

1. 研究背景
近年来,智能对话机器人在智能客服领域的应用越来越广泛。流畅的人机对话对解决客户的问题和维护客户的情绪十分重要,这要求机器人必须能够识别何时应当保持倾听,何时应当作出回复。然而现有的对话机器人几乎都遵循一问一答(turn-by-turn)的交互模式,这种模式经常导致机器人对客户不完整或重复的表达作出不合适的回复,甚至让对话朝着错误的方向发展下去。下图是滴滴客服场景中,一个用户和客服的对话,以及将客户的问题输入机器人后得到的对比结果,可以看到,客服机器人经常对这类不完整或重复的表达给出错误的回答。在客服领域中,用户在移动端更加倾向连续发送短的、片段的或重复的问题,因此机器人错误回复的问题更为突出。
尽管如此,学术界关于何时才是恰当的回复时机的研究却非常少。Google 在 Smart reply 系统中提出了 Triggering model,通过对邮件数据进行标注并训练一个二分类模型来判断某一封邮件是否应当被回复。然而在智能客服领域,对话具有半开放、多轮交互的特点,会话级别的标注成本十分高昂并且难以覆盖长尾意图。另一方面,由于在线客服经常同时服务多个客户,在回答客户的同时还要查询知识库、查询工具系统来解决用户的问题,针对某个客户的问题,客服往往不能及时的回复。这就削弱了客户和客服的对话日志中本应携带的有关应答时机的监督信息,并导致以监督学习的方式训练应答模型变得不可行。
在本文中,我们提出了 MRTM 模型,它基于自监督学习机制来学习一个给定的上下文是否应当被应答。具体来说,MRTM 引入了多轮对话答案选择(Multi-turn Response Selection)作为辅助任务。它通过给定上下文和候选回复,选择正确回复来建模给定上下文和候选回复的语义匹配关系。在建模多轮语义匹配模型中,我们提出通过一种非对称注意力机制来获取给定上下文中共现句子的重要度关系。这是基于这样的观察,即那些具有更高注意力得分的句子往往需要被回复,而那些较低分数的句子则可以被忽略。本文在滴滴客服对话数据集、京东客服对话数据集上进行了实验,结果表明 MRTM 大幅优于基于规则和基于监督学习的基线模型,同时超参数实验表明,增加训练数据可以有效的提升自监督学习任务的效果。MRTM 模型被集成至滴滴智能客服系统中,为司机、乘客和客服提供更加智能的服务。
2. 问题挑战
在智能客服场景中,应答时机判断问题较为复杂和困难,主要体现在以下三个方面:
应用于智能客服的应答时机判断模型需要具备多轮建模的能力,在不同的上下文语境下,用户发送相同 query 的情况下需要模型表现出不同的应答行为。例如用户发送“你好”,如果此时会话处于刚开始时,则欢迎语是较好的回复,如果是在等待查询结果时,欢迎语则很容易引起客户情绪上的不满。
应用于智能客服的应答时机判断模型对于预测的准确率和召回率要求都较高,“频繁”回复和“哑”回复均会导致不好的对话体验。在客服场景下,对话通常是半开放的,客户和客服的话题可能从业务和闲聊中频繁切换,这使得标注需要覆盖大量的会话日志,成本十分高昂。相比之下,其他与回复触发时机有关的任务,例如 token 级别上触发预测的任务(back-channels)则对召回率并不敏感。
客服坐席通常同时服务多个客户,由于查询知识库、查询系统判责处置结果、输入延时或网络延时等原因,客服往往不能十分及时的回复客户的问题。这导致以客服回复时机作为监督信号来训练应答响应模型变得不可行。
针对以上挑战我们提出了基于自监督学习的 MRTM 模型。
3. 解决方案
我们首先引入给定上下文和候选回复,选择正确回复任务作为辅助任务来协助应答模型训练。这是基于这样的事实:虽然客服往往不能及时回复某个客户的问题,但他们总是会尽快的对那些必要回复的问题作出回复。因此上下文与真正的回复之间满足大致的语义匹配关系,并且那些对语义匹配贡献程度较大的客户句子是应当被回复的,而那些对语义匹配贡献程度较低的客户句子应当被忽略。我们将上下文看做是多个重叠的局部上下文的组合,使用了滑动窗口对每个局部上下文中的客户句子进行建模。在每个滑动窗口内,我们提出了一种非对称自注意力机制来保留客户句子中重要的意图,并滤除无关的意图。非对称自注意力机制使用每个局部上下文窗口内的最后一个句子作为 key,与所有句子进行 attention 计算得到一个局部上下文窗口的表示。非对称自注意力机制强迫每个局部上下文窗口内的末尾句子首先关注到自身,其次向前关注。这是基于“某个客户的句子距离客服的回复越近,越有可能代表局部上下文的意图”的经验。值得强调的是,非对称自注意力机制可以减缓经典的自注意力机制引入的重要度偏差,如果使用经典自注意力机制,那些客户的高频问题倾向于在所有局部上下文窗口内都有很高的权重,从而干扰局部上下文窗口中最后一个客户问题的应答召回率,增加机器人的错误静默几率。
我们仅将局部上下文应用于客户的句子。这是因为在多数场景下,客服的回复均是完整且清晰表达的。在其他场景下,如果有必要也可以将局部上下文应用于会话的双方。当获取到所有局部上下文窗口表示之后,我们仅提取那些末尾句紧邻客服回复的局部上下文窗口和最后一个局部上下文窗口对应的表示,和所有的客服回复重新组合为上下文来建模时间上的序列关系。
模型图如下:
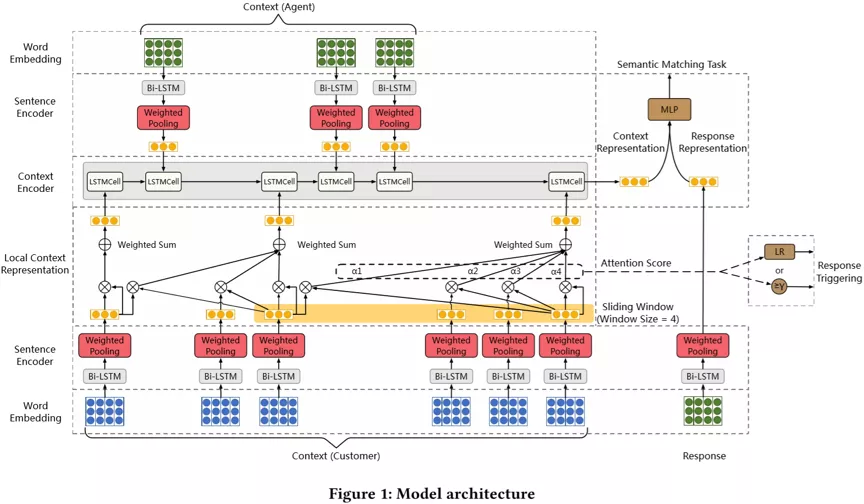
在问题和回复句向量编码阶段,我们考虑了 BiLSTM 和 BERT 两种编码器。其中 BiLSTM 是从头开始训练的,而 BERT 是在训练语料上首先进行预训练,再进行微调。
4. 实验与结果
为了验证 MRTM 的模型效果,我们设计了四个 baseline 作为对比方法:
一、 基于规则的方法:
a. Active Triggering based on Longest Utterance (ATLU)
b. Passive Triggering based on Shortest Utterance (PTSU)
二、 基于监督学习的方法:
a. Supervised Single-turn response Triggering
b. Supervised Multi-turn response Triggering
同时我们标注了少量样本(1 千个完整对话)作为验证集和测试集。为了研究不同触发策略的影响,我们设计了两种策略:
策略 1: 获取最后一个局部上下文表示窗口中的最后一句话的自注意力得分 s 作为触发条件。对滴滴客服对话数据集和京东客服对话数据集统计后,客户发言和客服发言之比约为 1.3:1,因此我们简单的设置阈值为 0.3,当 s<0.3 时机器人保持静默。我们标记这个策略为 I1。
策略 2(I2): 将最后一个局部上下文表示窗口中的若干注意力得分作为触发条件,不仅考虑最后一轮的自注意力得分,同时向前考虑 2-3 轮得分。为了完成这个策略的效果评估,我们额外标注了非常少(100 条)的样本训练一个二分类器。我们标记这个策略为 I2。
实验结果如下:
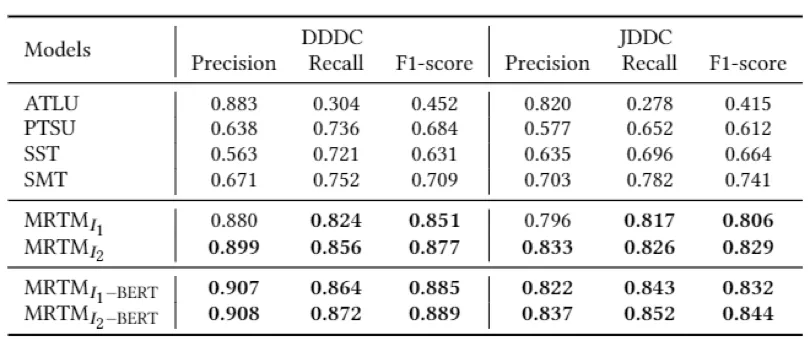
通过实验结果可以看到,MRTM 在准确率和召回率方面相比基于规则和基于监督学习的 baseline 性能更加优越。其中 ATLU 方法可以取得很高的准确率指标,这意味着在一个局部上下文窗口内,更长的句子会更容易被客服及时回复,然而召回率却很低,这意味着很多短句也会被及时回复。PTSU 方法的准确率和召回率都不高,这意味着需要回复的短句例如“你好”、“谢谢”、“好的”等和其他不需要回复的短句发生了混淆。
基于监督学习的方法在遇到具有不同标签的相似样本均发生了混淆。其中 SMT 具备更强的多轮建模能力,因此相比 SST 的性能更加良好和稳定。
基于 BERT 的 MRTM 相比基于 BiLSTM 的 MRTM 有一定提升,这意味着我们的自监督学习方案还有进一步提升的空间。但考虑到线上应用的性能,我们采用了基于 BiLSTM 的 MRTM。
作者介绍:
Simon,滴滴高级专家算法工程师
2017 年 7 月加入滴滴,任高级专家算法工程师,负责智能客服算法和架构工作,包括客服机器人、机器人平台、预测推荐、人工客服智能辅助等。2010 年硕士毕业于北京航空航天大学,硕士论文获得优秀学位论文。曾在腾讯、阿里巴巴公司工作,专注于广告推荐、问答对话领域的算法研发。在 KDD 等会议发表多篇论文,发表多篇国内国际专利,担任 TKDE 等期刊,KDD、AACL 等会议的审稿人。
本文转载自公众号滴滴技术(ID:didi_tech)。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论