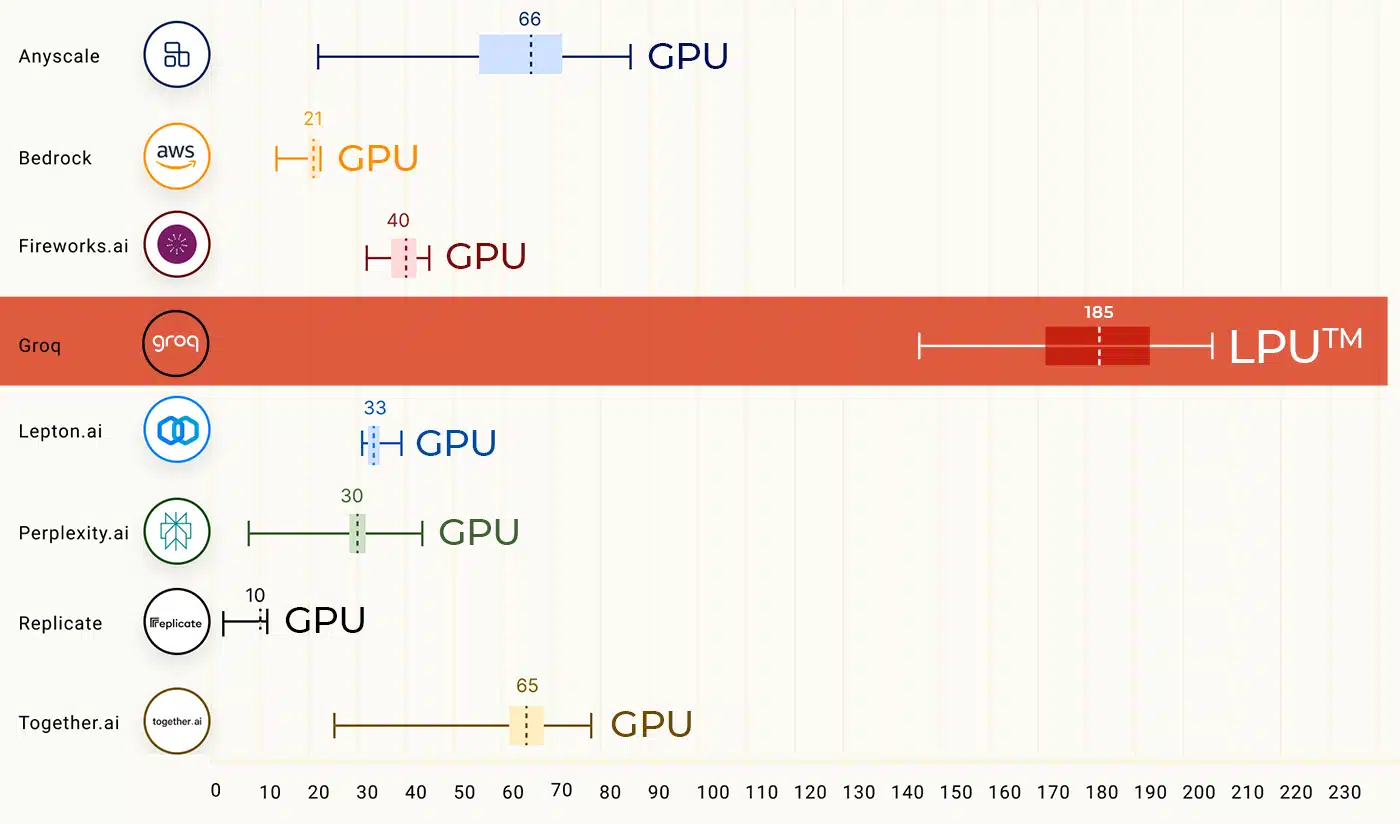
此外,根据 Artificial Analysis 上周公布的第三方测试结果,Groq 每秒能够生成 247 个 token,远远高于微软的 18 个 token。也就是说如果将 ChatGPT 运行在 Groq 芯片之上,其速度将可提高 13 倍有余。
成本推算屡受质疑
在传统 CPU 和 GPU 领域,更快的推理速度往往意味着要付出更高的成本。但从成立之初,Groq 就在强调公司的使命是将计算成本降至零。
在面对成本问题时,Ross 曾在两年前接受《福布斯》采访时表示:“Groq 决定做一些完全不同的事情,进行与传统半导体行业智慧相反的创新。我们的使命是将计算成本降至零。我知道每个人都讨厌高昂的计算成本。但是,如果你回顾一下计算的历史就会发现计算成本避无可避。因此,当我们说‘将计算成本降至零’时,我们仍然以具有竞争力的行业价格点来销售我们的解决方案。也就是说,当我们提供数量级的性能改进(200 倍、600 倍、1000 倍)时,我们每美元所提供的性能是 200、600、1000 倍。所以,它正在接近免费。”
Groq 在官网上称“保证击败同等上市模型的已发布提供商所发布的每百万 token 的价格。”
但一些业内人士以及开发者群体对于 Groq 卡的高昂价格和 CEO 主张的的“价格正在接近免费”的说辞提出了质疑。原 Facebook 人工智能科学家、原阿里巴巴技术副总裁贾扬清就给 Grop 算了一笔账,Groq 的成本到底如何,且看大佬的分析。

(图片来自网络)
此外,也有 Groq 前员工在 Hacker News 上表示 Groq 理论上的推理成本是不切合实际的。
Groq 曾在发文中指出,他们使用了 576 个芯片来实现以 500 T/s 的速度运行 Mixtral 8x7B-32k 这样的结果。但不得不注意的是,每个单独的用户都需要一个单独的 KV 缓存,每个用户将增加更多千兆字节。
我曾在 Groq 工作两年,我预计他们实现这些性能数字的总费用将超过数百万美元,他们发布的理论价格应该比实际使用价格更低,因此这个结果是不切实际的。从每美元实际性能的角度来看,它们似乎不可行,但如果你将成本问题抛到九霄云外,那么它们确实挺酷的。
Groq 背后的秘密:架构和编译器
那么,Groq 又是如何做到如此之快呢?据悉,Groq 能做到如此之快背后的秘诀是架构和编译器的创新。
从零开始设计架构
在一次公开技术分享中,Groq CEO Ross 透露, Groq 芯片的架构从头开始设计的,其中包含数千个并行处理推理查询的多线程处理器。每个芯片周围都有一个独特的、确定性的数据流架构,可最大限度地提高吞吐量,同时最大限度地减少延迟和功耗。
Groq 的 TSP 处理器绕过了造成时序不可预测性的缓存和控制逻辑。相反,结果按照软件定义的序列直接从一个执行单元流向下一个执行单元,从输入到输出仅花费几微秒。
对于大规模部署,GroqNode 服务器提供机架就绪的可扩展计算系统。GroqNode 是八个 GroqCard 加速器组,在 4U 服务器机箱中具有集成芯片到芯片连接以及双服务器级 CPU 和高达 1 TB 的 DRAM。GroqNode 旨在实现大型深度学习模型的高性能和低延迟部署。
最后,对于数据中心部署,GroqRacks 提供了可扩展的加速器网络。GroqRack 结合了 8 个 GroqNode 集的功能,具有多达 64 个互连芯片。其结果是一个确定性网络,单个机架的端到端延迟仅为 1.6 微秒,非常适合海量工作负载,并且旨在扩展到整个数据中心。
在面对面的基准测试中,与基于 GPU 的大型语言模型推理系统相比,Groq 系统的延迟时间提高了 100 倍,而成本仅为 1/5。当 GPU 性能受到批处理要求和内存层次结构的影响时,Groq 的架构是从头开始构建的,以最大限度地减少单个查询的延迟。
通过消除昂贵的数据移动,GroqChips 仅消耗几瓦的功率,而不是像 GPU 那样消耗数百瓦的功率。这使得能源效率提高了 10 倍,这对于控制爆炸式增长的 AI 计算成本至关重要。
值得注意的是,Groq 自称“第一个语言处理单元 (LPU™) 的创建者”。它的核心壁垒在于其独特的 LPU 推理引擎,LPU 代表语言处理单元,这是一种新型的端到端处理单元系统,可为具有顺序组件的计算密集型应用程序提供最快的推理,例如人工智能大语言模型。
Groq 一直在强调,LPU 解决了大语言模型的两个瓶颈:计算密度和内存带宽。就大语言模型而言,LPU 比 GPU 和 CPU 具有更大的计算能力。这减少了每个单词的计算时间,从而可以更快地生成文本序列。此外,消除外部内存瓶颈使 LPU 推理引擎能够在大语言模型上提供比 GPU 好几个数量级的性能。

根据推特上与 Groq 关系密切的投资人 k_zeroS 分享,LPU 的工作原理与 GPU 截然不同。它采用了时序指令集计算机(Temporal Instruction Set Computer)架构,这意味着它无需像使用高带宽存储器(HBM)的 GPU 那样频繁地从内存中加载数据。这一特点不仅有助于避免 HBM 短缺的问题,还能有效降低成本。
与传统 GPU、GPU、TPU 相比,Groq 的 LPU 也有其自身优势。
一直以来,使用现有架构并连接许多 CPU 解决了训练挑战。人工智能推理要困难得多,因为它是实时的、对延迟敏感的,并且需要高性能和高效率。
随着时间的推移,CPU 变得越来越大、越来越复杂,具有多个内核、多个线程、片上网络和控制电路。负责加速软件性能和输出的开发人员必须处理复杂的编程模型、安全问题以及由于处理抽象层而导致编译器控制可见性的丧失。简而言之,标准计算架构具有不提供推理性能优势的硬件功能和元素。
GPU 架构专为 DRAM 带宽而设计,并构建在多数据或多任务固定结构处理引擎上。GPU 执行大规模并行处理任务,但存在内存访问延迟,而 ML 已经突破了外部内存带宽的限制。

不同于英伟达 GPU 需要依赖高速数据传输,Groq 的 LPU 在其系统中没有采用高带宽存储器(HBM)。它使用的是 SRAM,其速度比 GPU 所用的存储器快约 20 倍。
鉴于 AI 的推理计算相较于模型训练需要的数据量远小,Groq 的 LPU 因此更节能。在执行推理任务时,它从外部内存读取的数据更少,消耗的电量也低于英伟达的 GPU。
如果在 AI 处理场景中采用 Groq 的 LPU,可能就无需为英伟达 GPU 配置特殊的存储解决方案。LPU 并不像 GPU 那样对存储速度有极高要求。Groq 公司宣称,其技术能够通过其强大的芯片和软件,在 AI 任务中取代 GPU 的角色。
编译器是重要基石
在编译器部分,Groq 也做了大量创新。Jonathan Ross 坚持将编译器作为公司技术能力的基石,因此设计团队在做芯片的前六个月的时间里专注于设计和构建编译器。只有在团队对编译器感到满意后,才开始研究芯片架构。
与传统编译器不同,Groq 不依赖内核或手动干预。通过编译器和硬件的软件优先协同设计方法,Groq 构建了编译器,自动将模型直接映射到底层架构。自动编译过程允许编译器优化硬件上的模型执行,而无需手动开发或调整内核。
该编译器还可以轻松添加资源和扩展。到目前为止,Groq 已经使用刚刚描述的自动化流程编译了 500 多个用于实验目的的 AI 模型。
当 Groq 将客户的工作负载从 GPU 移植到 Groq LPU 时,第一步是删除针对 GPU 的不可移植的供应商特定内核,然后删除任何手动并行或内存语义。当所有非必要的内容都被剥离后,剩下的代码会变得更加简单和优雅。
目前,在 Groq 网站上,用户可以随意测试不同的聊天机器人,并查看它们在 Groq LPU 上的运行速度。感兴趣的朋友可以点击尝试:https://groq.com/
Groq 为何备受关注?
Groq/Grok 这个词来自 Robert Heinlein 于 1961 年创作的科幻小说《异乡异客》(Stranger in a Strange Land),本身的意思是“深刻而直观地理解”。也许正是为了达成这样的效果,众多 AI 厂商才争相用它来形容自己的 AI 产品。
那么,Groq 为何能在短期内获得如此大的关注?
有分析认为,之所以备受关注,原因主要有三点:其一,是 Groq 在架构和编译器上的创新(上文已经详解,不再赘述);其二,是谷歌芯片大佬光环加持;其三,是 Groq LPU 的出现有望使客户摆脱硬件的锁定。
2016 年底,Jonathon Ross 从谷歌离职创办了 Groq,希望能为 AI 和 HPC 工作负载提供毫不妥协的低延迟和高性能。Ross 此前发明了驱动谷歌机器学习(ML)软件的张量处理单元(TPU),这两项技术为当时红极一时的 AlphaGo 提供了重要的技术支撑。当时,谷歌的这支工程团队在大约 14 个月内就完成了第一代 TPU,因此被外界认为是一支技术实力超群的技术团队。
就在那一年,这支技术实力超强的谷歌 TPU 团队中的前 10 名成员中有 8 名成员跟随 Ross 离开了谷歌。
2017 年,这家初创公司从风险投资家 Chamath Palihapitiya 那里获得了 1030 万美元的资金,公司最近还聘请了 Xilinx 销售副总裁 Krishna Rangasayee 担任首席运营官。
这个神秘的团队在成立后的三年时间里几乎从社交媒体中“隐身”,没有过多关于公司的消息爆出。直到 2019 年 10 月,Groq 发布了一篇名为《世界,认识 Groq》的博客,向世界宣告了自己的存在。
此后的时间里,Groq 打造出了名为语言处理单元(LPU)的 AI 芯片,并向外界放出消息称其速度已经超越了英伟达的图形处理单元(GPU)。换句话说,从早期结果来看,LPU 的确有希望击败已经在 AI 模型领域成为行业标准的英伟达 GPU。
迄今为止,Groq 已从顶级风险投资公司获得了约 3.62 亿美元的资金。
据 Ross 介绍,Groq 的软件定义架构提供了更大的灵活性,有望帮助客户摆脱传统硬件解决方案中将用户锁定在特定于供应商的框架(例如 CUDA 和英伟达生态系统)中的处境。
正如 Ross 所描述的,“我们的编译器会自动执行此操作。因此,您可以在其中放入一行 groq.it,然后将模型放在括号中,就这样了。” 这种便携式方法允许使用 PyTorch 等标准框架训练的模型无需修改即可在 Groq 系统上高效运行。
通过避免专有接口,Groq 能够与最新出现的机器学习创新兼容,而不需要模型转换。因此,Groq 的平台设计旨在防止当今困扰许多 GPU 部署的硬件锁定问题。对于平衡新兴需求与遗留约束的开发团队来说,Groq 的灵活性提供了一条前进的道路。

乔纳森·罗斯 (Jonathan Ross),Groq 的首席执行官兼创始人。
尽管 Groq 赢得了一波广泛关注,但其 AI 芯片是否真能与英伟达 GPU 或者谷歌 TPU 在计算性能和可扩展性上正面对抗仍然有待观察。
英伟达的霸主地位,短期内谁都撼动不了
在近期 Groq 攻占各大科技媒体头条板块之时,老牌 AI 芯片霸主英伟达刚刚公布了去年第四季度财报。
据英伟达最新财报显示,截至 2024 年 1 月 28 日,2024 财年第四季度收入达到 221 亿美元,环比增长 22%,同比增长 265%,净利润为 122.85 亿美元,同比增长 769%。值得一提的是,英伟达单季度收入甚至已高于 2021 年全年。这一增长主要得益于人工智能技术的快速发展,特别是在加速计算和生成式 AI 领域。
受此影响,该公司股价在美股盘后一度大涨 10%。英伟达 CEO 黄仁勋表示,加速计算和生成式人工智能已经达到了引爆点,全球各个公司、行业和国家的需求都在飙升。
多年来,通过巧妙的收购、内部硬件/软件开发和战略联盟,以及利用 ChatGPT 发布所引发的生成式 AI 热潮,英伟达以压倒性优势牢牢占领了芯片霸主地位。无论是全行业的芯片短缺,还是其拟斥资 400 亿美元收购芯片竞争对手 Arm 的失败,都没有对英伟达的惊人增长产生任何明显影响。
“一个新的计算时代已经开始。世界各地的公司正在从通用计算向加速计算和生成式人工智能转型。”英伟达创始人兼首席执行官黄仁勋在公司财报中表示。
每家芯片公司都把英伟达列为了一个巨大的目标,如今,Groq 似乎距离赶超英伟达这一目标更近了些。
参考链接:
https://gizmodo.com/meet-groq-ai-chip-leaves-elon-musk-s-grok-in-the-dust-1851271871
https://vmblog.com/archive/2024/02/07/groq-a-game-changing-ai-chip-company-you-need-to-know.aspx




